Building your own private knowledge graph on Google Cloud
Tania Salame
Google Cloud Customer Engineer
Try Google Cloud
Start building on Google Cloud with $300 in free credits and 20+ always free products.
Free trialA Knowledge Graph ingests data from multiple sources, extracts entities (e.g., people, organizations, places, or things), and establishes relationships among the entities (e.g., owner of, related to) with the help of common attributes such as surnames, addresses, and IDs.
Entities form the nodes in the graph and the relationships are the edges or connections. This graph building is a valuable step for data analysts and software developers for establishing entity linking and data validation.
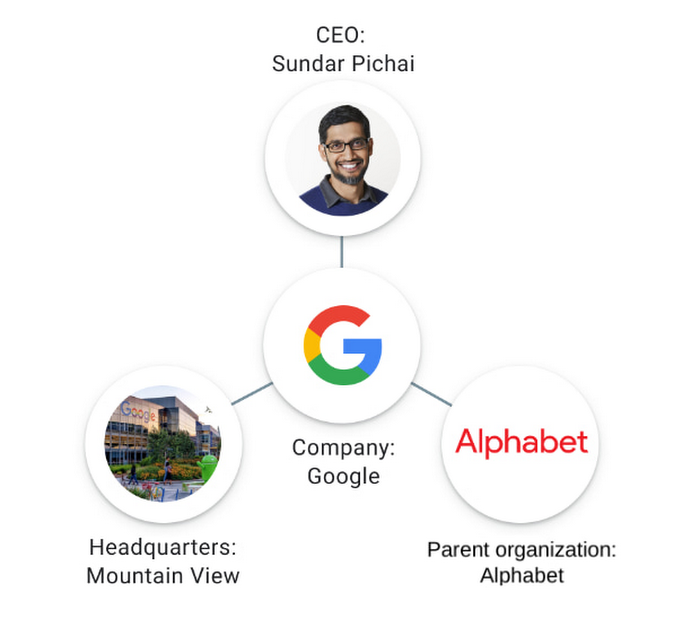
The term “Knowledge Graph” was first introduced by Google in 2012 as part of a new Search feature to provide users with answer summaries based on previously collected data from other top results and sources.
Advantages of a Knowledge Graph
Building a Knowledge Graph for your data has multiple benefits:
Clustering text together that is identified as one single entity like “Da Vinci,” “Leonardo Da Vinci,” “L Da Vinci,” “Leonardo di ser Piero da Vinci,” etc.
Attaching attributes and relationships to this particular entity, such as “painter of the Mona Lisa.”
Grouping entities based on similarities, e.g., grouping Da Vinci with Michelangelo because both are famous artists from the late 15th century.
It also provides a single source of truth that helps users discover hidden patterns and connections between entities. These linkages would have been more challenging and computationally intensive to identify using traditional relational databases.
Knowledge Graphs are widely deployed for various use cases, including but not limited to:
Supply chain: mapping out suppliers, product parts, shipping, etc.
Lending: connecting real estate agents, borrowers, insurers, etc.
Know your customer: anti-money laundering, identity verification, etc.
Deploying on Google Cloud
Google Cloud has introduced two new services (both in Preview as of today):
The Entity Reconciliation API lets customers build their own private Knowledge Graph with data stored in BigQuery.
Google Knowledge Graph Search API lets customers search for more information about their entities from the Google Knowledge Graph.
To illustrate the new solutions, let’s explore how to build a private knowledge graph using the Entity Reconciliation API and use the generated ID to query the Google Knowledge Graph Search API. We’ll use the sample data from zoominfo.com for retail companies available on Google Cloud Marketplace (link 1, link 2).
To start, enable the Enterprise Knowledge Graph API and then navigate to the Enterprise Knowledge Graph from the Google Cloud console.
The Entity Reconciliation API can reconcile tabular records of organization, local business, and person entities in just a few clicks.Three simple steps are involved:
Identify the data sources in BigQuery that need to be reconciled and create a schema mapping file for each source.
Configure and kick off a Reconciliation job through our console or API.
Review the results after job completion.
Step 1
For each job and data source, create a schema mapping file to inform how Enterprise Knowledge Graph ingests the data and maps to a common ontology using schema.org. This mapping file will be stored in a bucket in Google Cloud Storage.
For the purposes of this demo, I am choosing the organization entity type and passing in the database schema that I have for my BigQuery table. Note to always use the latest from our documentation.
Step 2
The console page shows the list of existing entity reconciliation jobs available in the project.
Create a new job by clicking on the “Run A Job” button in the action bar, then select an entity type for entity reconciliation.
Add one or more BigQuery data sources and specify a BigQuery dataset destination where EKG will create new tables with unique names under the destination data set. To keep the generated cluster IDs constant across different runs, advanced settings like “previous BigQuery result table” are available.
Click “DONE” to create the job.
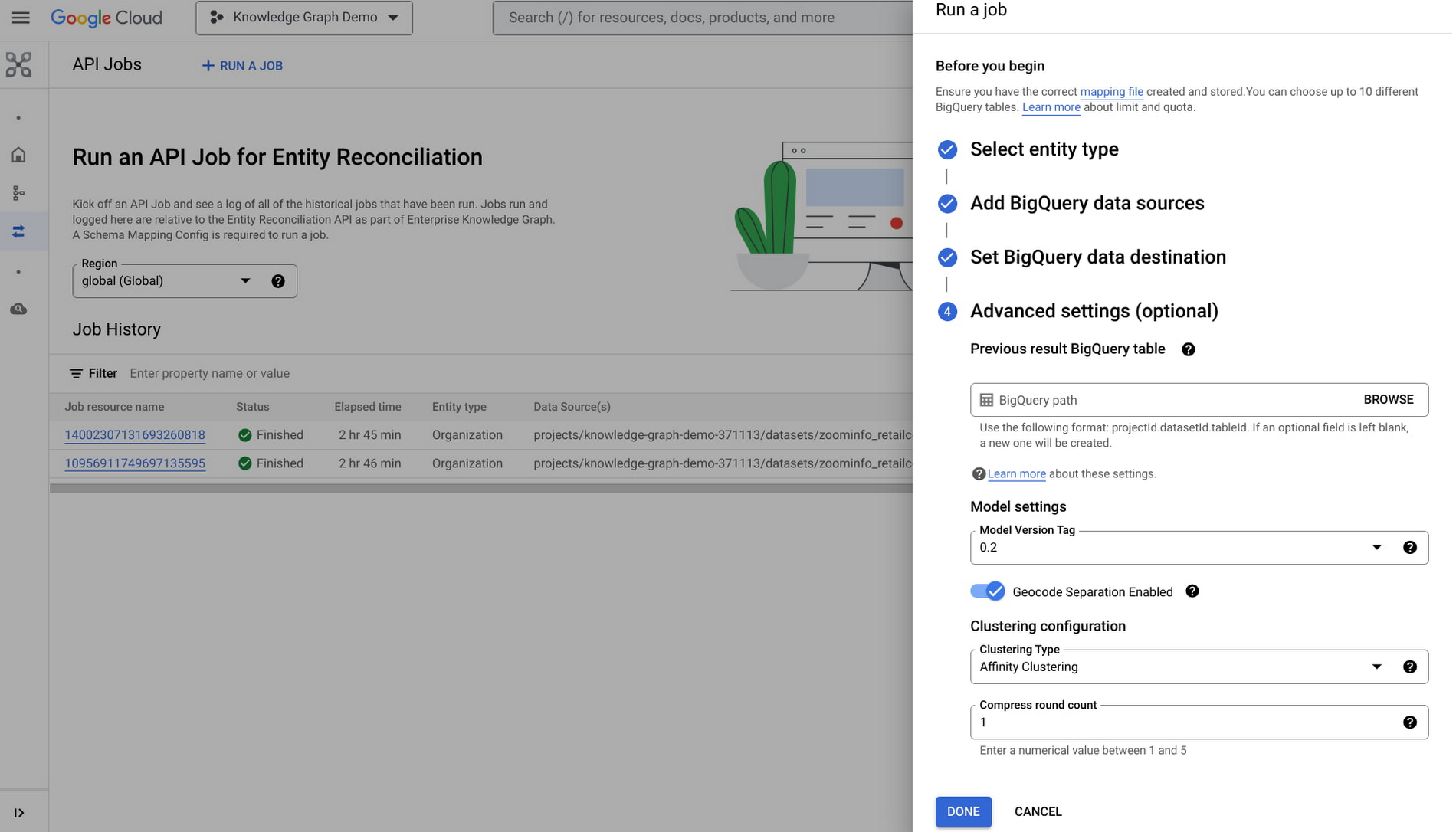
Step 3
After the job completes, navigate to the output BigQuery table, then use a simple join query similar to the one below to review the output:
This query joins the output table with the input table(s) of our Entity Reconciliation API and orders by cluster ID. Upon investigation, we can see that two entities are grouped into one cluster.
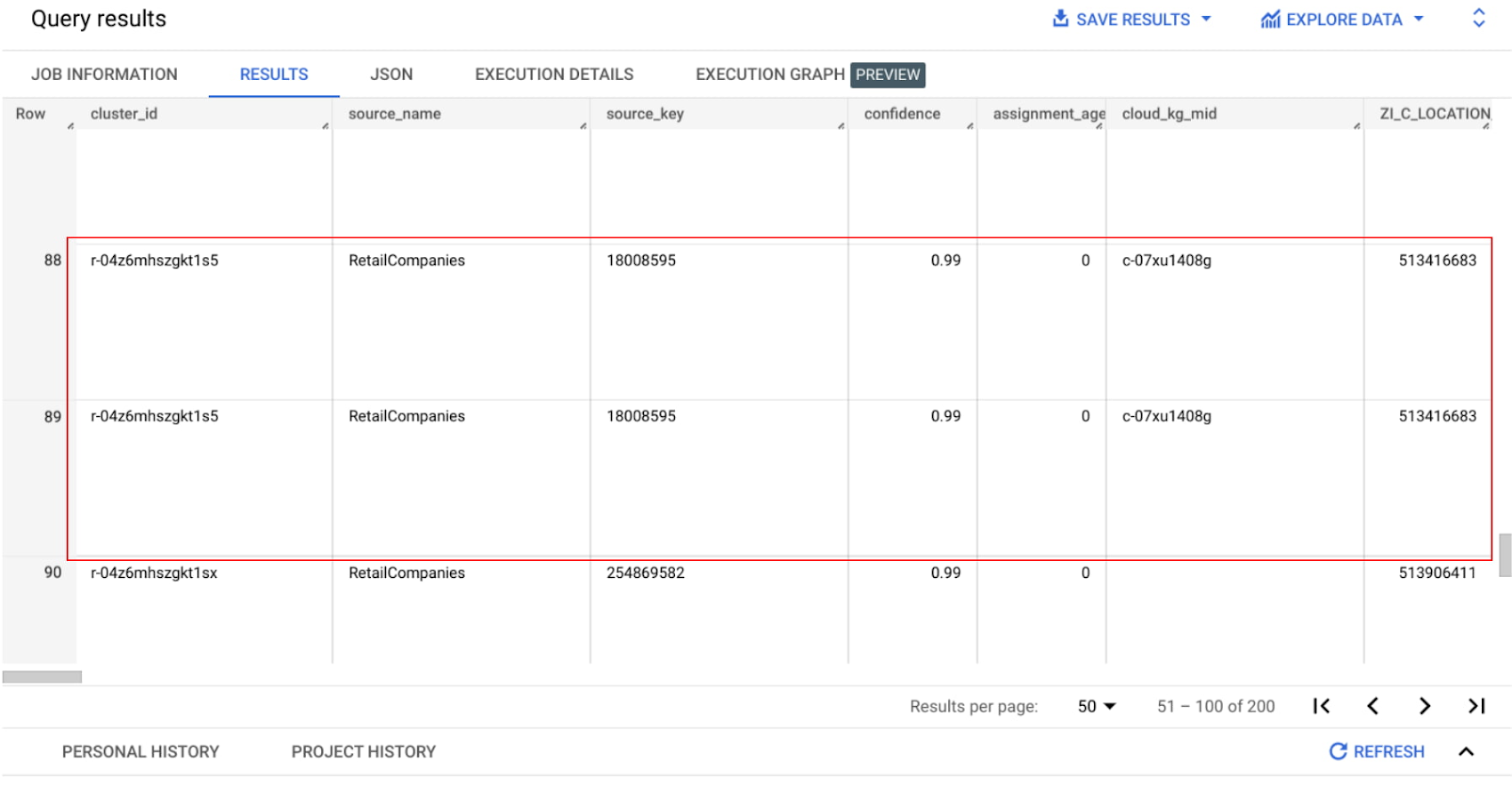
The confidence score indicates how likely it is that these entities belong to this group. Last but not least, the cloud_kg_mid column returns the linked Google Cloud Knowledge Graph machine ID, which can be used for our Google Knowledge Graph Search API.
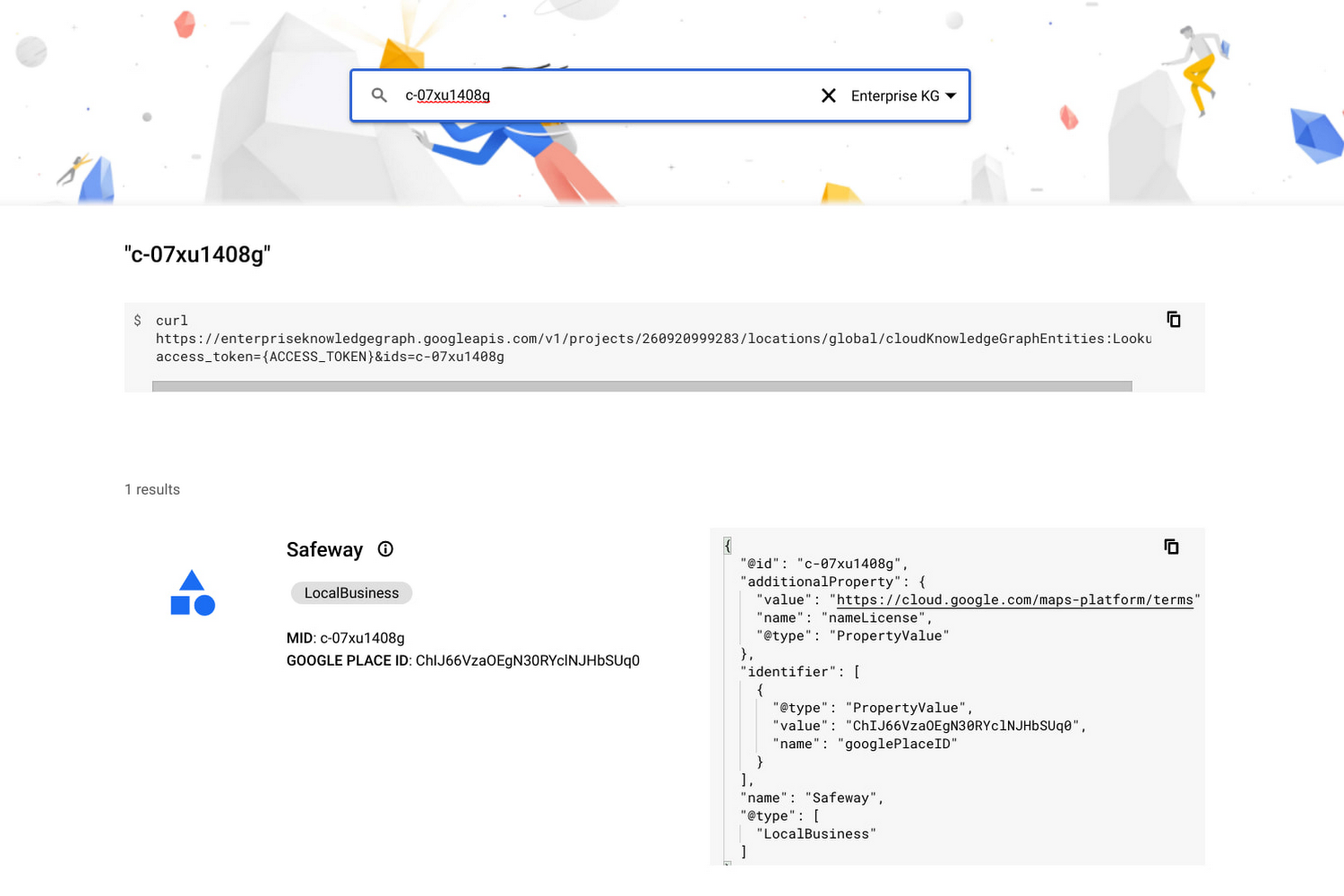
Running the above cURL command will return response that contains a list of entities, presented in JSON-LD format and compatible with schema.org schemas with limited external extensions.
For more information, kindly visit our documentation.
Special thanks to Lewis Liu, Product Manager and Holt Skinner, Developer Advocate for the valuable feedback on this content.



