Getting started with NL2SQL (natural language to SQL) with Gemini and BigQuery
Bernard Chang
Technical Account Manager
Wei Yih Yap
Generative AI Field Solutions Architect
The rise of Natural Language Processing (NLP) combined with traditional Structured Query Language (SQL) has given rise to an exciting new technology known as Natural Language to SQL, or NL2SQL, which translates questions phrased in everyday human language into structured SQL queries.
Not surprisingly, the technology has tremendous potential to transform the way we interact with data.
Leveraging NL2SQL, non-technical users such as business analysts, marketers, and other domain experts can interact with databases, explore data and gain insights on their own, without the need for specialized SQL knowledge. Even for those who are familiar with SQL, NL2SQL can reduce the time they need to manually formulate complex queries, freeing them time for more strategic analysis and decision-making.
What does that look like on the ground? Imagine being able to talk to a chat interface and get answers to questions on-the-fly such as:
-
“What is the total number of sold units month to date?”
-
“What are the key drivers for change in APAC sales comparing sales in Q1 and Q2?”
Traditionally, this would require a specialist to gather data from databases and transform it into business insights. Leveraging NL2SQL, we can democratize analytics by reducing barriers to accessing data.
However, there are challenges that make it difficult for NL2SQL to be widely adopted. In this blog, we'll explore NL2SQL solutions on Google Cloud and best practices for implementation.
Data quality challenges in real-world applications
But first, let’s take a deeper look at some of the things that make NL2SQL difficult to implement.
While NL2SQL excels in controlled environments and direct questions, real-world production data presents a variety of challenges, including:
Data formatting variations: The same information can be represented in different formats, e.g., 'Male,' 'male,' or 'M' for gender; or '1000,' '1k,' or '1000.0' for monetary values. In addition, many organizations have their own acronyms that are not well documented.
Semantic ambiguity: Large Language Models (LLMs) often lack domain-specific schema understanding, leading to misinterpretations of user queries, e.g. when the same column name carries different meanings.
Syntactic rigidity of SQL: Semantically correct queries can fail if they don't adhere to SQL’s strict syntax rules.
Custom business metrics: NL2SQL needs to handle complex business calculations and understand relationships between tables through foreign keys. A nuanced understanding of the tables to be joined and modeled together is needed to translate the question accurately. Furthermore, every organization has its own business metrics to measure in the final narrative report and there is no single general approach.
Customer challenges
It’s not just the data that can be ambiguous or imprecisely formatted — users’ questions are often confusing or complex. Here are three common problems with users’ questions that can make it hard to implement NL2SQL.
Ambiguous questions: Even seemingly straightforward questions can be ambiguous. For instance, a query about the "total number of sold units month to date" might require clarification on whether to use average_total_unit or running_total_unit, etc; as well as which date field to use. An ideal NL2SQL solution should proactively prompt the user to specify the appropriate column and incorporate their input during the SQL query generation process.
Underspecified questions: Another challenge is under-specificity in the question, where a user’s question about “the return rate of all products under my team in Q4” contains insufficient information, i.e. which team to interpret the query completely. An ideal NL2SQL solution should recognize uncertainty in the original input and follow up with clarifying questions to get a complete query representation.
Complex questions with multi-step analysis: Many questions involve multiple analysis steps. For example, think about identifying key drivers for quarter-over-quarter sales changes: An ideal NL2SQL solution should be capable of breaking down the analysis into manageable components, generating intermediate summaries, and ultimately compiling a comprehensive final report that addresses the user's query.
Addressing the challenges
To tackle these challenges, we prompted engineered Gemini Flash 1.5 as a routing agent to classify questions based on their complexity. Once the question is classified, we can use techniques such as ambiguity checks, vector embeddings, semantic searches, and contribution analysis modeling to improve our outputs.
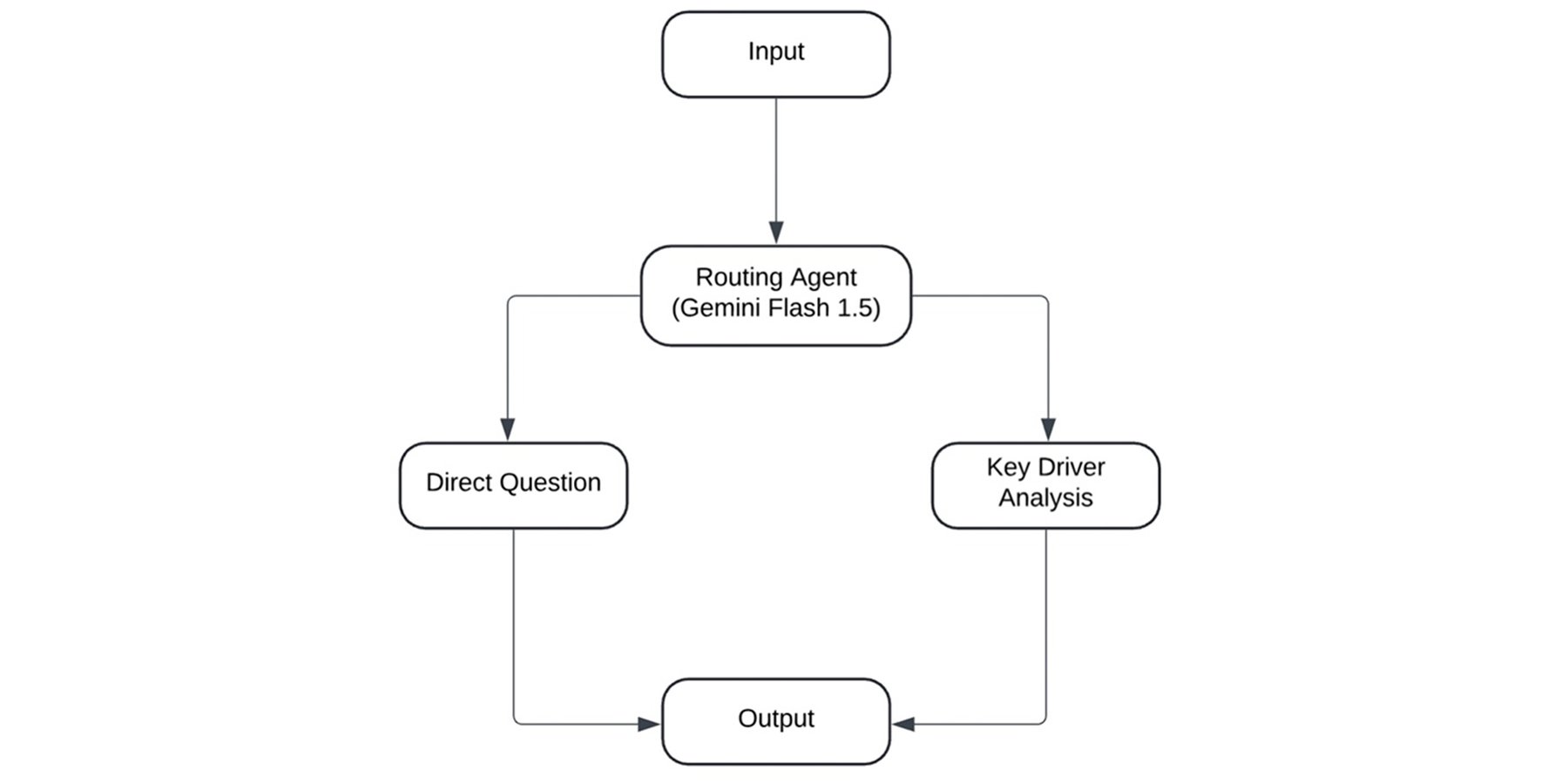
We use Gemini to receive instructions and respond in a JSON format. For example, the following few-shot prompt allows Gemini to behave like a routing agent:

Direct questions
For direct questions, we can leverage in-context learning, draft SQL ambiguity checks, and user feedback loops to clarify the correct column names in scope, and to ensure unambiguous SQL generation for simple questions.
For simple and direct questions, our approach performs the following tasks:
-
Collects good question/SQL pairs
-
Stores examples as BigQuery rows
-
Creates vector embeddings for the question
-
Extracts similar examples based on the user’s question via BigQuery vector search
-
Inserts example, table schema and question as LLM context
-
Generates draft SQL
-
Performs SQL ambiguity check + user feedback + refinement + syntax validation (Loop)
-
Executes the SQL
-
Summarizes the data in natural language
Our heuristic experiment suggested that Gemini performs well at tasks to check for SQL ambiguity. By first generating a draft SQL model that includes all the table schema and questions as context, we then prompted Gemini to follow up with clarifying questions for the user.
Key driver analysis
Data analysis that involves multi-step reasoning, where analysts need to slice and dice data by every conceivable combination of attributes (regions, product categories, distribution channels) is sometimes also called key driver analysis. For this use case, we recommend using a combination of Gemini and BigQuery contribution analysis.
On top of the steps taken with direct questions, key driver analysis incorporates some additional steps:
-
When asked a question about key driver analysis, the routing agent redirects to a key driver analysis special handling.

- Using BigQuery ML vector search, the agent retrieves similar question/SQL embedding pairs from ground truth stored in a BigQuery vector database.
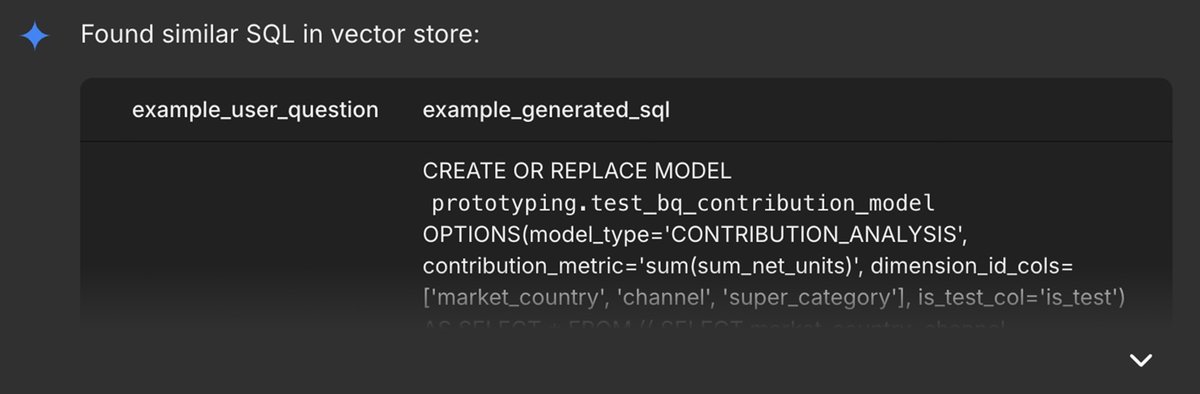
- It then generates and validates the CREATE MODEL statement to build a contribution analysis report.
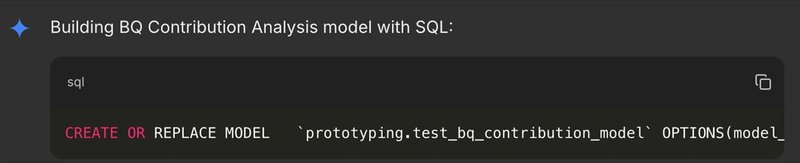
- It finally runs the following SQL to retrieve the contribution analysis report:

The resulting report looks like this:
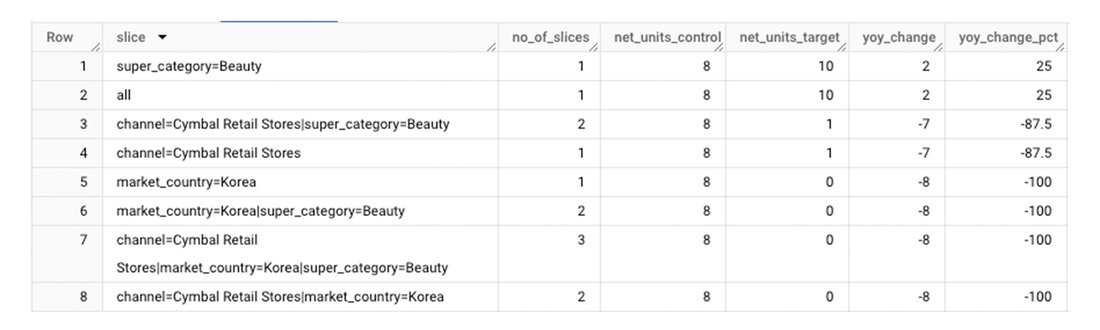
You can further summarize the report in natural language using Gemini:

Implementing NL2SQL on Google Cloud
While this may seem complicated, the good news is that Google Cloud offers a full complement of tools to help you implement a working NL2SQL solution. Let’s take a look.
Embedding and retrieval using BigQuery vector search:
BigQuery is used for embedding storage and retrieval, enabling efficient identification of semantically relevant examples and context for improved SQL generation. You can generate embeddings using Vertex AI’s text embedding API or directly at BigQuery via the ML.GENERATE_EMBEDDING function. Using BigQuery as a vector database and its native vector search makes it easy to match user questions and SQL pairs.
BigQuery contribution analysis
Given a dataset with both test and control data, contribution analysis modeling can detect regions of the data that are causing unexpected changes by identifying statistically significant differences across the dataset. A region is a segment of the data based on a combination of dimension values.
In BigQuery ML, the recently announced contribution analysis in preview enables automated insight generation and explanations of multi-dimensional data at scale, helping to answer questions like “why?” “what happened?” and “what’s changed?” with respect to your data.
In short, BigQuery’s contribution analysis models make it easier to generate multiple queries using NL2SQL, improving overall efficiency.
Ambiguity checks with Gemini
Traditionally, NL2SQL is a unidirectional process that translates natural language queries to structured SQL queries. To improve performance, Gemini can help to reduce ambiguity and improve the output statements.
You can use Gemini 1.5 Flash to gather user feedback by asking clarifying questions when a question, table, or column schema is ambiguous, helping to refine and improve the resulting SQL query. You can also use Gemini and in-context learning to streamline the generation of SQL queries and natural language summaries of the results.
The proposed architecture

NL2SQL best practices
We learned a lot over the course of developing this NL2SQL solution. Check out the following tips for a leg up on your own NL2SQL initiative.
Start with the questions to be answered: A question may sound simple, but reaching the desired answer and narrative often involve multiple reasoning steps, depending on the purpose of the final report. Have your question, SQL and expected natural language ground truth collected prior to your experiment.
Data preprocessing is crucial: Using LLMs is not a replacement for data cleansing and preprocessing. Ensure business domain acronyms are replaced with meaningful description or metadata, and create new table views as necessary. Start with simple questions that use one table before moving on to questions that require complex joins.
Practice SQL refinement with user feedback and iteration: Our heuristic experiment shows that refinement with feedback works better after creating a first draft of your SQL.
Use a custom flow for multi-step queries: BigQuery contribution analysis models can enable automated insight generation and explanations of multi-dimensional data at scale.
What’s next?
The combination of NL2SQL, LLMs and data analysis techniques represent a significant step towards making data more accessible and actionable for everyone. By empowering users to interact with databases using natural language, we can democratize data access and analysis, making better decision-making accessible to a wider audience within every organization.
Exciting new developments such as BigQuery contribution analysis and Gemini make it easier to rationalize data, scale and value than ever before. Read more about BigQuery contribution analysis here to get started on the public preview and start exploring the possibilities today!
And for more, check out more innovative ways to leverage BigQuery & Generative AI in Google Cloud:

