How to simplify building RAG pipelines in BigQuery with Document AI Layout Parser
Jeff Nelson
Developer Relations Engineer, Google Cloud
Eric Hao
Software Engineer
Document preprocessing is a common hurdle when building retrieval-augmented generation (RAG) pipelines. It often requires Python skills and external libraries to parse documents like PDFs into manageable chunks that can be used to generate embeddings. In this blog, we look at new capabilities within BigQuery and Document AI that simplify this process, and take you through a step-by-step example.
Streamline document processing in BigQuery
BigQuery now offers the ability to preprocess documents for RAG pipelines and other document-centric applications through its close integration with Document AI. The ML.PROCESS_DOCUMENT function, now generally available, can now access new processors, including Document AI's Layout Parser processor, allowing you to parse and chunk PDF documents with SQL syntax.
The GA of ML.PROCESS_DOCUMENT provides developers with new benefits:
- Improved scalability: The ability to handle larger documents up to 100 pages and process them faster
- Simplified syntax: A streamlined SQL syntax makes it possible to interact with Document AI processors for easier integration into your RAG workflows
- Document chunking: Access to additional Document AI processor capabilities like Layout Parser, to generate document chunks necessary for RAG pipelines
In particular, document chunking is a critical — but challenging — component of building a RAG pipeline. Layout Parser in Document AI simplifies this process. We’ll explore how this works in BigQuery and demonstrate its effectiveness using a real-world scenario shortly.
Document preprocessing for RAG
Breaking down large documents into smaller, semantically related units improves the relevance of the retrieved information, leading to more accurate answers from a large language model (LLM).
Generating metadata such as document source, chunk location, and structural information alongside chunks can further enhance your RAG pipeline, making it possible to filter, refine your search results, and debug your code.
The following diagram provides a high-level overview of the preprocessing steps in a basic RAG pipeline:
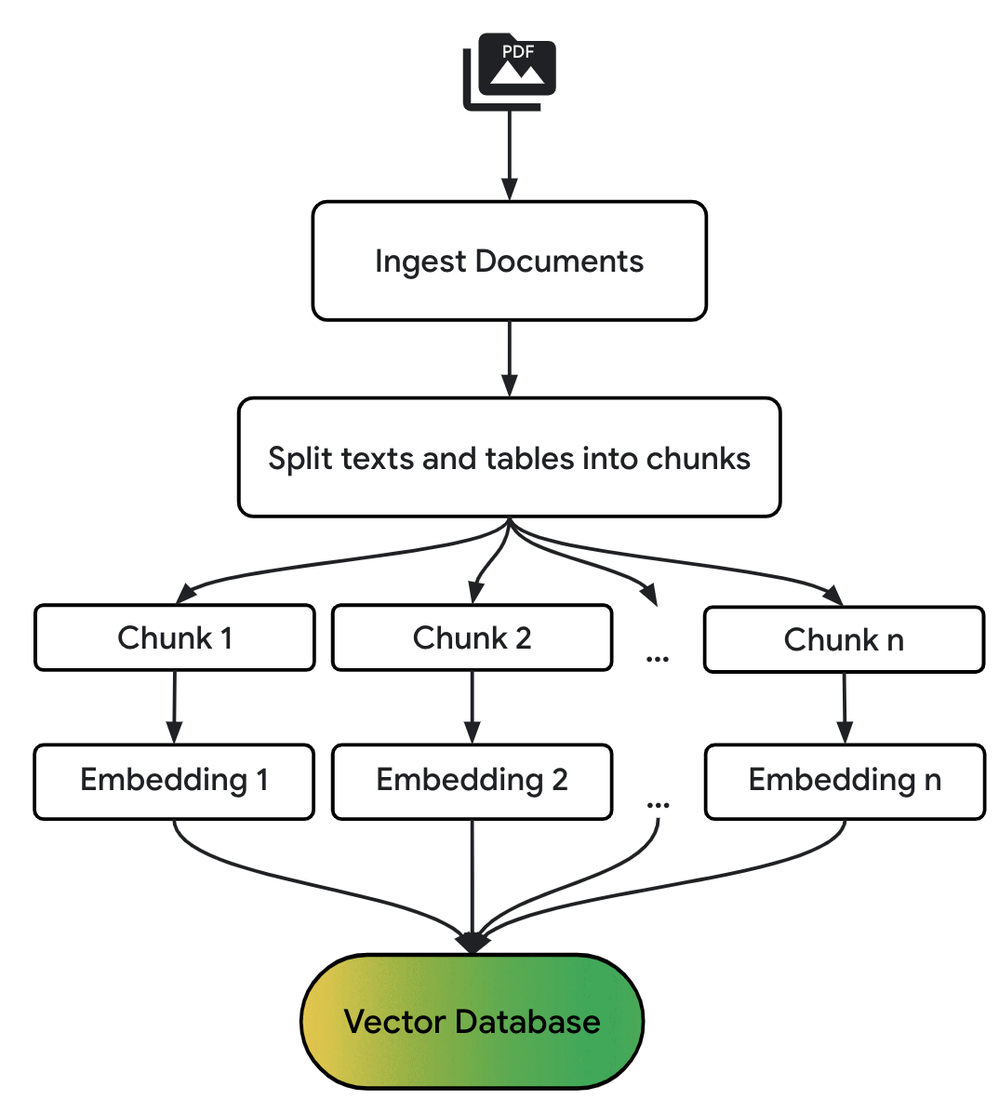
Build a RAG pipeline in BigQuery
Comparing financial documents like earnings statements can be challenging due to their complex structure and mix of text, figures, and tables. Let’s demonstrate how to build a RAG pipeline in BigQuery using Document AI's Layout Parser to analyze the Federal Reserve’s 2023 Survey of Consumer Finances (SCF) report. Feel free to follow along in the notebook here.
Dense financial documents like the Federal Reserve’s SCF report present significant challenges for traditional parsing techniques. This document spans nearly 60 pages and contains a mix of text, detailed tables, and embedded charts, making it difficult to reliably extract information. Document AI’s Layout Parser excels in these scenarios, effectively identifying and extracting key information from complex document layouts such as these.
Building a BigQuery RAG pipeline with Document AI’s Layout Parser consists of the following broad steps.
1. Create a Layout Parser processor
In Document AI, create a new processor with the type LAYOUT_PARSER_PROCESSOR. Then create a remote model in BigQuery that points to this processor, allowing BigQuery to access and process the documents.
2. Call the processor to create chunks
To access PDFs in Google Cloud Storage, begin by creating an object table over the bucket with the earnings statements. Then, use the ML.PROCESS_DOCUMENT function to pass the objects through to Document AI and return results in BigQuery. Document AI analyzes the document and chunks the PDF. The results are returned as JSON objects and can easily be parsed to extract metadata like source URI and page number.
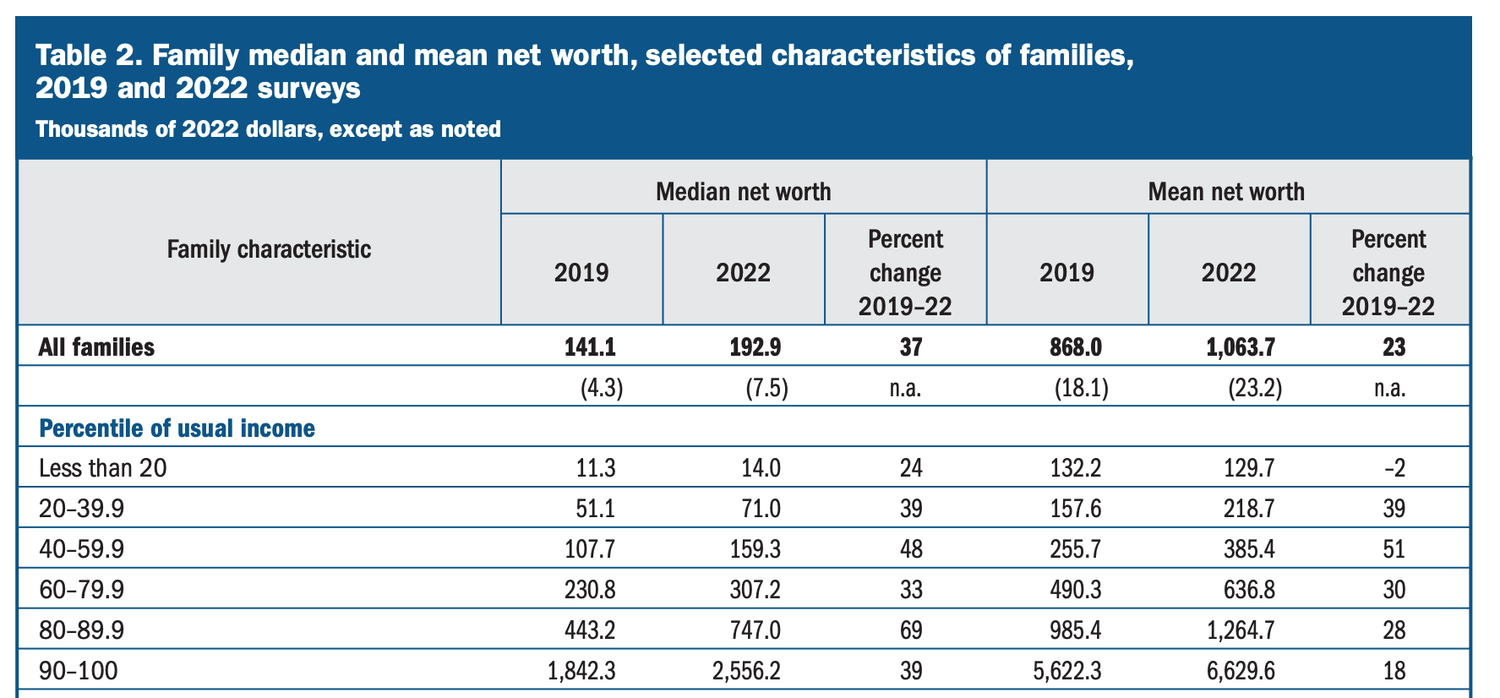
Sample image of a table element in the Survey of Consumer Finances report (p.12)
Parse the document with the ML.PROCESS_DOCUMENT function
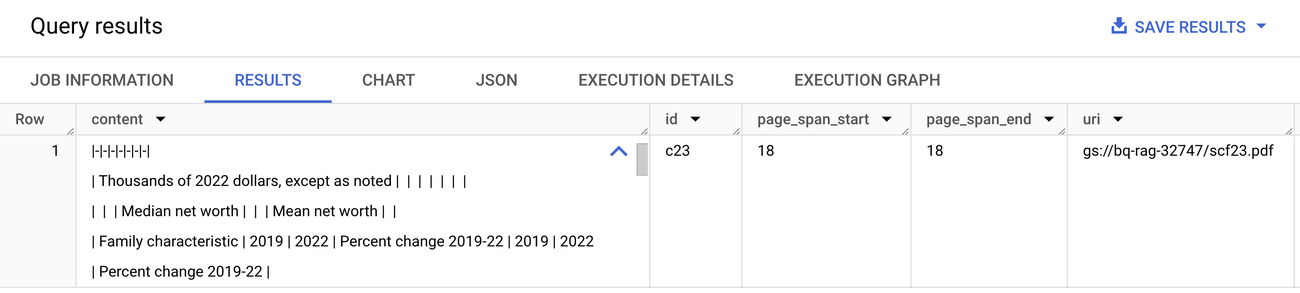
Sample document chunk after parsing the JSON from ML.PROCESS_DOCUMENT
3. Create vector embeddings for the chunks
To enable semantic search and retrieval, we’ll generate embeddings for each document chunk using the ML.GENERATE_EMBEDDING function and write them to a BigQuery table. This function takes two arguments:
- A remote model, which calls a Vertex AI embedding endpoints
- A column from a BigQuery table that contains data for embedding
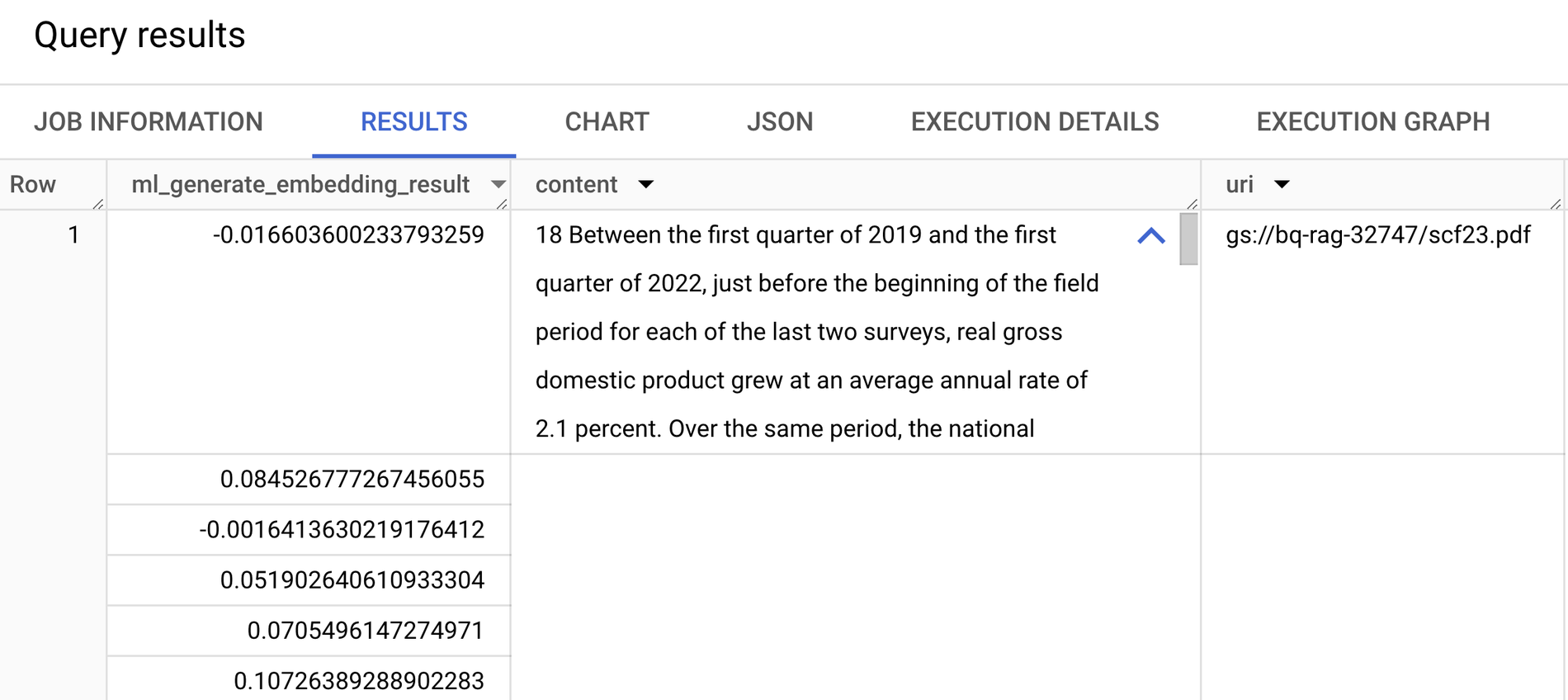
Vector embeddings in BigQuery returned from ML.GENERATE_EMBEDDINGS
4. Create a vector index on the embeddings
To efficiently search through large chunks based on semantic similarity, we’ll create a vector index on the embeddings. Without a vector index, performing a search requires comparing each query embedding to every embedding in your dataset, which is computationally expensive and slow when dealing with a large number of chunks. Vector indexes use techniques like approximate nearest neighbor search to speed up this process.
5. Retrieve relevant chunks and send to LLM for answer generation
Now we can perform a vector search to find chunks that are semantically similar to our input query. In this case, we ask how typical family net worth changed in the three years this report covers.
The retrieved chunks are then sent through the ML.GENERATE_TEXT function, which calls the Gemini 1.5 Flash endpoint and generates a concise answer to our question.
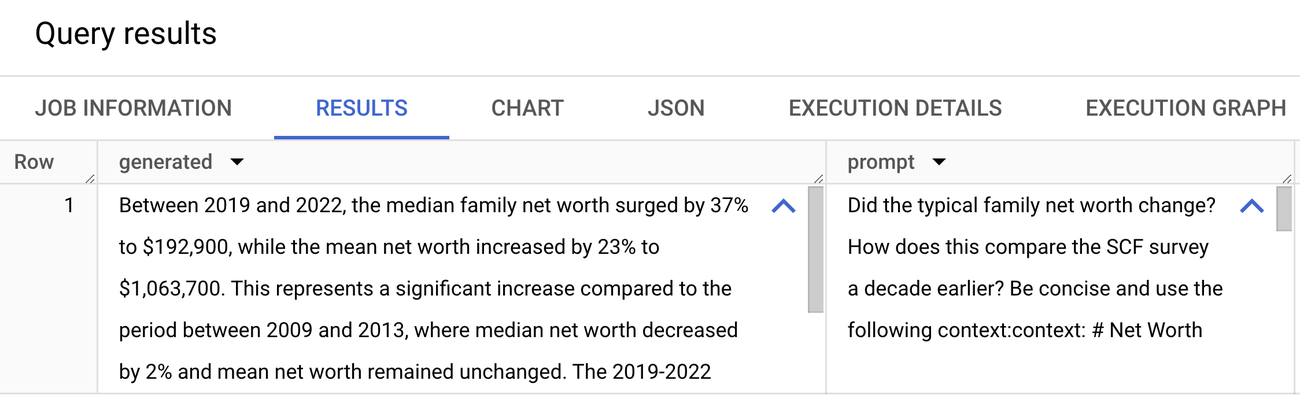
And we get an answer: median family net worth increased 37% from 2019 to 2022, which is a significant increase compared to the period a decade earlier, which noted a 2% decrease. Notice that if you check the original document, this information is within text, tables, and footnotes — traditionally areas that are tricky to parse and infer results together!
This example demonstrated a basic RAG flow, but real-world applications often require continuous updates. Imagine a scenario where new financial reports are added daily to a Cloud Storage bucket. To keep your RAG pipeline up-to-date, consider using BigQuery Workflows or Cloud Composer to incrementally process new documents and generate embeddings in BigQuery. Vector indexes are automatically refreshed when the underlying data changes, ensuring that you always query the most current information.
Get started with document parsing in BigQuery
The integration of Document AI's Layout Parser with BigQuery makes it easier for developers to build powerful RAG pipelines. By leveraging ML.PROCESS_DOCUMENT and other BigQuery machine learning functions, you can streamline document preprocessing, generate embeddings, and perform semantic search — all within BigQuery using SQL.
Ready to dive deeper? Explore the resources and documentation linked below:
If you have feedback or questions, let us know at bqml-feedback@google.com.

