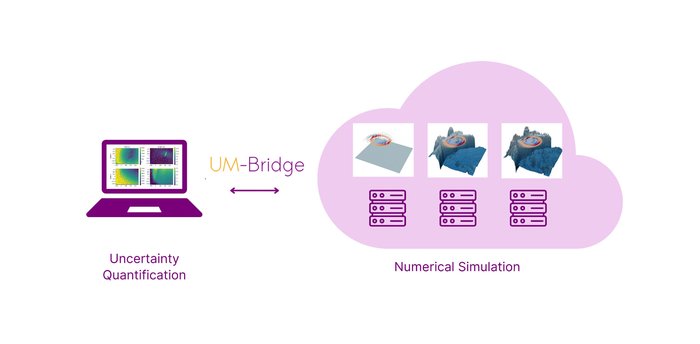
Google Cloud で実現するクラウドでの天気予報
Google Cloud Japan Team
※この投稿は米国時間 2022 年 3 月 29 日に、Google Cloud blog に投稿されたものの抄訳です。
天気予報と気候モデリングは、コンピュータの使用が世界で最も複雑かつ難しいタスクに数えられます。加えて、これらは時間的制約がきわめて大きいうえに需要も高く、週末の旅行者から大規模農業経営者までさまざまな人々が最新の気象予測を求めています。タイムリーで役立つ予測を提供するため、天気予報は通常、オンプレミスのデータセンターがホストするハイ パフォーマンス コンピューティング(HPC)クラスタに依存しています。オンプレミスの HPC システムは多大な設備投資を必要とし、長期にわたって高額の運用コストがかかります。また、多くの電力を消費し、ほぼ固定された構成を持ち、基盤となるコンピュータ ハードウェアも交換頻度が低いです。
このようなシステムに代わってクラウドを使用すると、柔軟性が向上し、ハードウェアが常時更新され、高い信頼性、地理的に分散したコンピューティングとネットワーキング、従量課金制の料金モデルが得られます。最終的には、クラウド コンピューティングにより、費用対効果を実現しつつ、気象予報士は最新のハードウェア システムとソフトウェア システムを使用して、柔軟なプラットフォームで正確な結果をタイムリーに伝えることができます。これは天気予報の従来の手法と比較すると大きな変化であり、困難に思えるかもしれません。これを支援するものとして、気象予報士は Fluid Numerics の新しい WRF VM イメージを使用して、Google Cloud で Weather Research and Forecasting(WRF)を簡単に実行し、オンプレミスのスーパーコンピュータのパフォーマンスをわずかなコストで実現できるようになりました。このソリューションを利用すると、気象予報士は WRF シミュレーションを Google Cloud で 1 時間もかけずに実行できます。
WRF の詳細
Weather Research and Forecasting(WRF)は、研究者と運営組織の両方が使用する一般的なオープンソースの数値天気予報モデリング システムです。WRF は主に気象と気候のシミュレーションに使用されますが、化学的要素との相互作用や森林火災モデリングなどのユースケースをサポートするよう機能が拡張されています。WRF の開発は、アメリカ大気研究センター(NCAR)、アメリカ海洋大気庁(NOAA)、アメリカ空軍、海軍調査研究所、オクラホマ大学、アメリカ連邦航空局と共同で 1990 年代後半に開始されました。WRF コミュニティは 160 か国 48,000 人を超えるユーザーで構成され、大気研究と業務予報の支援という目標を共有しています。
Google Cloud WRF イメージは Google の HPC 用 MPI ベスト プラクティスを使用して構築されています。ただし、ハイパー スレッディングはデフォルトでは無効になっておらず、Google Cloud の他の HPC ソリューション(SchedMD の Slurm-GCP など)と簡単に統合できます。通常、WRF とその付随要素のインストールには時間がかかりますが、この新しい WRF VM イメージを使用することで、WRF v4.2 プリインストール済みのスケーラブルな HPC クラスタのデプロイが、Google の Codelab ですばやく簡単に実行できます。この作業では OpenMPI 4.0.2 が使用されています。Google では、Intel MPI で良い結果を得られたため、さらにパフォーマンス向上が可能かどうかを研究する予定です。
WRF の最適化
WRF イメージの開発プロセスでは、パフォーマンスとコストに最適なアーキテクチャとビルド設定の決定が重要な鍵でした。Google は、理想的なコンパイラ、最適な CPU プラットフォーム、ファイル IO を処理するための最良のファイル システムの選択方法を評価しました。そのため、お客様はこの選択作業が必要ありません。パフォーマンス評価のテストケースとして、Google は CONUS 2.5 km ベンチマークを使用しました。
以下の CONUS 2.5 km ランタイムとコストの図は、Google Cloud で使用可能な異なるマシンタイプに 480 MPI ランク(プロセスの番号付け方法)を使用した 2 時間の予測における、WRF のシミュレーションに必要なランタイムを示しています。図では、各マシンタイプについて、コンパイラ、コンパイラ最適化、タスク アフィニティの異なる一連のテストで測定されたランタイムの中で、最も低いものを示しています。
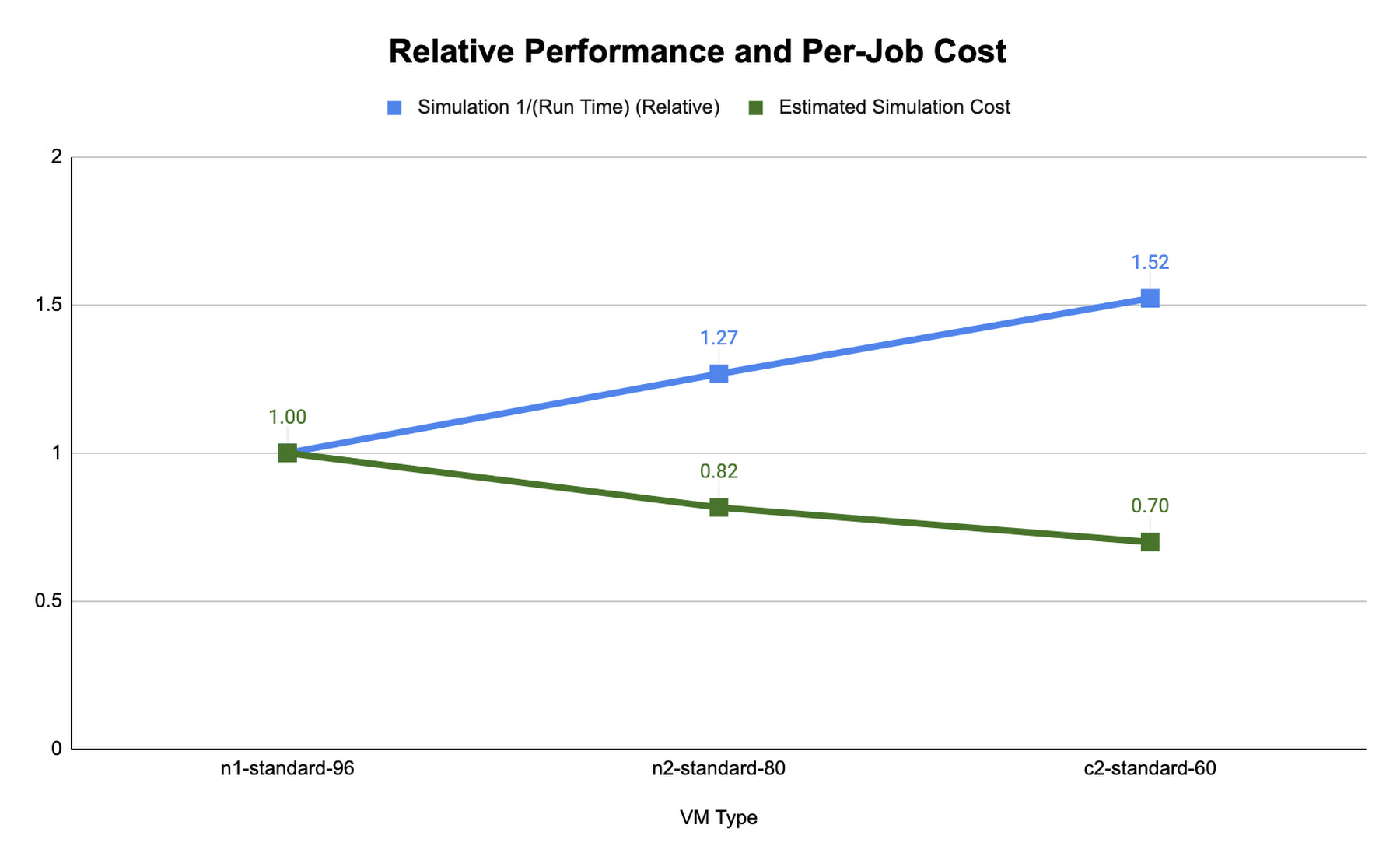
コンピューティングに最適化された c2 インスタンスのランタイムが最も短いことがわかりました。Slurm ジョブ スケジューラにより、MPI タスクをマッピングして、タスク アフィニティ フラグを使用するハードウェアをコンピューティングできます。各マシンタイプのランタイムとコストを最適化する際、WRF を起動する srun –map-by core –bind-to core と srun –map-by thread –bind-to スレッドを使用して比較しました。各 MPI プロセスは、前者では物理コア(各 MPI ランクに 2 つの vCPU)、後者では単一の vCPU にそれぞれマッピングされます。コアによるマッピングと MPI ランクのコアへのバインディングは、ハイパースレッディングの無効化に似ています。
それぞれのプラットフォームの CONUS 2.5 km に理想的なシミュレーション コストとランタイムは、各 MPI ランクに vCPU を登録すると実現できます。vCPUs へのバインディングでは、物理コアへのバインディングに比較して、必要なコンピューティング リソースは半分になります。これにより、シミュレーションの 1 秒あたりのコストも削減されます。また、CONUS 2.5 km では、MPI ランクをコアにマッピングすると同数の MPI ランクのランタイムが削減される一方、パフォーマンスの向上はコスト削減の効果を上回るほど大きくないこともわかりました。このため、WRF-GCP ソリューションは、デフォルトではハイパースレッディングを無効化していません。
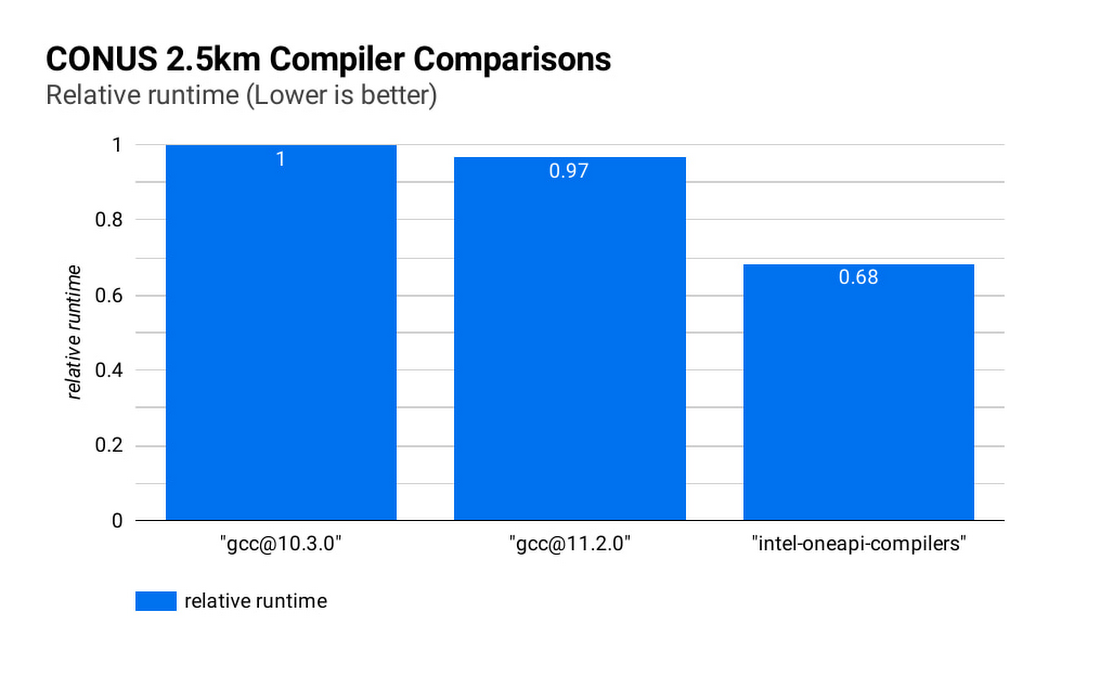
理想的なコンパイラを選択することでランタイムとシミュレーション コストをさらに削減できます。下の図(CONUS 2.5 km コンパイラの比較)は、8 個の c2-standard-60 インスタンスでの WRF CONUS 2.5 km ベンチマークのシミュレーション ランタイムを示しています。コンパイラは、GCC 10.30、GCC 11.2.0、Intel® OneAPI®(v2021.2.0)を使用しています。それぞれのコンパイラで WRF はレベル 3 コンパイラ最適化および Cascade Lake ターゲット アーキテクチャ フラグを使用してビルドされています。Intel® OneAPI® コンパイラで WRF をコンパイルすると、同じハードウェア上で WRF シミュレーションは GCC ビルドより約 47% 速く実行され、コストは約 68% です。各コンパイラで MPI 実装として OpenMPI 4.0.2 を使用しました。他のアプリケーションでは Intel MPI 2018 で優れたパフォーマンスが認められています。Google は、これと他の MPI 実装とのパフォーマンス比較を調査する予定です。
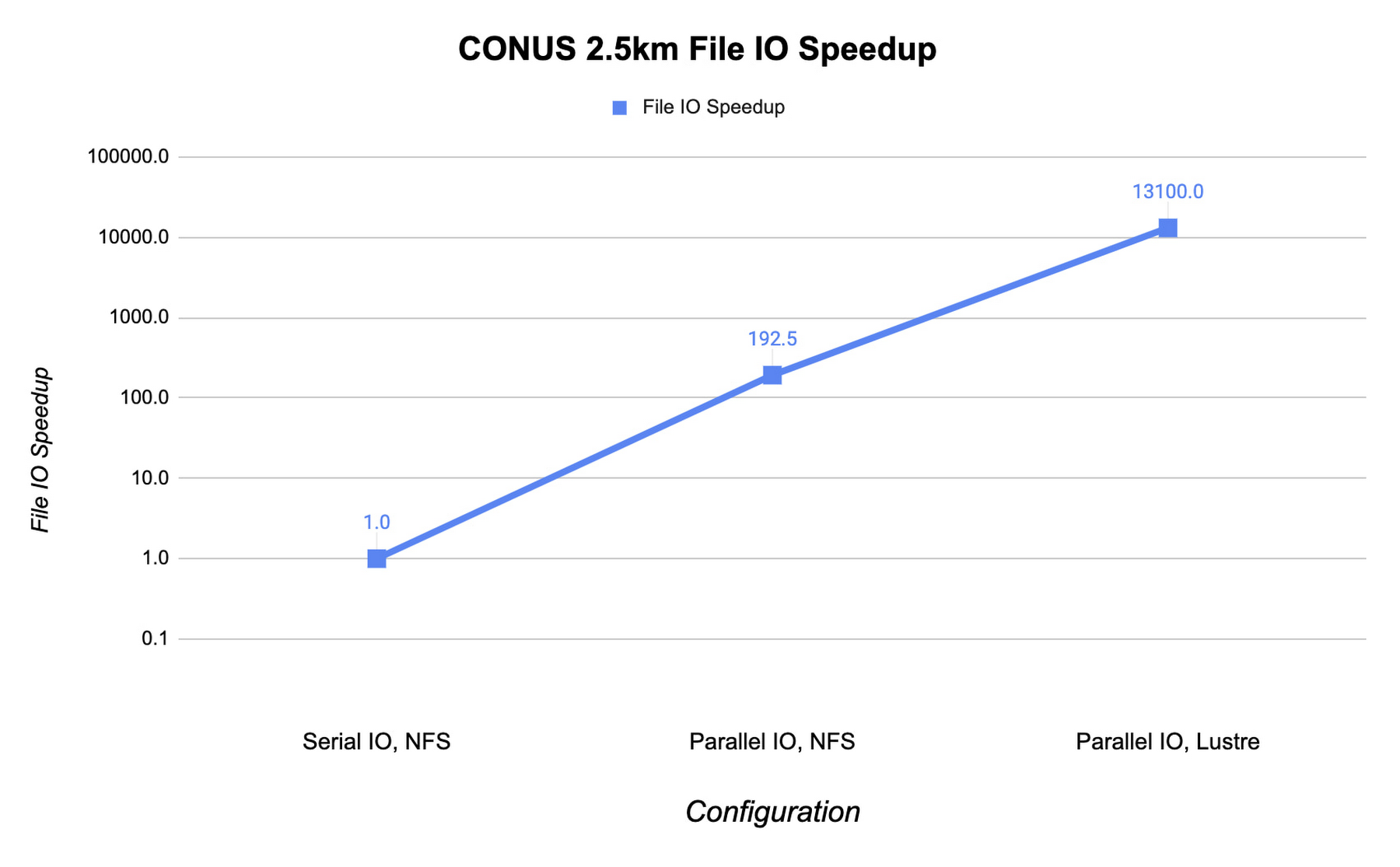
MPI ランクの数が増えるにつれて WRF のファイル IO が大きなボトルネックになる可能性があります。最適なファイル IO パフォーマンスを得るには、WRF で並列ファイル IO を使用し、Lustre などの並列ファイル システムを利用する必要があります。
以下は、NFS ファイル システムでのシリアル IO と比較したファイル IO アクティビティの速度向上を示しています。この例では、MPI ランク 960 の c2-standard-60 インスタンスで CONUS 2.5 km ベンチマークを実行しています。WRF のファイル IO ストラテジーを並列 IO に変更すると、ファイル IO 時間が 60 倍加速されます。
Fluid Numerics のオープンソース Lustre Terraform infrastructure-as-code からデプロイした Lustre 並列ファイル システムを使用すると、IO の速度がさらに向上し、シミュレーション コストも削減されます。また、Google Cloud Marketplace の DDN の EXAScaler ソリューションを使用することで、Lustre を利用することもできます。この場合、4 個の n2-standard-16 インスタンスを Lustre オブジェクト ストレージ サーバー(OSS)インスタンスに使用します。それぞれのローカル SSD は 3 TB です。Lustre メタデータ サーバー(MDS)は n2-standard-16 インスタンスで、PD-SSD ディスクは 1 TB です。Lustre ファイル システムをクラスタにマウントした後、Lustre ストライプ カウントを 4 に設定します。これにより、ファイル IO を 4 個の OSS インスタンスに分散できます。IO を Lustre ファイル システムに切り替えることで、ファイル IO の速度はさらに 193 倍上昇します。これは、シリアル IO での単一の NFS サーバーとは桁違いの速度向上です。
コンピューティング リソースの追加と MPI ランク数の増加により、シミュレーションの実行時間は短縮されます。理想的な完全な線形スケーリングを実現できれば、MPI ランクを倍にすることでシミュレーション時間は半分に短縮されます。しかし、MPI ランクを追加すると、通信オーバーヘッドも増大し、シミュレーションあたりのコストも増加します。通信オーバーヘッドは、多くのマシンで処理をさらに細かく分割するために必要な通信量が増加することで発生します。
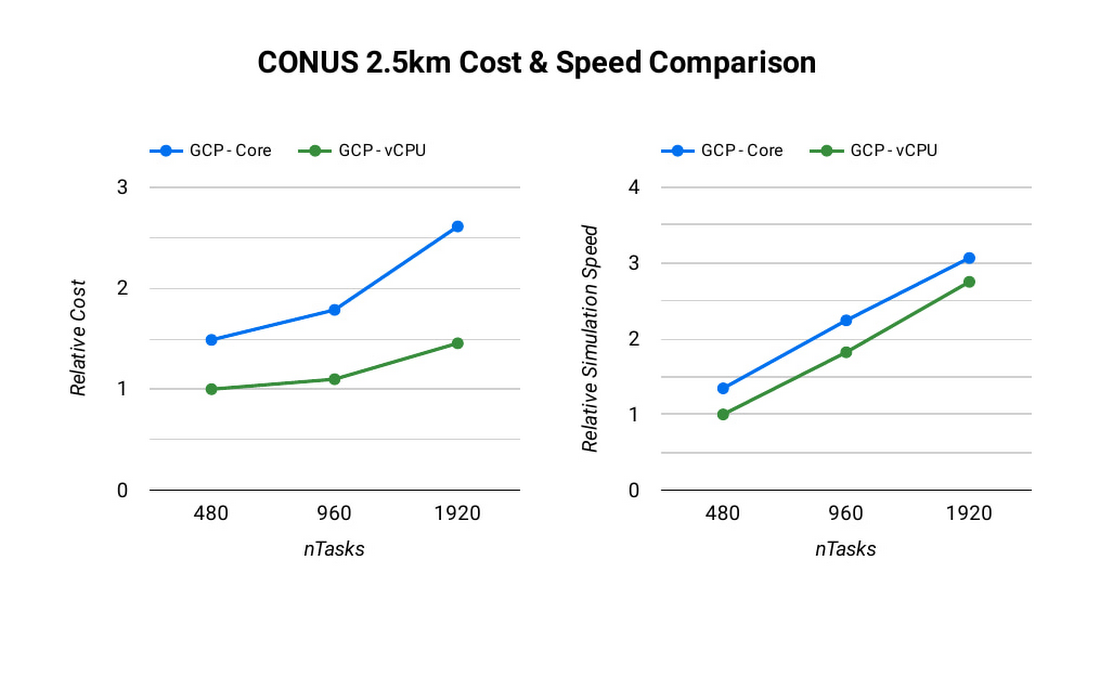
CONUS 2.5 km ベンチマークでの WRF のスケーラビリティを評価するため、MPI ランク数を 2 倍ずつ増やす一連のモデル予測を実行します。以下は、MPI ランク数を 480~1920 の間で変更した、Lustre ファイル システムを使用した c2-standard-60 インスタンスでの 2 時間の予測を示します。MPI ランクはそれぞれの実行で vCPU にバインディングされています。これにより、MPI ランクが増加するにつれて各シミュレーションのための vCPU の数も増加します。HPC ワークロードの多くは、同時マルチスレッディング(SMT)が無効化されているときに最適に動作します。一方、CONUS 2.5 km では、SMT が有効化されているときに最良のパフォーマンスが得られることがわかりました。このため、実行時の MPI ランク数は vCPU の合計数に等しくなっています。
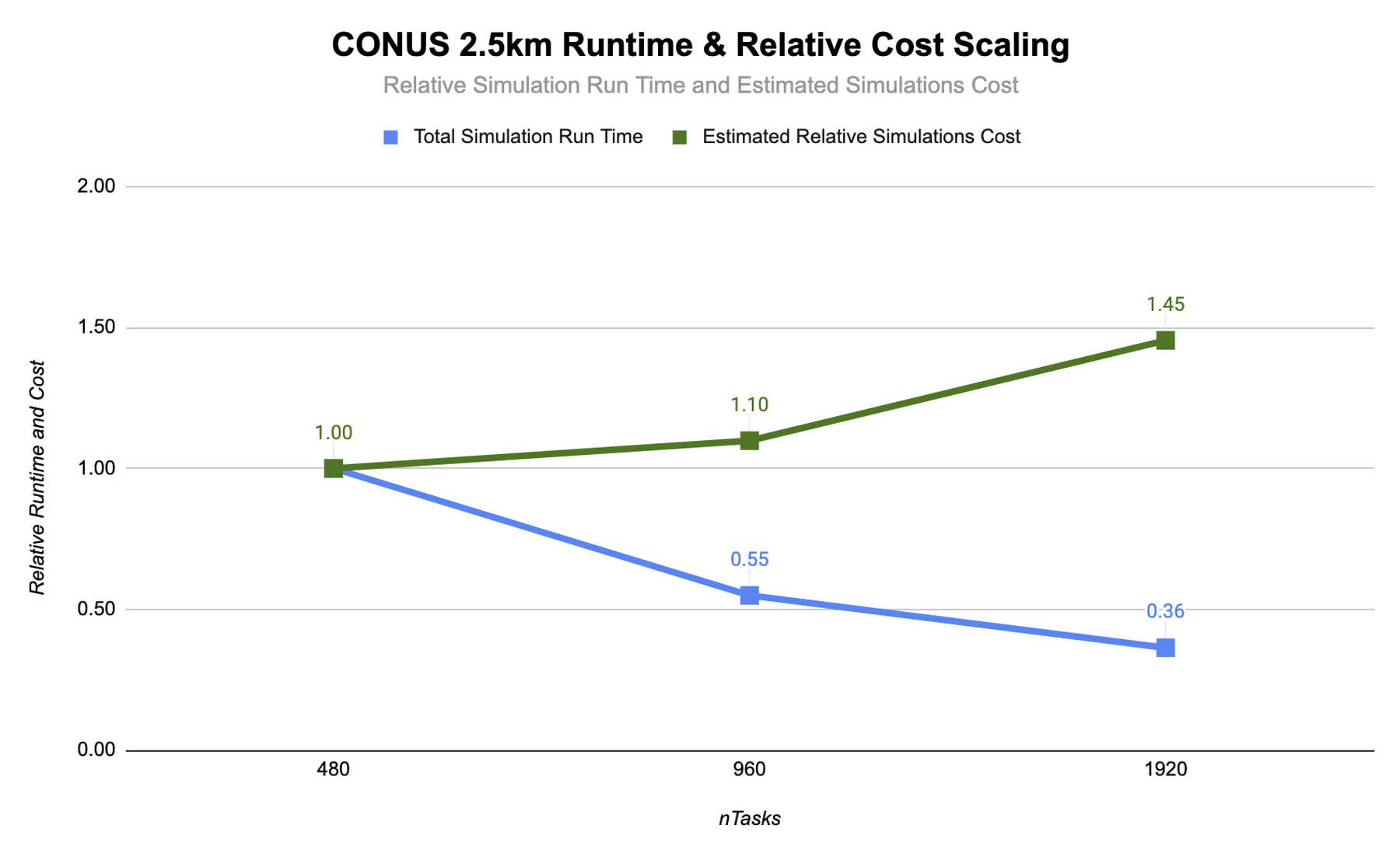
CONUS 2.5 km ランタイムとコスト スケーリングの図を見ると、MPI ランク数とコンピューティング リソースが上昇するにつれ、ランタイム(青色の棒線)が短縮することがわかります(少なくとも 1920 個のランクまで)。MPI ランクが 480 から 960 になると実行時間が短くなり、速度が約 1.8 倍上昇します。MPI ランクを再度 2 倍の 1920 にすると、速度の上昇は 1.5 倍のみになります。MPI ランクの増加に対してランタイムの速度向上が比例しない傾向は、MPI オーバーヘッドの特徴です。この傾向は、MPI ランクが増加するとともに強くなります。
最適な構成の決定
WRF のような密結合している MPI アプリケーションは、MPI ランクが増加するとスケーリング効率が減少する挙動を示します。このため、総所有コスト(TCO)の検討時には、パフォーマンスのスケーリングとともにコストのスケーリングの評価が重要です。Google Cloud での秒単位の課金によって、この種の分析が少し簡単になります。前述のように、960 コアから 1920 コアに数を倍増すると、速度は 1.5 倍上昇する一方でコストが 32% 増加します。状況によっては、追加コストがかかっても、このような速度上昇が必要かもしれません。
Google では、WRF をすぐに開始して CONUS 2.5 km ベンチマークで試せるように、このデプロイを Terraform スクリプトにカプセル化し、付随する Codelab を用意しました。
Google Cloud のハイ パフォーマンス コンピューティング商品に関する詳細は、https://cloud.google.com/hpc をご覧ください。また、Google のパートナーの Fluid Numerics に関する詳細は、https://www.fluidnumerics.com をご覧ください。
- Google Cloud HPC ソリューション マネージャー Wyatt Gorman
- Fluid Numerics 創設者兼オペレーション担当ディレクター Joe Schoonover 氏