機械学習によりリアルタイムの外国為替データの異常値を検出する方法
Google Cloud Japan Team
※この投稿は米国時間 2021 年 6 月 11 日に、Google Cloud blog に投稿されたものの抄訳です。
あなたはクオンツ トレーダーで、お気に入りのマーケット データ プロバイダからリアルタイムの外国為替(FX)の価格データにアクセスしているとします。おそらくデータ パートナーを利用したり、最初に合成データ生成ツールを使って値の有効性を確認したりしているでしょう。同じようなことをしようとしているクオンツ トレーダーは何千人もいるはずです。では他のトレーダーとの差別化を図るために、異常値検出ツールをどのように使用するべきでしょうか。
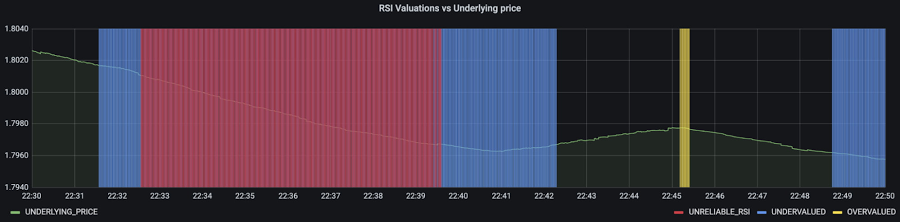
もし、生の FX 価格データで異常値検出ツールをトレーニングする代わりに、すでに定評がある売買シグナルを提供しているインジケーターで異常値を検出できるとしたらどうでしょうか。相対力指数(RSI)はそのようなインジケーターの一つで、一般に RSI が 70 を上回ると売りシグナル、30 を下回ると買いシグナルになると言われています。これはあくまでも簡易的なルールであるため、為替相場の調整時などにはシグナルが不正確になる場合があります。そしてこれこそが異常値検出ツールが最も役立つタイミングとなります。
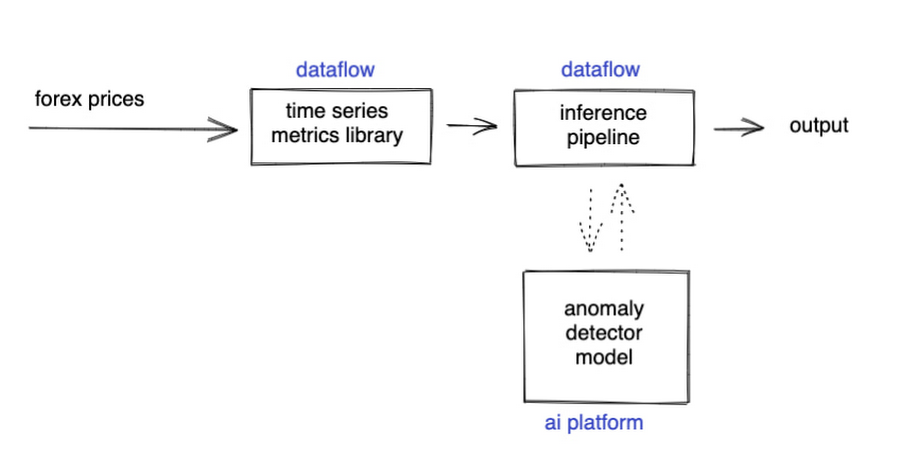
つまり、次のようなハイレベルなコンポーネントが考えられます。

これらのコンポーネントは、リアルタイムでデータを処理し、必要に応じて弾力的にスケールするのが望ましいのは言うまでもありません。Dataflow パイプラインや Pub/Sub は、そのための最適なサービスです。あとは、Apache Beam SDK の上にコンポーネントを記述するだけで、分散型で復元力のある、スケーラブルなコンピューティングの恩恵を受けることができます。
幸いなことに、すでに Apache Beam 用の素晴らしい Google プラグインがいくつかあります。具体的には、RSI の計算やその他多くの有用な時系列指標を含む Dataflow 時系列サンプル ライブラリと、Dataflow パイプライン内で AI Platform または Vertex AI 推論を使用するためのコネクタが備わっています。実線の矢印が Pub/Sub トピックを表すように図を更新してみましょう。
Dataflow の時系列サンプル ライブラリにはギャップ フィリング機能も備わっているため、フローが機械学習(ML)モデルに到達した後は、連続したデータの取得が可能になります。これにより、極めて複雑な ML モデルを実装できるため、懸念となるエッジケースが 1 つ減ります。
ここまで、リアルタイム データのフローについてのみ説明してきましたが、可視化や ML モデルの継続的な再トレーニングには過去のデータも必要になります。BigQuery をデータ ウェアハウスとして使用し、Dataflow を使用して Pub/Sub をその中に組み込んでみましょう。この組み込み作業では高度な並列処理が可能なので、データタイプに関係なく汎用的に使えるようにパイプラインを記述し、同じ Dataflow ジョブを共有することで、コンピューティング リソースを共有できるようにしました。これにより、コスト削減とスケールアップに必要な時間の両方において、スケールの効率化が実現します。
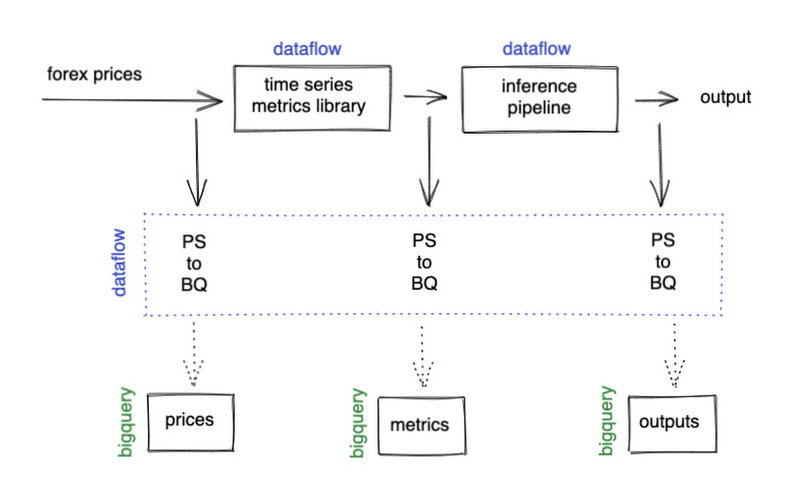
データ モデリング
ここでは、データ形式についてもう少し詳しく見ていきます。データ エンジニアリング プロジェクトを大規模に実施するうえで重要なのは、柔軟性、相互運用性、デバッグの容易さです。そのため、人間が読むことができ、ツールが普遍的に理解できるフラットな JSON 構造を各データタイプに対して使用することにしました。BigQuery もこれを理解できるため、BigQuery コンソールで、プロジェクトの各コンポーネントが期待どおりに動作しているかを簡単に確認できます。
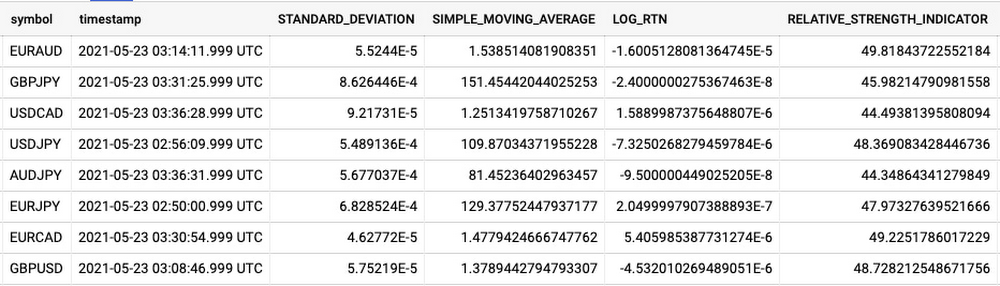
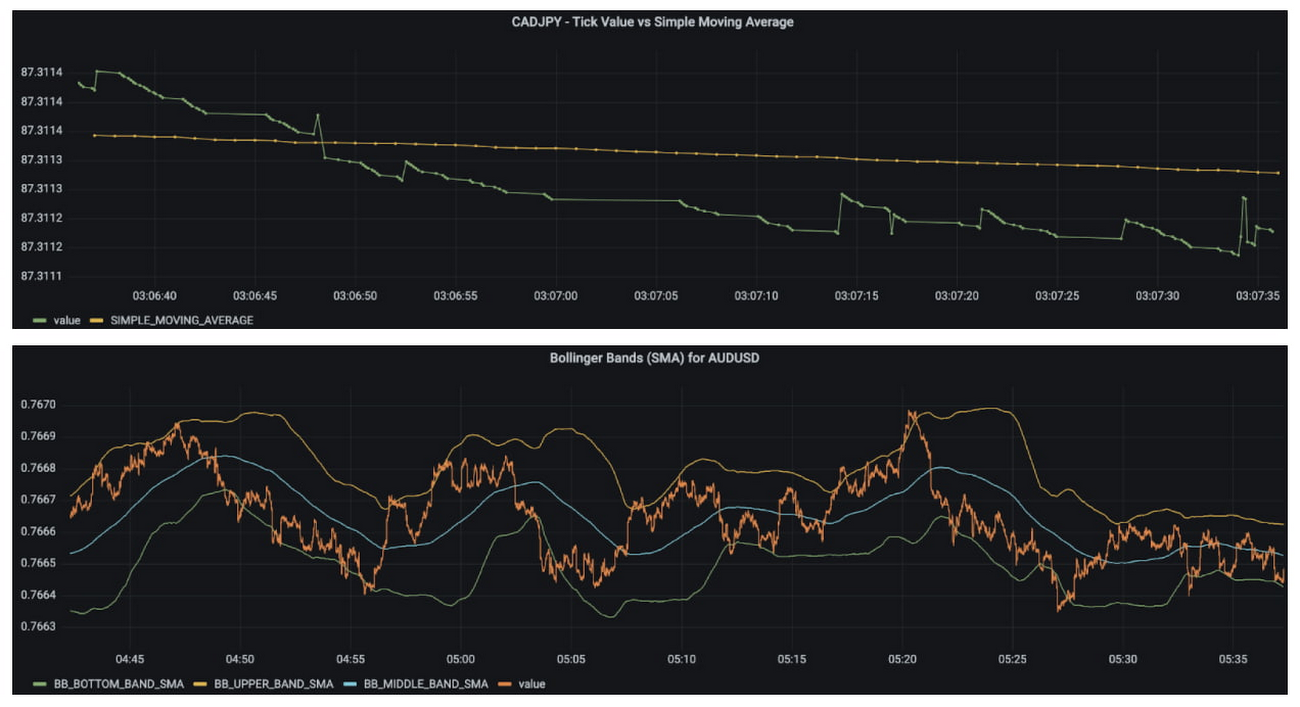
ご覧のように、Dataflow のサンプル ライブラリは RSI よりも多くの指標を生成できます。このライブラリは、時系列のウィンドウを対象とした 2 種類の指標の生成をサポートしています。順序付けされていないウィンドウで算出可能な指標と、順序付けされたウィンドウを必要とする指標です。ライブラリでは、これをそれぞれタイプ 1 指標、タイプ 2 指標と呼んでいます。順序付けされていない指標は多対一の関係を持っていて、時間経過に伴うポイントの数を減らすことでデータのサイズを小さくすることができます。順序付けされた指標は、順序付けされていない指標の出力に基づいて実行され、分解能を損なうことなく時間領域を通じて情報を伝えるのに役立ちます。追加設定なしでサポートされている指標の包括的なリストについては、Dataflow サンプル ライブラリのドキュメントをご覧ください。
今回の出力は人間のクオンツ トレーダーが解釈するので、順序付けされていない指標を使い、リアルタイム データのフローの時間分解能を 1 秒あたり 1 回(1 ヘルツ)に下げてみましょう。自動売買のアルゴリズム向けに出力する場合は、より高い頻度を選択する可能性があります。順序付けされた指標ウィンドウのサイズを決定するのはやや難しいものの、大まかには ML モデルがコンテキストに対して持つタイムステップの量を決定し、結果として異常検出に関連する時間枠を決定します。少なくとも、クオンツ トレーダーが行動を起こす時間を確保するには、エンドツーエンドのレイテンシよりも長い時間が必要になります。ここでは 5 分に設定します。
データの可視化
ML モデルについて見ていく前に、指標で起こっていることをより直感的に感じられるように可視化し、これまでに得たものがすべて機能していることを確認してみましょう。Google Kubernetes Engine(GKE)の Autopilot クラスタで、Grafana の Helm チャートと BigQuery プラグインを使用します。可視化の設定は完全に構成主導型であり、追加設定なしのスケーリングが可能になります。また、GKE は他のコンポーネントを後でホストするための場所を提供してくれます。
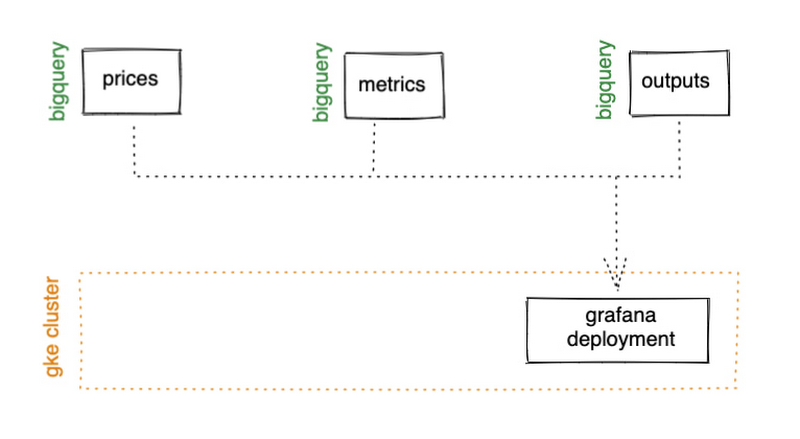
GKE Autopilot では、デフォルトで Workload Identity が有効になっているため、BigQuery へのアクセス時に機密情報を渡すことを心配する必要がありません。代わりに BigQuery への読み取りアクセスが可能な GCP サービス アカウントを作成し、リンクされた Kubernetes サービス アカウントを介してデプロイメントに割り当てることができます。
これで、Grafana ダッシュボードにいくつかのパネルを作成し、ギャップ フィリングや指標がリアルタイムで機能しているのを確認できます。
機械学習モデルの作成とデプロイ
では、機械学習の説明に入ります。先ほど触れたように、新たなデータが得られれば、ML モデルを継続して維持し、引き続き市場の最新のトレンドに対応させたいと考えています。TensorFlow Extended(TFX)は、エンドツーエンドの機械学習パイプラインを本番環境で作成するためのプラットフォームであり、再利用可能なトレーニング パイプラインの構築に伴うプロセスを容易にします。また、AI Platform や Vertex AI に公開するための拡張機能もあり、Dataflow ランナーも使用できるため、Google のアーキテクチャにも適しています。TFX パイプラインにはまだオーケストレーターが必要なので、それを Kubernetes のジョブでホストできます。また、それをスケジュールされたジョブでラップすれば、再トレーニングもスケジュールどおりに行うことができます。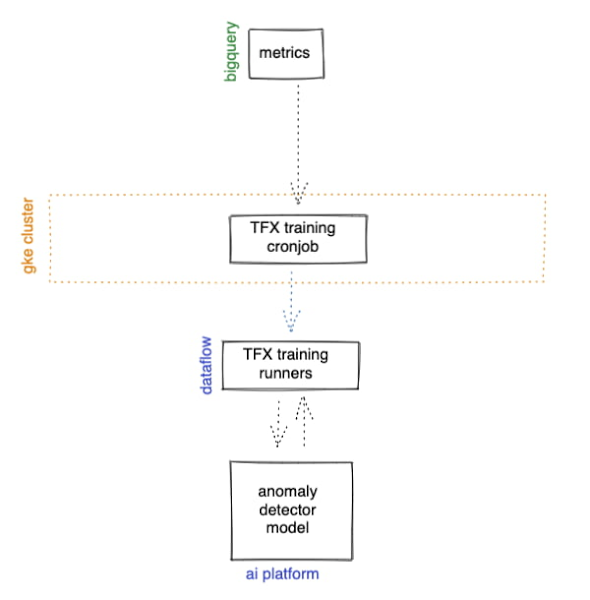
TFX では、データは tf.Example 形式にする必要があります。Dataflow のサンプル ライブラリは tf.Examples を直接出力できますが、これは 2 つのパイプラインを密結合します。複数の ML モデルを並行して実行したり、既存の履歴データを基に新しいモデルをトレーニングしたりするには、パイプラインを疎結合にする必要があります。デフォルト TFX BigQuery アダプタを使用する方法もありますが、この場合、BigQuery の各行がちょうど 1 つの ML サンプルにマッピングされるように制限されるため、リカレント ネットワークを使用できなくなります。
追加設定なしで使えるソリューションのいずれも要件を満たしていなかったので、必要なことを実現してくれるカスタム TFX コンポーネントを記述することにしました。カスタム TFX BigQuery アダプタを使うことで、標準的な JSON データ形式を BigQuery に保持したままリカレント ネットワークをトレーニングし、パイプラインを疎結合に保つことができます。トレーニング時間と推論時間の両方で、ウィンドウ処理ロジックを同じにする必要があります。そのため、Beam の標準的なコンポーネントを使ってカスタム TFX コンポーネントを構築し、同じコードを両方のパイプラインでインポートできるようにします。
カスタム生成ツールが完成したので、異常値検出モデルの設計を開始できます。今回の時系列のユースケースでは、長短期記憶(LSTM)を利用したオートエンコーダが適しています。オートエンコーダによってサンプルの入力データを再構成してみることで、それがどれだけ近づくかを測定できます。この差は、再構成誤差と呼ばれます。十分に大きな誤差がある場合、そのサンプルを異常値と呼びます。オートエンコーダの詳細については、Ian Goodfellow、Yoshua Bengio、Aaron Courville 著『Deep Learning』の第 14 章をお読みください。
ここでのモデルでは、入力と出力の特徴として単純移動平均、指数移動平均、標準偏差、ログリターンを使用しています。エンコーダとデコーダのサブネットワークには、それぞれ 32 個と 16 個のニューロンを備えた 30 タイムステップ LSTM を 2 層配置しています。
Google のトレーニング パイプラインには、前処理の変換として z スコアのスケーリングが含まれています。これは通常、機械学習において推奨される方法ですが、異常値検出にオートエンコーダを使う際には、少し違いがあります。再構成誤差を算出するには、モデルの出力だけでなく、入力も必要です。これについては、モデル提供関数を使用して、モデルが出力と前処理された入力の両方をレスポンスの一部として返すようにすることで実現しています。TFX では、トレーニングされたモデルを AI Platform に push する機能がデフォルトでサポートされているので、push 側を構成するだけで、トレーニング(再トレーニング)コンポーネントが完成します。
異常値をリアルタイムで検出する
Google Cloud AI Platform にモデルを用意できたので、推論パイプラインでモデルをリアルタイムで呼び出す必要があります。データは標準の JSON を使用しているため、RSI の経験則をインラインで簡単に適用して、必要な場合のみモデルを実行できます。AI Platform で再構築された出力を使用して、再構成誤差を算出することができます。これを Pub/Sub に直接ストリーミングすることで、可視化の際に異常しきい値を動的に適用できるようにしましたが、静的なしきい値がある場合は、それをここで適用することも可能です。
まとめ
広範なアーキテクチャは、次のようになりました。
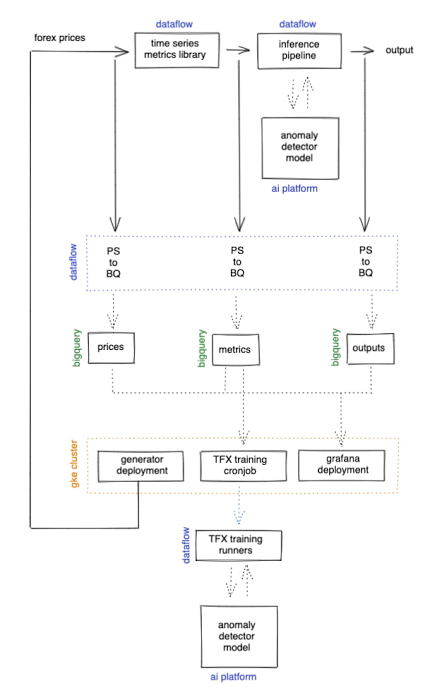
さらに重要なのは、これが私たちのユースケースに適しているかということです。異常値検出ツールの再構築誤差を標準の RSI の売買シグナルに対してプロットしてみると、モデルによって、経験則を盲目的に信頼すべきではないことが示されているタイミングを確認できます。クオンツ トレーダーの皆様のご健闘をお祈りいたします。
次のステップとして、今回取り上げた内容をさまざまなことに応用してみましょう。複数通貨のモデルを使って、相関する通貨の値動きが予想外となるタイミングを検出したり、すべての Pub/Sub トピックを可視化ツールに接続してリアルタイムのダッシュボードを提供したりすることもできます。
お試しください
最後に、リポジトリをクローンして自分の環境ですべてを設定できるよう、実際の取引所にアクセスすることなく FX データを生成できるデータ シンセサイザーを用意しました。お察しのとおり、これも GKE クラスタ上でホストしています。他にも多くの機能があります。TFX は SQL データベースを使用し、アプリケーション コードはすべて Docker イメージにパッケージ化されて Terraform と Cloud Build によりインフラストラクチャと一緒にデプロイされます。これらの詳細にご興味がありましたら、リポジトリにアクセスしてクローンを作ってみてください。
このパターンを貴社向けに最適化するためのサポートが必要な場合は、Google Cloud チームと Kasna チームまでお気軽にお問い合わせください。
-Kasna 最高技術責任者 Troy Bebee
-Google Cloud データ分析担当アウトバウンド プロダクト マネージャー David Sabater



{kind=link}
{kind=link}