Strise が生成 AI でマネー ロンダリング防止(AML)を強化
Adrian Trzeciak
Engineering Manager, Strise
※この投稿は米国時間 2024 年 6 月 15 日に、Google Cloud blog に投稿されたものの抄訳です。
Strise とは
金融機関にとって、国内外の法令遵守にかかる費用は大きな負担となっており、規制機関の厳しい監視に対応するため、銀行業界は 2,000 億ドル以上を費やしています。このプロセスを容易にして負担を軽減するため、Strise は北欧の大手金融機関や急成長中のフィンテック企業からも信頼されるマネー ロンダリング防止(AML)インテリジェンス システムを構築しました。AI を活用した当社のプラットフォームは、AML をリソースの浪費から成功戦略へと変革し、コンプライアンス チームが金融犯罪と戦うために必要なツールを提供します。
実際にはどのような手段が使用されているのでしょうか。毎日起こる数百万のイベントのうち、特定の企業や個人に関係するものはほんの一握りです。Strise は、最先端の自然言語処理(NLP)研究と AI を活用したプラットフォームを組み合わせて、不要な情報を除去し、お客様にとって最も重要なイベントを特定します。
生成 AI が KYC と AML にもたらす可能性
生成 AI には、顧客理解(KYC)とマネー ロンダリング防止(AML)の手続きを改善する大きな可能性があります。時間とコストがかかり、ミスも発生しやすい KYC と AML の手作業のチェックに苦労している金融機関は、AI がもたらすスピード、効率性、精度の恩恵を受けながら、コンプライアンスを維持できます。
生成 AI の力と数十億のパラメータを含む大規模学習モデル(LLM)を組み合わせることで、KYC と AML のプロセスが最適に自動化されます。これらのモデルの力が追加され、データの収集、検証、リスク評価が効率化されます。これにより、新規顧客のオンボーディングの加速、カスタマー エクスペリエンスの向上、エラー率の低減が実現するだけでなく、現在手作業によるチェックで費やされている数十億ドルを節約できる可能性があります。LLM はデータ処理タスクの精度と信頼性を大幅に高めることもできます。これは、AML を適用するにあたり極めて重要なことです。こうしたテクノロジーにより、テキストデータから詳細な感情分析を実行する能力が強化され、膨大な情報をより高い精度で処理できるようになります。
以上から、マネー ロンダリング活動の兆候となりうる企業や個人に関連するデータポイントの処理についてさらなる可能性が生まれています。企業がバラバラに見えるデータをより正確に結び付けられるようになり、企業を金融犯罪から守るだけでなく、規制遵守を徹底し、多額の罰金や評判の失墜を回避できます。
Vertex AI を選んだ理由
当社は当初から Google Cloud を全面的に信頼しており、スタック内で幅広い Google サービスを活用しています。規制の厳しいこの業界では、データのローカライズ、暗号化、セキュリティ、EU 規制の遵守に関して、各市場に独自の要件があります。Google Cloud ベースのサービスと、Vertex AI およびその LLM が緊密に統合され、IAM とガバナンス機能を備えていることで、これらのサービスを本番環境に移行するプロセスを大幅に短縮できます。
Google Cloud は、LLM に関する当社の取り組みの推進に大きく役立っており、チーム向けの教育用コンテンツや業界固有のアドバイスが提供されるため、お客様に合わせたプロダクトやサービスのカスタマイズを大規模に継続できます。
生成 AI の用途
ユーザー エクスペリエンスの円滑化Strise は、シンプルかつエレガントなプロダクトの開発に注力しています。視覚的な魅力があり、使いやすいソフトウェアに惹かれるのが人間の本能です。これまでの経験上、シンプルなものより複雑なユーザー エクスペリエンスを好むというお客様には会ったことがありません。
KYC は複雑で、複数のシステムにまたがる複雑なプロセスが多いため、シンプルなインターフェースを構築するのが難しくなります。こうした壁に直面した場合、当社では一時的に使いやすさを犠牲にしても、最も厳しい規制基準を維持することを最優先に取り組んでいます。
膨大な数のメニューやオプションを移動することなく、必要なことを伝えるだけでよい世界を想像してみてください。そうなれば、人間とテクノロジーの関係性が根本的に変わり、膨大な時間が節約され、シームレスなユーザー エクスペリエンスが実現します。
この新しい現実はもうすぐ訪れると確信しています。Strise が、自社アプリの現行機能内でお客様の目標達成を支援する LLM ベースの AI Co-Pilot を開発しているのはそのためです。アプリの一部領域では、Co-Pilot が標準インターフェースの代わりになります。
たとえば、当社は銀行の顧客ポートフォリオを継続的にモニタリングする機能を開発しています。個人や企業が新しい財務情報、規制の最新情報、重要な公的地位を有する者の情報の変更といった新規データを取得すると、銀行の調査員に対して審査プロセスが自動的にトリガーされます。簡単そうに聞こえますが、このソリューションでは複数のトリガーを 1 つに統合できるため、基本的に「規制情報の変更と新しい EBITDA マージンがある高リスクの会社すべてにトリガーを設定したい」と伝えることになります。
似たような設定を手動で行う場合は、複数のプルダウンから情報を組み合わせ、スクロールして正しい選択肢を見つける必要があります。もしくは「規制情報の変更と新しい EBITDA マージンがあるすべての高リスクの会社」と入力して、LLM がそのリクエストを処理し、対応する一連のトリガーに変換します。
ではなぜ、もっと先に進まないのでしょう。アプリケーション全体をシンプルなプロンプトにできないのでしょうか。当社は今後、必要なクリック数の削減と、クリックベースからプロンプト ベースへのフローの変換をぜひ試してみるつもりです。
コードの生成膨大な量のイベントを毎日処理するには、さまざまなデータソースをすばやく結びつける必要があります。しかし、ソース コンテンツを有用な形式にマッピングするプロセスは繰り返しでつまらないため、これを好むエンジニアはいません。プロセスの中でエンジニアは次のことを行います。
-
API 仕様と利用可能なエンドポイントの確認
-
テスト用のリクエスト ペイロードの生成とレスポンスの分析
-
マッピング ロジックの開発とインテグレーション
Strise が最近実施した LLM ハッカソンの一つで、自社の基準に従って、コードを 1 行も書かない新しいインテグレーションのための Scala コードの生成に取り組みました。プロンプトでサンプルのペイロードとレスポンスを受けとり、既存のライブラリを使用してインテグレーションを実行する Scala コードを生成します。そこから、エンジニアは pull リクエストを送信するだけです。
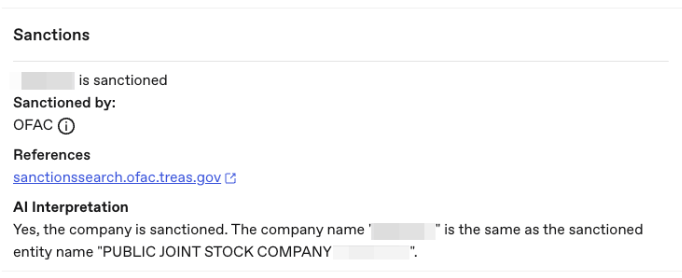
偽陽性の削減 KYC プロセスは、特定の企業や個人に関する情報を入手できるかどうかに大きく左右されます。情報が正しく表示されない場合、お客様との取引ができなくなる可能性があります。一方、情報が不足している場合、除外対象のお客様と取引してしまう可能性があります。
企業や個人が規制対象かどうかの判定は、コンプライアンス ソリューションの重要な要素です。この方法は偽陽性の数が多くなるかもしれませんが、コンプライアンス担当者が結果を解釈できます。LLM を使用する場合は、当事者情報と特定された規制レコードを Vertex AI に送信できます。プロンプトに加えて、入出力のサンプルの小さなデータセットを送信することで、それが真陽性か、偽陽性かについての PaLM の解釈とその説明を取得できます。
当社の非技術系チームは、生成 AI を使った新しいアイデアやユースケースを日々模索しており、それが課題に立ち向かい、ワークフローを見直す意欲につながっています。Google Cloud の使いやすさによって、非常に複雑な大規模言語モデルを一般ユーザーでも利用できるようハードルが下がったことで、想像もできないような生産性の変革が続いています。従業員が生成 AI を使用してデータベースのクエリを実行するための chatbot を構築する場合も、データログを実用的なインテリジェンスに要約するための chatbot を構築する場合も、Google Cloud パートナーがサポートしてくれます。
-Strise、エンジニアリング マネージャー Adrian Trzeciak 氏



