安全でコンプライアンスに対応した ML / AI を導入するための Vertex AI の基盤
Google Cloud Japan Team
Vertex AI プラットフォームのセキュリティを確保し、本番環境ワークロード対応のエンドツーエンドの ML / AI プラットフォームとして活用する
※この投稿は米国時間 2023 年 1 月 24 日に、Google Cloud blog に投稿されたものの抄訳です。
他社との差別化、収益の拡大、費用の削減、効率の最大化を目的に、自社の変革を達成するために重要な要素として ML / AI を導入する企業のお客様が増加し続けています。多くのお客様にとって、ML / AI の導入は難易度の高い取り組みです。その理由としては、ML / AI でサポートできるアプリケーションが多岐にわたるためにどのアプリケーションを優先するかを決定するのが難しいということが挙げられます。それだけでなく、ML / AI ソリューションを本番環境に移行するには、セキュリティ、アクセス、データに関する一連の評価を行う必要があり、場合によっては ML / AI プラットフォームにはない機能が必要になる場合があることも、ML / AI 導入の難易度を高くしています。このブログ投稿では、将来の機械学習オペレーション(MLOps)と ML / AI のユースケースに適した Vertex AI の基盤を構築できるようにするために、特に Vertex AI Platform と、その構成に対応する Cloud 基盤をセットアップする方法を取り上げます。
このブログ投稿では取り上げませんが、説明可能性は、本番環境対応の ML システムの実務担当者にとって考慮すべき重要な要素のうちの一つです。特徴量を基にした説明方法、特徴アトリビューション方式(サンプリングされた Shapley、統合勾配、XRAI)、微分可能モデルと微分不可能モデルについて詳しくは、Vertex Explainable AI をご確認ください。
現時点で Vertex AI を構成するサービスの数は 22 を超えていますが、ここではシンプルに次の 5 つのコアサービスを取り上げ、エンドツーエンドの機械学習プロセスを確立し、お客様の業務で活用するために役立つ情報をお伝えします。
Vertex AI Workbench
Vertex AI Feature Store
Vertex AI Training
Vertex AI Prediction
Vertex AI Pipelines
Vertex AI エンタープライズ ネットワーキング アーキテクチャのリファレンス
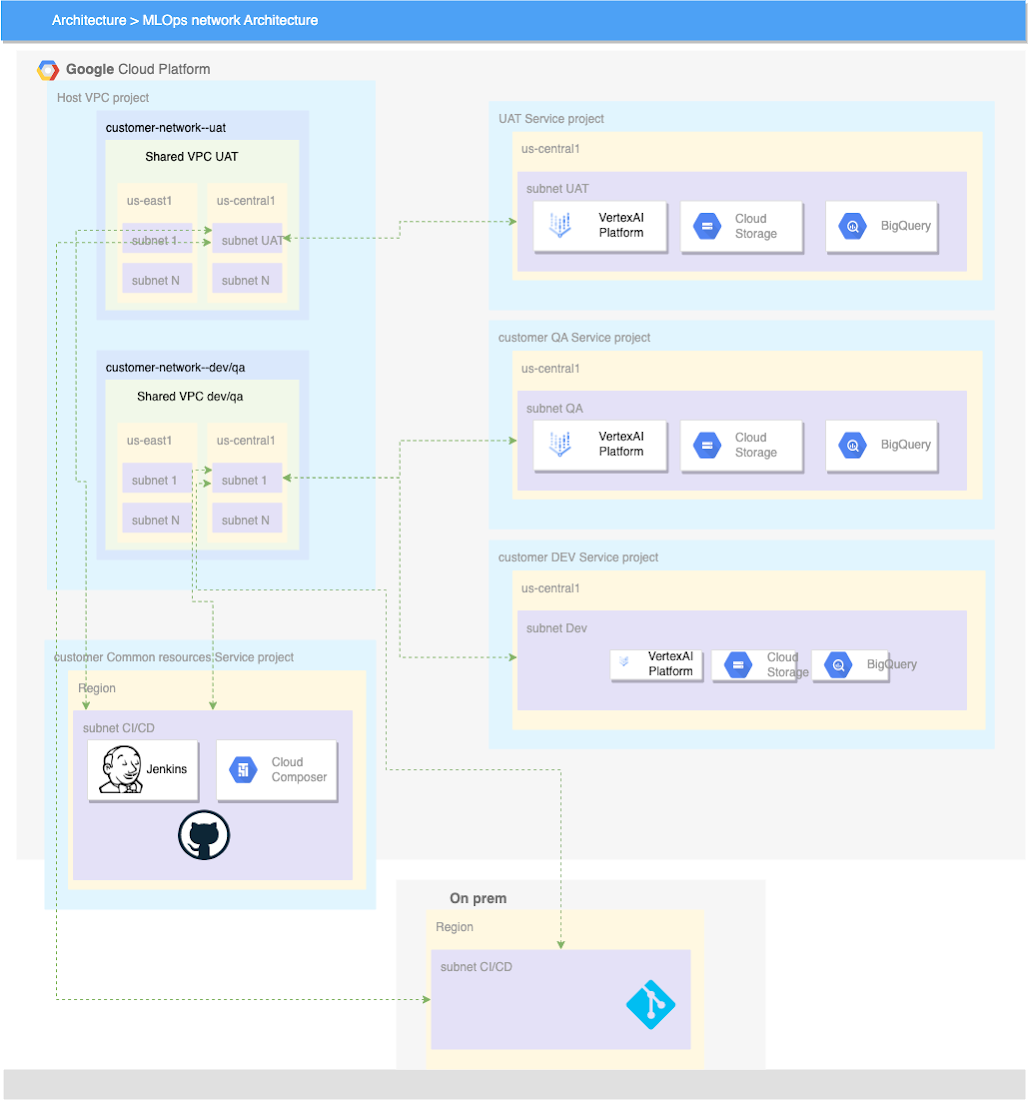
重要な要素の一つは、開発環境、ユーザー受け入れテスト / 品質保証(UAT / QA)環境、本番環境をどのように確立すべきかを理解することです。ある環境から別の環境に移行するときには誰しも、可能な限り外部アクセスを制限して、自動化したいと思うことでしょう。こうした移行の時点から、コードを本番環境に公開するという点において、ML / AI はソフトウェア開発ライフサイクルと非常に似通ったものになります。DevOps Research and Assessment(DORA)、開発オペレーション(DevOps)、機械学習オペレーション(MLOPs)に慣れ親しんでおられる方なら、継続的に安全かつ確実にコードをリリースしてビルドするために、継続的インテグレーションと継続的デリバリーが両方のフレームワークでどのように適用されるのかがおわかりになるでしょう。
Vertex AI 機械学習オペレーション
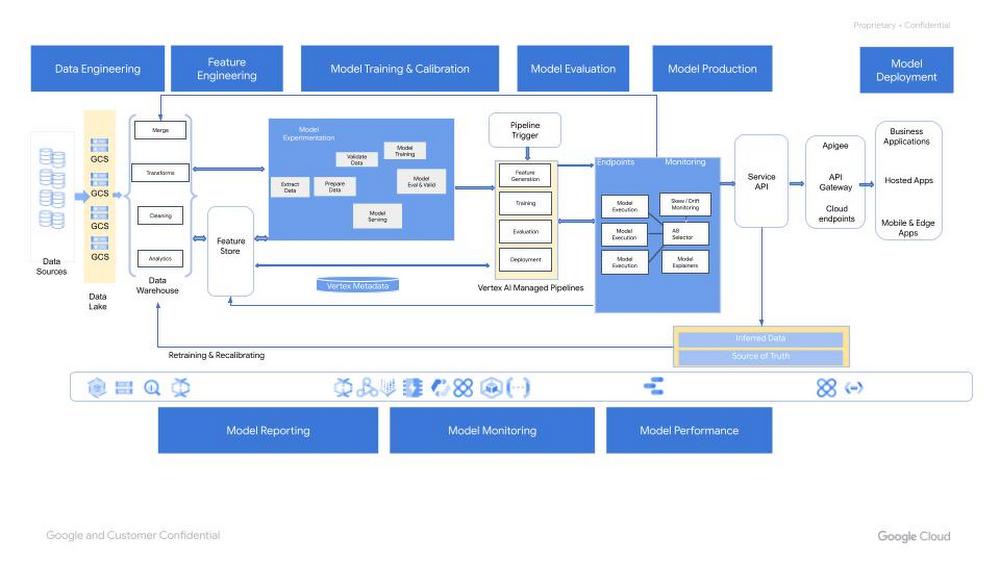
自動化された信頼性の高い方法で複数の環境にソフトウェアをリリースできるようにするために、機械学習オペレーションには DevOps の多数の要素が取り入れられます。MLOps への移行のどの段階にあるのかは企業によって異なるとは思いますが、IDC の調査研究をはじめとする多くの調査研究によると、ML / AI プロジェクトの投資収益率(ROI)の多くは、本番環境に移行する段階が占めています。
DevOps は、大規模なソフトウェア システムの開発と運用における一般的な手法です。この手法には、開発サイクルの短縮、開発の迅速化、信頼性の高いリリースが可能になるなどの利点があります。これらの利点を享受するには、ソフトウェア システム開発における次の 2 つのコンセプトを導入します。
ML システムはソフトウェア システムであるため、同様の手法を適用すれば、ML システムの大規模なビルドや運用がより確実になります。ただし、MLOps は次の点で DevOps とは異なることを理解する必要があります(「MLOps: 機械学習における継続的デリバリーと自動化のパイプライン | Cloud アーキテクチャ センター」)。
チームのスキル: ML プロジェクトのチームには通常、探索的データ分析、モデル開発、テストに注力する、データ サイエンティストや ML 研究者が含まれます。これらのメンバーが、本番環境クラスのサービスをビルドできる経験豊富なソフトウェア エンジニアであるとは限りません。
開発: ML には実験的性質があります。問題を解くのに最適な方法をできるだけ早く見つけるために、さまざまな機能、アルゴリズム、モデリング手法、パラメータ構成を試す必要があります。これを行ううえで課題となることは、何が機能し、何が機能しなかったかを追跡すること、そしてコードの再利用性を最大化しながら再現性を維持することです。
テスト: ML システムのテストは、他のソフトウェア システムのテストよりも複雑です。一般的な単体テストと統合テストに加えて、データ検証、トレーニングされたモデルの品質評価、モデルの検証が必要になります。
デプロイ: ML システムでのデプロイは、予測サービスとしてオフラインでトレーニングした ML モデルのデプロイのようにシンプルではありません。ML システムでは、モデルの再トレーニングとデプロイが自動で行われるように、複数のステップからなるパイプラインをデプロイしなければならない場合があります。このパイプラインにより複雑さが増します。さらに、データ サイエンティストがパイプラインをデプロイする前に、新しいモデルをトレーニングし検証するため、手動で行われている手順を自動化する必要があります。
本番環境: ML モデルは、最適化されていないコーディングだけでなく、絶えず発展しているデータ プロファイルが原因でパフォーマンスが低下する可能性があります。つまり、モデルの劣化につながる要因は従来のソフトウェア システムよりも多く、こうした要因による性能低下を考慮しなければなりません。そのため、データの統計情報の概要を追跡し、モデルのオンライン パフォーマンスをモニタリングして、値が想定と異なる場合に通知を送信するかロールバックする必要があります。
Vertex AI Workbench - ユーザー管理
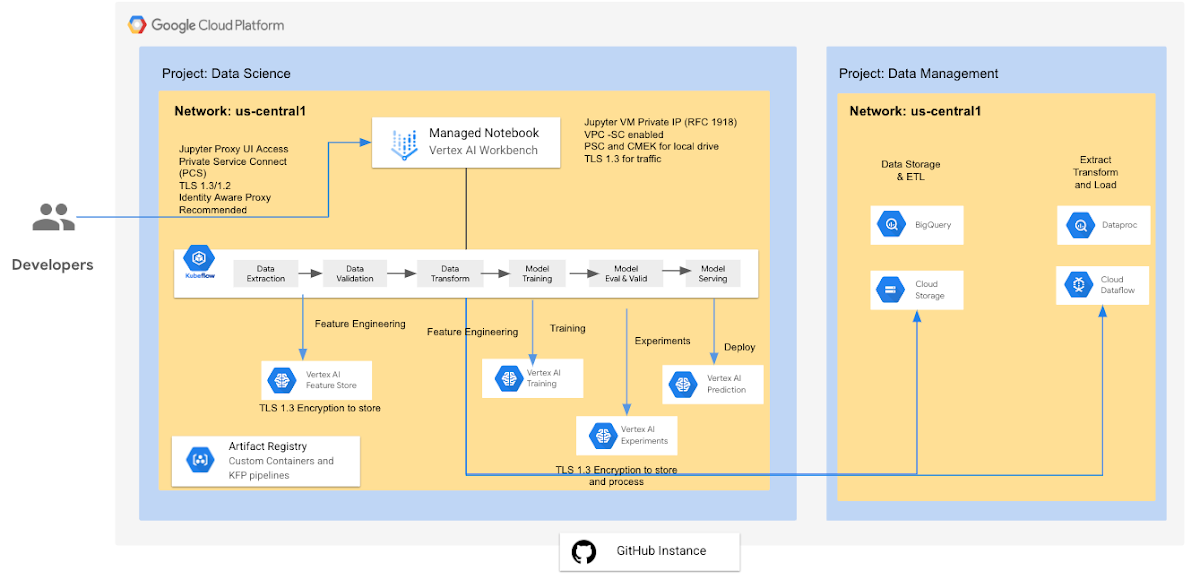
ユーザー管理のノートブックは、JupyterLab ノートブック環境が有効になっており、直ちに使用を開始できる Deep Learning VM Image インスタンスです。このページで、ユーザー管理のノートブック インスタンスの環境をアップグレードする方法について説明しています。Google Cloud 内のユーザー管理のノートブック上で Jupyter ノートブックを実行している場合、インスタンスは Vertex AI Workbench によって管理される仮想マシン(VM)上で動作します。Jupyter ノートブックから、BigQuery と Google Cloud Storage のデータにアクセスできます。セキュリティを強化するには、Workbench ノートブックのコンピューティング インスタンスとして Shielded VM を実行します。ログビューアを介したコンシューマ プロジェクトのログ ストリーミングがサポートされています。また、このガイドに沿って、Notebooks API を任意のレガシー VM に組み込むこともできます。
GCP 内の保存データはすべて暗号化されます。デフォルトでは、この暗号化には Google が管理する暗号鍵が使用されますが、管理を強化するために、お客様自身が管理する顧客管理の暗号鍵(CMEK)も使用できます。さらに、Google の External Key Manager を使用して、お客様所有のハードウェア セキュリティ モジュール(HSM)で生成された暗号鍵を提供することもできます。デフォルトで、転送中のデータも TLS を使用して暗号化されます。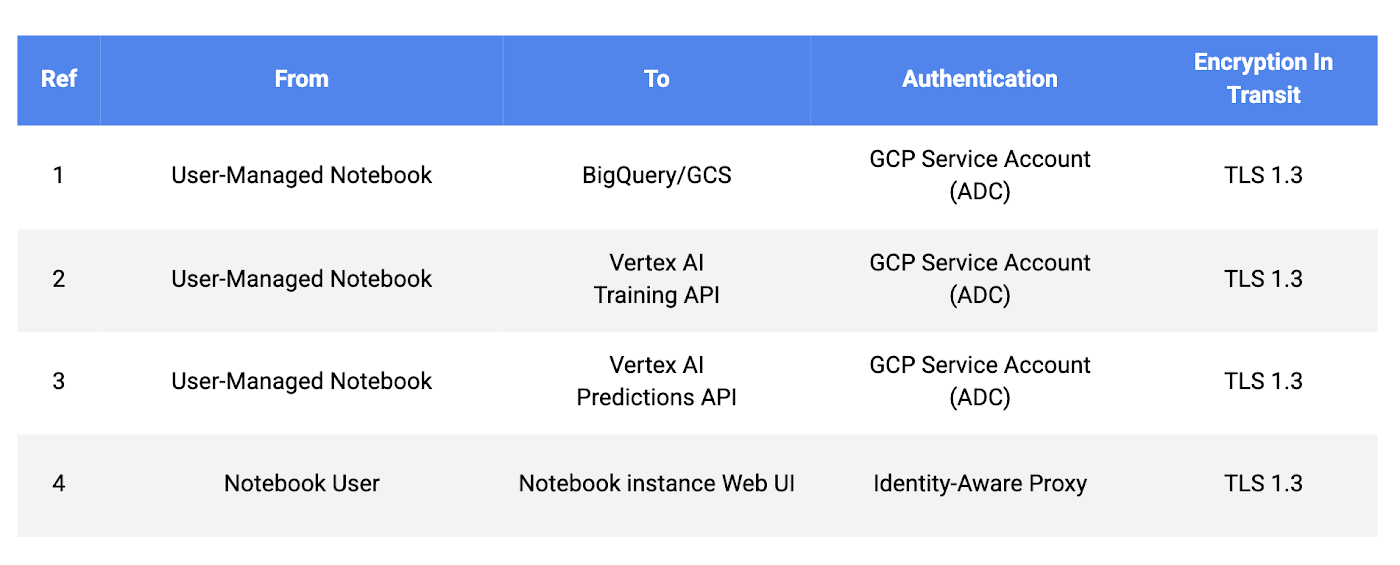
また、アプリケーションには Google Cloud クライアント ライブラリを使用することをおすすめします。Google Cloud クライアント ライブラリは、アプリケーションのデフォルト認証情報(ADC)というライブラリを使用して、サービス アカウントの認証情報を自動的に検索します。さらに、事前定義ロールや基本ロールではなく、カスタム サービス アカウントを使用することもおすすめします。
Vertex AI Feature Store
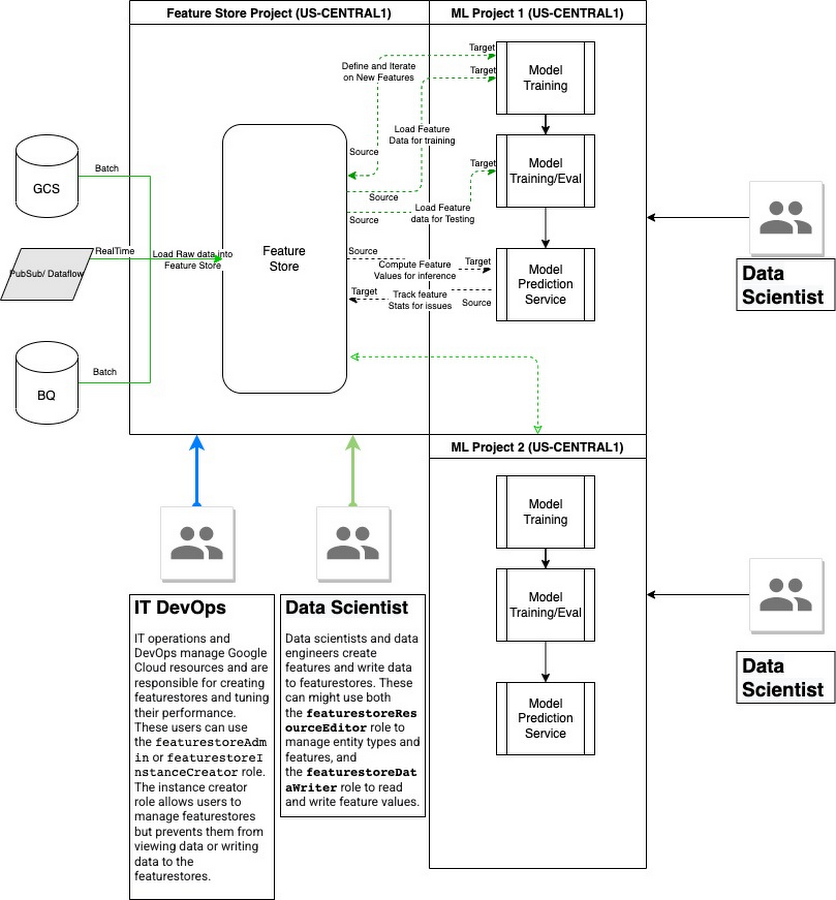
Vertex AI Feature Store は、機械学習で使用する特徴量を整理、保存、提供するための一元化されたリポジトリです。一元化された Feature Store を使用すると、組織は機械学習で使用する特徴量を大規模かつ効率的に共有、発見、再利用できるため、新しい機械学習アプリケーションの開発とデプロイにかかる時間を短縮できます。
Feature Store はリージョン サービスなので、すべてのデータは Feature Store リソースと同じ GCP リージョン内、またはユーザーがリクエストした GCP リージョン内に維持されます。エンタープライズ向けデプロイでは、多数のデータ サイエンス プロジェクトが貢献したり、互いに協力し合ったりできる、共有サービス プロジェクトを構成することをおすすめします。Feature Store は、構成可能なデータ保持の上限まで特徴値を維持します。デフォルトのデータ保持の上限は 4,000 日です。サービング ノードごとに最大 5 TB のデータを保存できます。Feature Store の割り当てと上限の詳細についてはこちらをご覧ください。
暗号化は、データの取り込み / エクスポートに使用されるストレージ システム(GCS、BigQuery、ノートブックのブートディスクおよび永続ディスク)によって行われます。すべてのデータ(特徴量 / EntityType メタデータ、特徴値データ)は転送時に暗号化されます(TLS 1.3 がサポートされています)。Feature Store と Feature Store 内のすべてのコンテンツには CMEK を使用できます(CMEK を使用する Feature Store を作成します)。Vertex Feature Store では VPC Service Control がサポートされています。
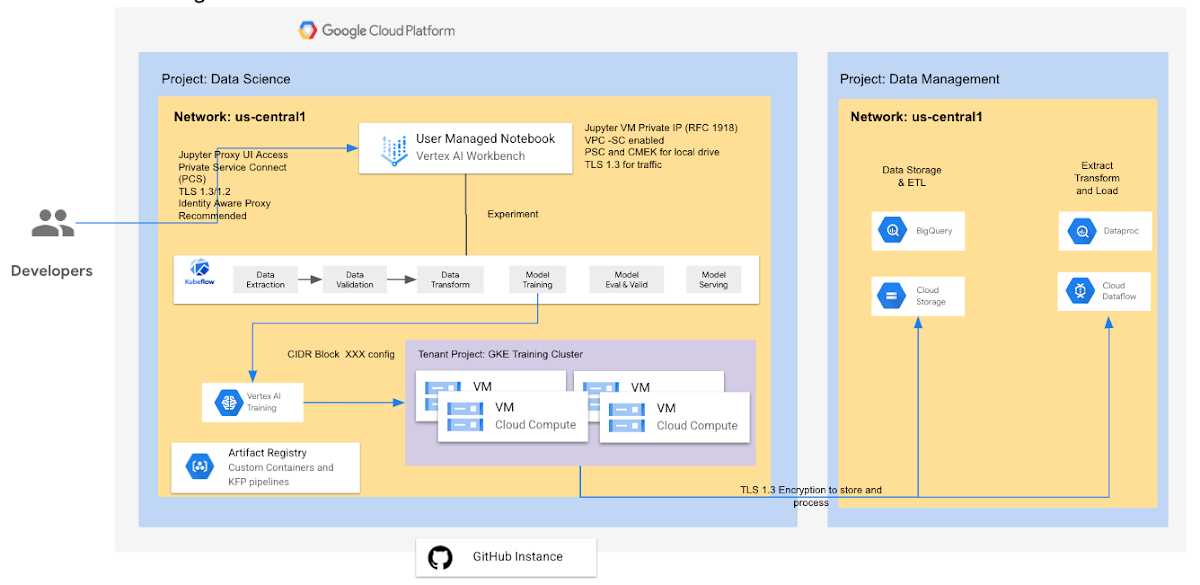
Vertex AI Training の主な利点の一つは、Vertex AI で分散トレーニング ジョブを実行するときに、トレーニング クラスタ内の複数のマシン(ノード)を指定できることです。トレーニング サービスにより、指定したマシンタイプに応じてリソースが割り当てられます。指定のノードで実行中のジョブは、レプリカと呼ばれます。同じ構成のレプリカのグループは、ワーカープールと呼ばれます。このタイプの構成は、機械学習モデルのトレーニングを大幅に加速するのに役立ちます。
Vertex AI Training は、Google がテナント プロジェクト内で管理する GCE / Kubernetes クラスタであり、ジョブが完了すると破棄されます(コンテナとデータが破棄されます)。テナント プロジェクトはユーザーのプロジェクトと 1 対 1 の関係にあり、どちらのプロジェクトも同じリージョン内に存在するため、データ所在地が尊重されます。トレーニング ジョブはテナント プロジェクトにはデータを保存しません。ユーザーのコードを実行するために必要なときに、VM(RAM 内またはブートディスク上)だけにデータを保存します。トレーニング プロセスでは、ユーザーからの明示的なリクエストにより、ユーザー プロジェクトの GCS にデータを保存できます。コード、ブートディスク上の pull されるデータ、コードによってディスク上に一時的に保存されるデータを暗号化するのに、CMEK を使用できます。カスタム トレーニング ジョブにプライベート IP を使用するには、こちらのガイドをご覧ください。
Vertex AI Training は、ユーザーが実行するトレーニング ジョブごとに、Kubernetes ベースのマネージド トレーニング クラスタを提供します。これらのクラスタは、必要に応じて作成され、破棄されます。そのため、あるジョブを実行した後、次のジョブを実行するまで使用しないリソースに対して料金を支払うことなく、必要に応じてトレーニング時間を最小化できます。そのうえ、コンテナの形状と数量を調整することで、実行するジョブごとに適切な費用対性能比を選択できます。この機能は、GPU に対応するトレーニング ジョブの場合には特に価値があります。Google Cloud は GPU インフラストラクチャに多大な投資をしてきました。その結果、ユーザーは複数の GPU タイプからユースケースに応じて適切なものを選択することができるようになりました。ぜひこの利点を活用しましょう。また、Vertex AI Vizier をブラックボックス ツールとして利用してハイパーパラメータを調整し、理想的なモデル アーキテクチャを探すプロセスを単純化することもできます。
Vertex AI Training を使用すると、クラスタの設定、構成、強化、パッチ適用などといったクラスタの保守について気にする必要がなくなります。トレーニング コードを送信するだけで、そのコードが実行されるので、優れた ML コードを作成することに専念できます。
現在のところ、Terraform を使用して「Job リソース」を作成することはできません。そのため、IaC によってトレーニングを設定するのは困難です。ただし、マネージド パイプラインを作成する際の前提条件となるリソース(サービス アカウント、Cloud Storage バケット、API など)は、この Terraform モジュールにバンドルされています。
コードを「トレーニング」するのは Vertex AI の役目ではありません。Vertex AI Training がトレーニング コードを実行します。作成するトレーニング コードで、データをローカルのキャッシュに保存するか、メモリに直接ストリーミングするかを決定できます。データがコンピューティング ノード上のローカル ストレージに到達するかどうかは、コードで使用しているストレージ メカニズムによって変わります。コードで GCSFuse を使用すれば、データはローカル ディスクに到達するでしょう。NFS マウントを使用する場合も、データはローカル ディスクに到達すると考えられます。一方、GCS、BigQuery などに直接アクセスすると、データのフローを管理できます。
Vertex AI Training リソースを作成する際に選択できるトレーニング方法は 2 つあります。AutoML とカスタム トレーニングです。AutoML の詳細については、以降のセクションで説明します。カスタム トレーニング ジョブ(Vertex AI API の CustomJob リソース)は、Vertex AI でカスタム機械学習(ML)トレーニング コードを実行するための基本的な方法です。この方法を使用すると、TensorFlow、PyTorch、scikit-learn、XGBoost のトレーニング アプリケーションをクラウド内で実行できます。カスタム トレーニングの詳細については、こちらのドキュメントをご覧ください。Kubeflow を使用して GKE 上でトレーニング ジョブを実行する場合の詳細は、こちらでご確認ください。
Vertex AI Training では、Vertex AI マネージド データセットを使用してカスタムモデルをトレーニングできます。それには、カスタム トレーニング パイプラインを作成するときに、トレーニング アプリケーションが Vertex AI データセットを使用するように指定します。Vertex AI Training でマネージド データセットを使用する方法について詳しくは、こちらのドキュメントをご覧ください。
Vertex AI Predictions
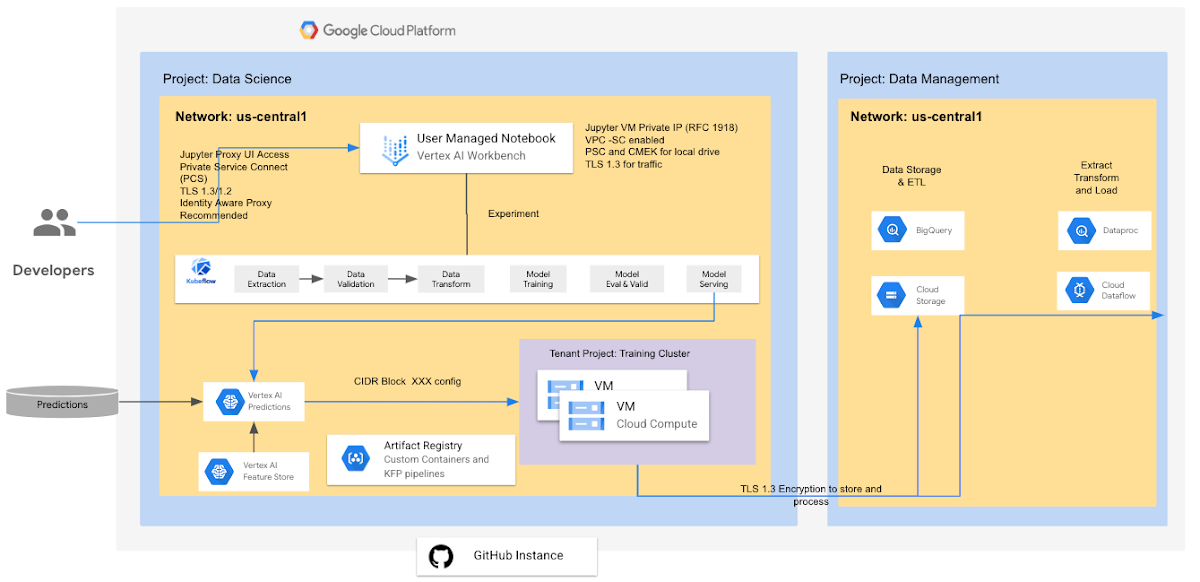
Vertex AI バッチ予測は、機械学習バッチ予測を提供するマネージド サービスです。このサービスは、BigQuery および Google Cloud Storage から入力データを取得し、そのデータに対して予測を実行して、結果を GCS、BigQuery のそれぞれに返します。
テナント プロジェクトはユーザー プロジェクトと 1 対 1 の関係にあり、どちらのプロジェクトも同じリージョン内に存在するため、データ所在地が尊重されます。テナント プロジェクトにはバッチ予測用の入力データは保存されません。ユーザーのコードを実行するために必要なときに、VM(RAM 内またはブートディスク上)だけにデータを保存します。メモリ内の入力データと出力データは、ジョブが完了するとワイプされます(すべてがワイプされます)。バッチ予測ジョブを進めるために使用される一時ファイル(モデルファイル、ログ、VM ディスクなど)はすべて、CMEK を使用して暗号化されます。BatchPrediction で書き出された結果がユーザー指定の宛先に格納される場合は、デフォルト値の暗号化構成に従います。それ以外の場合は、CMEK で暗号化されます。
Vertex AI がカスタム トレーニング モデルからオンライン予測を提供する方法をカスタマイズするには、モデル リソースを作成するときに、事前にビルドされたコンテナではなくカスタム コンテナを指定します。カスタム コンテナを使用すると、Vertex AI は各予測ノードで任意の Docker コンテナを実行します。予測にカスタム コンテナを使用する方法については、こちらのドキュメントをご覧ください。
オンライン予測
Vertex AI オンライン予測は、機械学習によるオンライン予測のユースケースに対応するマネージド サービスです。このサービスを利用すると、Google Cloud コンソールまたは Vertex AI API を使用して、表形式の分類モデルまたは回帰モデルからオンライン(リアルタイム)予測と説明を簡単に取得できます。アプリケーションの入力に応じてリクエストを行う場合や、タイムリーな推論が必要な場合などは、非同期のリクエストであるバッチ予測ではなく、同期リクエストを受けるオンライン予測を使用します。企業向けに推奨される手法として、オンライン予測にプライベート エンドポイントを使用する方法については、こちらのガイドをご覧ください。
オンライン予測を取得するには、まず、分類モデルまたは回帰モデルをトレーニングして、精度を評価する必要があります。オンライン予測をリクエストするには、predict リクエストで入力データ インスタンスを JSON 文字列として送信します。リクエストとレスポンスの本文のフォーマットについては、予測リクエストの詳細をご覧ください。
組織がすべてのトラフィックを限定公開の状態に維持しなければならない場合は、プライベート エンドポイントを使用して Vertex AI で予測を提供することをおすすめします。こうすると、低レイテンシかつ安全な接続を Vertex AI オンライン予測サービスとの間で確立できます。プライベート エンドポイントを使用してオンライン予測を行う前に、自身のネットワークと Vertex AI の間でピアリング接続を確立するようにプライベート サービス アクセスを構成する必要があります。この設定が完了したら、オンライン予測にプライベート エンドポイントを使用するためのガイドで説明している手順を行ってください。重要な点として、各予測のサイズは 1.5 MB 未満に抑える必要があります。
Vertex AI マネージド パイプライン
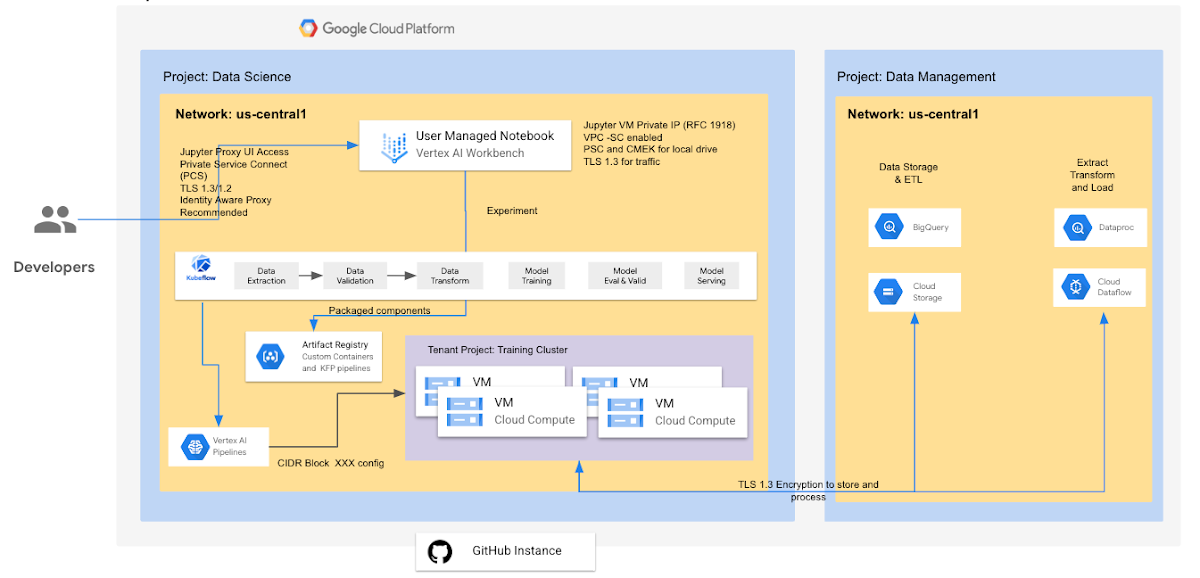
Vertex AI Pipelines は、自分のプロジェクトのネットワークにピアリングされているテナント プロジェクトに含まれる、Google 所有の VPC ネットワークで実行されます。各パイプライン ステップ(コンポーネント インスタンス)には、コンテナ イメージが関連付けられています。パイプラインは、Container / Artifact Registry でホストされているコンテナ イメージを使用します。デフォルトでは、コンポーネントは Vertex AI CustomJob として動作します。GKE 上の Kubeflow を使用してパイプラインを構築する方法については、こちらをご覧ください。
Vertex AI Pipelines は Cloud Storage を使用して、パイプライン実行のアーティファクトを保存します。Vertex ML Metadata は、Vertex AI Pipelines を使用して実行されるパイプラインのメタデータをテナント プロジェクトに保存します。Vertex AI Pipelines では、カスタム サービス アカウント、顧客管理の暗号鍵、ピアリングした VPC ネットワークを使用できます。デフォルトで、すべての保存データは暗号化されます。
現在のところ、Terraform を使用して「Job リソース」を作成することはできません。そのため、IaC によってマネージド パイプラインを設定するのは困難です。マネージド パイプラインを作成する際の前提条件となるリソース(サービス アカウント、Cloud Storage バケット、API など)は、この Terraform モジュールにバンドルされています。
パイプライン実行のアーティファクトはパイプライン ルート内に保存されます。パイプラインを実行するサービス アカウントを作成し、パイプラインの実行に必要な Google Cloud リソースに対する詳細な権限をアカウントに付与することをおすすめします。顧客管理の暗号鍵(CMEK)でデータを暗号化する場合は、パイプラインを実行する前に CMEK 鍵を使用してメタデータ ストアを作成する必要があります。メタデータ ストアが作成された後、メタデータ ストアで使用される CMEK 鍵は、パイプラインで使用される CMEK 鍵とは別のものになります。
- Global Vertex AI COE リード Crispin Velez
- Vertex AI アウトバウンド プロダクト マネージャー Vincent Ciaravino