Vertex AI を使用した迅速なモデル プロトタイピングとデプロイ
Google Cloud Japan Team
※この投稿は米国時間 2022 年 3 月 16 日に、Google Cloud blog に投稿されたものの抄訳です。
「機械学習システムの隠れた技術的負債」NeurIPS(2015 年)
Google が著したもう 1 つの非常に興味深いホワイトペーパーに、MLOps の実践ガイド: 機械学習における継続的デリバリーと自動化のフレームワークがあります。AI / ML 分野でのソート リーダーシップに加え、Google Cloud ではプロトタイピングから本番環境へ進む過程で、データ サイエンティストや ML エンジニアを支援する豊富なツールを提供しています。
デジタル トランスフォーメーションの重要な柱としての AI / ML の認知度が強まる一方、デプロイを成功させ効果的に運用することが、AI による価値を獲得する際のボトルネックとなっています。試験運用や概念実証の次の段階に進んだ組織は半分にすぎません。
Khalid Salama、Jarek Kazmierczak、Donna Schut, MLOps の実践ガイド
この記事が目指しているのは、前述のリソース内で提示されているベスト プラクティスを理解し、Google Cloud プロジェクトで活かしてもらうことです。ここで焦点を当てるのは MLOps と、ML ワークフローをパイプラインに組み込むためのツール オプションであるため、モデル開発には触れず、それ以外のあらゆる事項について説明します。このノートブックは GitHub のリポジトリで公開されているもので、モデルの考案からデプロイまでを支える Vertex Pipeline の構築について説明しています。
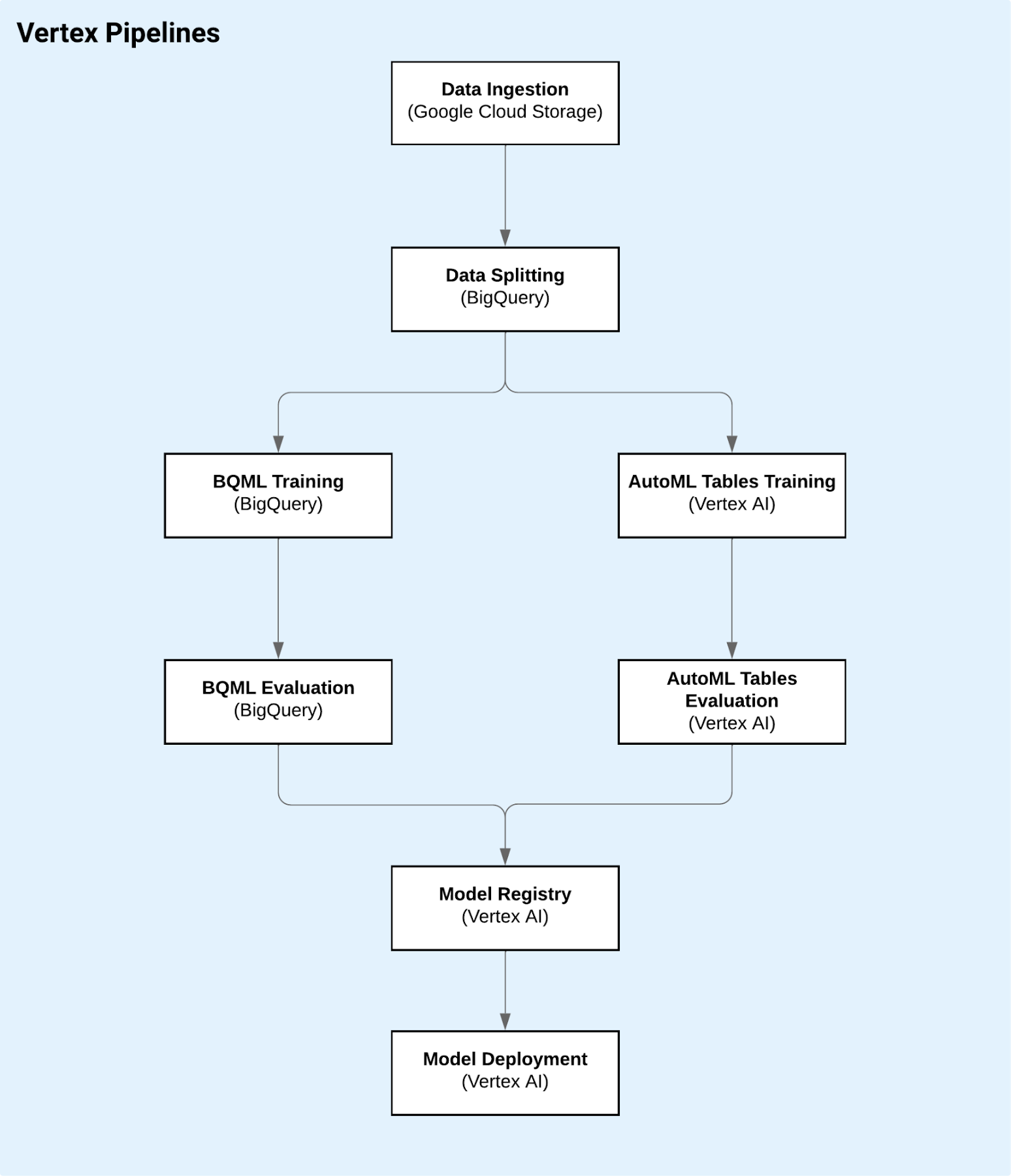
Vertex Pipeline に含まれる手順(ノートブック)
実際のモデル作成と最適化プロセスは、BigQuery ML と AutoML Tables というエキスパートに任せます。また、2 つの異なるモデルをトレーニングし、使用したデータセットでより優れたパフォーマンスを見せた方を選択します。パイプラインについて詳しく説明する前に、モデル開発に必要なツールを手短に紹介します。
BigQuery ML(BQML)を使用すると、BigQuery のペタバイト規模を活かしながら、BigQuery で標準 SQL クエリを使用して、機械学習モデルを作成し実行できます。BigQuery ML は、SQL 実務担当者が既存の SQL ツールやスキルを使ってモデルを構築することを可能にし、機械学習をより多くの人が利用できるようにします。
AutoML Tables はさらに人による操作が不要で、非常に高度な機械学習フレームワークのメリットを享受するときでも、モデルコードを書く必要はありません。AutoML は多様なモデル アーキテクチャを自動でテストし、ニーズに合う最先端のモデルを導き出します。
パイプライン
このワークフローの全行程をつなぎ合わせるためには、Vertex Pipelines を使用します。Vertex Pipelines を使用すると、サーバーレスで ML ワークフローをオーケストレートできます。Vertex Pipelines で ML ワークフローをオーケストレートする前に、ワークフローをパイプラインとして記述する必要があります。この例では、Kubeflow Pipelines v2 SDK を使用します。
機械学習ワークロードのために Vertex AI を使用する利点は、パイプラインのワークフロー全体で使用するソリューションが相互通信することです。パイプラインを実行すると、Vertex AI はパイプライン実行時に生成されたすべてのアーティファクトのメタデータとリネージを自動で追跡します。パイプライン メタデータは、以下の疑問の解決に役立ちます。
特定のモデルのトレーニングに使用されたデータセットはどれか。
特定のデータセットを使用してトレーニングされた組織のモデルはどれか。
どの実行で最も正確なモデルが作成されたのか、またそのモデルのトレーニングに使用されたハイパーパラメータはどれか。
以下の画像の通り、データセットの作成に使用された生の .csv ファイルにまで遡って特定のモデルを追跡することができます。
リネージのトラッキング
データ

アワビは海のカタツムリであり、この演習の目標は殻の実際のサイズからアワビの年齢を予測することです。カリフォルニア大学から提供されたデータセットには、1 つの分類的な特徴と 6 つの数値的な特徴を伴う 4,177 のインスタンスが含まれています。測定値に基づいてアワビの輪紋の数を予測するので、これを回帰問題として処理していきます。輪紋の数を求めることで、年齢が推測できます。
まず、Google Cloud Storage(GCS)のバケット上にホストされた .csv ファイルから行程はスタートします。データにアクセスできたら、Google のデータ ウェアハウスである BigQuery にインポートしていきます。今回は、データセットをトレーニング(80%)、評価(10%)、テスト(10%)の 3 つのサブセットに分割していきます。トレーニング スライスと評価スライスはモデルの作成と最適化に使用され、テスト部分はモデルの選択に使用されます。トレーニング データを作成するためのベスト プラクティスについては、こちらで説明しています。
モデルのトレーニング
BQML では、ほんの数行の SQL を記述するだけでモデルを構築できます。このデモでは、BQML 上で線形回帰モデルを使用します。ですが、ディープ ニューラル ネットワークやブーストツリーといったその他のモデル アーキテクチャをクリエイティブに使用することもできます。BQML でサポートされているモデルの一覧は、各モデル向けのエンドツーエンドのユーザー ジャーニーをご確認ください。この記事では扱っていませんが、ML モデルのトレーニング時には、ニューラル アーキテクチャ検索のような非常に高度な機能を持つハイパーパラメータの調整を BQML がサポートしていることも言及しておきます。
Vertex Pipelines では、いくつかの構築済みコンポーネントを提供しており、Kubeflow パイプラインの作成およびオーケストレーションのプロセスの簡素化が可能です。必要な操作は、使用しているデータセットや予測しようとしているターゲット列といった、いくつかのパラメータを指定するだけです。これを説明するために、AutoMLTabularTrainingJobRunOp と BigqueryCreateModelJobOp を使用します。
AutoML モデルのトレーニングの前に、パイプラインの前の段階で作成した BigQuery テーブルを使った Vertex データセットの作成が必要です。これは、TabularDatasetCreateOp の構築済みコンポーネントを使用して行うことができます。データセットの作成が完了すると、AutoMLTabularTrainingJobRunOp を使用してモデルのトレーニングが可能となります。
BQML のパートでは、最初のステップとして BQML の CREATE MODEL ステートメントに沿って SQL クエリを定義します。以下のように、特徴列とターゲット ラベルを指定する必要があります(今回の場合は輪紋)。
SQL クエリの作成後は、BigqueryCreateModelJobOp の構築済みコンポーネントを使用して、Vertex Pipeline に基盤となるリソースの管理を任せられます。
モデルの評価
BQML と AutoML を使用したモデルのトレーニングが完了した後は、テストのデータセットで優れたパフォーマンスを見せるモデルはどれか、という評価における最初の疑問に答えを出す必要があります。
AutoML Tables が評価指標を引き出し、直接 UI に表示します。BQML には、mean_absolute_error や mean_squared_log_error などの指標を集める構築済みコンポーネント(BigqueryEvaluateModelJobOp)があります。最初のタスクは、そうした指標をプログラムで集め、相互に比べることです。ノートブックでは、こうしたサービスの利用方法を紹介する、Google が作成した 2 つのカスタム コンポーネントを確認することができます。
モデルのパフォーマンスを評価するために選んだ指標は、二乗平均平方根誤差(RMSE)でした。これらの指標はモデルのパフォーマンスの分析にとても重要です。ですから、後からパイプラインのパフォーマンスを把握するために活用できるメタデータを確実にロギングする必要があります。幸いにも、Vertex Pipelines ではメタデータのロギングが可能で、後に続くパイプラインの実行との比較もできます。これは、異なるモデル アーキテクチャや異なるデータセットとの比較、またはトレーニング コードへ今後、加えていくことになる変更との比較にも役立ちます。
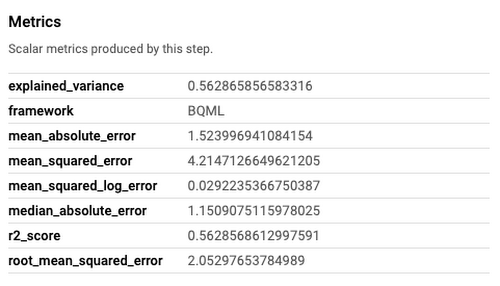
どのモデルが最適であるかがわかったら、本番環境に push するための最小要件を満たしているかを確認する必要があります。そのために、デプロイのしきい値を設定しました。このデモでは、RMSE <= 2.5 を選択しています。もし最適なモデルの RMSE がしきい値よりも低い場合、パイプライン上で次のステップに進みます。
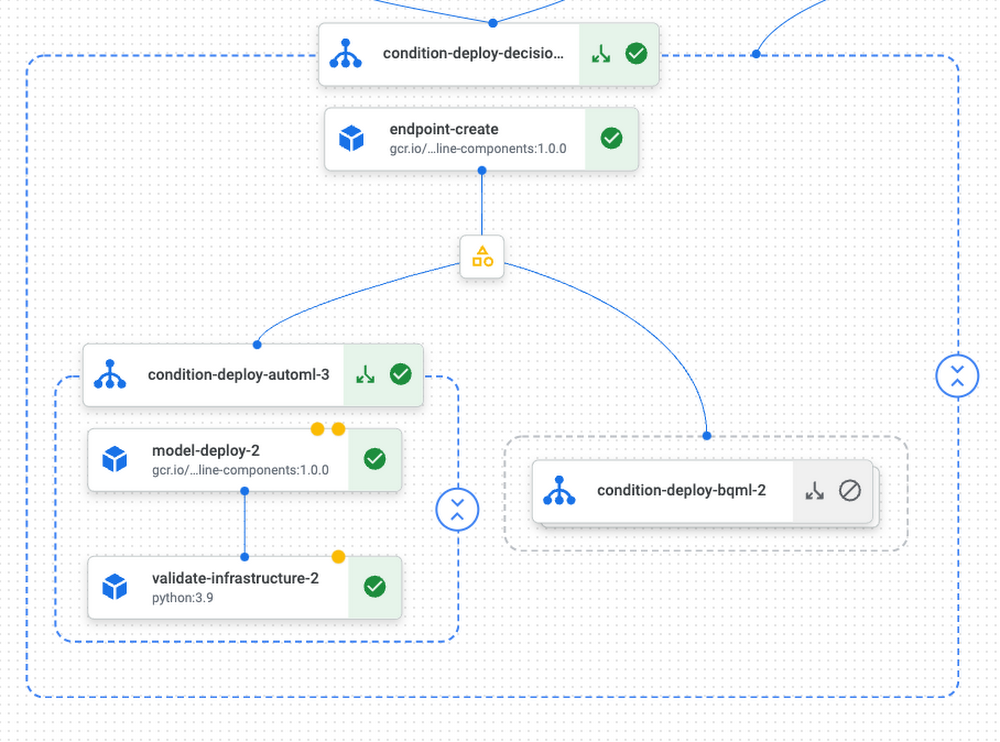
モデルのデプロイ
モデルの評価手順では、最も優良なモデルが明らかになります。次は、モデルをエンドポイントにデプロイし、提供します。これには Vertex Prediction を使用します。Vertex Prediction を使用すると、HTTP 経由でのオンライン サービングに際し、モデルを本番環境により簡単にデプロイできます。BQML モデルも AutoML モデルも、構築済みの TensorFlow イメージを伴っているため、コンテナの作成について心配することなくモデルを提供できます。
構築済みコンポーネントを使用することで、新しいエンドポイントを作成し、そこにモデルをデプロイするプロセスを簡略化できます。以下のコード スニペットは、パイプライン内で 2 つの条件を連結し、以下の質問に答える方法を示しています。
最も優良なモデルは最小要件のしきい値を満たしているか。
満たしている場合は、AutoML と BQML のどちらのモデルを本番環境にデプロイするべきか。
この段階で、モデルは本番環境向けの準備が整った状態で、予測リクエストを受け入れます。これをテストするために、新しくデプロイしたモデルに HTTP リクエストを実施する、validate_infra コンポーネントを追加しました。その方法については、ノートブック上で validate_infrastructure と検索すると確認していただけます。
まとめ
この記事では、概念を本番環境に移す際に AI 実務担当者が直面する課題の一部を紹介しました。Google のノートブックの中で、機械学習パイプラインの開発に使用できる複数の Google Cloud ツールにまたがる 14 のコンポーネントを使用しています。
次のステップ
実際にお試しいただくことで、ノートブックを実行し、Vertex AI のメリットを実感していただけます。複数の GCP サービスの緊密な統合により、はるかに少ない労力でモデルを概念から本番環境へ移行できるため、ML の生産性を増大させることができます。
ご精読ありがとうございました。質問やチャットをご希望の場合は、LinkedIn からご連絡ください。
- 機械学習担当カスタマー エンジニア Rafa Carvalho





_1_(24196696646).jpg){kind=link}