PyTorch / XLA と Cloud TPU VM を利用したディープ ラーニング ワークロードのスケーリング
Google Cloud Japan Team
※この投稿は米国時間 2021 年 7 月 20 日に、Google Cloud blog に投稿されたものの抄訳です。
はじめに
ディープ ラーニングの発展の多くは、(1)データサイズと(2)コンピューティング パワーが増大したことによるものです。ディープ ラーニング モデルをトレーニングするときのデータセットは、大きいほど効果が高まります。モデルのトレーニング パフォーマンスが安定するだけではありません。調査によれば、モデルとデータセットが中規模から大規模の場合、モデルのパフォーマンスはトレーニング データのサイズのべき乗則に従うことがわかりました。つまり、データセットの増加に伴うモデルの精度の向上は予測可能だということです。
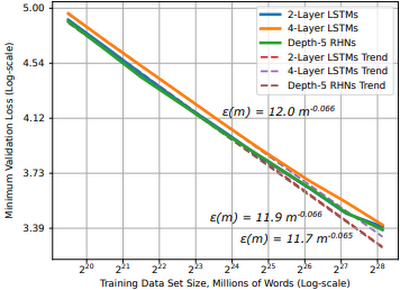
図 1: 単語学習モデルにおける学習曲線とデータセットのサイズ(出典)
実際に、より大きなデータセットでモデルのパフォーマンスを向上させるには、(1)GPU や TPU などのハードウェア アクセラレータを使用し、(2)効率的にこのデータを保存してアクセラレータに提供するシステムを構築する必要があります。リモート ストレージからアクセラレータ デバイスへのデータ ストリーミングを選ぶ理由は、以下のとおりいくつか考えられます。
データサイズ: データが大きく、1 台のマシンだけでは扱えないこともあるため、リモート ストレージと効率的なネットワーク アクセスが必要
ワークフローの効率化: データをディスクに転送すると、時間とリソースが大きく消費されるので、データのコピーは少ない方が望ましい
コラボレーション: アクセラレータ デバイスからデータを切り離すと、ワークロードやチームの枠を超えて、より効率的にアクセラレータ ノードを共有できる
リモート ストレージからアクセラレータにトレーニング データをストリーミングすると、これらの問題を軽減できますが、新しい別の問題が生じます。
ネットワーク オーバーヘッド: 多くのデータセットは何百万ものファイルで構成されていて、これらのファイルへのランダムなアクセスはネットワーク ボトルネックになる。シーケンシャル アクセス パターンが必要
スループット: 最新のアクセラレータは高速だが、この速度を生かせるくらいに速くデータをフィードできるかどうかが問題。並列 I/O とパイプラインを使用したデータへのアクセスが必要
ランダムとシーケンシャルの比較: ディープ ラーニング ジョブの最適化アルゴリズムはランダム性を利用しているが、ランダム ファイル アクセスは、ネットワーク ボトルネックを発生させる。シーケンシャル アクセスはネットワーク ボトルネックを軽減するが、トレーニングの最適化に必要なランダム性を低下させる可能性がある。これらのバランスを取ることが必要
大規模な環境でこれらの問題に対処するシステムの構築方法
図 2: データセットを大きくし、デバイス数を増やすスケーリング
この投稿では、次の内容を取り上げます。
ディープ ラーニング ジョブから分散型トレーニング設定へのスケーリングに関係する問題
新しい Cloud TPU VM インターフェースの使用
Google Cloud Storage(GCS)から Cloud TPU Pod スライスで実行されている PyTorch / XLA モデルにトレーニング データをストリーミングする方法
この記事で使用するコードは、こちらの GitHub リポジトリにあります。
モデルとデータセット
この記事では、v3-32 TPU Pod スライスで PyTorch / XLA ResNet-50 モデルをトレーニングします。トレーニング データは GCS に保存され、トレーニング時に TPU VM にストリーミングされます。ResNet-50 は、コンピュータ ビジョン タスクと機械学習パフォーマンスのベンチマークによく使われる 50 層の畳み込みニューラル ネットワークです。エンドツーエンドの例を示すために、CIFAR-10 データセットを使用します。元のデータセットは、60,000 個の 32x32 のカラーイメージで構成され、それぞれが 6,000 個のイメージで構成される 10 のクラスに分割されています。このデータセットをアップサンプリングして、1,280,000 個のイメージを含むトレーニングセットと、50,000 個のイメージを含むテストセットを作成しました。CIFAR を使用したのは、一般公開され、よく知られているためです。GitHub リポジトリには、独自のワークロードや、ImageNet などより大きなデータセットにこのソリューションを適用するためのガイドがあります。
Cloud TPU
TPU(Tensor Processing Unit)は、大規模なモデルのトレーニング用に、特に設計された ML ASIC です。大きな行列乗算を行うタスクの処理に優れているため、ディープ ラーニング ジョブを高速化し、トレーニングの総コストを削減できます。TPU をあまり使ったことがない場合は、TPU の機能について、次の記事をお読みください。
この例で使用する v3-32 TPU は、32 個の TPU v3 コアと、合計 256 GiB の TPU メモリで構成されています。この TPU Pod スライスは、4 つの TPU ボードで構成されています(1 ボードに 8 個の TPU コア)。各 TPU ボードは高パフォーマンス CPU ベースのホストマシンに接続され、TPU にフィードするデータの読み込みや前処理などを行います。
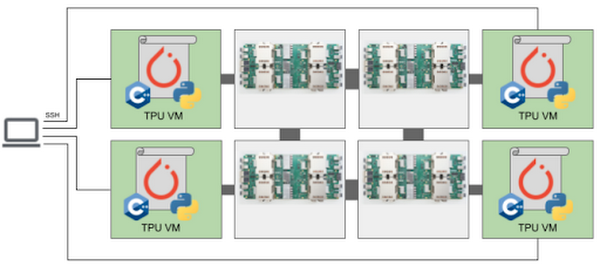
図 3: Cloud TPU VM のアーキテクチャ(出典)
TPU には、新しい Cloud TPU VM からアクセスします。Cloud TPU VM を使用する場合、構成内の TPU ボードごとに VM が作成されます。各 VM は 48 個の vCPU と 340 GB のメモリで構成され、最新の PyTorch / XLA イメージがプリインストールされています。ユーザー VM がないため、TPU ホストに直接 SSH 接続して、モデルとコードを実行します。このルートアクセスによって、コードと TPU VM の間にネットワーク、VPC、ファイアウォールが不要になります。その結果、入力パイプラインのパフォーマンスが大幅に向上します。Cloud TPU VM の詳細については、システム アーキテクチャをご覧ください。
PyTorch / XLA
PyTorch / XLA は、XLA(Accelerated Linear Algebra)ディープ ラーニング コンパイラを使用して PyTorch および Cloud TPU に接続する Python ライブラリです。GitHub リポジトリに、チュートリアル、ベスト プラクティス、Docker イメージ、一般的なモデル(ResNet-50、AlexNet など)のコードがあります。
データ並列型分散トレーニング
分散トレーニングとは、一般的に、複数のアクセラレータ デバイス(GPU、TPU など)を使用するトレーニング ワークロードを指します。この例では、確率的勾配降下法で、データ並列型分散トレーニング ジョブを実行します。データ並列型トレーニングでは、モデルは 1 つの TPU デバイスに適合し、分散構成で各デバイスにモデルを複製します。デバイスを追加する目的は、重複しないトレーニング バッチのパーティションを各デバイスに分散させて並列処理を行い、全体的なトレーニング時間を短縮することです。モデルが複数のデバイスに複製されるため、各デバイスのモデルは、トレーニング ステップが終わるたびに通信をして、ウェイトを同期する必要があります。データ並列型分散ジョブでは、このデバイス通信は非同期と同期のどちらでも行われます。
ローカル勾配を計算した後、xm.optimizer_step() 関数が AllReduce(SUM) 演算を適用して、コア間でローカル勾配を同期します。次に、PyTorch optimizer_step(optimizer) を呼び出し、同期された勾配でローカル ウェイトを更新します。TPU で、チップを接続する専用のネットワークを通じて、XLA コンパイラが AllReduce 演算を生成します。最後に、グローバルに平均をとった勾配が、各モデルレプリカのパラメータ ウェイトに書き込まれます。これにより、すべてのレプリカがトレーニング イテレーションのたびに同じ状態から開始されるようになります。この関数は、トレーニング ループで次のように呼び出されます。
入力パイプラインのパフォーマンス
上記のとおり、TPU の課題は、TPU を十分に活用できる速度でトレーニング データをフィードすることです。この問題は、トレーニング データをローカル ディスクに保存する場合に発生し、リモート ストレージからデータをストリーミングすると、より明確になります。まず、一般的な機械学習トレーニング ループを見てみましょう。
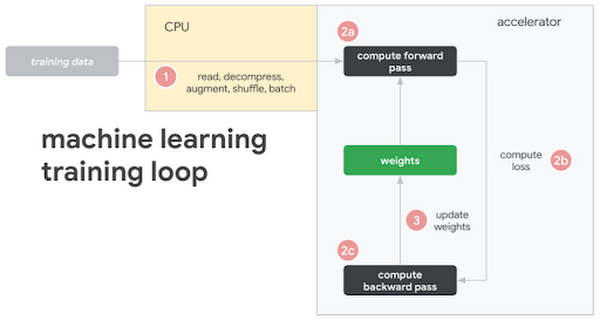
この図には、次のステップが示されています。
トレーニング データがローカル ディスクまたはリモート ストレージに保存される
CPUが(1)データをリクエストして読み込み、さまざまな変換で拡充させ、バッチ処理を行い、モデルにフィードする
モデルが変換され、トレーニング データがバッチ処理されると、(2)アクセラレータに切り替わる
アクセラレータが(2a)フォワードパス、(2b)損失、(2c)バックワード パスを計算する
勾配を計算した後、(3)パラメータ ウェイトが更新される(学習!)
このサイクルを繰り返す
このパターンは、さまざまな方法で採用できます(たとえば、一部の変換をアクセラレータで計算することもできます)。しかし、重要なことは、最も高価なコンポーネントであるアクセラレータを最大限に活用するアーキテクチャが理想的であるということです。そのため、パフォーマンスの最大のボトルネックは、主に CPU で駆動される入力パイプラインで発生することとなります。これを解決するために、WebDataset ライブラリを使用します。WebDataset は、特にリモート ストレージを使用する環境において、ディープ ラーニング ワークロードのストリーミング データ アクセスを改善するように設計されている、PyTorch データセットの実装です。詳細を見てみましょう。
WebDataset 形式
WebDataset は単なる POSIX tar アーカイブ ファイルで、通常の tar コマンドで作成できます。データ変換の必要はありません。tar ファイルのデータ形式はディスク上のものと同じです。たとえば、このトレーニング イメージが保存されているとき、および入力パイプラインに転送されるときの形式は、PPM、PNG、JPEG のまま変わりません。tar 形式は、小さなデータセットと大きなデータセットのどちらでも、また、データがローカル ディスクと GCS などのリモート ストレージのどちらに保存されていても、パフォーマンスの向上に役立ちます。WebDataset で実現できる 3 種類の主なパイプライン パフォーマンスの改善を紹介します。
(1)シーケンシャル I/O
GCS は高いスループットを維持できますが、接続の開始時にネットワーク オーバーヘッドが発生します。何百万もの画像ファイルにアクセスする場合、このオーバーヘッドは望ましくありません。代わりに、個々の画像ファイルが格納されている tar ファイルをリクエストして、シーケンシャル I/O を行うことができます。tar ファイルをリクエストして、tar ファイル内の個別のファイルをシーケンシャルで読み込むようにすると、ネットワーク上でオブジェクトの I/O がより高速になります。これにより、GCS との間で確立するネットワーク接続の数を削減し、潜在的なネットワーク ボトルネックの発生を減らすことができます。
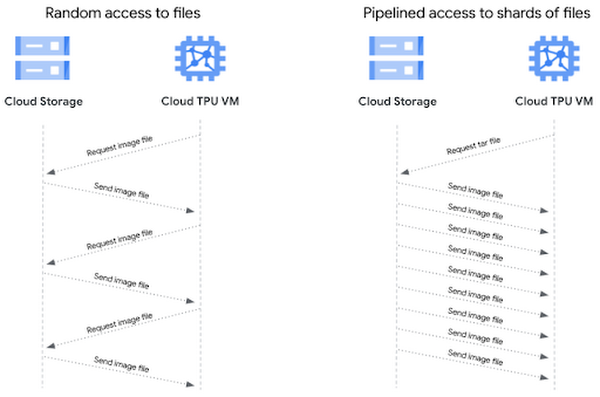
(2)パイプライン データアクセス
ファイルベースの I/O では、画像ファイルにランダム アクセスします。これは、トレーニングの最適化には適していますが、画像ファイルごとにクライアント リクエストとストレージ サーバー レスポンスが発生します。シーケンシャル ストレージでは、1 回のクライアント リクエストで tar ファイルを要求すると、ファイル内のデータサンプルがシーケンシャルにクライアントに流れてくるため、より高いスループットが得られます。このパターンで個別の画像ファイルへのパイプライン アクセスを行うと、より高いスループットが実現されます。
(3)シャーディング
TB 単位になる大量のデータを 1 つのシーケンシャル ファイルに保存すると、作業が難しくなり、並列 I/O ができなくなります。データセットをシャーディングすると、以下のようなメリットが得られます。
シャードを並列に開くことで、ネットワーク I/O を集約できる
シャードを並列に処理することで、データの前処理を高速化できる
ランダムにシャードにアクセスし、各シャードからシーケンシャルに読み取れる
シャードをワーカーノードとデバイスに効率的に分散させることができる
各デバイスのトレーニング サンプルの数を均等にできる
シャードの数とシャード内のサンプルの数を制御できるため、同じサイズのシャードを分散させることで、トレーニング エポックごとに各デバイスが同じ数のサンプルを受け取るようにできます。tar ファイルをシャーディングして、ランダム ファイル アクセスとシーケンシャル読み取りのバランスを取ることができます。シャードにランダム アクセスし、メモリ内でシャッフルすることで、トレーニングの最適化に十分なランダム性が得られます。一方、各シャードからシーケンシャルで読み取ることで、ネットワーク オーバーヘッドを減らすことができます。
デバイスおよびワーカー間でのシャードの分散
ここでは、実質的に PyTorch IterableDataset を作成しているため、トレーニング エポックごとに PyTorch DataLoader を使用して、デバイスにデータを読み込むことができます。これまでの PyTorch Dataset では、データをサンプルレベルで分散させていましたが、今回は、シャードレベルで分散させます。この分散ロジックを処理する 2 つの関数を作成し、データセット オブジェクトを作成するときに、これらの関数を引数 `splitter=` と `nodesplitter=` で渡します。どちらの関数も、シャードのリストを取得し、シャードのサブセットを返すだけです(次のスニペットをモデル スクリプトに組み込む方法については、付属の GitHub リポジトリの test_train_mp_wds_cifar.py をご覧ください)。
次のコードで、シャードをワーカーごとに分割します。
次のコードで、シャードをデバイスごとに分割します。
これら 2 つの関数を使用して、トレーニング データ用と検証データ用のデータローダを作成します。まず、トレーニング用ローダです。
このスニペットで使用している変数のうちいくつかを説明します。
xm.xrt_world_size()は、デバイス(TPU コア)の合計数ですFLAGS.num_workersは、データの読み込みと前処理に際して生成された TPU コアごとのサブプロセスの数ですepoch_sizeは、エポックごと、デバイスごとのトレーニング サンプルの数を指定しますshardshuffle=Trueは、シャードをシャッフルすることを意味し、.shuffle(10000)は、サンプルをインラインでシャッフルします.batched(batch_size, partial=True)は、batch_sizeでデータセット内のデータを明示的にバッチ処理し、‘partial=True’は、バッチが不完全でも処理します(最後のシャードでよく発生します)このローダは、標準の PyTorch DataLoader です。ここでは、WebDataset データセットでバッチ処理、シャッフル、不完全なバッチに対処するので、これらに対応する PyTorch の DataLoader の引数は使用しません
パフォーマンスの比較
図 7 の表は、ImageNet データセットで PyTorch / XLA ResNet-50 モデル トレーニングを行った場合の、3 つの異なるトレーニング構成のパフォーマンスを比較したものです。構成 A はベースライン指標で、ローカル ストレージから読み取り、個別の画像ファイルにランダム アクセスするモデルを表します。構成 B は、A と似た設定を使用しますが、トレーニング データを 640 POSIX tar ファイルにシャーディングして、WebDataset ライブラリでシャードをサンプリングし、Cloud TPU デバイス上のモデルレプリカに分散させています。構成 C は、B と同じサンプリングと分散のロジックを使用しますが、トレーニング データを GCS のリモート ストレージから取得します。指標は、構成ごとに 90 エポックのトレーニング ジョブを 5 回行った結果の平均を表します。
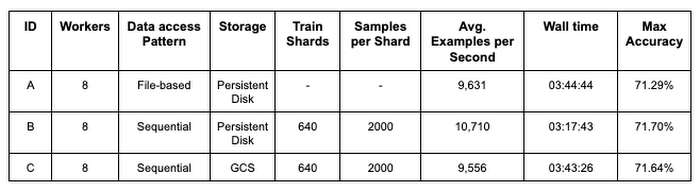
構成 A と B を比較すると、シャーディングされ、シーケンシャルに読み取れるデータ形式を使用するだけで、パイプラインとモデルのスループット(1 秒あたりの平均サンプル数)が 11.2% 向上することがわかります。また、モデル トレーニングのパフォーマンスに悪影響を与えることなく、リモート ストレージを利用できることがわかります。構成 A と C を比較してみると、パイプラインとモデルのスループット、トレーニング時間、モデルの精度が維持できています。
シーケンシャルな並列 I/O の効果を強調するために、多くの構成設定は一定にしました。調査と改良ができる領域は、まだたくさんあります。今後の投稿で、Cloud TPU プロファイラ ツールを使用して PyTorch / XLA トレーニング ジョブをさらに最適化する方法を説明します。
エンドツーエンドの例
この例の全体を見ていきましょう。
例をたどるにあたり、このノートブックを使用して、シャーディングされた CIFAR データセットを作成できます。
始める前に
Cloud Shell で次のコマンドを実行して、GCP プロジェクトを使用するように gcloud を構成し、TPU VM プレビューに必要なコンポーネントをインストールして、TPU API を有効にします。TPU 1VM の設定の詳細については、この手順をご覧ください。Cloud TPU VM への接続
デフォルトのネットワークは、すべての VM への SSH アクセスを許可するようにあらかじめ構成されています。デフォルトのネットワークを使用しない場合や、デフォルトのネットワーク設定が編集されている場合は、ファイアウォール ルールを追加して、SSH アクセスを明示的に有効にする必要があります。
現在、TPU VM のプレビュー版では、ネイティブの scp(PyTorch / XLA Pod に必要)を許可するために OS Login を無効にすることをおすすめします。
TPU 1VM スライスの作成
TPU Pod スライスを europe-west4-a に作成します。このリージョンは、TPU VM と v3-32 TPU Pod スライスの両方をサポートします。
TPU_NAME: TPU ノードの名前ZONE: TPU ノードのロケーションACCELERATOR_TYPE: サポートされるアクセラレータのタイプについては、こちらをご覧くださいRUNTIME_VERSION: PyTorch / XLA では、単一の TPU と TPU Pod 用に v2-alpha を使用します。これが、公開プレビュー リリースの安定バージョンです。
PyTorch / XLA では、すべての TPU VM がモデルのコードとデータにアクセスできる必要があります。gcloud を使用して、必要なパッケージとコードを各 TPU VM にインストールするメタデータ startup-script を含めます。
このコマンドで、v3-32 TPU Pod スライスと、TPU ボードごとに専用の VM が 1 つ、合計 4 つの VM が作成されます。
次のgcloud ssh コマンドを使用して、TPU VM に SSH 接続します。デフォルトでは、このコマンドは最初の TPU VM ワーカー(w-0 で表されるもの)に接続します。TPU Pod に関連付けられている他の VM に SSH 接続するには、コマンドに「--worker ${WORKER_NUMBER}」を追加します。ここで、WORKER_NUMBER は 0 ベースです。TPU VM の管理について詳しくは、こちらをご覧ください。VM で次のコマンドを実行すると、Pod の VM ワーカー間で SSH 接続するための SSH 認証鍵が生成されます。
PyTorch トレーニング
メタデータの起動スクリプトが、すべてのリポジトリをクローンしたことを確認します。次のコマンドを実行すると、torchxla_tpu ディレクトリが表示されます。
モデルをトレーニングするために、まず環境変数を設定します。
-
BUCKET: シャーディングしたデータセットを保存する GCS バケットの名前。トレーニング ログとモデル チェックポイントもここに保存します(GCS オブジェクトの名前とフォルダのガイドラインをご覧ください) {split}_SHARDS: train/val シャード。中括弧の表記でシャードを列挙しますWDS_{split}_DIR: train/val シャードをダウンロードするために、パイプを使用してgsutilコマンドを実行しますLOGDIR: トレーニング ログを保存する GCS バケット内の場所
オプションで、モデル チェックポイントを保存し、前のチェックポイント ファイルから読み込むための環境変数を渡すこともできます。
モデル チェックポイントを保存する場合、チェックポイント ファイルは、各エポックの終了時に、検証精度が上がっていた場合に保存されます。チェックポイントが作成されるたびに、PyTorch / XLA xm.save() ユーティリティ API がファイルをローカルに保存します。古いファイルがある場合は上書きします。次に、Cloud Storage Python SDK で、指定された $LOGDIR にファイルをアップロードします。古いファイルがある場合は上書きします。この例では、次のように関連情報のディクショナリが保存されます。
Cloud Storage SDK を使用して各モデルのチェックポイントを GCS にアップロードする関数を次に示します。
前のチェックポイントからトレーニングを再開するには、ダウンロードする GCS オブジェクトを LOAD_CHKPT_FILE 変数で指定し、このファイルを保存するローカル ディレクトリを LOAD_CHKPT_DIR 変数で指定します。モデルが初期化されると、torch.load() でディクショナリをシリアル化解除し、load_state_dict() でモデルのパラメータ ディクショナリを読み込みます。次に、.to(device) でモデルをデバイスに移動します。
Cloud Storage SDK を使用してチェックポイントをダウンロードし、ローカル ディレクトリに保存する関数を次に示します。
ディクショナリの他の情報を使用して、トレーニング ジョブを構成することもできます(最高検証精度とエポックを更新するなど)。
これらのファイルの保存や読み込みをしたくない場合は、コマンドライン引数から除外します。PyTorch / XLA チェックポイント ファイルの保存と読み込みの詳細については、こちらをご覧ください。
これで、トレーニングの準備が整いました。
--restart-tpuvm-pod-serverは XRT_SERVER(XLA ランタイム)を再起動します。これは、連続して TPU ジョブを実行するときに便利です(特に、サーバーが悪い状態で終わった後)。XRT_SERVER は Pod 設定を通じて不変なので、環境変数を受け取るにはサーバーを再起動する必要があります。test_train_mp_wds_cifar.pyは、PyTorch / XLA の分散マルチプロセス スクリプトによく似ていますが、WebDataset と CIFAR をサポートするように調整されていますTPU には Brain Floating Point Format のハードウェア サポートが含まれていて、
XLA_USEBF16=1を設定すると使用できます
トレーニング中の各ステップの出力は次のようになります。
10.164.0.25は、VM ワーカーの IP アドレスを表します[0]は、VM ワーカー 0 を表します。この例では、4 つの VM ワーカーを使用していますTraining Device=xla:0/2は、TPU コア 2 を表します。この例では 32 個の TPU コアを使用しているので、最大値はxla:0/31です(0 ベースであることにご注意ください)Rate=1079.01は、この TPU コアの 1 秒あたりサンプル数の指数移動平均を表しますGlobalRate=1420.67は、このエポックにてその時点までの、このコアの 1 秒あたりサンプル数の平均を表します
各エポックのトレーニング ループが終了すると、次のような出力が表示されます。
Replica Train Samplesは、このレプリカが処理したトレーニング サンプルの数を表しますReduced GlobalRateは、このエポックでのすべてのレプリカの GlobalRate の平均です
トレーニングが完了すると、次のような出力が表示されます。
ログは VM ワーカーごとに非同期で生成されるため、シーケンシャルに読み取ることは困難です。任意の TPU VM ワーカーのログをシーケンシャルに表示するには、次のコマンドを実行します。ここで、IP_ADDRESS は、上記の [0] の左に表示されているアドレスです。
結果を .txt ファイルに変換して GCS バケットに保存するには、次のようにします。
クリーンアップ
TPU VM リソースのクリーンアップは、簡単なコマンド 1 つで行えます。
まず、TPU VM を接続解除していない場合は接続解除します。
Cloud Shell で、次のコマンドを使用して TPU VM リソースを削除します。
GCS バケットとそのコンテンツを削除するには、Cloud Shell ターミナルで次のコマンドを実行します。
次のステップ
この記事では、分散ディープ ラーニング トレーニング ジョブでリモート ストレージを使用する際に生じる問題を調査しました。リモート ストレージ アクセスに関係する問題は、シャーディングされたシーケンシャル読み取り可能なデータ形式を使用して解決できます。また、この方法は、WebDataset ライブラリを使用すると PyTorch で簡単に実践できます。最後に、例を通じて、トレーニング データを GCS から TPU VM にストリーミングし、Cloud TPU Pod スライス上で PyTorch / XLA モデルをトレーニングする方法を示しました。
関連情報
このシリーズの次回の投稿では、今回の例をもう 1 度使って、Cloud TPU ツールでトレーニング ジョブをさらに最適化します。シャードサイズ、シャード数、バッチサイズ、ワーカー数などの変数が、入力パイプライン、リソース使用率、1 秒あたりのサンプル数、精度、損失、全体的なモデルの収束に与える影響を示します。
質問がおありの場合や、チャットをご希望の場合は、著者(Jordan、Shane)までご連絡ください。
このブログ投稿に関しては、Karl Weinmeister、Rajesh Thallam、Vaibhav Singh に協力をいただきました。また、Daniel Sohn、Zach Cain、および PyTorch / XLA チームの皆さんには、Cloud TPU での PyTorch エクスペリエンスの向上に尽力していただきました。ここに謝意を表します。
-機械学習スペシャリスト Jordan Totten
-カスタマー エンジニア Shane Hansen



