PyTorch Lightning 組み込みの TPU サポートの使用方法
Google Cloud Japan Team
※この投稿は米国時間 2021 年 4 月 10 日に、Google Cloud blog に投稿されたものの抄訳です。
Lightning フレームワークは、PyTorch の重要な一部を担っています。PyTorch Lightning は PyTorch の軽量ラッパーであり、PyTorch コードをモジュールに体系化し、一般的なタスクに役立つ関数を提供します。Lightning の概要や Google Cloud Platform 上での使い方については、こちらのブログ投稿をご覧ください。
Lightning の特筆すべき機能の一つに、コアモデル コードを変更することなく、任意のハードウェアでトレーニングができることが挙げられます。Accelerator API に、CPU、GPU、TPU、Horovod などのサポートが組み込まれていますが、独自のハードウェアをサポートするように API を拡張することもできます。
このブログ投稿では、いかに簡単に TPU で Lightning を使用してモデルのトレーニングを開始できるかをご紹介します。TPU(Tensor Processing Unit)は、モデルのトレーニングにかかる時間を大幅に短縮することができる特殊な ML プロセッサです。TPU を初めて使用する場合は、こちらの TPU のディープ ラーニングに特化した設計とはのブログ投稿をご覧ください。TPU のアーキテクチャや利点についてわかりやすく説明しています。

Google Cloud での PyTorch / XLA サポートの一般提供により、PyTorch と TPU ハードウェア間の橋渡しが実現しました。XLA(Accelerated Linear Algebra)は、モデルからの高度なオペレーションを、TPU の速度とメモリ使用量に最適化されたオペレーションにコンパイルします。PyTorch / XLA の Deep Learning Containers は、gcr.io/deeplearning-platform-release/pytorch-xla で入手可能であり、TPU で PyTorch を使用するために必要なすべてのものが事前構成されています。
ここまでコンセプトについて触れてきましたが、開始方法について見ていきましょう。まず、クラウド インフラストラクチャ(TPU ノードに接続されているノートブック インスタンス)の設定方法についてご説明し、続けて、その TPU ノードを PyTorch Lightning のトレーニングで使用する方法をご紹介します。
ノートブック インスタンスを設定する
最初に、ノートブック インスタンスを設定します。Cloud Console から [AI Platform] > [ノートブック] の順に移動します。[新しいインスタンス] から [インスタンスのカスタマイズ] を選択すると、より具体的な構成情報を提供できます。
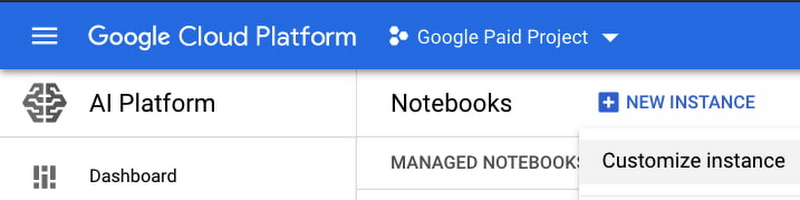
次に、リージョンとゾーンを選択します。その後の重要な入力項目には、次のものがあります。
環境: カスタム コンテナ
Docker コンテナ イメージ: gcr.io/deeplearning-platform-release/pytorch-xla.1-8
マシンの構成: n1-standard-16
[作成] を選択すると、ノートブック インスタンスのプロビジョニングを開始できます。
PyTorch / XLA の新しいイメージが提供されている場合は、それらをご利用いただけます。バージョンが、TPU ノードのバージョン(これから作成する)と一致することを確認してください。利用可能なイメージは、gcr.io/deeplearning-platform-release で閲覧できます。
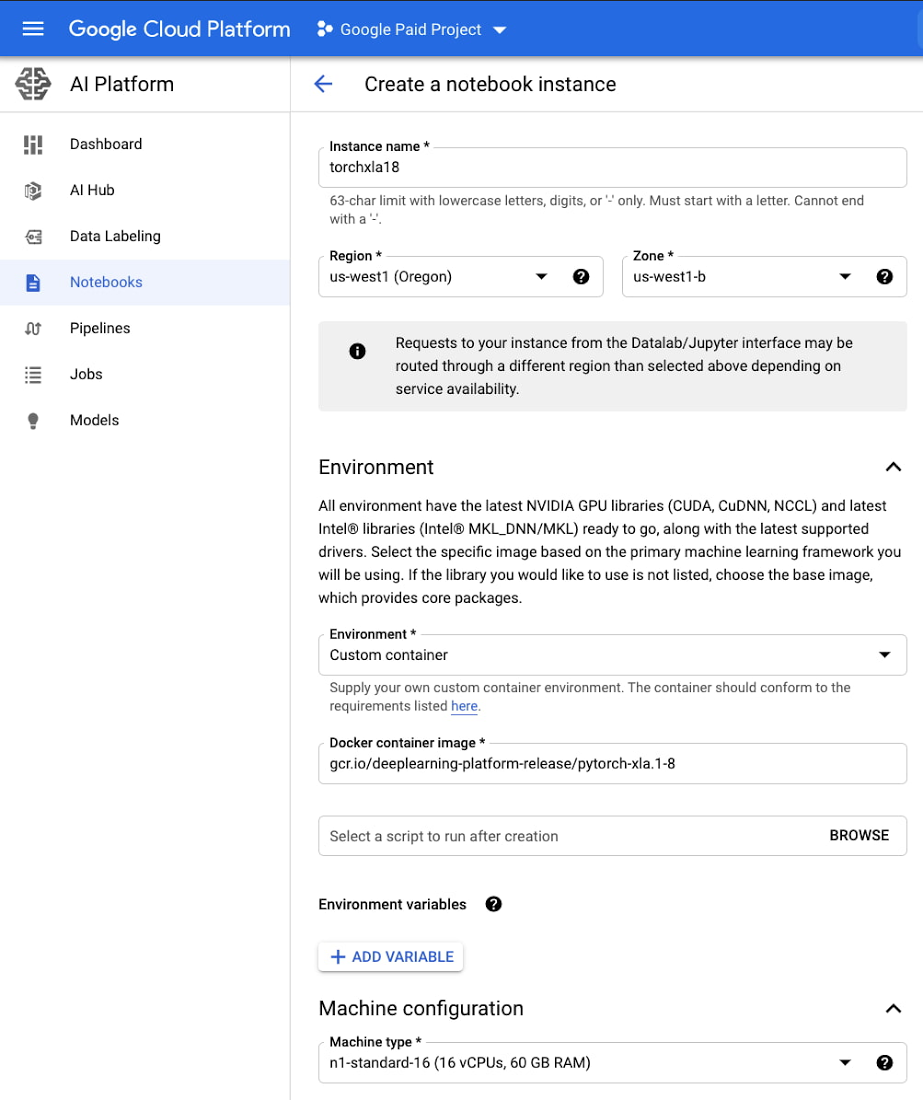
ノートブックがプロビジョニングされたら、[JupyterLab を開く] を選択して JupyterLab 環境にアクセスします。このチュートリアルのサンプルにアクセスする場合は、新しいターミナルを開いて([ファイル] > [新規] > [ターミナル])、以下のコマンドを実行します。
cd /home/jupyter
git clonehttps://github.com/GoogleCloudPlatform/ai-platform-samples
しばらくすると、左側のサイドバーが更新されます。サンプルは、[ai-platform samples] > [notebooks] > [samples] > [pytorch] > [lightning] 内にあります。
TPU ノードを設定する
次に、ノートブック インスタンスから使用できる TPU ノードをプロビジョニングします。Cloud Console から [Compute Engine] > [TPU] の順に移動します。[TPU ノードを作成] を選択して、任意の名前を入力します。[ゾーン] と [TPU タイプ] をそれぞれ選択します。なお、TPU の提供状況はリージョンごとに異なりますのでご注意ください。
[TPU ソフトウェア バージョン] には、ノートブックに選択したバージョンと一致するものを必ず選択します。この例では、pytorch-1.8 になります。また、このチュートリアルでは、[ネットワーク] に datalab-network を選択して、ネットワーク設定を構成せずにノートブック インスタンスから直接 TPU にアクセスできるようにします。
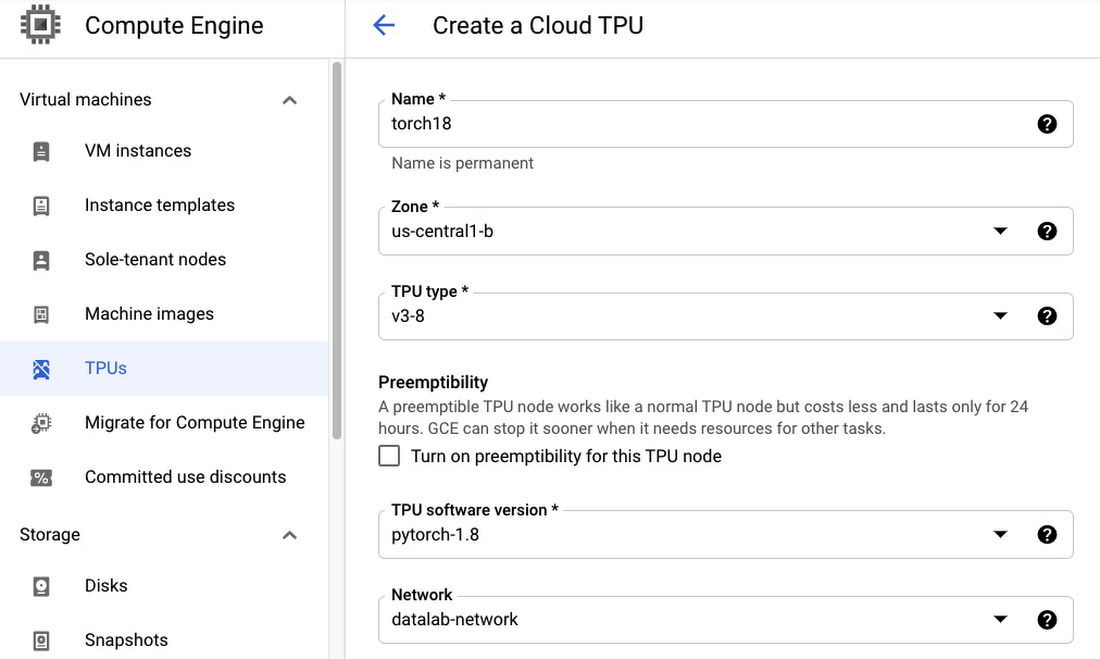
ノートブック インスタンスを TPU ノードに接続する
TPU がプロビジョニングされたら、サンプル ノートブックに戻ります。TPU 構成には、コメント化を解除できるいくつかのオプションのセルがあります。それらを詳しく見てみましょう。
まずは、作成した Cloud TPU の IP アドレスを確認します。ゾーンは TPU ゾーンに置き換えてください。
次の項目の値をメモします。
ACCELERATOR_TYPE: v3-8 が表しているのは、TPU タイプとコア数です。この例では、TPU タイプが v3、コア数は 8 になります。
NETWORK_ENDPOINTS: TPU ノードと通信できるように、この IP アドレスを環境変数に含める必要があります。サンプル ノートブックでこの変数を設定すると、次の行でこの変数がエクスポートされます。
%env XRT_TPU_CONFIG=tpu_worker;0;$tpu_ip_address:8470
基本的に、その環境変数 1 つをエクスポートできれば十分です。
TPU を使用してモデルをトレーニングする
Lightning は、LightningModule や LightningDataModule などのクラスを拡張することにより、PyTorch コードを体系化できるようにします。LightningModule に含まれているモデルコードは、さまざまなタイプのハードウェアで再利用できます。
Lightning Trainer クラスがトレーニング プロセスを管理します。データの反復バッチ処理や、損失の計算といった標準的なトレーニング タスクの処理のほかに、分散トレーニングにも対応できます。また、PyTorch の DistributedDataSampler を使用して適切なデータを各 TPU コアに分散したり、PyTorch の DistributedDataParallel 戦略を活用して、各コアにわたってモデルを複製し、適切な入力を渡して、各コア間の通信の差を管理したりすることもできます。
Trainer の作成時に、tpu_cores 引数を使用して TPU サポートを構成できます。TPU のコア数を渡すことも、使用する特定のコアを渡すことも可能です。

環境変数 XLA_USE_BF16=1 を設定することで、Brain Floating Point Format(bfloat16)を使用できます。bfloat16 は、実際には 32 ビット非浮動小数点形式と同じように動作し、メモリ使用量を削減してパフォーマンスを向上させます。詳細については、ブログ投稿 BFloat16: Cloud TPU で高パフォーマンスを発揮させる秘訣をご覧ください。
fit() メソッドを呼び出すだけでトレーニングを開始できます。
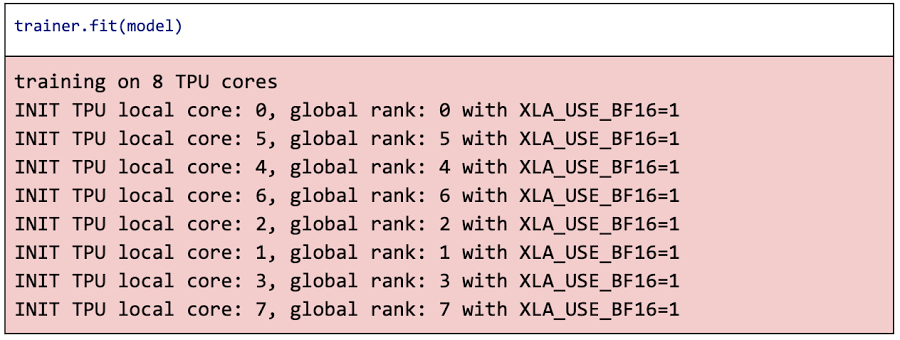
これで、推論に使用したり、本番環境のデプロイに向けてモデルファイルに保存したりすることができる、トレーニング済みの PyTorch モデルが作成されます。これらの方法について詳しくは、AI Platform Notebooks で直接開くことができるサンプル ノートブックをご確認ください。
このブログ投稿では、Google Cloud Platform で実行している PyTorch Lightning を使用することで TPU でのトレーニングを簡単にする方法を確認しました。また、TPU ノードを構成し、JupyterLab ノートブック インスタンスに接続する方法をご紹介し、さらに、任意のハードウェアで動作する再利用可能な同一のモデルコードを使用して、TPU コア間にわたって標準的な PyTorch の分散トレーニングを活用しました。簡単に使える TPU を活用して、さまざまな問題を解決していきましょう。
-デベロッパー アドボカシー担当マネージャー Karl Weinmeister



