PyTorch/XLA: Cloud TPU VM でのパフォーマンスのデバッグ(パート 3)
Google Cloud Japan Team
※この投稿は米国時間 2022 年 1 月 22 日に、Google Cloud blog に投稿されたものの抄訳です。
この記事は、Google Cloud TPU VM での PyTorch/XLA のパフォーマンス デバッグ エコシステムに関する説明の 3 回にわたるシリーズの最後のパートです。パート 1 では、まず PyTorch/XLA プロファイラを使用したトレーニング パフォーマンスについて判断するための重要な概念について説明し、最後に PyTorch 1.8 でのMulti-Head-Attention(MHA)の実装で遭遇した興味深いパフォーマンスのボトルネックについて解説しました。パート 2 では、最初に PyTorch 1.9 で導入され、パフォーマンスのボトルネックの解決に用いられた別の MHA の実装について説明し、プロファイラを使用した評価で示した動的グラフのサンプルを示すとともに、コンパイル時のペナルティとデバイスからホストへの転送の間に発生する可能性のあるトレードオフについて学習しました。
このパートでは話題を変えて、サーバーサイドのプロファイリングについて解説します。クライアントやサーバー関連の用語については最初のパートでも説明しましたが、サーバーサイドの機能は、TPU ランタイム(XRT サーバーともいう)やその後に(TPU デバイス上で)発生するすべてのコンピューティングを指します。このような分析の目的は多くの場合、ある特定のオペレーションや、TPU 上にある自分のモデルの特定のセクションのパフォーマンスを確認することです。PyTorch/XLA では、ユーザーのアノテーションによってこの確認作業を楽に行うことができます。アノテーションはソースコードに挿入でき、Tensorboard を使用してトレースとして可視化することが可能です。
環境の設定
ここまでの 2 パートで使用した mmf(マルチモーダル フレームワーク)を引き続き使用します。このパートから学習を開始した方は、パート 1 の「環境の設定」セクションをお読みのうえ、TPU VM を作成し、この投稿の「TensorBoard の設定」から続行してください。作業しやすくするため、コマンドについてここで復習します。
TPU VM インスタンスの作成(まだ作成していない場合)
インスタンスが作成されたら、次のコマンドを使用して、そのインスタンスに SSH 接続します。
TensorBoard の設定
SSH トンネリングによるポート転送に使用する SSH フラグの引数を確認します。この引数によって、お使いのブラウザで localhost:9009 を介してポート 9009 をリッスンするアプリケーション サーバーに接続できます。TensorBoard のバージョンを正しく設定して他のローカルのバージョンと競合しないようにするには、まず次のコマンドで既存のバージョンの TensorBoard をアンインストールしてください。
現在のコンテキストでは、アプリケーション サーバーはポート 9009 をリッスンしている TensorBoard のインスタンスです。
これで、お使いのブラウザで localhost:9009 からアクセス可能な TensorBoard サーバーが開始します。プロファイリング データはまだ収集されていませんので注意してください。ユーザーガイドの手順に従って、localhost:9009 の PROFILE ビューを開きます。
トレーニングの設定
このケーススタディでは、PyTorch / XLA 1.9 環境を中心に説明します。
代替手段を更新します(python3 をデフォルトにします)。
環境変数を構成します。
MMF トレーニング環境
Meta Research が開発した MMF(Multimodal Training Framework)ライブラリは、マルチモーダル(テキスト / 画像 / 音声)学習問題のモデルを研究者が簡単にテストできるように構築されています。 ロードマップに記載したとおり、この事例紹介では UniTransformer モデルを使用します。まず mmf ライブラリのクローンを作成してインストールします(再現性を持たせるために特定のハッシュを選択)。
mmf ライブラリをデベロッパー モードでインストールする前に、mmf のインストール時に既存の PyTorch 環境がオーバーライドされないよう、requirement.txt を以下のように変更してください。
validate_batch_sizes メソッド(この記事で選択した commit に固有のもの)に、以下のパッチを適用します。
mmf ライブラリをデベロッパー モードでインストールします。
Trace API
PyTorch/XLA プロファイラには、アノテーション(TensorBoard で後から可視化可能)を用いてコードのさまざまなセグメントを解析できる主要な API が 2 つ(StepTrace と Trace)あります。StepTrace や Trace を使用する場合は、まずプロファイラ サーバーを起動する必要があります。
プロファイラ サーバーを起動する
以下のコード スニペットでは、start_server (<port_number>) の呼び出しを導入するために、main メソッド mmf_cli/run.py を変更しました。このメソッドで返されるサーバー オブジェクトは、変数内に取り込まれた場合のみ保持されることに注意してください。そのため、server = xp.start_server(3294) に設定すると、開始されるプロファイラ サーバーがトレーニングの最後まで保持されます。しかし、何も割り当てをせずに起動サーバー xp.start_server(3294) のみを呼び出すと、サーバー オブジェクトが保持されないため、サーバーとやりとりができなくなります(後ほど、TensorBoard を介して所定の期間のプロファイルのキャプチャをサーバーに要求します)。
start_server を呼び出す際の引数として使用したポート番号をメモします(この場合は 3294)。このポート番号は、後のセクションでプロファイラ サーバーと通信する際に使用します。
トレースのアノテーションの挿入
mmf ライブラリをデベロッパー モードでインストールすると、このケーススタディを進めるために、次に示すようにソースコードを変更できます。
以下のコード スニペットでは、StepTrace および Trace アノテーションを示しています。StepTrace では特定のコンテキスト(Training_Step)を導入し、その中でさらに、Trace アノテーションを介してフォワード、バックワード、更新の回数をキャプチャする、ネストされた特定のコンテキストをいくつか導入します。
前のコード スニペットで示したとおり、xp は torch_xla.debug.profiler を xp としてインポートすることを指すことに注意してください。
トレーニングを開始すると、これらのアノテーションを xp.trace メソッドと TensorBoard プロファイラのプロファイルのキャプチャ機能のいずれかを使用してトレースにキャプチャできるようになります。このケーススタディでは、TensorBoard の機能を使用してプロファイルのインタラクティブおよび反復的なキャプチャを行います。開発テストの設定では、xp.trace を使用して TensorBoard の logdir にプロファイル データをキャプチャできますが、トレースのデータはすぐに大きくなるため、トレースの呼び出しは相応の期間しかアクティブにならないことに注意してください。
TensorBoard を起動する
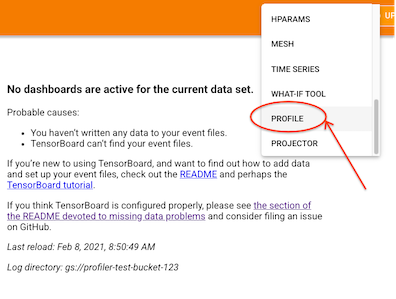
「TensorBoard の設定」セクションで述べた TensorBoard の設定手順を思い出してください。ポート 9009 から TensorBoard サーバーを起動しました。そして TPU VM に SSH 接続を行ったときに、localhost のポート 9009 を TPU VM の 9009 に転送しました。ブラウザで localhost:9009 を開くと、以下の UI が表示されます。
注: プルダウン メニューに [Profile] オプションが表示されない場合は、TensorBoard のバージョンをチェックして、設定セクションで説明した手順のとおりにプロファイラ プラグインがインストールされていることを確認してください。
トレーニングの開始
これまでと同じスクリプトを使用してトレーニングを開始しますが、1 か所だけ変更します。distributed world size を 8 に変更します(トレースで all-reduce を可視化するため)。
トレーニングが開始されると、以下のログ スニペットが表示されます。
プロファイルのキャプチャ
先ほど開始した TensorBoard の UI から、[Capture Profile] をクリックして、localhost:3294(start_server の呼び出しで指定したものと同じポート番号)を次のように指定します。
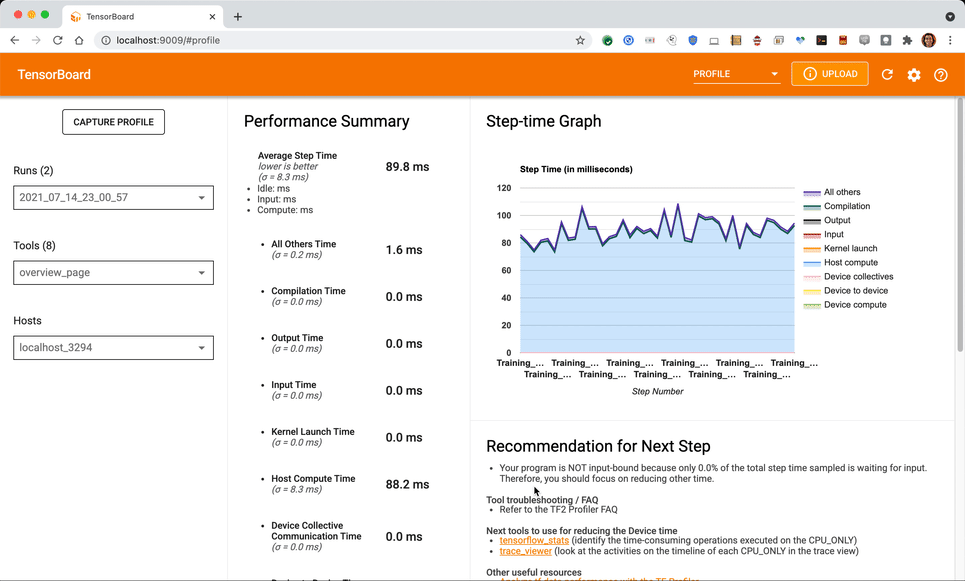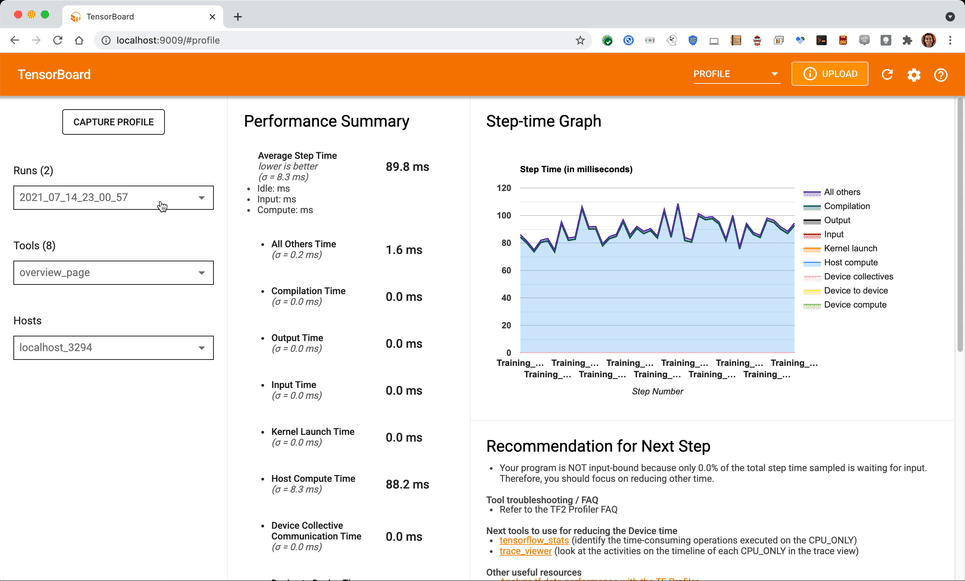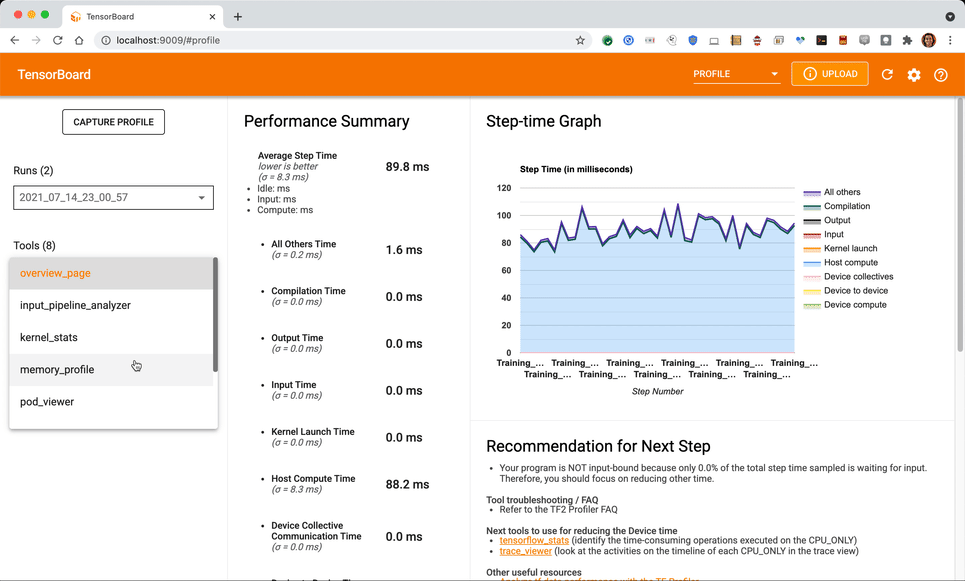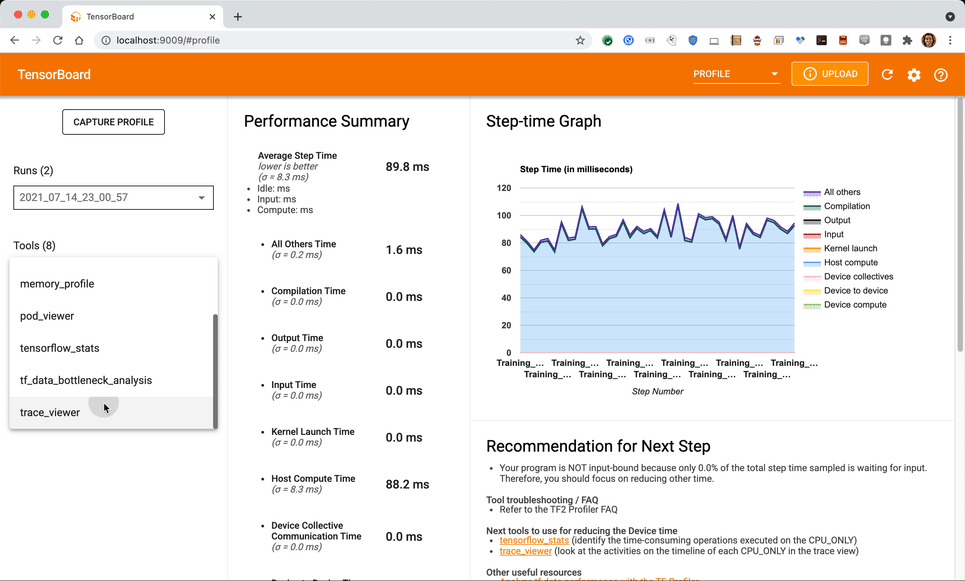
キャプチャが完了すると、以下のような概要ページが表示されるはずです(トレース内に 2 つ以上のトレーニング ステップがキャプチャされた場合は、概要ページが空白になる可能性があります。これは、入力パイプラインの推奨事項を満たすためには、最低 1 つのトレーニング ステップを完了する必要があるためです。
このケーススタディでは、トレース表示に注目して、他のビューについて詳しく見ていきます。(メモリ プロファイラや Pod ビューアなどについては、TensorBoard プロファイラに関するドキュメントを参照してください。)この記事の執筆時点では、TPU VM ではこれらの機能を完全にはサポートしていません。
Trace Viewer 内のアノテーションに移動する
Trace Viewer には、全デバイスから収集されたトレース(TPU プロセスなど)や全ホストから収集されたトレース(CPU プロセスなど)が表示されます。以下のように検索バーを使用して下にスクロールすると、ソースコードに導入したアノテーションを探すことができます。
トレースについて理解する
次の図は、コード スニペット例で作成したアノテーションを示しています。
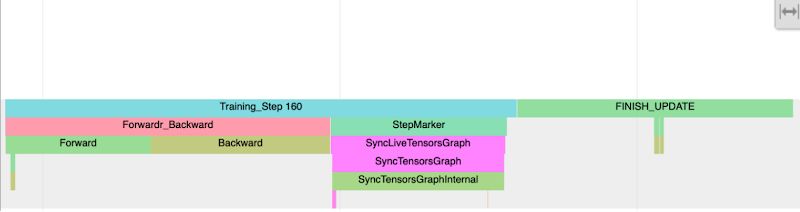
「Training Step」というトレースと、フォワードパスおよびバックワード パスのサブトレースに注目してください。CPU プロセスのトレースにあるこれらのアノテーションは、フォワードパスとバックワード パス(IR グラフ)の走査にかかった時間を示します。フォワードパスとバックワード パスによって早めの実行(低減しない op や値の取得)が強制される場合は、フォワード トレースやバックトレースが壊れて、StepMarker によって複数回挿入されていることが分かります。StepMarker は、mark_step() の暗黙的または明示的な呼び出しに対応する組み込みのアノテーションです。
FINISH_UPDATE トレースにも注目してください。mmf コードでは、これは縮小勾配および更新オペレーションに対応します。もうひとつ、TPUExecute 関数の呼び出しを開始しているホストプロセスがあります。
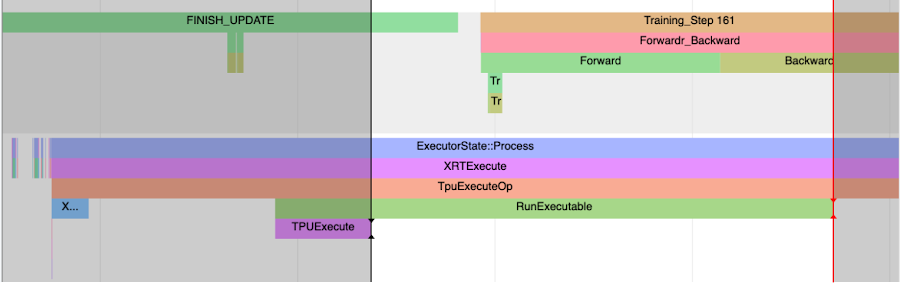
TPUExecute から RunExecutable トレースの最後までのウィンドウを作成すると、デバイスのグラフ実行と all-reduce のトレースが表示されます(最上部までスクロールして戻る)。
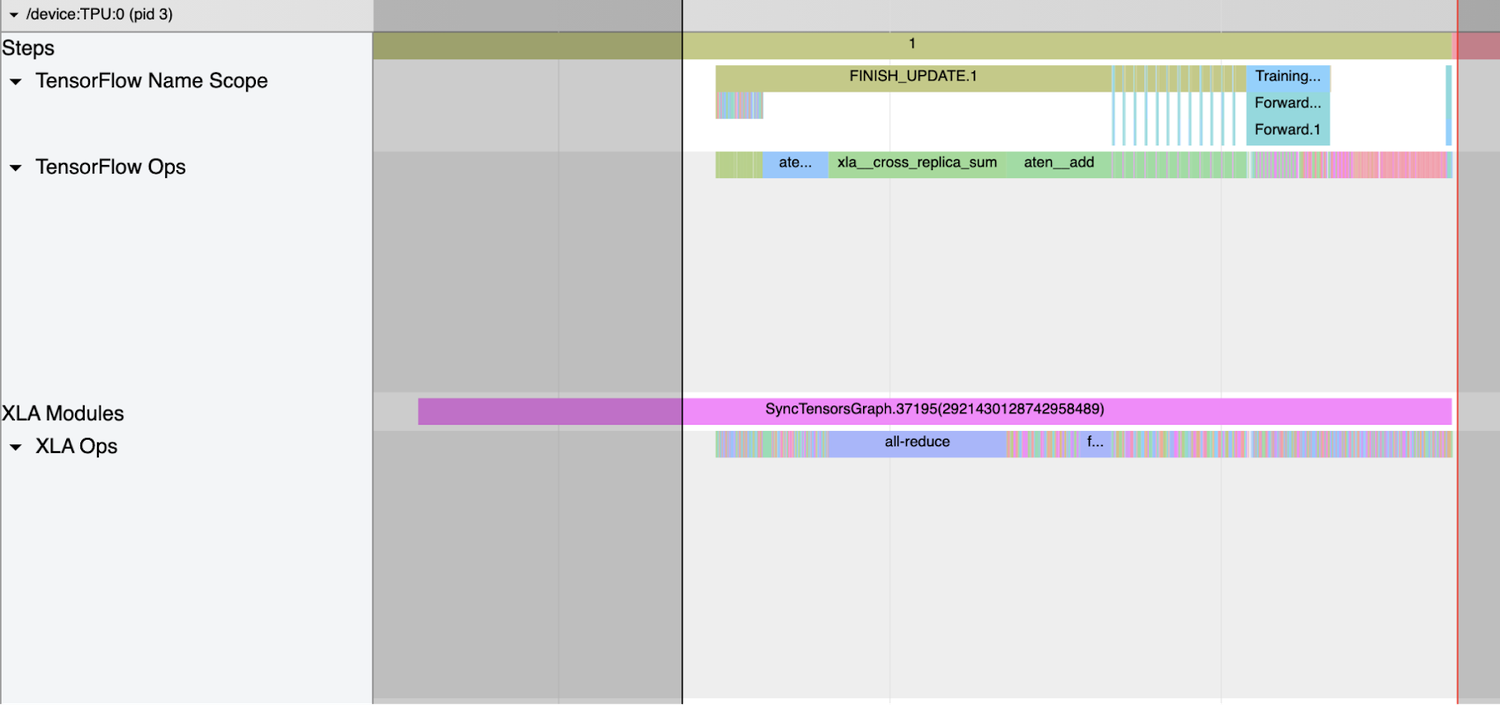
tensorflow op に表示されている all-reduce の xla_op および対応する all-reduce の cross_replica_sum に注目してください。XLA_HLO_DEBUG が有効になっていると、Tensorflow Name Scope と Tensorflow Ops がトレース内に表示されます(「トレーニングの開始」セクションのコード スニペットを参照)。ここには、HLO(High Level Operations)グラフに反映されたアノテーションが表示されます。
デバイスのトレースのギャップにも注目してください。デューティ サイクル(1 サイクルあたりのアノテーションされたトレースの割合)は、デバイスでグラフの実行にかかった時間の割合です。ギャップを調査するためには、Trace Viewer のウィンドウ ツールを使用してギャップの時間を選択し、CPU トレースを検証して、その時間に実行されている他のオペレーションを把握することをおすすめします。たとえば、次のトレースでは、デバイスのトレースが何も見られない 72.143 ミリ秒の時間を選択します。
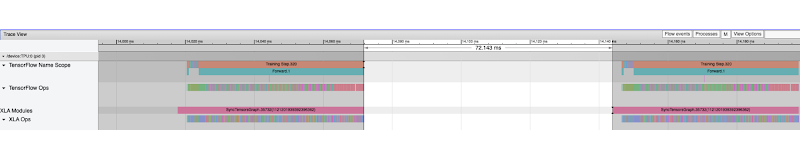
CPU トレース内の同じ時間(ビュー内で拡大)を検証すると、以下の 3 つの主な時間チャンクがあるのが分かります。
1. 次のステップの IR 生成(バックワード パス)と重複し、その後に StepMarker(mark_step())の呼び出しがある。MarkStep から PyTorch/XLA に対して、ここまでに走査された IR グラフが実行されることが通知されます。これが新しいグラフの場合、このグラフが最初にコンパイルされて最適化されます(StepMarker のトレースが長くなり、また別のプロセス トレースが「xxyy」とアノテーションされます)。
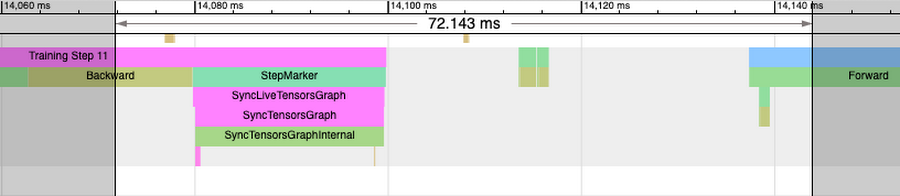
2. グラフとデータがサーバーに転送される(ホストから TPU デバイスに転送されるなど)。

TPU VM のケースでは、サーバーへの転送が妥当なオペレーションだと考えられます。
3. キャッシュが見つかった場合にそこからプログラム(グラフ)を読み込むか、入力グラフを読み込んで、最終的に TPU の実行をトリガーする XRTExecute が開始される。(XRTExecute や割り当て、プログラムの読み込み、署名については、このケーススタディでは取り扱いません)

また、現在のステップが TPU 上で実行されている間に次のステップの IR 生成がすでに開始されていることにも注意してください。
まとめると、デバイス トレース内のギャップは調査する必要がある領域です。前述の 3 つのチャンクやシナリオと別に、非効率的なデータ パイプラインが原因である場合もあります。調査の際には、コードのデータ読み込み部分にアノテーションを追加して、デバイスの実行についてトレース内でそのアノテーションを検査することも可能です。良質なパイプラインのためには、データの読み込みとサーバーへの転送がデバイスの実行と重複している必要があります。重複していない場合、デバイスがしばらくの間データを待ちながらアイドル状態になり、それが入力パイプラインのボトルネックになります。
アノテーションの伝播
PyTorch/XLA のトレーニングには HLO グラフに変換した IR グラフを使用します。このグラフはその後さらにランタイムによってコンパイルおよび最適化されますが、最適化の際にグラフの最初の構造は保持されないため、アノテーションが HLO グラフに伝播する(XLA_HLO_DEBUG=1 によって可能になる)と、それ以降これらのアノテーションは同じ順序では表示されません。たとえば、次のトレース(前述のトレースを拡大したもの)について考えてみましょう。

このウィンドウは、ホストプロセスの複数のフォワード トレースとバックワード トレースに対応していません(フォワード ステップ タグもトレーニング ステップ タグも表示されないとトレース内にギャップがあるのが分かります)。また、Training_Step、Forward および FINISH_UPDATE のトレースもこの中に散在しているのが分かります。これは、最初のアノテーションが伝播したグラフが、複数の最適化パスで処理されているためです。
まとめ
Profiler API を使用してホストとデバイスのトレースにアノテーションを伝播させる方法は、トレーニングのパフォーマンスを分析する際に大変便利な仕組みです。このケーススタディでは、この分析にかかるトレーニングの時間を削減するため、最適化に関する推論は一切行いませんでしたが、学習のために紹介のみ行いました。最適化によって、効率や TPU 使用率、デューティ サイクル、トレーニングの取り込みスループットなどが改善する可能性があります。
次のステップ
演習として、このケーススタディで行った分析を、log_interval を 1 に設定してもう一度行うことをおすすめします。この演習により、デバイスからホストへの転送コストと、ここで議論したいくつかの変更の効果を重点的に学習でき、トレーニングの最適なパフォーマンスが得られます。
これで、パフォーマンスのデバッグの 3 つのパートの 3 つ目を完了します。ここではパート 1 で説明したパフォーマンスの基本概念とコマンドラインのデバッグについて復習しました。パート 1 では、デバイスからホストへの転送の頻度が高すぎるために処理が遅い Transformer ベースのモデルのトレーニングについて調査しました。パート 1 の最後には、トレーニングのパフォーマンスを向上させるための演習を行いました。パート 2 では、まずパート 1 の演習の解答を解説し、パフォーマンスの低下の一般的なもうひとつのパターンである動的グラフについて考察しました。そして最後に今回の投稿では、アノテーションや TensorBoard の Trace Viewer を使用して、パフォーマンス分析についてより深く考察しました。このシリーズで解説した概念が、PyTorch/XLA プロファイラを使用したトレーニングのデバッグをより効率的に実行し、トレーニングのパフォーマンスを向上させるための行動につながるインサイトを導き出すうえで皆さんのお役に立てば幸いです。ぜひ、ご自身のモデルで実験し、ここでお話しした概念を適用して学習してみてください。
謝辞
執筆を辛抱強く寛大に待ってくれた Google の Jordan Totten、Rajesh Thallam、Karl Weinmeister および Jack Cao の各氏に感謝します。各氏からのたくさんのフィードバックがなければ、この投稿は間違いだらけのものになっていたことでしょう。特に Jordan には、このシリーズに挙げたケーススタディを辛抱強くテストし、数多くのバグを見つけ出し、貴重な提案をしてくれたことに感謝します。執筆中に励ましてくれ、特に投稿が長すぎると誰も読んでくれないから分けた方がいいとフィードバックをくれた Meta の Joe Spisak と Geeta Chauhan、Google の Shauheen Zahirazami と Zak Stone の各氏に感謝します。初期のリビジョンについてのフィードバックと質問を寄せてくれた Meta AI の Ronghong Hu 氏に感謝します。そのおかげで、特にトレースに関する議論がはるかに読みやすく有益なものになりました。そして最後に、MMF フレームワークを作成した Meta AI の Amanpreet Singh 氏に感謝します。デバッグに関するさまざまな議論へのインプットやケーススタディの選択、MMF での TPU の構築に関するインプットをいただきました。氏の力がなければ、このシリーズは実現しなかったことでしょう。
-機械学習スペシャリスト、アウトバウンド プロダクト マネージャー Vaibhav Singh



{kind=link}