PyTorch/XLA: TPU-VM でのパフォーマンスのデバッグ(パート 1)
Google Cloud Japan Team
※この投稿は米国時間 2022 年 1 月 6 日に、Google Cloud blog に投稿されたものの抄訳です。
この 3 回にわたるシリーズでは、Google Cloud TPU VM での PyTorch/XLA のパフォーマンス デバッグ エコシステムについて説明します。今年(2021 年)半ばの TPU VM。TPU VM アーキテクチャにより、ML 実務担当者は TPU ハードウェアが接続されているホストで直接作業できるようになります。TPU プロファイラが 2021 年半ばにリリースされたことで、TPU VM での PyTorch トレーニングのデバッグはかつてないほどシンプルになりました。パフォーマンスを分析するプロセスは変わりましたが、ネットワーク接続 TPU アーキテクチャ(別名 TPU ノード アーキテクチャ)で身につけた PyTorch/XLA の基礎は引き続き有効です。
この(最初の)パートでは、トレーニング パフォーマンスの観点から、PyTorch/XLA の概念的な枠組みについて概説します。なお、ここでいうトレーニング パフォーマンスとは、トレーニング スループット(つまりサンプル数/秒、画像数/秒、またはそれに相当するもの)を指します。ここでは事例紹介を通じて、予備的なプロファイラ ログを理解し、是正措置を特定します。パフォーマンスのボトルネックを解消する解答は、読者の演習用に残しておきます。
このシリーズのパート 2 では、パート 1 で演習用に残した解答について説明するとともに、他のパフォーマンス改善の機会を特定するためのパフォーマンス分析をさらに紹介します。
最後のパート 3 では、ユーザー定義コードのアノテーションを紹介します。こうしたアノテーションをトレースの形で可視化する方法と、トレースを理解するための基本的な概念を解説します。
このシリーズを通じて、Cloud TPU での PyTorch コードのパフォーマンスを分析する方法と、Cloud TPU を利用する際に考慮すべき点について理解を深めていきましょう。
はじめに
XLA テンソルの内部構造を理解すると、以降のコンテンツにアクセスしやすくなり、有用性が高まります。XLA テンソルについて簡単に確認するために、PyTorch Developers Day 2020 のこちらの講演と、Google Cloud Next のこちらの講演をご覧になることをおすすめします。また、PyTorch/XLA に馴染みのない方にはこちらの記事も参考になります。この記事は、読者が Google Cloud Platform SDK についてよく理解していることと、仮想マシンや Cloud TPU インスタンスなどのリソースを作成する権限で Google Cloud プロジェクトにアクセスできることを前提としています。プロファイラの概念の大部分はここで説明しますが、TPU VM プロファイラの入門的な資料を読むこともおすすめします。
PyTorch/XLA のクライアント サーバー テクノロジー
TPU ノード アーキテクチャ(TPU VM より前)と同様に、PyTorch XLA は依然として遅延テンソル パラダイムを使用しています。つまり XLA テンソルを使用しているとき、このテンソルに対して行われたオペレーションは単に中間表現(IR)グラフとして記録されます。ステップがマークされると(xm.mark_step() 呼び出し)、このグラフは XLA(HLO 形式 - High Level Operations)に変換され、実行するために TPU ランタイム(サーバー)にディスパッチされます。
なお、TPU ランタイムは TPU サーバーサイドの機能の一部であり、HLO グラフの生成までに行われる処理はすべてクライアントサイドの機能(以後このように呼びます)の一部です。TPU インスタンスを作成すると TPU ランタイム(サーバー)が自動的に起動した旧世代と異なり、TPU VM の場合は、トレーニングの送信時に PyTorch/XLA ライブラリがサーバーの起動を担当します。希望するポートで、XRT(XLA ランタイム)サーバーを手動で起動することもできます。したがって、後述するコード スニペットの XRT_TPU_CONFIG は、PyTorch/XLA が XRT サーバーを起動するデフォルト ポートを参照しています。旧世代と異なり、クライアントとサーバーは同じホストで動作しますが、抽象化は保持されており、パフォーマンスを把握するために役立ちます(詳細)。
事例紹介
コンテキスト
Facebook Research のマルチモーダル学習向けの MMF フレームワークを使用して、GLUE/QNLI タスクの UniT(Unified Transformer)トレーニングについて見ていきます。付随して PyTorch/XLA でのトレーニング パフォーマンスが最適とならないマルチヘッド アテンション実装の興味深い側面に触れ(PyTorch 1.8 で確認)、考えられる是正措置について説明します。
環境の設定
この事例紹介では TPU VM を使用しますので、以下の手順で作成します。次のコマンドを実行するには、マシンに Google Cloud Shell か、Google Cloud SDK がインストールされ、正しい認証情報がプロビジョニングされている必要があります(詳細については、TPU VM ユーザーガイドをご覧ください)。
TPU VM が作成されて READY 状態になったら、TPU VM ホストにログイン(ssh)し、TensorBoard プロファイラ プラグインをインストールして、TensorBoard サーバーを起動します。環境の設定については、TPU VM プロファイラ ユーザーガイドに記載されている手順をご覧ください。
トレーニングの設定
この事例紹介では 2 つの PyTorch 環境を使用します。PyTorch 1.8.1 で開始し、開発を進めながら PyTorch 1.9 に移行します。PyTorch 1.8.1 を開始点とするために、前のセクションで作成した TPU VM で次の手順を実施してください。
代替手段を更新します(python3 をデフォルトにします)。
環境変数を構成します。
MMF トレーニング環境
Meta Research が開発した MMF(Multimodal Training Framework)ライブラリは、マルチモーダル(テキスト / 画像 / 音声)学習問題のモデルを研究者が簡単にテストできるように構築されています。事例紹介のコンテキストに記載したとおり、この事例紹介では Unified Transformer(UniT)モデルを使用します。まず mmf ライブラリのクローンを作成してインストールします(再現性を持たせるために特定のハッシュを選択)。
mmf ライブラリをデベロッパー モードでインストールする前に、requirement.txt を以下のように変更してください(mmf のインストール時に既存の PyTorch 環境が上書きされないようにします。パッチを適用するには、以下のボックス内のテキストを patch-1.txt などのファイルにコピーし、mmf ディレクトリから git apply patch-1.txt を実行します)。
validate_batch_sizes メソッド(この記事で選択した commit に固有のもの)に対し、以下のパッチを適用します(前述の git apply を使用)。
mmf ライブラリをデベロッパー モードでインストールします。
デバッグの基本
どのようなときにトレーニングの時間が増大するのかを理解するために、次の 3 つの問いを考えてみます。
XLA コンパイルの数は、トレーニング ステップの数に応じて直線的に増加するか
デバイスからホストへのコンテキスト スイッチは直線的に増加するか
モデルは XLA 低減のない op を使用するか
こうした問いに答えるため、PyTorch/XLA には複数のツールが用意されています。これらの指標やカウンタを見つける最も簡単な方法は、クライアントサイド プロファイリングを有効にすることです。さらに詳しいレポートが必要な場合は、PyTorch/XLA トラブルシューティング ページで説明されているように、metrics_report を出力できます。多くの場合、PyTorch/XLA クライアントサイド プロファイラは出力した概要ログでこうした指標のいずれかに言及します。指標のログの例を次に示します。
こうした指標とカウンタについて理解を深めておくとさまざまな場面で役立つので、詳しく見ていきましょう。
デバッグの指標
CompileTime 指標
ここで注目すべき重要なフィールドは、TotalSamples、Counter、50% コンパイル時間です。TotalSample は XLA コンパイルが行われた回数を示します。Counter はコンパイルにかかった全体の時間を示し、50%= はコンパイル時間の中央値を示します。
aten::__local_scalar_dense カウンタ
このカウンタはデバイスからホストへの転送回数を示します。XLA コンパイルが完了すると、グラフの実行がデバイス上で行われます。ただし、ユーザーのコードの一部がテンソルの値を必要としないことに起因するデバイスからホストへの転送が発生するまで、テンソルはデバイス上に残ります。この手のインスタンスのよくある例としては、.item() 呼び出しや、if (...).any() ステートメントなどの値を必要とするコード内の制御構造が挙げられます。こうした呼び出しに遭遇した実行ポイントで、コンパイルと実行がまだ行われていないと、早期にコンパイルと評価が行われることとなり、トレーニングにさらに時間がかかります。
aten::<op_name> カウンタ
このカウンタは、その op が確認されたインスタンスの数を示します。接頭辞 aten:: は、この op の cpu/aten デフォルト実装が使用されており、XLA 実装を利用できないことを示します。中間表現(IR)グラフは XLA 形式に変換されてデバイス上で実行されるため、こうした op のインスタンスでのフォワードパスでは IR グラフを省略する必要があります。op への入力はデバイス上で評価され、ホストに送られます。op はその入力で実行されます。次に、op からの出力がグラフの残りの部分に差し込まれ、インスタンスの数と op の場所に基づいて実行が継続します。
TransferFromServerTime 指標
この指標の合計サンプル数は、デバイスからホストへの転送回数を示します。詳細な指標レポート(torch_xla.debug.metrics.metrics_report())では、デバイスからホストへの転送にかかった合計時間(アキュムレータ値)と、さまざまな分位数も報告されます。クライアントサイド プロファイリングのログでは、サンプルのカウント / 数のみが報告されます。この値がトレーニング ステップ数に応じて急激に(レート 1 以上)変化する場合、これは低減しない op(aten::*)やテンソル値を取得するコンストラクトがモデルまたはトレーニング コードに存在することを示します。
参考までに、PyTorch/XLA パフォーマンスの指標とカウンタの完全なリストを確認する方法を以下に紹介します。
基本事項についての説明は以上です。ここからは、学んだ概念を応用してみましょう。
テスト 0: デフォルト実行
mmf をインストールしたら、glue/qnli データセットでの UniTransformer モデルのトレーニングを開始できます。
ベスト プラクティス
デバッグの実行には TPU コアを 1 つだけ使用します。また、training.log_interval を 100 に設定します。通常、ロギングには 1 つ以上のテンソル値へのアクセスが伴い、テンソル値へのアクセスには、グラフの評価と、デバイスからホストへの転送が伴います。あまり頻繁に行われると、トレーニング時間に不必要なオーバーヘッドが生じる可能性があります。そのため、ロギングの間隔は、デバッグまたは開発といった一つのステージで区切らず、より大きく設定することをおすすめします。
観察
このトレーニングを実行すると、次のスニペットのようなログが出力されます。
1,500 ステップのトレーニングに 33 分以上かかり、最後の 100 ステップで報告された 1 秒あたりの更新数は 1.06 となっています。トレーニングの速度に満足できないため、調査を希望したとしましょう。ここで、PyTorch/XLA プロファイラが役立ちます。
テスト 1: クライアントサイド プロファイリングを有効にする
PT_XLA_DEBUG 環境変数は、クライアントサイド デバッグ機能を有効にします。つまり、この機能が有効になっていると、頻繁な再コンパイルやデバイスからホストへの転送が生じる可能性のあるユーザーコードの部分が、トレーニング中に報告され、最後に要約されます。
観察
クライアントサイド プロファイリングが有効になると、次のようなメッセージがトレーニング ログに出力されるようになります。
pt-xla-profiler とタグ付けされたログに注目してください。TransferFromServerTime(デバイスからホストへの転送)の頻度が高すぎることをプロファイラが報告しています。PyTorch XLA は遅延テンソル アプローチで動作するため、作成し最適化する PyTorch オペレーション グラフの実行は、ステップ マーカーが確認されるかテンソル値が取得されるまで(デバイスからホストへの転送)延期されます。前述のとおり、この転送が多すぎるとオーバーヘッドが増加します。わずか 1,500 ステップで 36,000 回も発生したとなると、確かに調査する価値があります。なお、これはステップ数/log_interval で直線的に増加すると予想できます。この係数がログで捕捉されているテンソル数より大きい場合、それはデバイスからホストへの転送数が、ログに記録されているものより多いことを意味します。これを減らすことで、パフォーマンスを改善できます。加えて、ログ間隔を大きくすることがほとんどの場合に有効なことも、この点からわかります。
また、トレーニングが完了した時点で(またはトレーニングが一度中断されたとき)、プロファイラがスタック トレースやフレーム カウント(グラフの差分を参照)など、概要をさらに提供していることにも注目してください。カウント 9,000 で「Equal」演算子が複数回出現しており、デバイスからホストへの転送が多いことと相関があるようです。また、出現回数が少ない「_local_scalar_dense」についても、「equal」op を調べた後に調査してみましょう。
スタック トレースは、マルチヘッド アテンション実装の以下のコードを指しています。
分析
torch.equal のマニュアル ページを見ると、次のようなことがわかります。
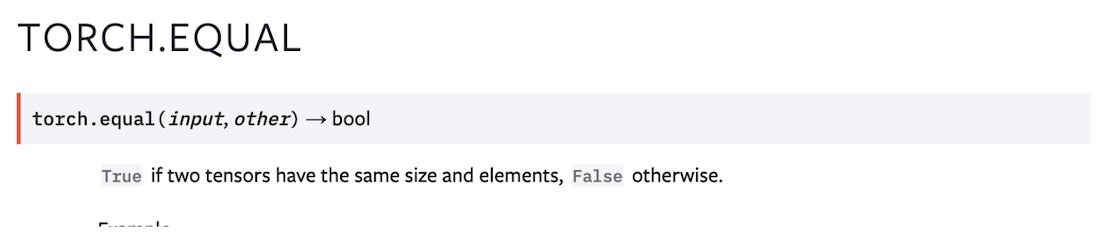
この演算子はスカラー値(ブール値)を返します。この演算子を if ステートメントで使用すると、PyTorch/XLA は、ブール値が使用されるグラフを推論する前に、このスカラー値につながるサブグラフを実行することになります。このコード スニペットはフォワードパスの一部であるため、サブグラフは、.equal 演算子のインスタンスの実行回数と同じだけ、ステップごとに評価されます。また、クライアントがグラフの残りの部分を作成できるように、実行結果をホストに転送する必要があります(デバイスからホストへの転送)。そのため、デバイスからホストへの転送のオーバーヘッドだけでなく、グラフの作成やコンパイルのパイプラインを遅くする大きなボトルネックが生じます。このような強制的な評価を、早期評価または過早評価といいます。
なお、テンソル オペランドのある == 演算子の場合、テンソルになります。== 演算子自体がグラフの一部になることがあります。そのため、== 演算子を使用しても早期評価にはなりません。ただし、テンソルの値がグラフに影響を与える場合(つまり動的なグラフを作成する場合)、キャッシュ保存によるグラフ コンパイル アプローチの利点がすぐに失われる可能性があります(詳しくはこちらの動画をご覧ください)。
考えられる是正措置
また、この MHA(マルチヘッド アテンション)に torch.equal を実装する手法は、GPU カーネルの最適化にも役立ちます。TPU のボトルネックを生じさせずにこの最適化を可能にする適切な解決策は、なんらかのパラメータ(トレーニング不可能なパラメータ、構成パラメータ)で torch.equal 呼び出しを装飾することです。考えられる解決策としては、こちらのような実装が挙げられます。ただし PyTorch 1.9 のコードは、テンソル比較(op)に移行して実装を単純化することで問題を修正しました。
次のステップ
今回は、PyTorch/XLA のパフォーマンスについて理解するために基本的な概念を紹介しました。また、.equal 演算子による強制的な実行に起因するパフォーマンスのボトルネックに関するテストも紹介しました。この場合に考えられる解決策としては、PyTorch コアコードの更新か、PyTorch のリリース 1.9 へのアップデートが挙げられます。実施にあたっては、こちらのユーザーガイドが参考になります。環境をアップデートした後は、テスト 1 をもう一度実施して、新しいパフォーマンス ログをメモしてください。この記事の次のパートでは、結果を確認し、パフォーマンスについてさらに掘り下げていきます。
それではまた次回お会いしましょう。質問がある場合やチャットを希望する場合は、LinkedIn からご連絡ください。
- Cloud カスタマー エンジニア、機械学習スペシャリスト Vaibhav Singh




