PyTorch/XLA: Cloud TPU VM でのパフォーマンスのデバッグ(パート 2)
Google Cloud Japan Team
※この投稿は米国時間 2022 年 1 月 13 日に、Google Cloud blog に投稿されたものの抄訳です。
この記事は、「PyTorch/XLA: TPU-VM でのパフォーマンスのデバッグ」シリーズのパート 2 です。前回の記事では、パフォーマンス分析の基本的な指標をご紹介しました。クライアント側のデバッグに PyTorch/XLA プロファイラを使用し、.equal() 演算子をマルチヘッド アテンション モジュールの実装内で使用することで、グラフの再コンパイルが頻繁に発生し、トレーニングの実行が遅くなる仕組みを特定しました。記事の後半では、考えられる対応を提示し、対応後のパフォーマンス分析について読者の演習の課題としました。この記事では、考えられる対応を振り返り、修正した場合のパフォーマンスを分析してさらに掘り下げていきます。
.equal() による遅延の解決
前回述べたように、MHA(マルチヘッド アテンション)に torch.equal を選択すると、GPU カーネルの最適化に役立ちます。TPU のボトルネックを生じさせずにこの最適化を行う方法としては、なんらかのパラメータ(トレーニングが不可能な構成のパラメータ)で torch.equal 呼び出しに制限をかけることが挙げられます。たとえば、このアプローチの例はこちらで確認できます。PyTorch 1.9 リリースでは、問題を修正するために、テンソル比較(is op)に移行するシンプルな別の実装が導入されました。PyTorch 1.9 以降のバージョンにアップグレードしてから、トレーニング スループットを確認します。
環境を PyTorch 1.9 にアップグレードする
この修正を適用し、さらに調査するために、PyTorch 1.9 にアップグレードします(以降のケーススタディで使用します)。
テスト 1: PyTorch 1.9 の .equal を修正してトレーニングを再実行する
PyTorch 1.9 環境では、MHA での .equal 演算子の問題が解決されました。トレーニングを再実行して、さらに調査を進めます。
結果
.equal op が修正されたため、トレーニング パフォーマンスの改善が見られます。1,500 ステップのトレーニングには 26 分以上かかり、最後の 100 ステップで報告された 1 秒あたりの更新数は 7.69 となっています。1 秒あたりの更新数は約 7 倍に改善されましたが、トレーニング時間の短縮は同程度には至りません。これは、最初の数ステップでのグラフの再コンパイルによるもので、トレーニングの実行速度には依然として遅延がみられます。ただし、数 100 ステップ後にはグラフのキャッシュ保存が功を奏し始め、1 秒あたりの更新数が高いレートで安定します。数 1000 ステップの測定ではトレーニング時間全体の改善に同様の要因が反映され始めます。
動的グラフ
パート 1 で説明した基盤では、遅延テンソルから記録される中間表現(IR)グラフは動的であることを説明しました。つまり、あるステップから次のステップへ頻繁に変化する場合(最悪のケースでは毎ステップ)、頻繁な再コンパイル(HLO グラフから LLO、さらに TPU 実行可能ファイルへのコンパイル)により PyTorch/XLA のパフォーマンスが低下します。このフレームワークは、一度コンパイルして頻繁に実行し、グラフのキャッシュ保存と XLA の最適化を高速化に利用できれば、最も効果的です。
このケーススタディでは、動的グラフを使用したシナリオを検証する機会もあります。実行のトレーニング部分が完了し、評価が開始されると、トレーニング時よりも評価時の速度の方があきらかに遅いことに気づくかもしれません。評価ではフォワードパスしか実行されないため、より高速であることが見込まれます。では、何が問題なのでしょうか?
通常、実行速度が遅くなる原因としては、デバイスからホストへ頻繁に転送が生じている場合とコンパイルの頻度が高い場合の 2 つがあります。PyTorch/XLA プロファイラを PT_XLA_DEBUG=1 で有効化すると、改善すべき部分の把握に役立つメッセージが取得できます。評価中には以下のようなメッセージが表示されます。
CompileTime 指標がステップ数に対して直線的に増加しているようです。つまり、調査すべき項目は、コンパイルの頻度が高くなっていないかということで、評価の元となるグラフは動的グラフであると判断できます。XLA による低減のない op の場合、デバイスからホストへの移行とコンパイル時間の両方が頻繁に発生します(演習として、どうしてそうなるかをご自身で確認してみることをおすすめします)。
この時点で、ソースコードの内容をある程度把握できていれば、コード内の動的構造について、正確な特定まではできなくとも大まかなあたりを付けられるはずです。調査に役立つように、ソースコードの動的構造と思われる部分の前後に、次の CompileTime 指標サンプルを出力するスニペットを挿入します。
ここで一度中断し、mmf ソースコードに動的構造の可能性がないか調べることをおすすめします(ヒント: 評価中にのみ発生します)。
数回程度繰り返すと、以下が検出されるはずです。
このサンプルの「self」は、レポートのオブジェクトを指します。評価ステップごとに、self[key] が既存の self[key] にテンソルを追加しています。このような演算は、グローバル指標のコンピューティングでは珍しいことではありません。
この問題の解決方法
動的グラフのサンプルはそれぞれ特有であるため、ここでは解決方法ではなく、分析を重視します。ただし、ここでは考察に役立つ一般的なアプローチをご紹介します。次のパターンについて考察しましょう。
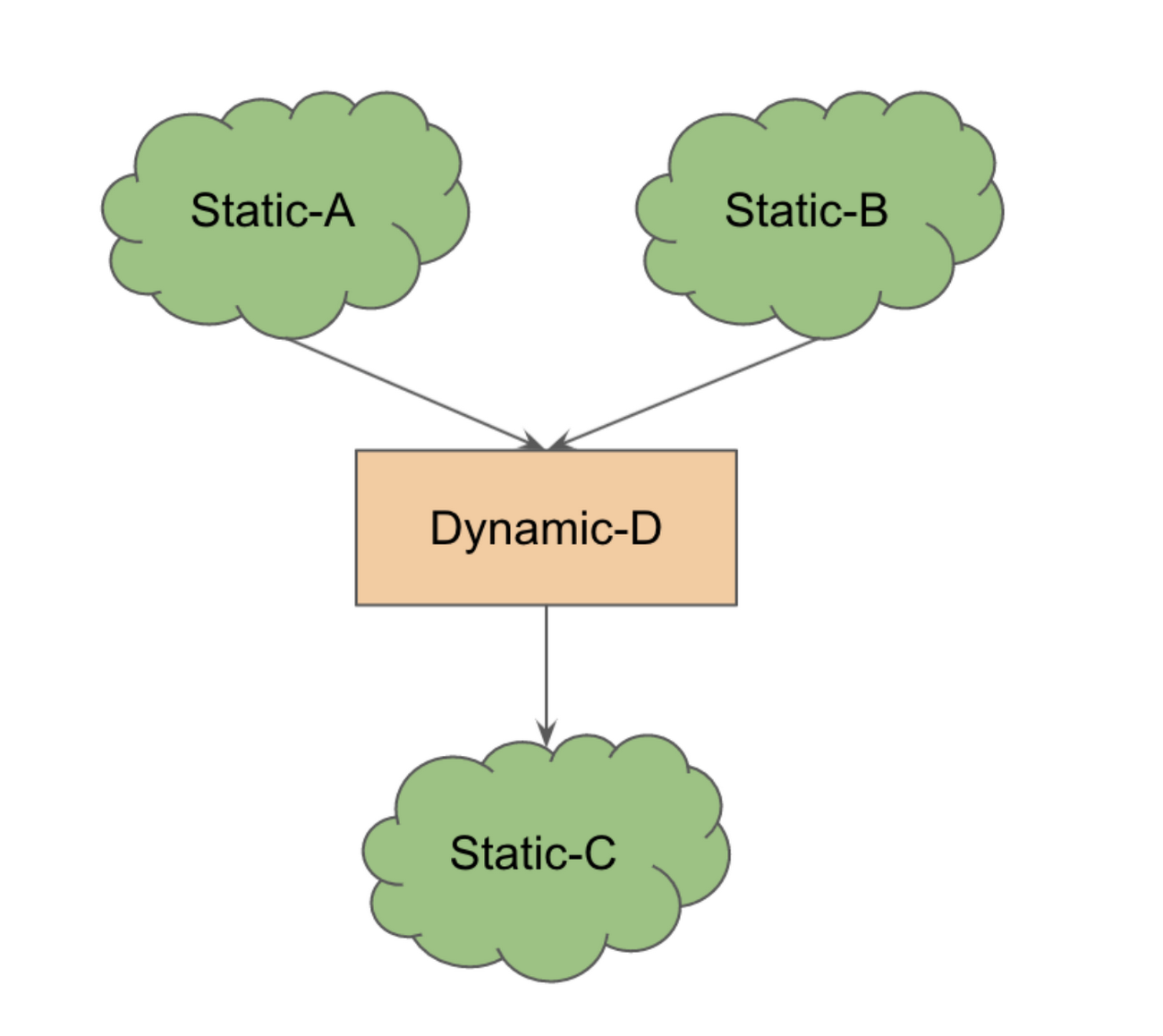
静的サブグラフ A と B は、動的な構造体 D に入力され、別のサブグラフ C に出力されます。このグラフ全体を一度に実行すると、動的コンポーネントのために再コンパイルがトリガーされます。しかし、ホスト(CPU)上で動的構造を実行する前に(デバイス上で)静的サブグラフを実行することが可能であれば、コンパイル時のペナルティとデバイスからホストに移行するペナルティをトレードオフできます。このトレードオフが大きい場合、全体の実行時間を引き続き高速化できます。
これは、同等の XLA 実装(低減 op)がない op に対して、PyTorch/XLA が自動的に使用するパターンです。前述のように、最善の方法は実行の各ステップで変更されないような動的構造の書き換えを検討することです。
幸いにも、mmf ライブラリでは、CPU 上でレポート オブジェクトの蓄積を行い、残りのグラフをデバイス(TPU)上で実行する CPU 実行機能が利用できます。これは次の方法で有効にできます。
すべてのフォワード Graph Execution は、レポート オブジェクトの蓄積を除いて引き続き TPU で実行されます。これにより、評価の大幅な高速化(5.81 sec/it から 23.56 it/sec)が生じることがわかります。また、ログに次のメッセージが表示されます。
これは、レポート オブジェクトの移行をホストする 1 つのデバイスで、複数の転送(レポート ディレクトリの各オブジェクトに 1 つ)が伴うことから想定されます。デバイスからホストへの転送が多数発生しますが、コンパイルも数百単位で削減されるため、速度が向上します。
次のステップ
このシリーズ記事は、パート 1 の演習から開始されており、PyTorch/XLA プロファイラから得た手がかりを使用して、実行時のボトルネックを検出し、これらのボトルネックの軽減方法について理解するためのコンセプトをいくつか紹介しました。この記事でご紹介した動的グラフのサンプルでは、グラフの特性により、コンパイル時のペナルティとデバイスからホストへの転送時のペナルティをトレードオフできました。このようなパターンは常に発生するわけではなく、モデルグラフの動的構造を可能な限り回避することがベスト プラクティスです。
演習として、プロファイラで報告された local_scalar_dense スタック トレースをより詳細に分析し、トレーニング パフォーマンスをさらに向上させる可能性のあるコードを研究することが推奨されます。このシリーズの最後のパートでは、サーバーサイドのプロファイリングとアノテーション トレースについて学習します。
それではまた次回お会いしましょう。質問がある場合やチャットを希望する場合は、LinkedIn からご連絡ください。
- 機械学習スペシャリスト、アウトバウンド プロダクト マネージャー Vaibhav Singh