Google Cloud でニーズに合った AI / ML 導入過程を選択する
Google Cloud Japan Team
※この投稿は米国時間 2022 年 6 月 7 日に、Google Cloud blog に投稿されたものの抄訳です。
組織の多くのユーザーが機械学習(ML)ライフサイクルで重要な役割を果たしています。プロダクト マネージャーは自然言語クエリを記述して BigQuery から必要な情報を引き出し、データ サイエンティストはモデルの構築と検証のさまざまな側面について検討し、ML エンジニアは本番環境でモデルを正常に動作させる責任を負っています。こうした役割には、それぞれ異なるニーズがあります。この投稿では、それらのニーズを満たすために利用できる Google Cloud ML / AI サービスについてご紹介します。
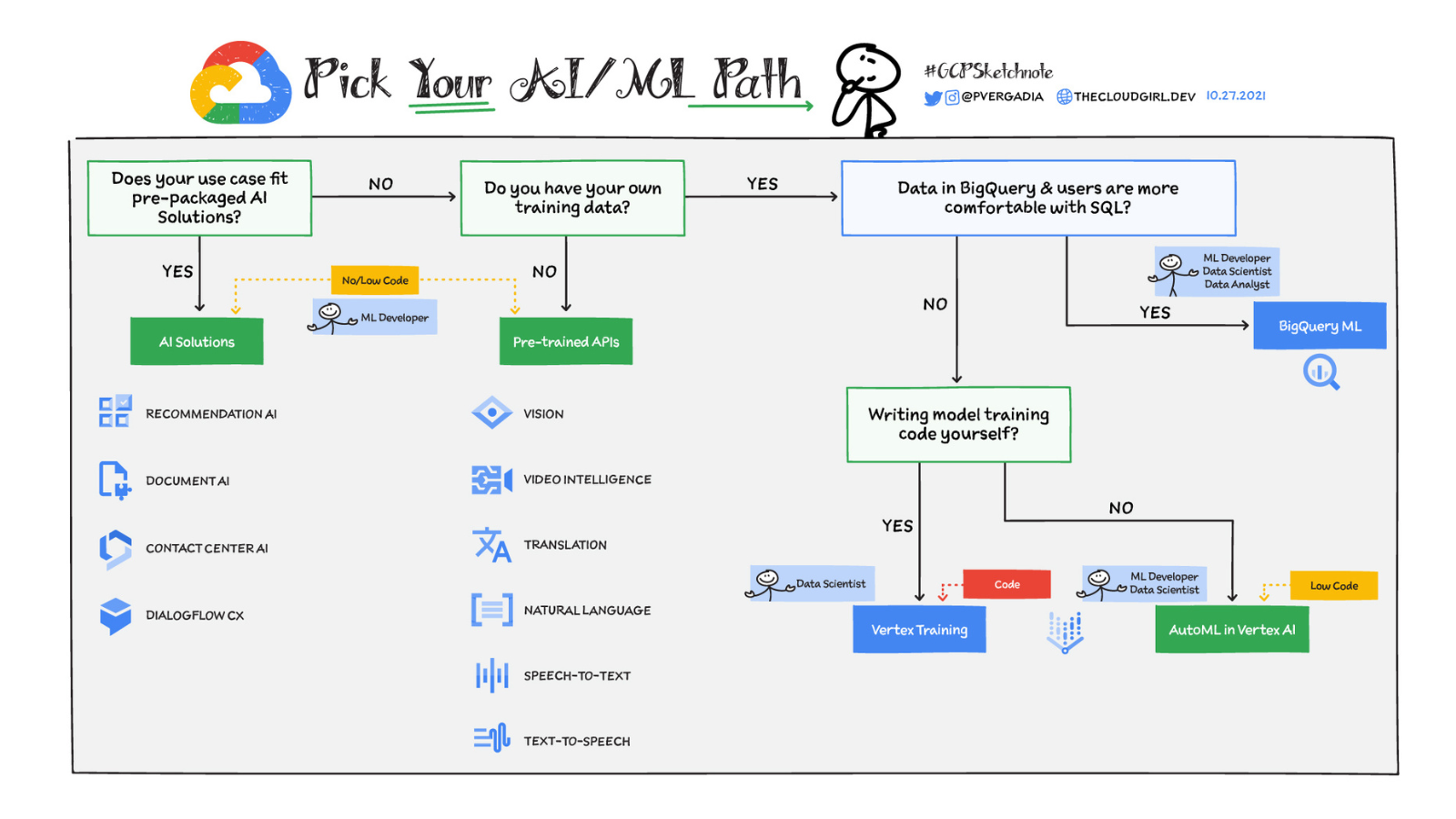
最適なサービスはユースケースとチームの専門知識のレベルによって異なります。高品質な ML モデルの構築とメンテナンスには多大な労力と ML の専門知識が必要になるため、一般的な経験則として、可能な場合、つまりユースケースに合う場合は、事前トレーニング済みモデルまたは AI ソリューションを使用します。データが構造化され、BigQuery に保存されていて、ユーザーが SQL に慣れている場合は、BigQuery ML を選択します。ユースケースで独自のコードを記述する必要がある場合は、Vertex AI でカスタム トレーニング オプションを使用します。ここでは、こうした選択肢についてもう少し詳しく説明します。
事前にパッケージ化された AI ソリューション
事前トレーニング済み API とパッケージ化された AI ソリューションは、いずれも過去に ML を使った経験がなくても利用できます。直接利用できるパッケージ化されたソリューションは 3 つあります。
Contact Center AI - デバイスやプラットフォームをまたいだ自然で豊かな会話環境を構築します。AI 搭載仮想エージェント、顧客対応から得られる分析情報、Agent Assist 機能を使用します。
Document AI - 非構造化データ(画像や PDF など)に対し、Google のコンピュータ ビジョン(OCR を含む)と自然言語処理(NLP)機能を使用してアクセスできるようにすることで、業務効率の向上、カスタマー エクスペリエンスの改善、情報に基づく意思決定を実現します。
Recommendations AI - 機械学習を使用して、すべてのタッチポイントで顧客のタイプや好みに合わせてパーソナライズされたおすすめ情報を提供できます。
事前トレーニング済み API
モデルのトレーニングに使用できるトレーニング データのない、動画、画像、テキスト、自然言語などの一般的な非構造化データのユースケースの場合、AI / ML のプロジェクトには事前トレーニング済みの API が最適です。事前トレーニング済みの API は、Google によって構築、調整、保守されている一般的な非構造化データの膨大なコーパスによってトレーニングされています。つまり、モデルの作成と管理について心配する必要はありません。
Vision AI - クラウドやエッジにある画像から有用な情報を AutoML Vision を使用して引き出し、事前トレーニング済みの Vision API モデルを使用して感情の検知、テキストの理解などを行います。
Video AI - 強力なコンテンツ検出機能と魅力的な動画体験を可能にします。
Translation AI - 高速で動的な機械翻訳機能を使用して、コンテンツとアプリの多言語対応を導入します。
Language AI - 自然言語理解(NLU)を使用して非構造化テキストから有用な情報を引き出します。テキストを抽出、分析、保存して、示唆に富んだテキスト分析を行います。
Speech-to-Text API - 音声を正確にテキストに(また Text-to-Speech API を使用してテキストを音声に)変換し、ユーザー エクスペリエンスを向上します。
BigQuery ML
トレーニング データが構造化され、BigQuery に保存されていて、ユーザーが SQL に精通している場合は、データ アナリストとデータ サイエンティストが BigQuery ML を使用して BigQuery の ML モデルを構築することになるでしょう。BigQuery ML で使用可能なモデルが、解決しようとしている問題に適しているかどうかを確認する必要があります。BigQuery ML では単純な SQL ステートメントを BigQuery インターフェースまたは API を通じて構築、トレーニングして、予測を行うことができます。
Vertex AI
Vertex AI はデータ サイエンスと機械学習向けのフルマネージドのエンドツーエンド プラットフォームです。自社のデータを使用した独自のカスタム モデルを作成する必要がある場合は、Vertex AI を使用します。Vertex AI のモデルのトレーニング オプションには、AutoML とカスタム トレーニングの 2 種類があります。どちらを選択するかは以下の要素から判断します。
ユースケース: ユースケースが AutoML でサポートされる機能に適している場合は、AutoML から開始するのがおすすめです。たとえば、ユースケースに画像、動画、テキスト、表形式などのデータタイプが含まれているユースケースの場合です。ただし、動画と表形式のメタデータなどが混在している入力タイプを受け入れるモデルの場合は、カスタムモデルを使用します。
要件: モデルのアーキテクチャ、フレームワーク、エクスポートしたモデルアセットを制御する必要がある場合(たとえば、モデルを TensorFlow または Pytorch で構築する必要がある場合)は、カスタムモデルを使用します。
チームの専門知識: ML / AI に関するチームの経験値を検討し、カスタムモデル構築の経験が限定的な場合、まず AutoML を理解してから、カスタムモデルの開発を検討してください。
チームの規模: データ サイエンスと ML を担当するチームの規模が小さい場合、AutoML の使用が適しています。カスタム モデルのコードは開発と保守に時間がかかるためです。
プロトタイピング: 最初のモデルを迅速に開発してこれをベースラインとして使用する場合は、AutoML を使用します。その後、このベースラインを本番環境のモデルとするか、それを改善してカスタムモデルを開発するかを判断します。
Service Directory の詳細については、こちらのドキュメントをご覧になるか、まず Vertex AI の動画で詳しい説明をご覧ください。また、本番環境に機械学習モデルをリリースするプロセスについて紹介する、6 月 9 日 午前 9 時(PST)開催の Applied ML Summit にもぜひご参加ください。

#GCPSketchnote をさらにご覧になるには、GitHub リポジトリをフォローしてください。同様のクラウド コンテンツについては、Twitter で @pvergadia をフォローしてください。thecloudgirl.dev もぜひご覧ください。
- Google、デベロッパー アドボケイト リード Priyanka Vergadia



