Opinary による Cloud Run を活用した高速なレコメンデーションの生成
Google Cloud Japan Team
※この投稿は米国時間 2023 年 1 月 11 日に、Google Cloud blog に投稿されたものの抄訳です。
編集者注: ベルリンを拠点とするスタートアップの Opinary は、機械学習パイプラインを Google Kubernetes Engine(GKE)から Cloud Run へと移行しました。アーキテクチャの変更をほんの少し加えた後、パイプラインはより高速かつ、費用効率のよいものになりました。レコメンデーションの生成にかかる時間が 20 秒から 1 秒に短縮され、驚くことに、50% の費用削減を実現しました。
この投稿では、Doreen Sacker 氏と Héctor Otero Mediero 氏が、移行について詳細で透明性の高いテクニカル レポートを紹介します。
Opinary が読者に訊ねる、読者エンゲージメントを増やすための適切な質問
Opinary の読者アンケートは世界中のニュース記事に掲載されています。このアンケートでは、1 クリックで意見を共有でき、他の読者と比較することができます。機械学習を活用して、最も関連性のあるアンケートを自動で追加します。
私たちは、このアンケートが、パブリッシャーの読者リテンションの増加、サブスクリプションの増加、その他の記事の成功指標の向上に役立つことに気づきました。広告主は、プレミアム パブリッシャーのサイトでターゲット グループにコンテキストに基づいてアクセスし、オーディエンスとの効果の高いインタラクションから利益を得ることができます。
アンケートについて例を見てみましょう。お気に入りのニュースサイトで、高速道路に速度制限を設けるべきかどうかについての記事を読んだと想像してください。ご存じかもしれませんが、ドイツのアウトバーンの大部分では未だに法廷速度が定められておらず、このことが激しい議論を呼んでいます。スピードを出すことを批判する人は、環境への影響や死傷者数について指摘しています。Opinary は、このアンケートを記事に追加しました。
レコメンデーション システムのアーキテクチャについてもっと知る
GKE で元々どのようにシステムを構築しているかについて説明します。私たちのパイプラインは記事の URL から始まり、記事に追加するおすすめのアンケートを配信します。これを実現するためのさまざまなコンポーネントについて、さらに詳しく見ていきましょう。これがビジュアル概要です。
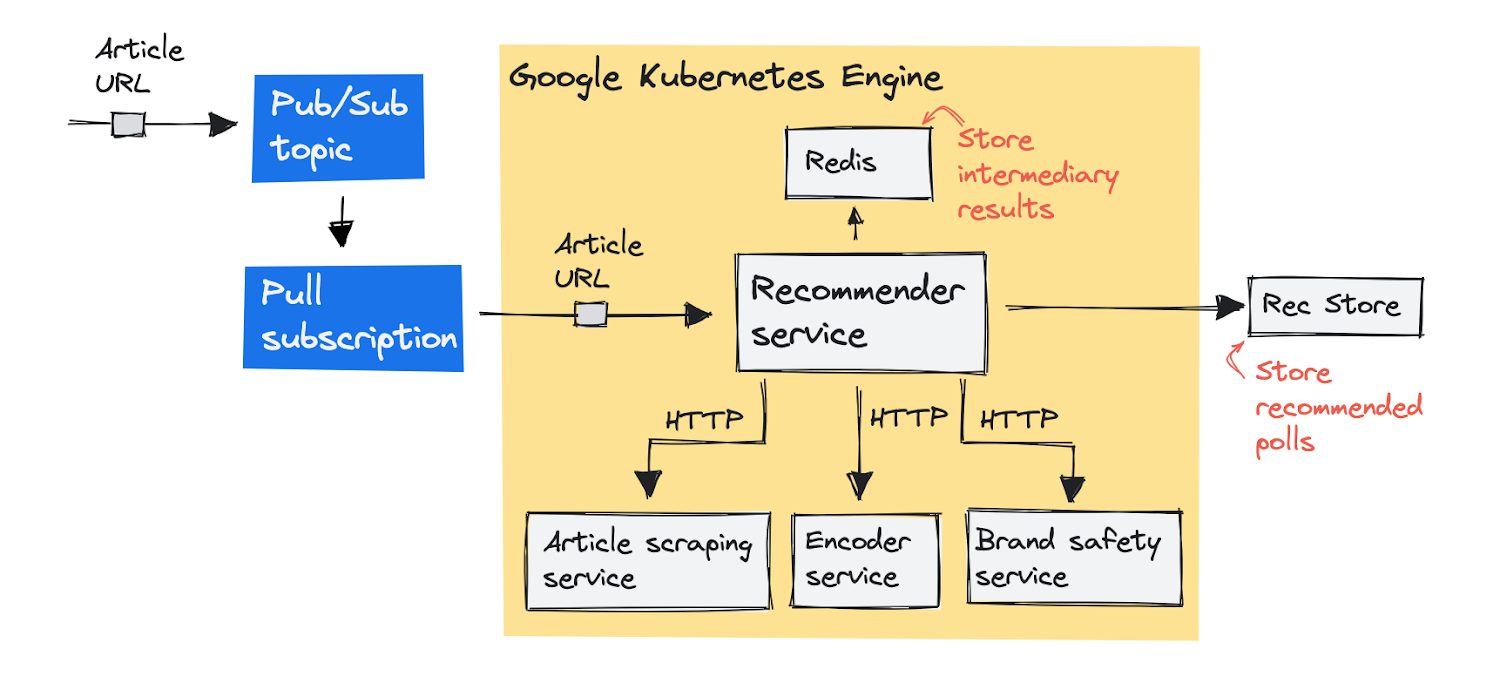
最初に、記事の URL を記載したメッセージを Pub/Sub トピック(メッセージ キュー)に push します。Recommender サービスは、メッセージを処理するために、メッセージをキューから pull します。サービスがアンケートを推奨する前に、個々のサービスに分かれたいくつかのステップを完了させる必要があります。Recommender サービスは、これらのサービスにひとつずつリクエストを送信し、Redis ストアにその結果を保存します。手順は以下のとおりです。
記事スクレイピング サービスが URL から記事のテキストをスクレイピング(ダウンロードと解析)します。
エンコーダ サービスが、テキストをテキスト埋め込みにエンコードします(ユニバーサル センテンス エンコーダを使用します)。
ブランド保護サービスは、記事本文に、死、殺人、事故などの悲惨な出来事が含まれるかどうかを検出します。このような記事にはアンケートを追加したくないからです。
この 3 つの手順が完了すると、レコメンデーション サービスは、既存のアンケートのデータベースからアンケートを推奨し、Rec Store と呼ばれる内部データベースに送信できるようになります。以上が、ドイツのアウトバーンの速度制限導入に関するアンケートの追加を推奨した手順になります。
Cloud Run への移行を決めた理由
Cloud Run が魅力的に映ったのは 2 つの理由がありました。1 つ目は、リクエストがない場合、自動的にコンテナ インスタンスをゼロまでスケールダウンするので、費用を削減できると思ったからです(実際、そのようになりました)。2 つ目は、私たちのチームは専属のデータ エンジニアがいないため(私たちは二人ともデータ サイエンティストです)、基盤となるインフラストラクチャについて心配することなく、フルマネージド プラットフォームでコードを実行できるというアイデアを気に入ったからです。
Cloud Run は、フルマネージド プラットフォームとして、デベロッパーの生産性を高めるように設計されています。これは、Google のインフラストラクチャ上で直接、コンテナ内のコードを実行できるサーバーレス プラットフォームです。デプロイは高速で、自動化されています。コンテナ画像の URL を入力すると、数秒後にコードがリクエストを送信します。
Cloud Run は、受信するすべてのリクエストやイベントを処理するために、自動でより多くのコンテナ インスタンスを追加し、不要になれば削除します。これは費用効率が良く、さらに、Cloud Run ではリクエストを提供しないコンテナのリソースに対しては料金が発生しません。
GKE から移行した主な動機は、この従量制の費用モデルでした。私たちは、使ったリソースの分だけ支払いたいのであり、夜間の大規模なアイドル状態のクラスタにはお金をかけたくありません。
わずかな変更で Cloud Run への移行を可能にする
わずかな変更で、GKE から Cloud Run へサービスを移行できました。
Pub/Sub サブスクリプションを pull から push へ変更。
クラスタ内のセルフマネージド Redis データベースをフルマネージド Cloud Memorystore インスタンスへ移行。
最初のターゲット アーキテクチャを図にすると、次のとおりです。
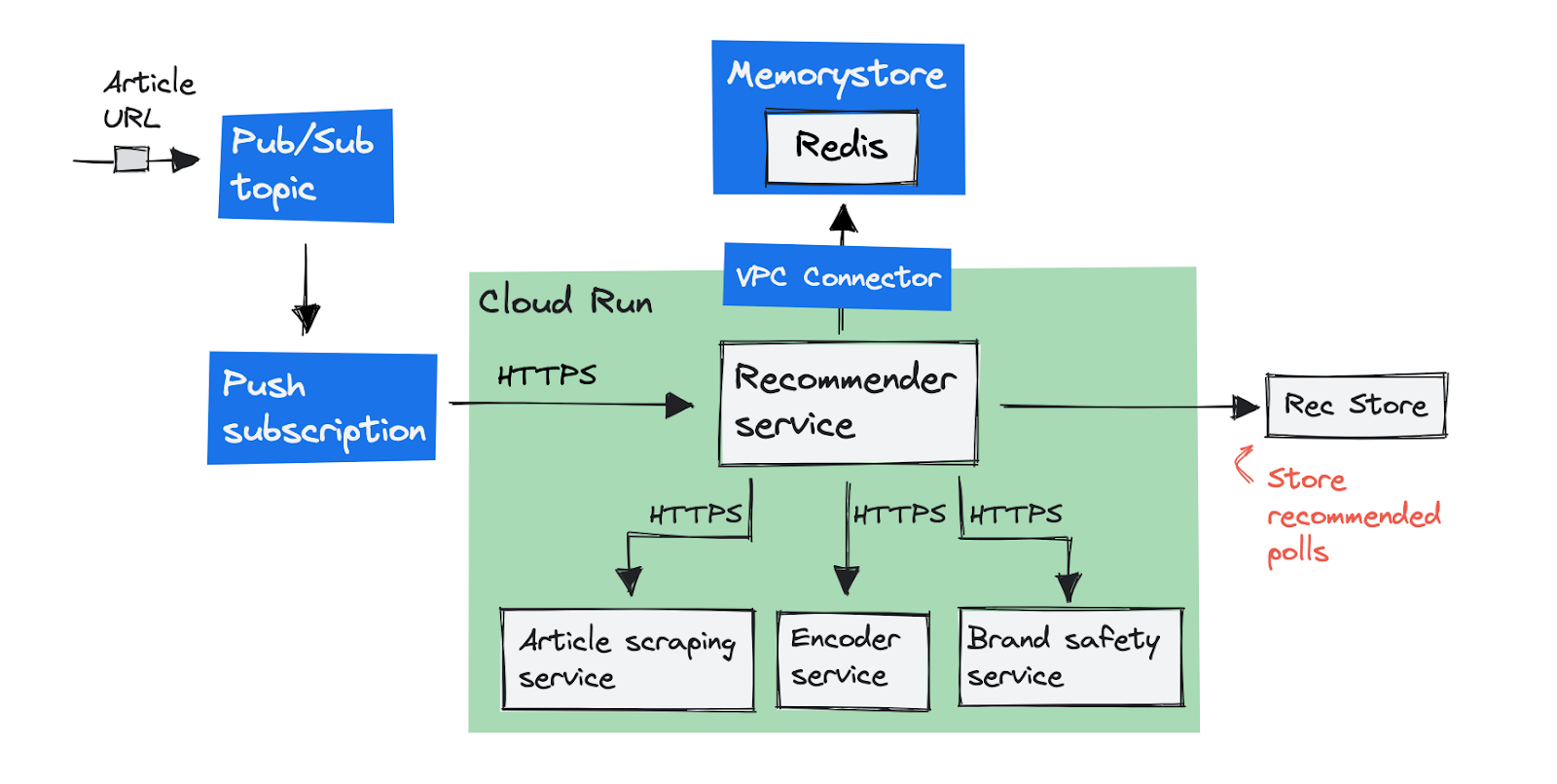
Pub/Sub サブスクリプションを pull から push へ変更
Cloud Run サービスは、受け取るウェブ リクエストにスケールするので、コンテナはリクエストを処理するためのエンドポイントを必要とします。Recommender サービスは、もともと Pub/Sub クライアント ライブラリを使用してメッセージを pull していたので、リクエストを処理するためのエンドポイントを持っていませんでした。
Google は、Pub/Sub から Cloud Run をトリガーする際、pull サブスクリプションの代わりに push サブスクリプションを使用することを推奨しています。push サブスクリプションでは、Pub/Sub はメッセージをリクエストとして HTTPS エンドポイントに配信します。これは Cloud Run である必要はなく、任意の HTTPS URL であることにご注意ください。Pub/Sub は、エラーになったリクエストやレスポンスが遅いリクエストを再試行することで、メッセージの送信を保証します。(構成可能なデッドラインを使用)
Cloud Memorystore Redis インスタンスのご紹介
Cloud Run は、すべての受信リクエストを処理できるように、コンテナ インスタンスを追加または削除します。Redis は HTTP リクエストを送信せず、オンデマンドで開始する使い捨てのコンテナの代わりに、永続的ボリュームに接続されたひとつもしくは複数のステートフル コンテナ インスタンスを持つことを好みます。
私たちは、クラスタ内の Redis インスタンスを置き換えるために Memorystore Redis インスタンスを作成しました。Memorystore インスタンスは、プロジェクトの VPC ネットワーク上に内部 IP アドレスを持っています。Cloud Run 上のコンテナは VPC の外部で動作します。つまり、VPC 上 の内部 IP アドレスに到達するためのコネクタを追加する必要があるということです。詳細はサーバーレス VPC アクセスについてのドキュメントをご覧ください。
Cloud Trace を使用してより高速に
移行の最初の部分はスムーズに進みましたが、システム改善への希望を持ちながらも、レコメンデーションを生成するのに約 20 秒かかる状態が続いていました。
私たちは、リクエストがどこで時間を費やしているのか知るために Cloud Trace を活用しました。そして、以下のことが判明しました。
1 つのリクエストを処理するために、コードが Redis に行ったリクエストは約 2,000 件でした。これらのリクエストを 1 つにまとめることで、大きな改善となりました。
VPC コネクタには、ネットワーク スループットのデフォルトの上限があり、その上限は私たちのワークロードに対してかなり低いものでした。より大きいインスタンスを使用することで、レスポンス時間が改善されました。
以下のように、この変更を展開すると顕著なパフォーマンスの向上がみられました。
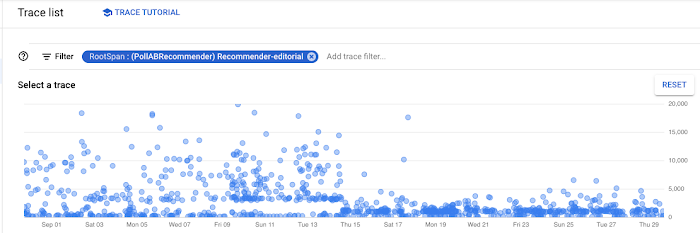
レスポンスを待つ時間に費用がかかる
上記の変更により、スケーラブルで高速なレコメンデーション生成が実現しました。そして、レコメンデーション生成の平均時間を 10 秒から 1 秒以下に短縮することができました。しかしレコメンデーション サービスは、他のサービスからのレスポンスを待っている間に何もしない時間が長く、多くの費用がかかるようになってしまいました。
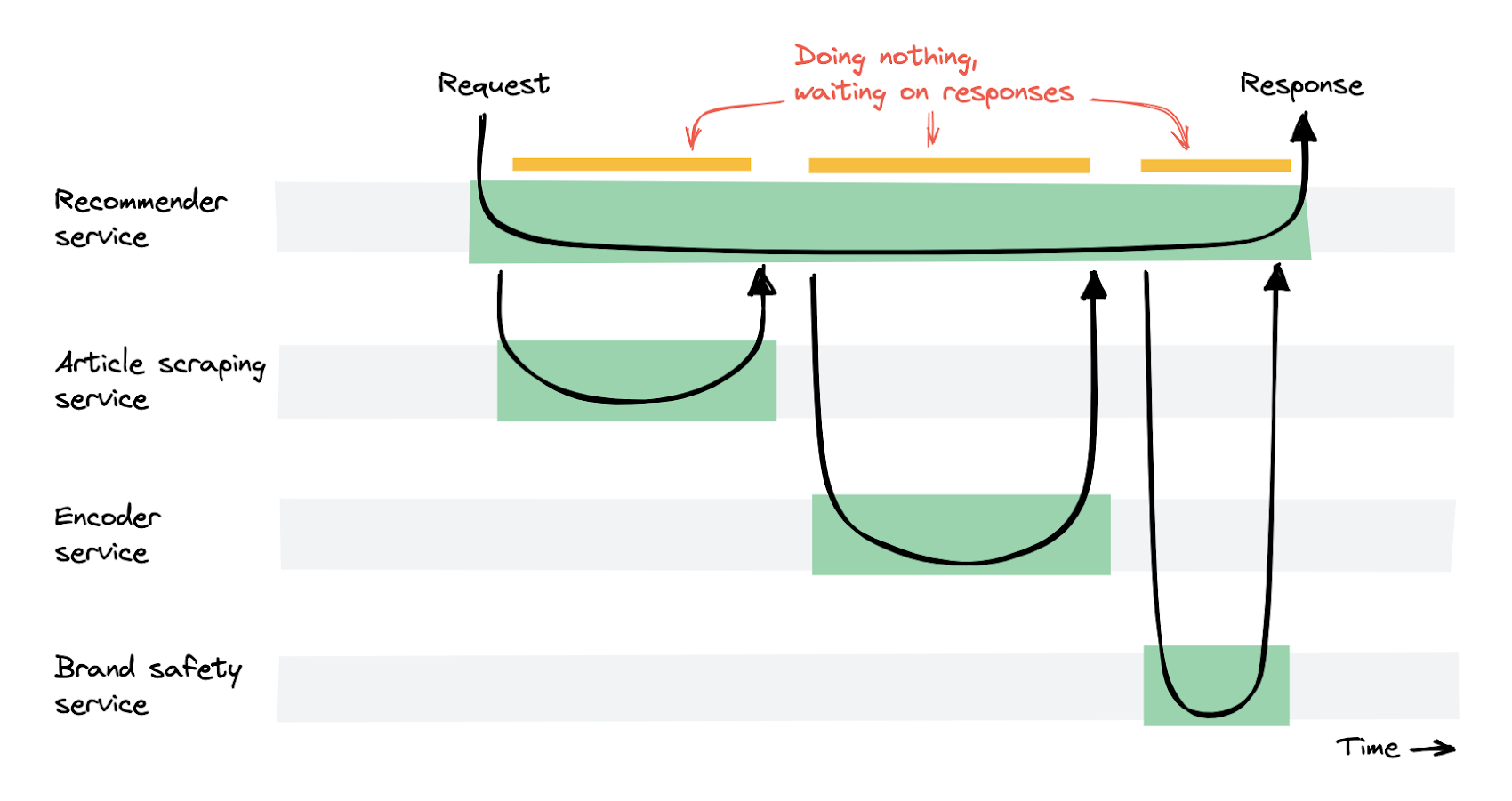
Recommender サービスは、リクエストを受け、他のサービスからのレスポンスを待ちます。結果として、Recommender サービスの多くのコンテナ インスタンスは、実行されているのにもかかわらず本質的には何もしておらず、ただ待っているだけの状態になっていました。そのため、Cloud Run の従量制費用モデルでは、多くの費用がかかってしまいます。従来の Kubernetes の設定と比較すると、費用は 4 倍になりました。
アーキテクチャを再考する
費用を削減するために、アーキテクチャを再考する必要がありました。レコメンデーション サービスは、他のすべてのサービスにリクエストを送信し、そのレスポンスを待ちます。これは、オーケストレーション パターンと呼ばれるものです。各サービスを独立して動作させるために、コレオグラフィ パターンに変更しました。それぞれのサービスが次々とタスクを実行する必要がありましたが、ひとつのサービスが他のサービスの完了を待つようなことはありませんでした。最終的にこのようになりました。
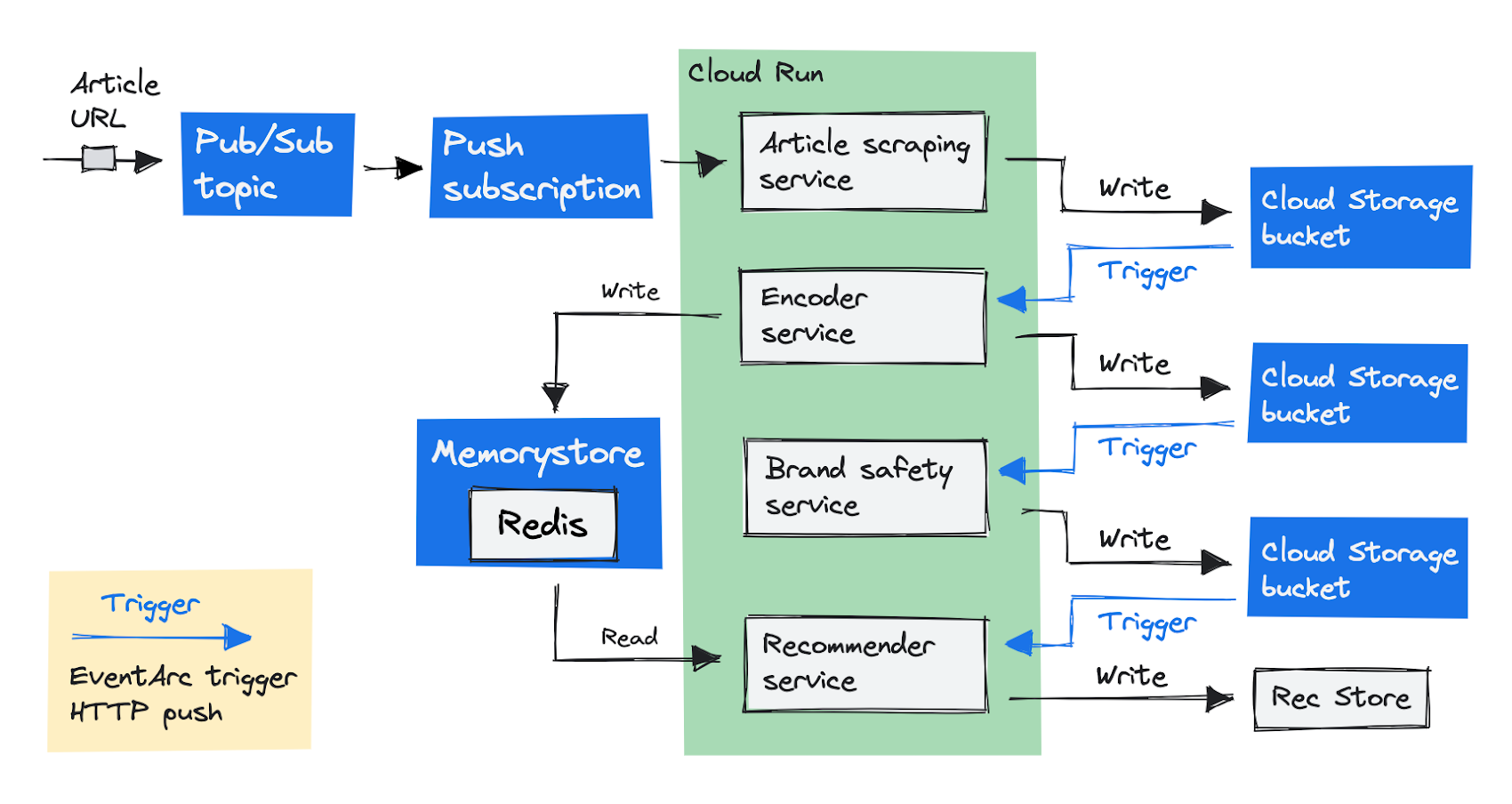
最初のエントリーポイントを、Recommender サービスではなく記事スクレイピング サービスに変更しました。スクレイピング サービスは、記事テキストを返す代わりに、テキストを Cloud Storage バケットに保存します。私たちのパイプラインの次のステップは、エンコーダ サービスを実行し、Eventarc トリガーを使用してそれを呼び出すことです。
Eventarc を使用すると、Cloud Storage を含む Google サービスからイベントを非同期的に配信できます。記事スクレイピング サービスがファイルを Cloud Storage バケットに追加すると同時にイベントを発生させる Eventarc トリガーを設定しました。
トリガーは、HTTP リクエストを使用してオブジェクト情報をエンコーダ サービスに送信します。エンコーダ サービスは、処理を行い、結果を再度 Cloud Storage バケットに保存します。次々と現れるサービスが処理を行い、その中間結果を Cloud Storage に保存して、次のサービスで使用します。
Eventarc トリガーを使用してすべてのサービスを非同期で呼び出すため、どのサービスも、他のサービスから結果が返ってくるのを待つことがなくなりました。従来の GKE の設定と比較すると、費用を 50% 削減できました。
アドバイスと結論
レコメンデーションの生成は高速かつスケーラブルなものとなり、費用は従来のクラスタ設定と比べて半分になりました。
コンテナベースのアプリケーションにとって GKE から Cloud Run への移行は、容易です。
Cloud Trace は、リクエストがどこで時間を費やしているのかを特定するのに便利です。
Cloud Run サービスから他のサービスへリクエストを送信し、同時にその結果を待つことは、多くの費用がかかるということがわかりました。Eventarc トリガーを活用して、サービスを非同期で呼び出すやり方が、より効果的でした。
Cloud Run は、まだ開発が進められていて、新機能が頻繁に追加されているので、全体的に優れたデベロッパー体験を提供します。
- Opinary、データ サイエンティスト(2020 - 2022 年)Héctor Otero Mediero 氏
- Opinary、シニア データ サイエンティスト Doreen Sacker 氏