Opinary generates recommendations faster on Cloud Run
Doreen Sacker
Senior Data Scientist at Opinary
Héctor Otero Mediero
Data Scientist at Opinary (2020-2022)
Editor's note: Berlin-based startup Opinary migrated their machine learning pipeline from Google Kubernetes Engine (GKE) to Cloud Run. After making a few architectural changes, their pipeline is now faster and more cost-efficient. They reduced the time to generate a recommendation from 20 seconds to a second, and realized a remarkable 50% cost reduction.
In this post, Doreen Sacker and Héctor Otero Mediero share with us a detailed and transparent technical report of the migration.
Opinary asks the right questions to increase reader engagement
We’re Opinary, and our reader polls appear in news articles globally. The polls let users share their opinion with one click and see how they compare to other readers. We automatically add the most relevant reader polls using machine learning.
We’ve found that the polls help publishers increase reader retention, boost subscriptions, and improve other article success metrics. Advertisers benefit from access to their target groups contextually on premium publishers’ sites, and from high-performing interaction with their audiences.
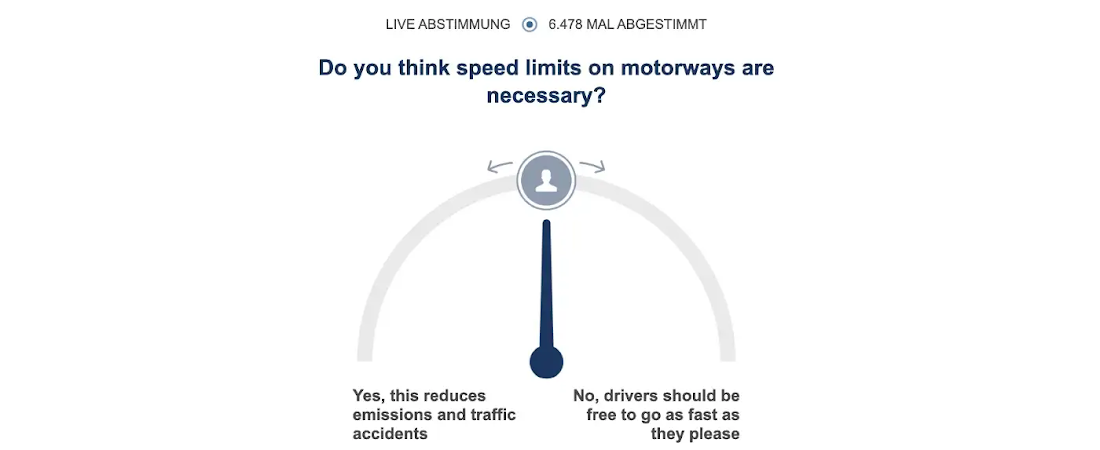
Let’s look at an example of one of our polls. Imagine reading an article on your favorite news site about whether or not to introduce a speed limit on the highway. As you might know, long stretches of German Autobahn still don’t have a legal speed limit, and this is a topic of intense debate. Critics of speeding point out the environmental impact and casualty toll. Opinary adds this poll to the article:
Diving into the architecture of our recommendation system
Here’s how we’ve architected our system originally on GKE. Our pipeline starts with an article URL, and delivers a recommended poll to add to the article. Let’s take a more detailed look at the various components that make this happen. Here’s a visual overview:
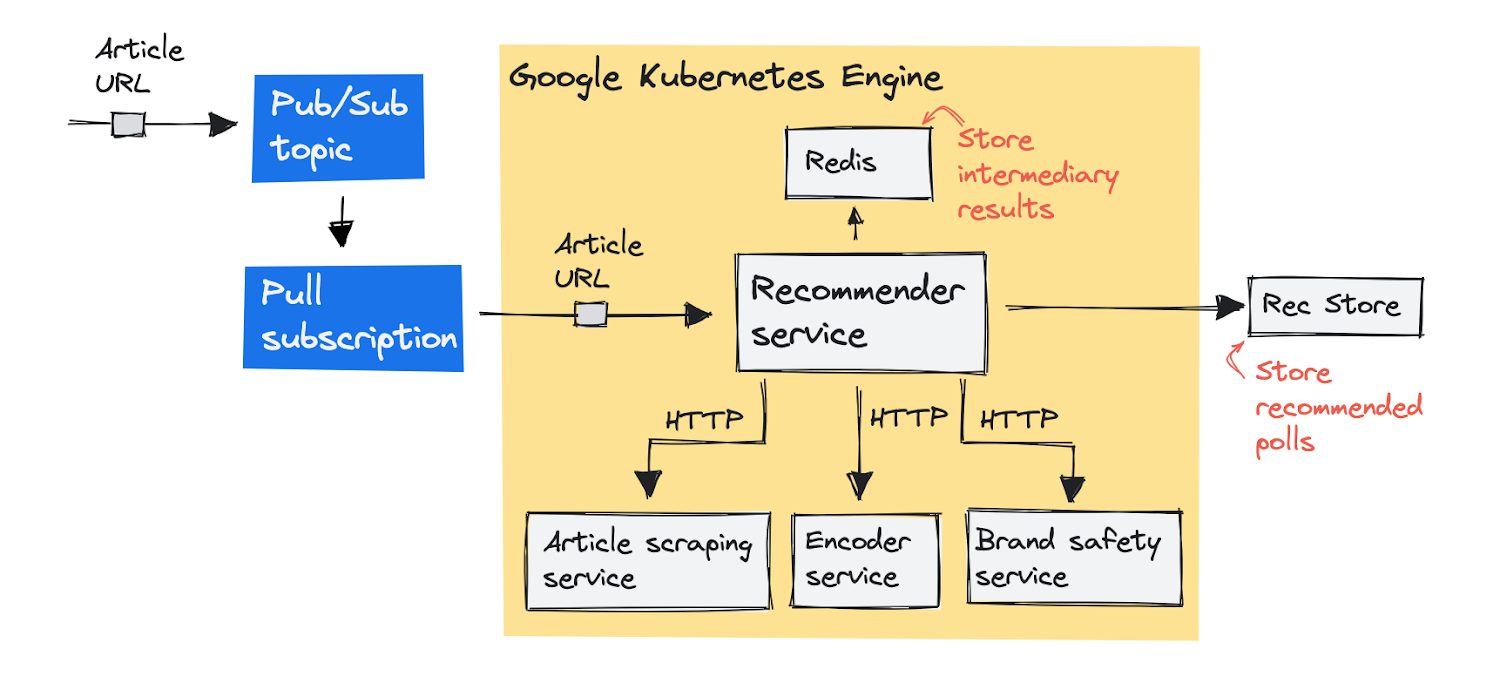
First, we’ll push a message with the article URL to a Pub/Sub topic (a message queue). The recommender service pulls the message from the queue in order to process it. Before this service can recommend a poll, it needs to complete a few steps, which we’ve separated out into individual services. The recommender service sends a request to these services one-by-one and stores the results in a Redis store. These are the steps:
The article scraper service scrapes (downloads and parses) the article text from the URL.
The encoder service encodes the text into text embeddings (we use the universal sentence encoder).
The brand safety service detects if the article text includes descriptions of tragic events, such as death, murder, or accidents, because we don’t want to add our polls into these articles.
With these three steps completed, the recommendation service can recommend a poll from our database of pre-existing polls, and submit it to an internal database we call Rec Store. This is how we end up recommending adding a poll about introducing a speed limit on the German Autobahn.
Why we decided to move to Cloud Run
Cloud Run looked attractive to us for two reasons. First, because it automatically scales down all the way to zero container instances if there are no requests, we expected we would save costs (and we did!). Second, we liked the idea of running our code on a fully-managed platform without having to worry about the underlying infrastructure, especially since our team doesn’t have a dedicated data engineer (we’re both data scientists).
As a fully-managed platform, Cloud Run has been designed to make developers more productive. It’s a serverless platform that lets you run your code in containers, directly on top of Google’s infrastructure. Deployments are fast and automated. Fill in your container image URL and seconds later your code is serving requests.
Cloud Run automatically adds more container instances to handle all incoming requests or events, and removes them when they’re no longer needed. That’s cost-efficient, and on top of that Cloud Run doesn’t charge you for the resources a container uses if it’s not serving requests.
The pay-for-use cost model was the main motivation for us to migrate away from GKE. We only want to pay for the resources we use - and not for a large idle cluster during the night.
Enabling the migration to Cloud Run with a few changes
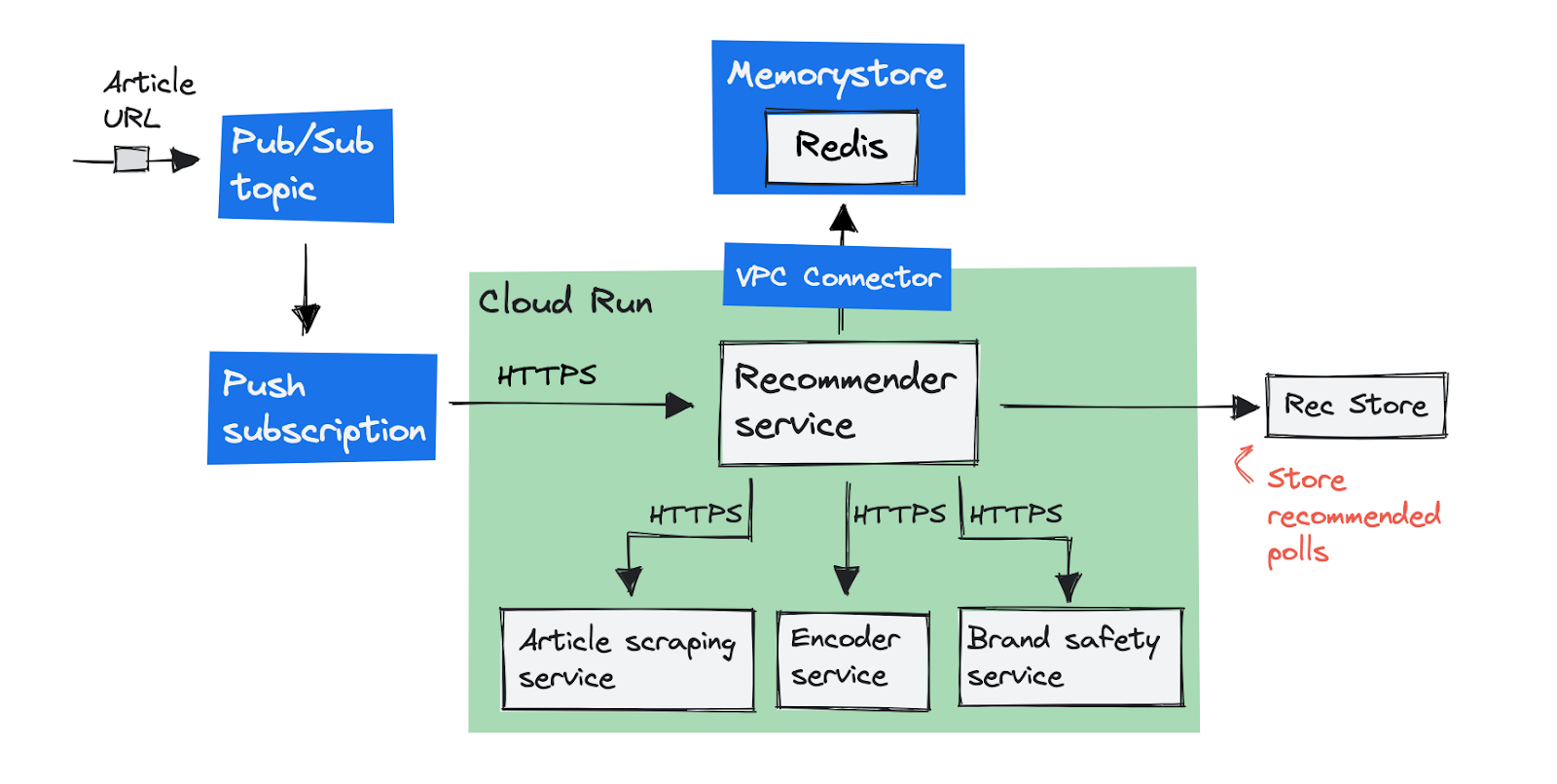
To move our services from GKE to Cloud Run, we had to make a few changes.
Change the Pub/Sub subscriptions from pull to push.
Migrate our self-managed Redis database in the cluster to a fully-managed Cloud Memorystore instance.
This is how our initial target architecture looks in a diagram:
Changing Pub/Sub subscriptions from pull to push
Since Cloud Run services scale with incoming web requests, your container must have an endpoint to handle requests. Our recommender service originally didn’t have an endpoint to serve requests, because we used the Pub/Sub client library to pull messages.
Google recommends to use push subscriptions instead of pull subscriptions to trigger Cloud Run from Pub/Sub. With a push subscription, Pub/Sub delivers messages as requests to an HTTPS endpoint. Note that this doesn’t need to be Cloud Run, it can be any HTTPS URL. Pub/Sub guarantees delivery of a message by retrying requests that return an error or are too slow to respond (using a configurable deadline).
Introducing a Cloud Memorystore Redis instance
Cloud Run adds and removes container instances to handle all incoming requests. Redis doesn’t serve HTTP requests, and it likes to have one or a few stateful container instances attached to a persistent volume, instead of disposable containers that start on-demand.
We created a Memorystore Redis instance to replace the in-cluster Redis instance. Memorystore instances have an internal IP address on the project’s VPC network. Containers on Cloud Run operate outside of the VPC. That means you have to add a connector to reach internal IP addresses on the VPC. Read the docs to learn more about Serverless VPC access.
Making it faster using Cloud Trace
This first part of our migration went smoothly, but while we were hopeful that our system would perform better, we would still regularly spend almost 20 seconds generating a recommendation.
We used Cloud Trace to figure out where requests were spending time. This is what we found:
- To handle a single request our code made roughly 2,000 requests to Redis. Batching all these requests into one request was a big improvement.
The VPC connector has a default maximum limit on network throughput that was too low for our workload. Once we changed it to use larger instances, response times improved.
As you can see below, when we rolled out these changes, we realized a noticeable performance benefit.
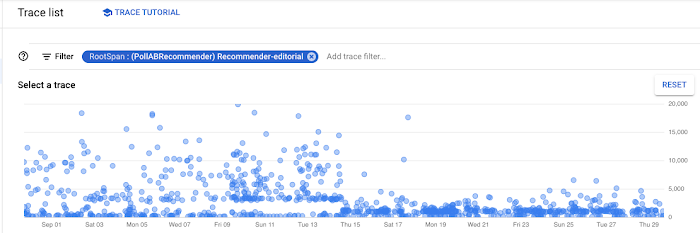
Waiting for responses is expensive
The changes described above led to scalable and fast recommendations. We reduced the average recommendation time from 10 seconds to under 1 second. However, the recommendation service was getting very expensive, because it spent a lot of time doing nothing, waiting for other services to return their response.
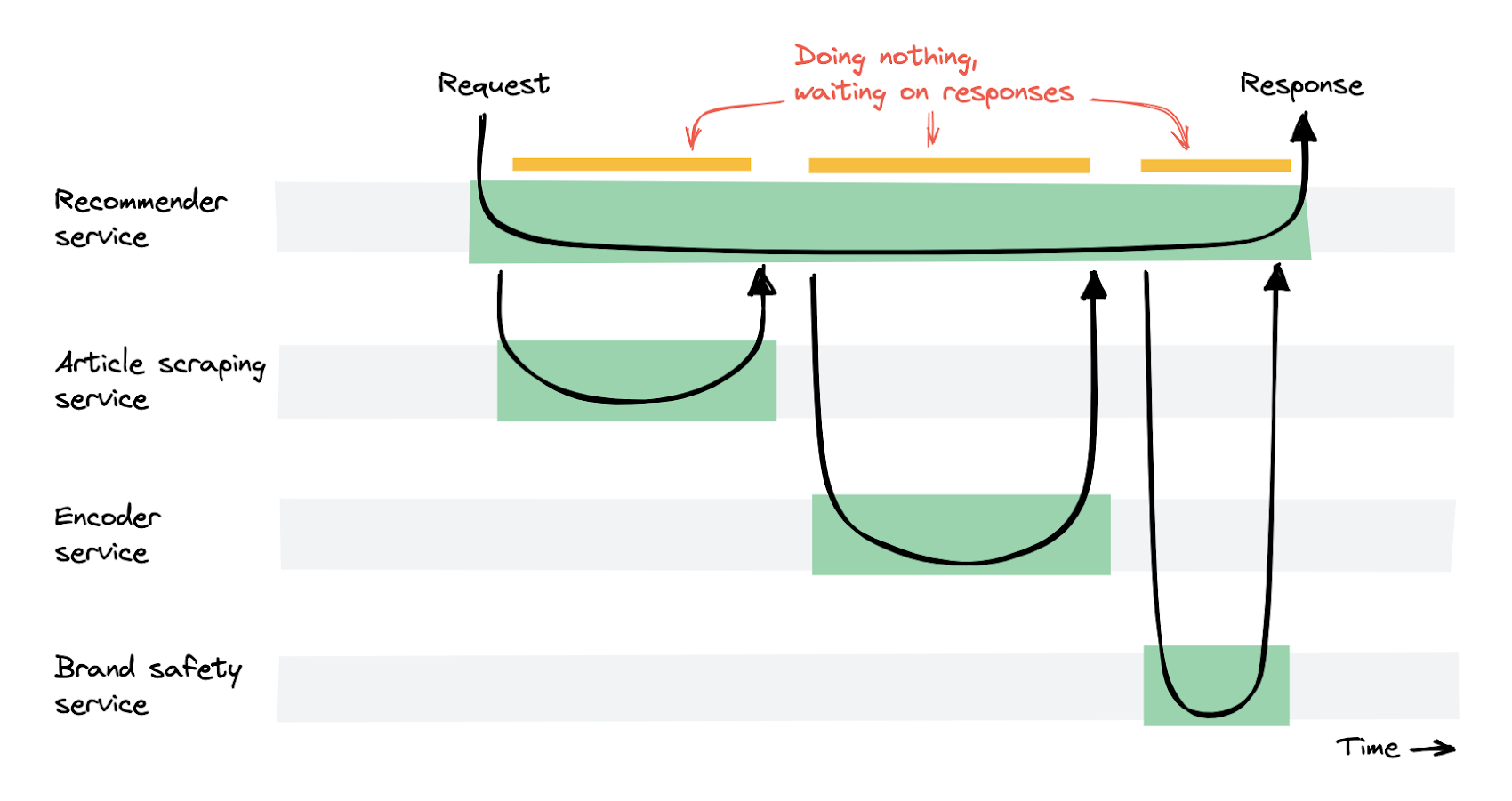
The recommender service would receive a request, and wait for other services to return a response. As a result, many container instances in the recommender service were running but were essentially doing nothing except waiting. Therefore, the pay-per-use cost model of Cloud Run leads to high costs for this service. Our costs went up by a factor of 4 compared with the original setup on Kubernetes.
Rethinking the architecture
To reduce costs, we needed to rethink our architecture. The recommendation service was sending requests to all other services, and would wait for their responses. This is called an orchestration pattern. To have the services work independently, we changed to a choreography pattern. We needed the services to execute their tasks one after the other, but without a single service waiting for other services to complete. This is what we ended up doing:
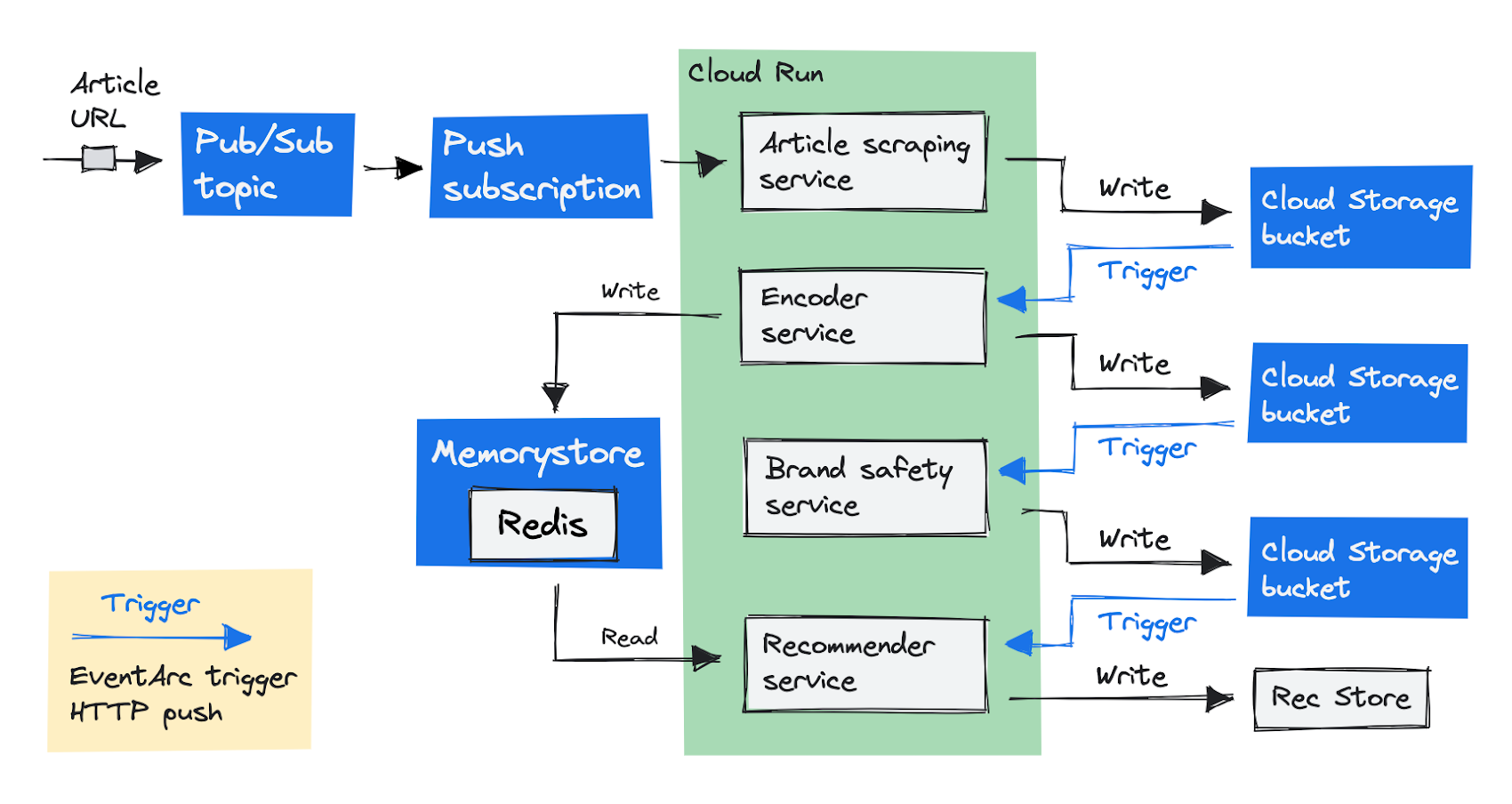
We changed the initial entrypoint to be the article scraping service, rather than the recommender service. Instead of returning the article text, the scraping service now stores the text in a Cloud Storage bucket. The next step in our pipeline is to run the encoder service, and we invoke it using an EventArc trigger.
EventArc lets you asynchronously deliver events from Google services, including those from Cloud Storage. We’ve set an EventArc trigger to fire an event as soon as the article scraper service adds the file to the Cloud Storage bucket.
The trigger sends the object information to the encoder service using an HTTP request. The encoder service does its processing and saves the results in a Cloud Storage bucket again. One service after the other can now process and save the intermediate results in Cloud Storage for the next service to use.
Now that we asynchronously invoke all services using EventArc triggers, no single service is actively waiting for another service to return results. Compared with the original setup on GKE, our costs are now 50% lower.
Advice and conclusions
Our recommendations are now fast, scalable, and our costs are half as much as the original cluster setup.
Migrating from GKE to Cloud Run is easy for container-based applications.
Cloud Trace was useful for identifying where requests were spending time.
Sending a request from one Cloud Run service to another and synchronously waiting for the result turned out to be expensive for us. Asynchronously invoking our services using EventArc triggers was a better solution.
Cloud Run is under active development and new features are being added frequently, which makes it a nice developer experience overall.