BigQuery、Vertex AI、MongoDB Atlas による映画のスコア予測
Google Cloud Japan Team
※この投稿は米国時間 2022 年 12 月 2 日に、Google Cloud blog に投稿されたものの抄訳です。
こんにちは。前回、Google Cloud と MongoDB Atlas についてご紹介してから少し経ちました。今回は、BigQuery、BQML、Vertex AI、Cloud Functions、MongoDB Atlas、Cloud Run を含めた新しいジャンルのテストについて、このブログにまとめようと思いつきました。Google がこれらのサービスをどのように統合して、フルスタック アプリケーションや、アプリケーションが使用するその他の独立した機能とサービスを提供しているかを解説します。Cloud Run と MongoDB Atlas によるサーバーレス MEAN スタック アプリケーションに関する以前の投稿はお読みいただけたでしょうか?もしまだの場合は、今回の議論で扱うトピックの一部でその投稿の手順を参照するようになっていますので、ぜひこの機会にご一読ください。今回のテストでは、BigQuery、Vertex AI、Mongodb Atlas を使用して、AutoML で作成した教師あり機械学習モデルによりカテゴリ変数を予測します。
テスト
映画は好きですか?たいていの人が好きだと思います。私たちは映画を見るだけではなく、映画の良さを引き立てているニュアンスや雰囲気について話すことも楽しみます。これは言語、地理、文化にかかわらず言えることです。私はよく、「映画の評価や成功要因に関して、いくつかの側面を変えることで結果にインパクトのある違いを生み出すことができたら」と考えてきました。つまりこれは、映画の成功スコアを予測して、変数に手を加え、値を上下に調整して結果に影響を与えることを意味します。今回のテストでは、まさにそれを実現しました。
アーキテクチャの概要
今回は、Vertex AI AutoML を使用して映画のスコアを予測し、MongoDB Atlas にトランザクションとして保存しました。モデルは BigQuery に保存されたデータでトレーニングされ、Vertex AI に登録されます。サービスのリストは、次の 3 つのセクションで構成されます。
1. ML モデルの作成
2. ユーザー インターフェース / クライアント アプリケーション
3. ML API を使用した予測のトリガー
ML モデルの作成
1. CSV から BigQuery に供給されるデータ
2. AutoML モデル作成のために Vertex AI に統合された BigQuery データ
3. Endpoint API を生成するために Vertex AI Model Registry にデプロイされたモデル
ユーザー インターフェース アプリケーション
4. トランザクション データを保存し、クライアント アプリケーションを強化する MongoDB Atlas
5. MongoDB Atlas と連携する Angular クライアント アプリケーション
6. Cloud Run にデプロイされたクライアント コンテナ
ML API を使用した予測のトリガー
7. デプロイされた AutoML モデルのエンドポイント呼び出しをトリガーする Java の Cloud Functions。UI からのリクエストとして映画の詳細を受け取り、予測された映画の SCORE を返して、レスポンスを MongoDB に書き戻します。

トレーニング データの準備
一般公開されている任意のデータセットを使用するか、独自のデータセットを作成する、または、git で CSV のデータセットを利用することもできます。今回は git のデータセットで、このテストの基本的な処理手順を実行しました。実際の実装では、綿密なクレンジングと前処理を自由に行ってください。以下は、データセットに含まれる独立変数です。
Name(文字列)
Rating(文字列)
Genre(文字列、カテゴリ)
Year(数値)
Released(日付)
Director(文字列)
Writer(文字列)
Star(文字列)
Country(文字列、カテゴリ)
Budget(数値)
Company(文字列)
Runtime(数値)
Cloud Shell を使用した BigQuery データセット
BigQuery はサーバーレスのマルチクラウド データ ウェアハウスで、運用上のオーバーヘッドを発生させずにバイトからペタバイトまでスケーリングできます。そのため、ML トレーニング データの保存に最適です。しかし、それだけではありません。組み込みの機械学習(ML)と分析機能により、SQL クエリだけを使用して、コードなしで予測を作成できます。また、連携クエリを使用して外部ソースからデータにアクセスできるため、複雑な ETL パイプラインが不要になります。BigQuery が提供するすべての機能については、BigQuery プロダクト ページで詳しくご紹介しています。
このような BigQuery の利点を活かし、ユーザーは有用な情報を得るためのデータの分析に専念できます。今回のブログでは、bq コマンドライン ツールを使用して、ローカルの CSV ファイルを新しい BigQuery テーブルに読み込みます。BigQuery を有効にするには、次の手順を行います。
Cloud Shell を有効にしてプロジェクトを作成する
Google Cloud 上で動作するコマンドライン環境の Cloud Shell を使用します。Cloud Shell には bq があらかじめ読み込まれています。
Google Cloud コンソールの [プロジェクト セレクタ] ページで、Google Cloud プロジェクトを選択または作成します。
Cloud プロジェクトに対して課金が有効になっていることを確認します。詳しくは、プロジェクトで課金が有効になっているかどうかを確認する方法をご覧ください。
BigQuery に移動して API を有効にします。ブラウザに次の URL を入力して、BigQuery ウェブ UI を直接開くこともできます。
Cloud コンソールで、[Cloud Shell をアクティブにする] をクリックします。プロジェクトに移動し、認証されていることを確認します。gcloud config コマンドを参照してください。
データセットの作成と読み込み
BigQuery データセットはテーブルのコレクションです。データセット内のすべてのテーブルは、同じデータのロケーションに保存されます。また、アクセス制御をカスタマイズして、データセットとそのテーブルへのアクセスを制限することも可能です。
1. Cloud Shell で bq mk コマンドを使用して、「movies」というデータセットを作成します。
2.
任意の一般公開データセットを使用することもできます。一般公開データセットを開いてクエリを実行するには、こちらのドキュメントの手順を参照してください。
4. bq load コマンドを使用して、CSV ファイルを BigQuery テーブルに読み込みます(BigQuery UI から直接アップロードすることもできます)。
--source_format=CSV - データファイルの解析時に CSV データ形式を使用します。
--skip_leading_rows=1 - CSV ファイルの最初の行はヘッダー行であるため、スキップします。
Movies.movies_score - データを読み込むテーブルを定義します。
./movies_bq_src.csv - 読み込むファイルを定義します。bq load コマンドで、「gs://my_bucket/path/to/file」の URI を持つ Cloud.Storage からファイルを読み込めます。
スキーマは、JSON スキーマ ファイルまたはカンマ区切りのリストとして定義できます(ここではカンマ区切りのリストを使用しました)。
お疲れさまでした。これで CSV データが movies.movies テーブルに読み込まれました。モデルのトレーニングに必要な列だけを残して、それ以外の列を無視するビューを作成することもできます。ぜひ覚えておいてください。
5. 早速、クエリを実行してみましょう。
BigQuery を操作するには、次の 3 つの方法があります。
bq コマンド
API
BigQuery Web SQL ワークスペースを使用してクエリを実行しました。SQL ワークスペースは次のようになります。
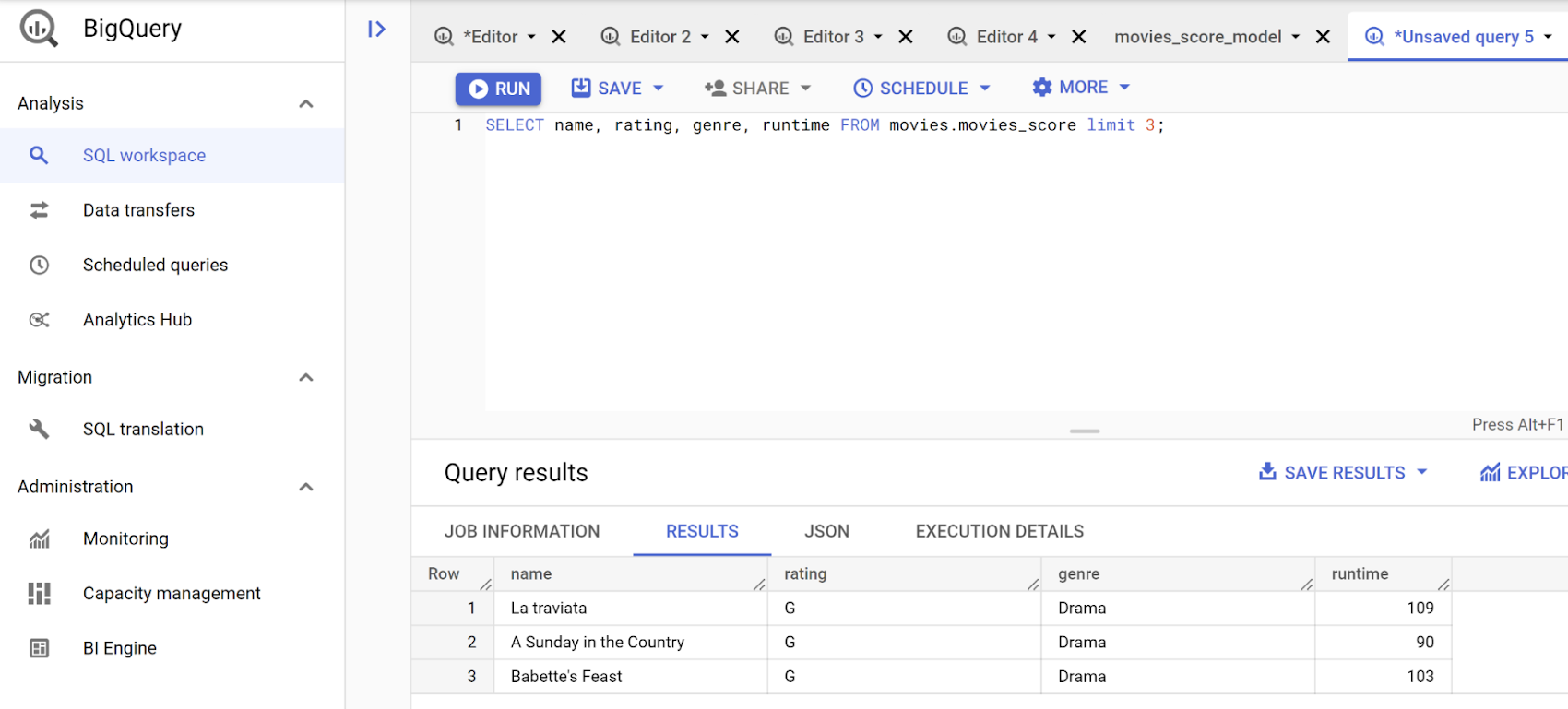
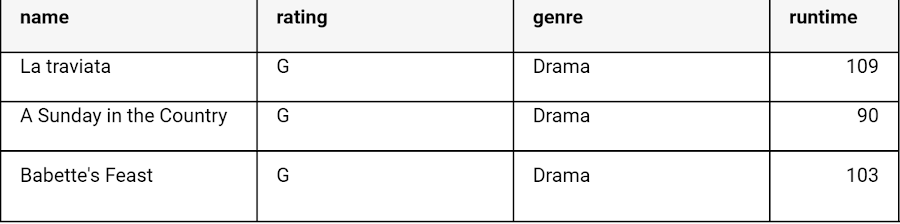
映画の成功スコアの予測(1~10 段階でのユーザースコア)
このテストでは、映画データセットのマルチクラス分類モデルとして、映画の成功スコア(ユーザースコア / 評価)を予測しています。
モデル選択に関するメモ
ここで選んだモデルは、実験的に選んだものです。最初はいくつかのモデルを実行し、その結果の評価に基づいて最終的に LOGISTIC REG にすることで、シンプルさを保ち、いくつかのデータベースから実際の映画の評価に近い結果を取得できました。ただし、これはあくまでモデルを実装するためのサンプルであり、このユースケースに推奨されるモデルではありません。他の実装方法として、スコアを予測するのではなく、ロジスティック回帰モデルを使用して映画の結果を GOOD / BAD として予測する方法があります。
Vertex AI AutoML インテグレーションでの BigQuery データの使用
BigQuery のデータを使って、Vertex AI で直接 AutoML モデルを作成します。BigQuery 自体から AutoML を実行し、モデルを VertexAI に登録してエンドポイントを公開することも可能です。BigQuery AutoML のドキュメントを参照してください。ただし、今回の例では、Vertex AI AutoML を使用してモデルを作成します。
Vertex AI データセットの作成
Google Cloud コンソールから Vertex AI に移動し、まだ Vertex AI API を有効にしていない場合は有効にします。データを展開して [データセット] を選択し、[作成] をクリックします。[表形式] データタイプと [回帰 / 分類] オプションを選択して、[作成] をクリックします。
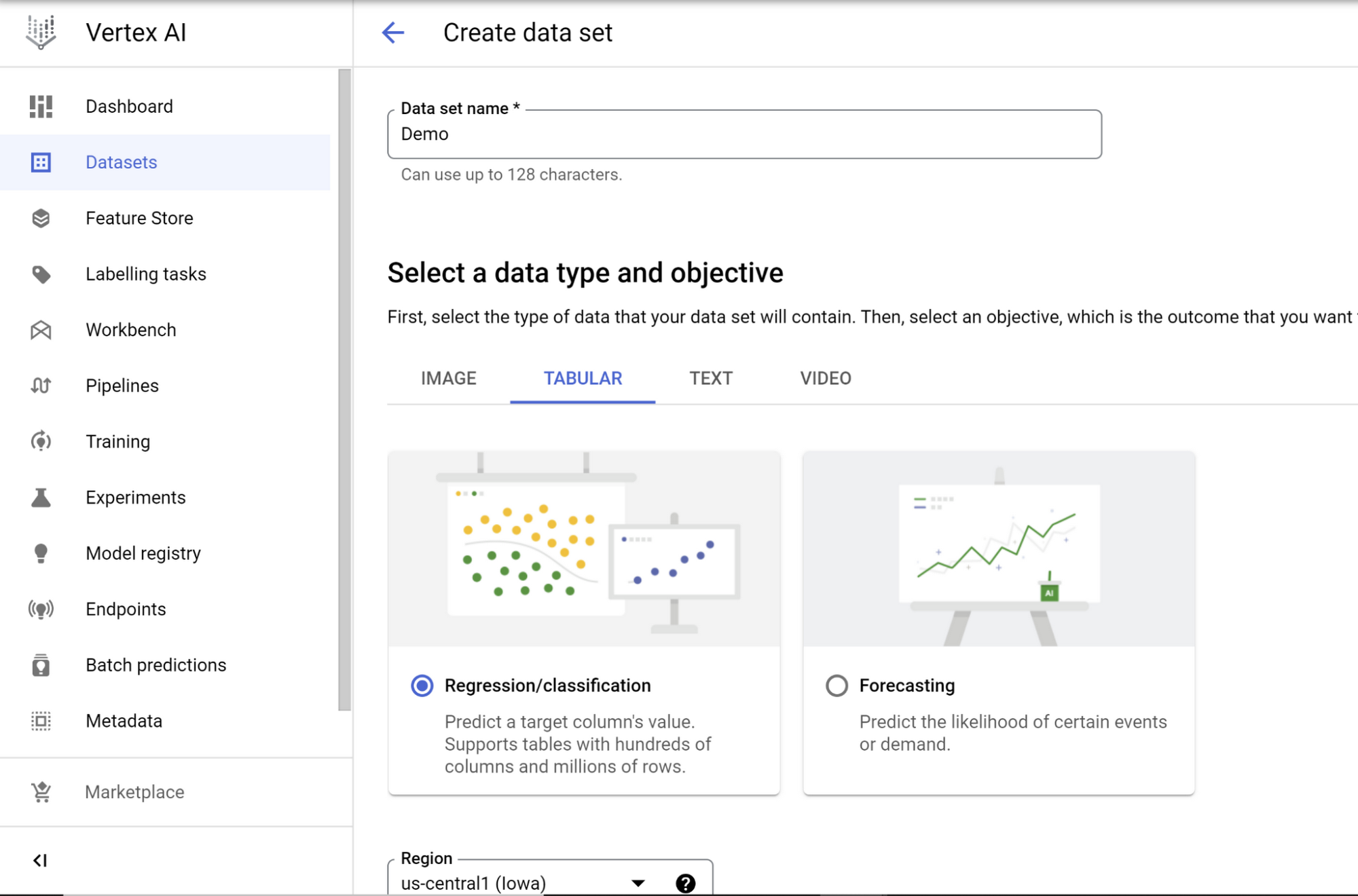
データソースの選択
次のページで、データソースを選択します。
[テーブルまたはビューを BigQuery から選択] オプションを選択し、[BigQuery のパス] の [参照] フィールドで BigQuery からテーブルを選択します。[続行] をクリックします。
重要事項
BigQuery テーブルを Vertex AI で表示するには、BigQuery インスタンスと Vertex AI データセットのリージョンが同じである必要があります。
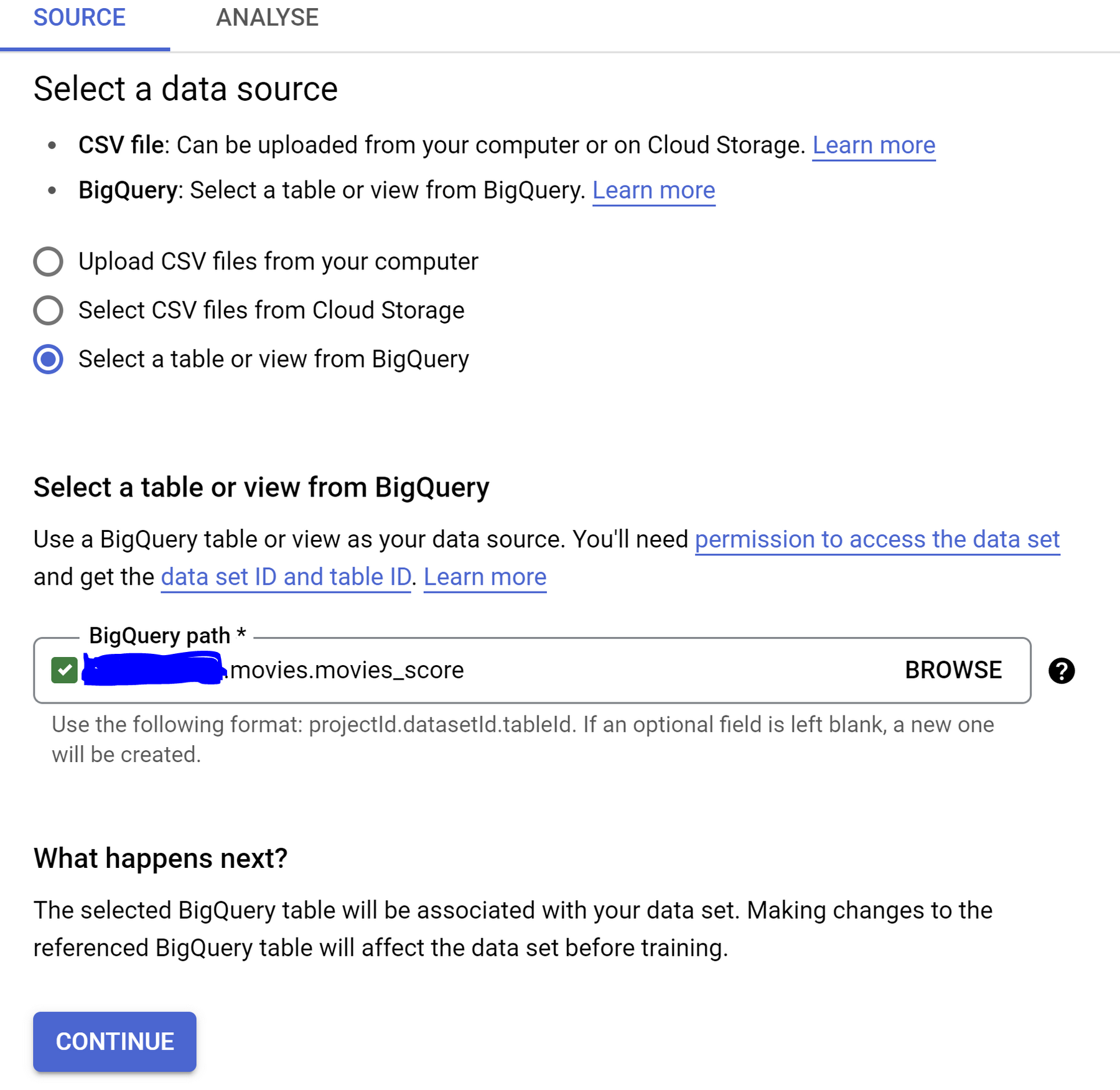
参照リストからソーステーブル / ビューを選択する場合は、必ずラジオボタンをクリックして、以下の手順を続行してください。誤ってテーブル / ビューの名前をクリックすると、Dataplex に移動します。その場合は、Vertex AI に戻る必要があります。
モデルのトレーニング
データセットが作成されると、[分析] ページに新しいモデルをトレーニングするオプションが表示されます。それをクリックします。
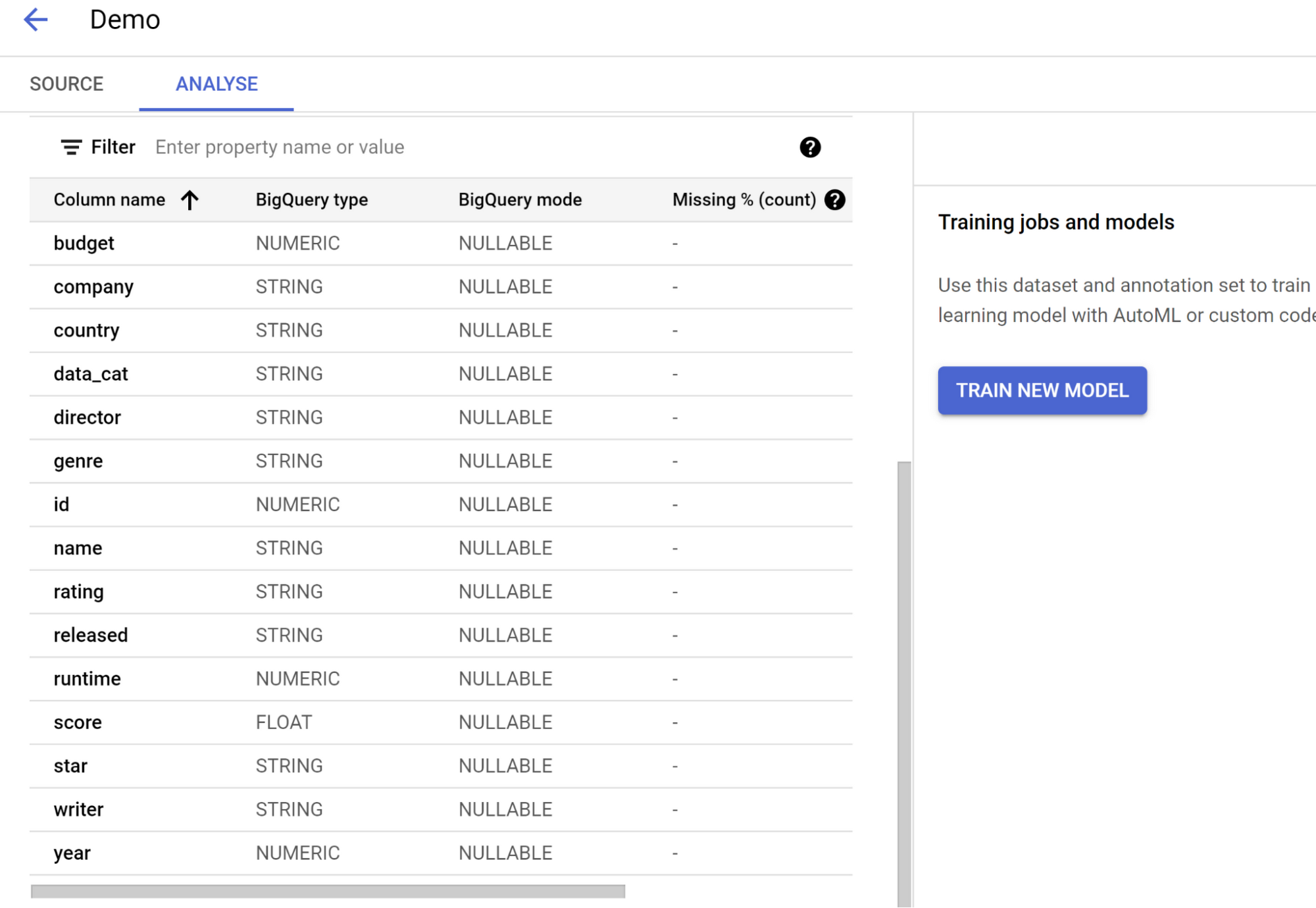
トレーニング ステップの構成
トレーニング プロセスの手順を実行します。
[Objective] は [Classification] のままにします。
[Model training method] で [AutoML] オプションを選択し、[続行] をクリックします。
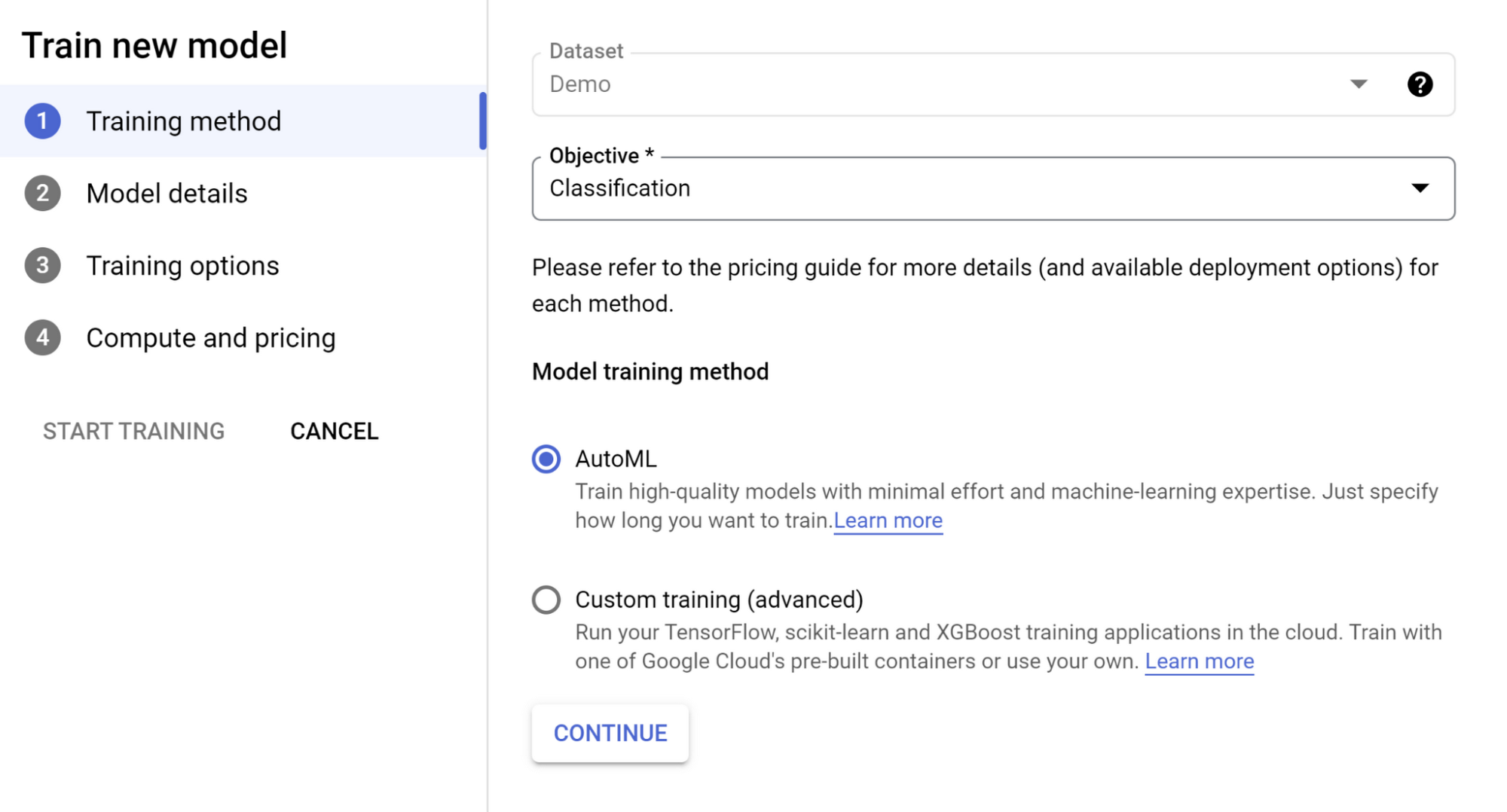
モデルに名前を付けます。
[Target column] のプルダウンで [score] を選択し、[続行] をクリックします。
また、[Export test dataset to BigQuery] オプションをオンにすると、追加の統合レイヤやサービス間でのデータ移動の必要なしに、データベース内の結果を含むテストセットを効率的かつ簡単に確認できます。
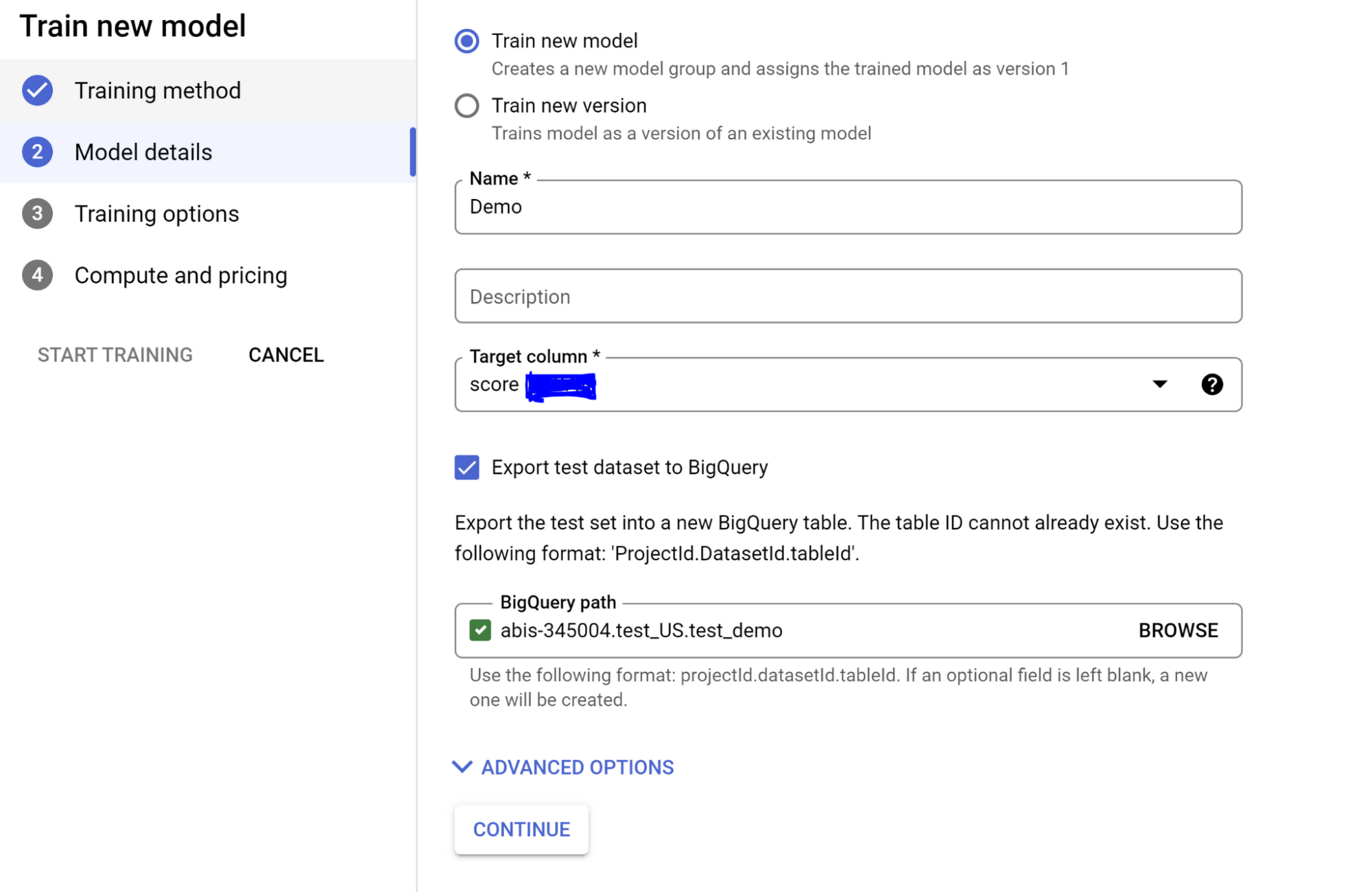
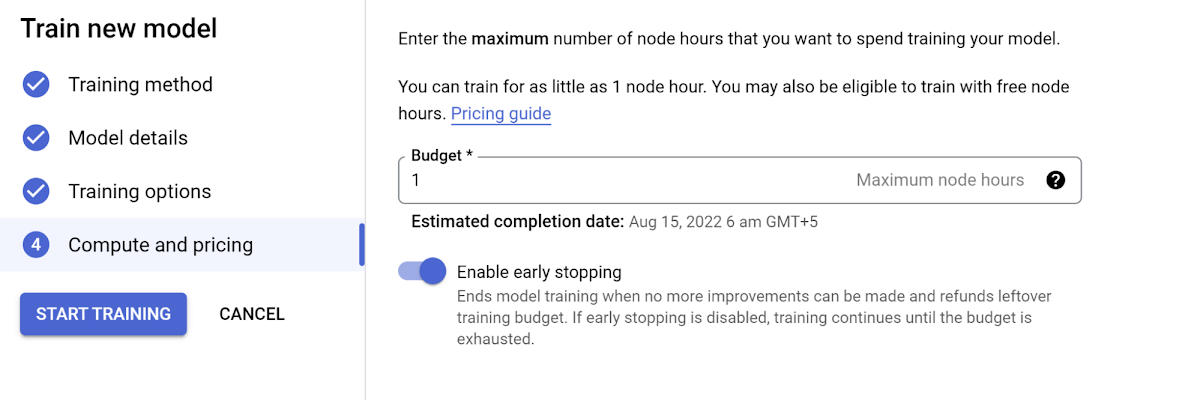
次のページでは、必要に応じた高度なトレーニング オプションと、モデルに設定するトレーニング時間を選択できます。なお、トレーニングに使用するノード時間を増やす場合は、料金設定にご注意ください。
[トレーニングを開始] をクリックして、新しいモデルのトレーニングを開始します。
モデルの評価、デプロイ、テスト
トレーニングが完了すると、[トレーニング](左側のメニューの [MODEL DEVERPMENT] という見出しの下)をクリックして、[TRAINING PIPELINES] セクションに一覧表示されているトレーニングを確認できるようになります。該当するトレーニングをクリックすると、[モデル レジストリ] ページが表示され、次のことができるようになります。
1. トレーニング結果を表示し、評価する。

2. API エンドポイントでモデルをデプロイし、テストする。
モデルをデプロイすると、アプリケーションで使用してリクエストを送信し、レスポンスでモデルの予測結果を取得できる API エンドポイントが作成されます。
3. 映画のスコアをバッチ予測する。
バッチ予測を BigQuery データベース オブジェクトと統合することも可能です。BigQuery オブジェクト(今回は映画のスコアをバッチ予測するビューを作成しました)から読み込み、新しい BigQuery テーブルに書き込みます。画像のようにそれぞれの BigQuery パスを指定し、[作成] をクリックします。
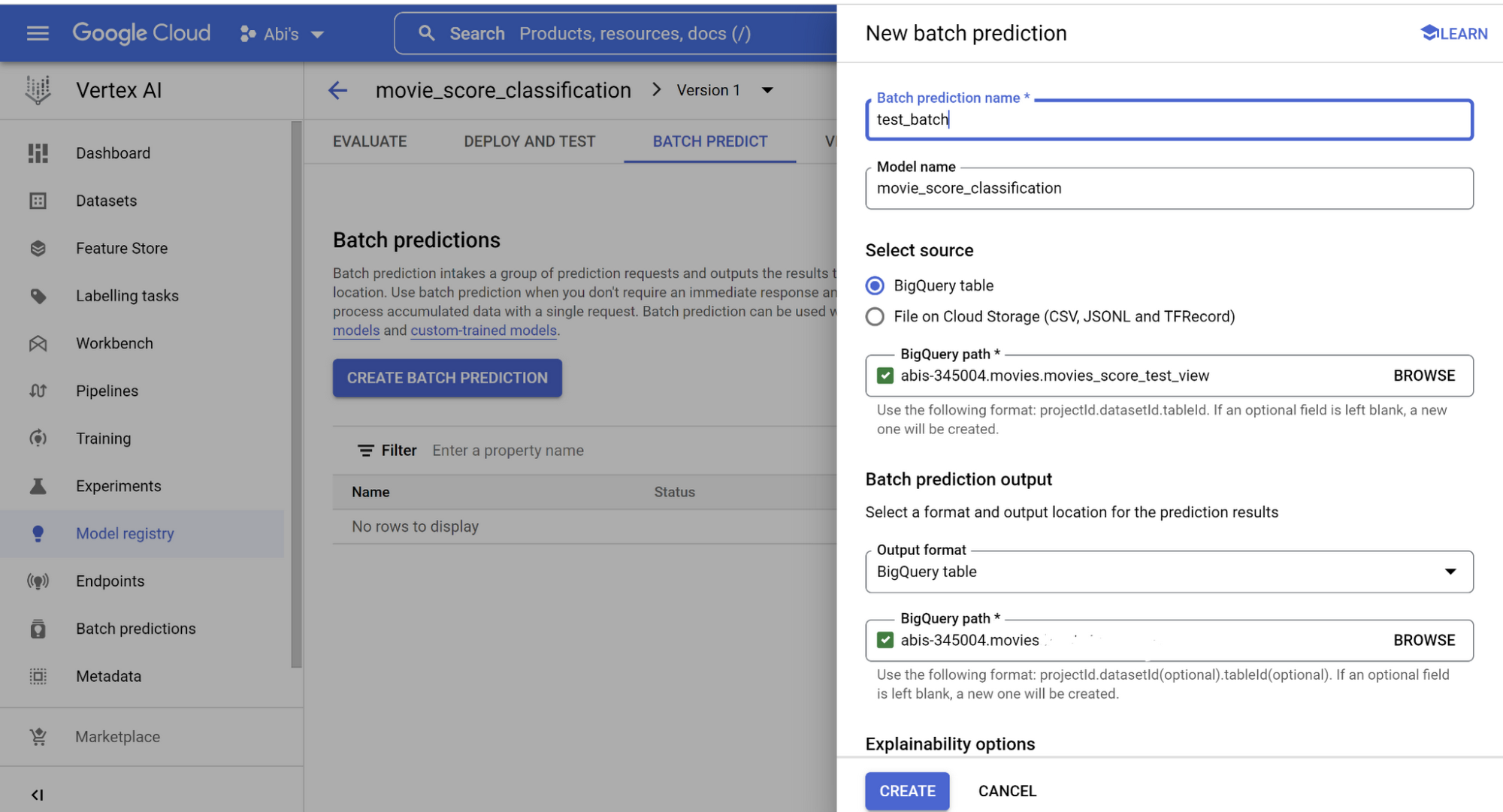
完了すると、バッチ予測結果についてデータベースにクエリを実行できるようになります。ただし、このセクションから先に進む前に、Vertex AI エンドポイント セクションで、デプロイされたモデルのエンドポイント ID、ロケーションなどの詳細をメモしておいてください。
同じユースケースについて、BigQuery ML を使用して SQL のみ(コードなし)でカスタム ML モデルを作成したことがあります。これについては、すでに別のブログで詳しく説明しています。
MongoDB Atlas と Angular によるサーバーレス ウェブ アプリケーション
このテストのユーザー インターフェースは Angular と MongoDB Atlas を使用しており、Cloud Run にデプロイされています。こちらのブログ投稿で、ウェブアプリで使用する MongoDB サーバーレス インスタンスを設定し、Cloud Run にデプロイする方法を確認してください。
また、このアプリケーションでは、MongoDB Atlas に統合された全文検索機能である Atlas Search も利用しています。Atlas Search では、映画に関する情報を入力する際にオートコンプリートが有効になります。データについては、先ほどと同じデータセットを Atlas にインポートしています。
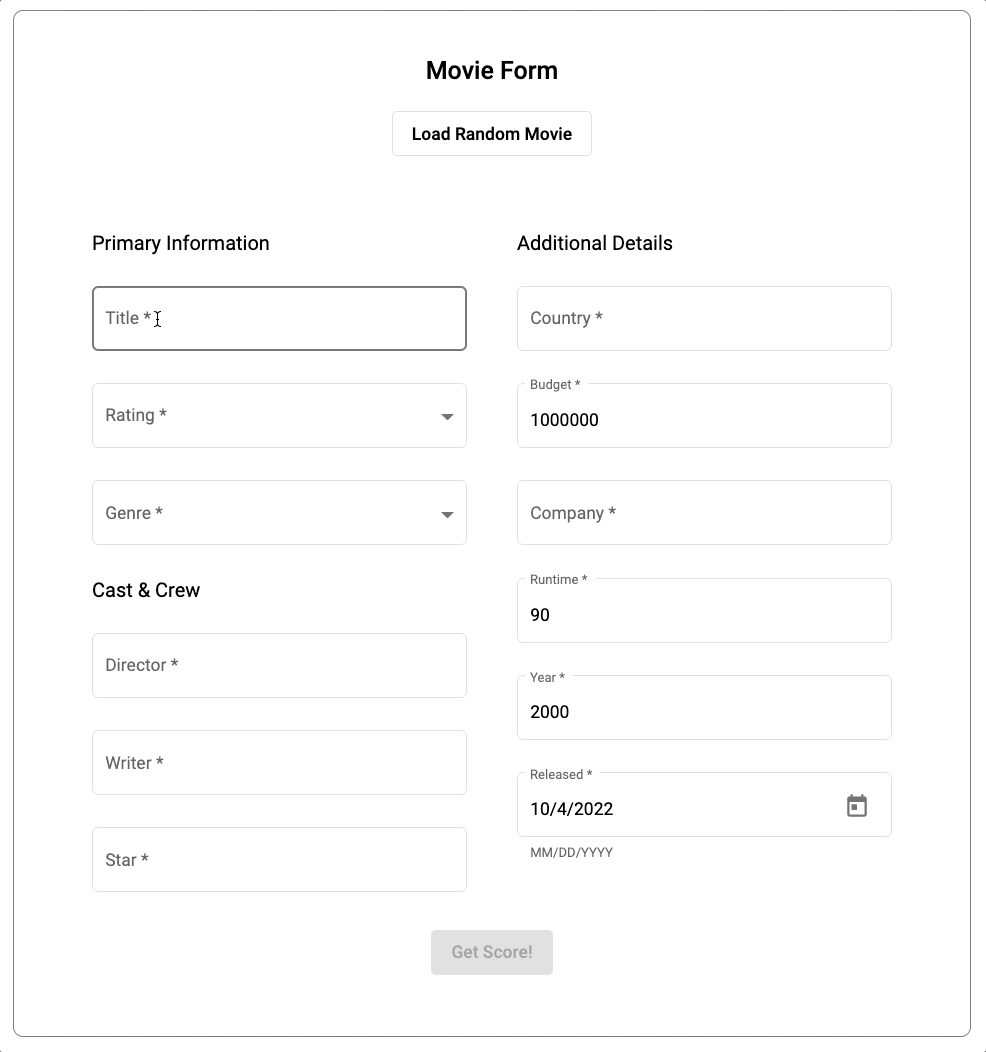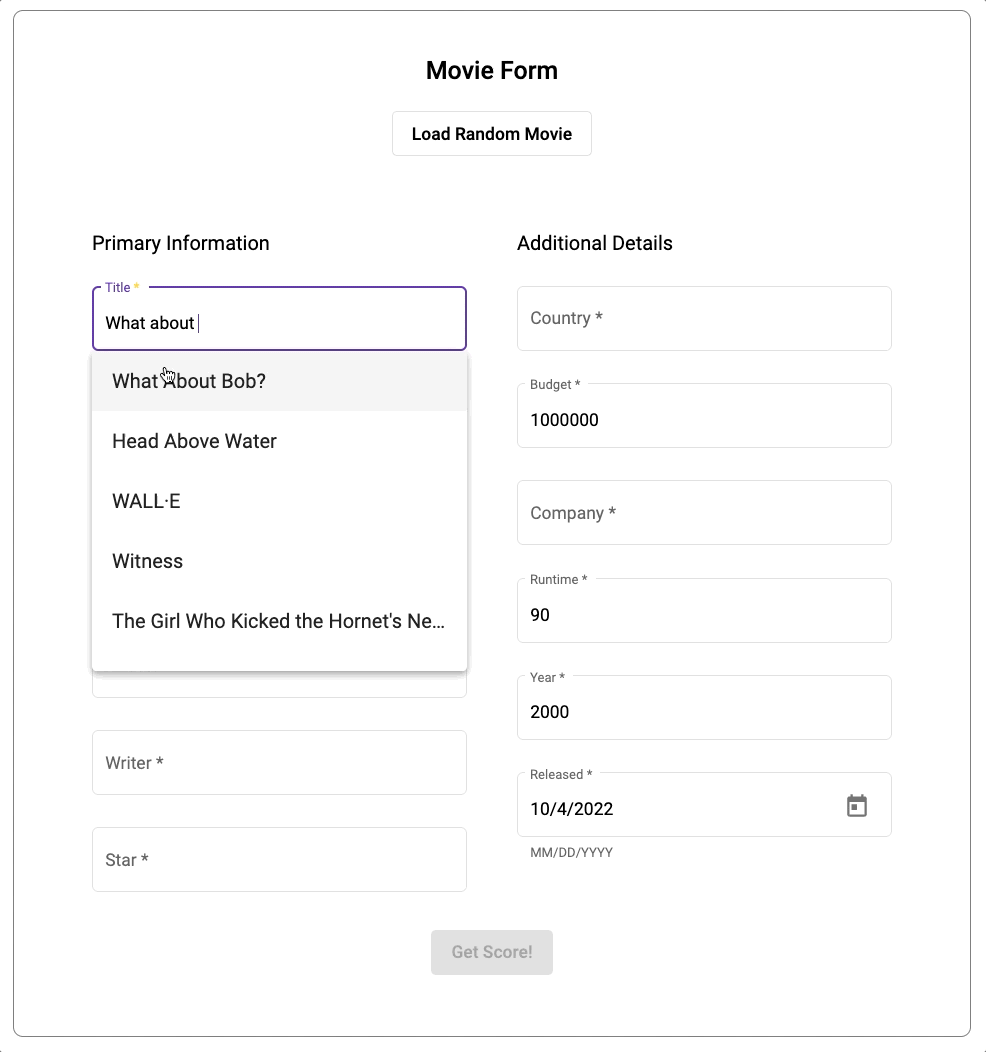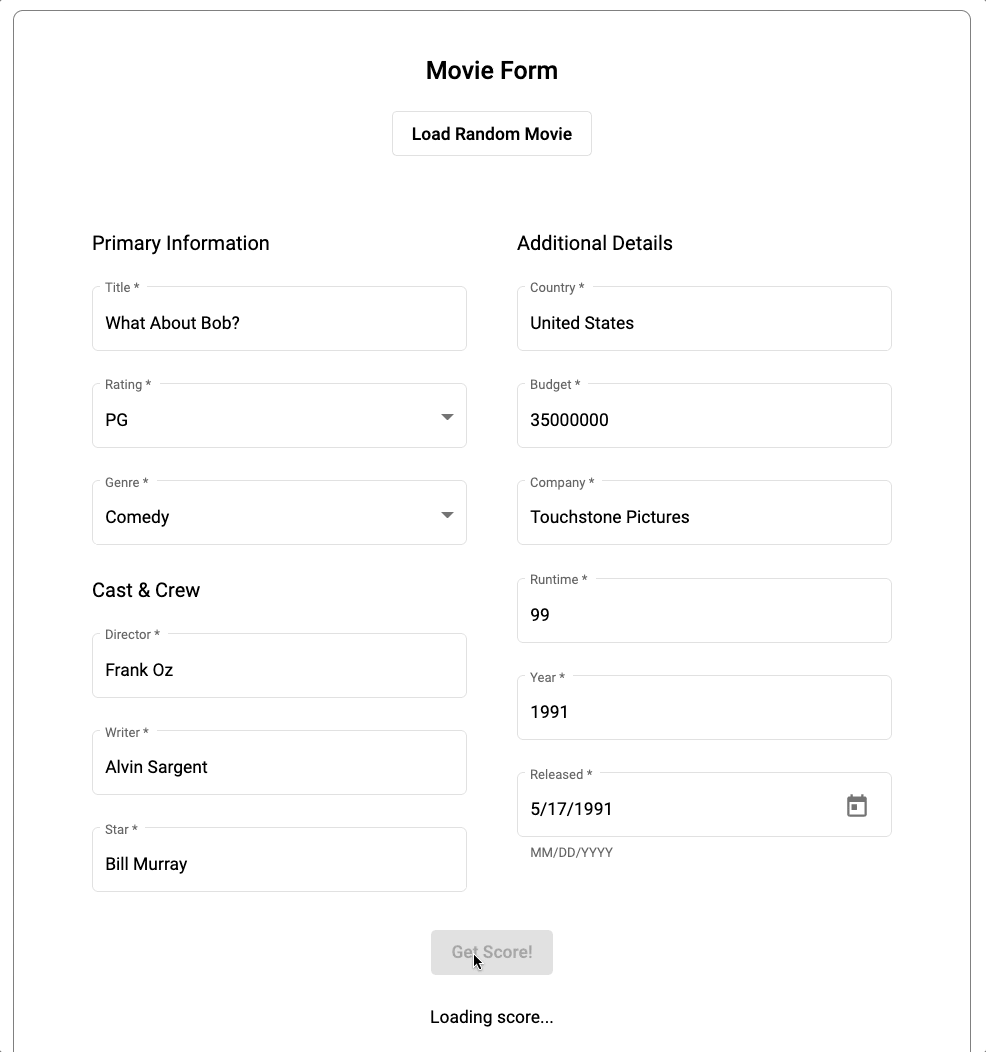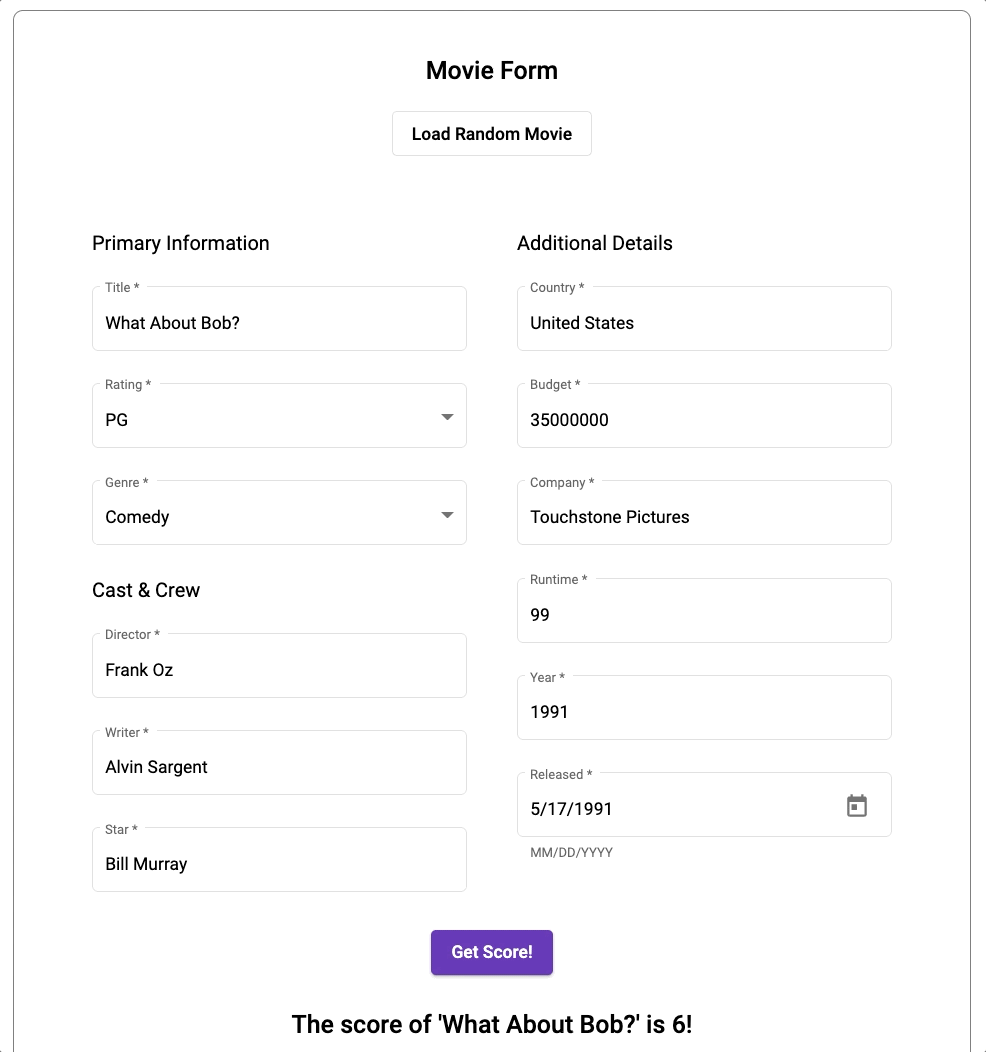
アプリケーションのソースコードは、専用の GitHub リポジトリで確認できます。
トランザクション データ用の MongoDB Atlas
このテストでは、MongoDB Atlas を使用してトランザクションを次の形式で記録します。
リアルタイムのユーザー リクエスト。
予測結果のレスポンス。
UI フィールドのオートコンプリートを促進するための過去データ。
MongoDB から BigQuery に、またはその逆にデータをストリーミングするためのパイプラインを構成する場合は、専用の Dataflow テンプレートを確認してください。
クラスタをプロビジョニングし、データベースをセットアップしたら、次のステップであるトリガーの作成の準備として、以下の事項を確認してください。
データベース名
コレクション名
なお、このクライアント アプリケーションでは、ユーザー入力を使用して映画のスコアを予測し、MongoDB に挿入する Cloud Functions のエンドポイント(以降のセクションで説明)を使用しています。
UI から ML 呼び出しをトリガーする Java の Cloud Functions
Cloud Functions は軽量なサーバーレス コンピューティング ソリューションで、デベロッパーはサーバーやランタイム環境を管理せずに、Cloud イベントに応答する単一目的のスタンドアロン ファンクションを作成できます。このセクションでは、Java の Cloud Functions のコードと依存関係を準備し、トリガーで実行されるように承認します。
ML のデプロイ手順でエンドポイントやその他の詳細情報をメモしたことを覚えていますか?ここではそれを使用します。Java の Cloud Functions を使用しているため、依存関係の処理には pom.xml を使用します。google-cloud-aiplatform ライブラリを使用し、Vertex AI AutoML エンドポイント API を活用します。
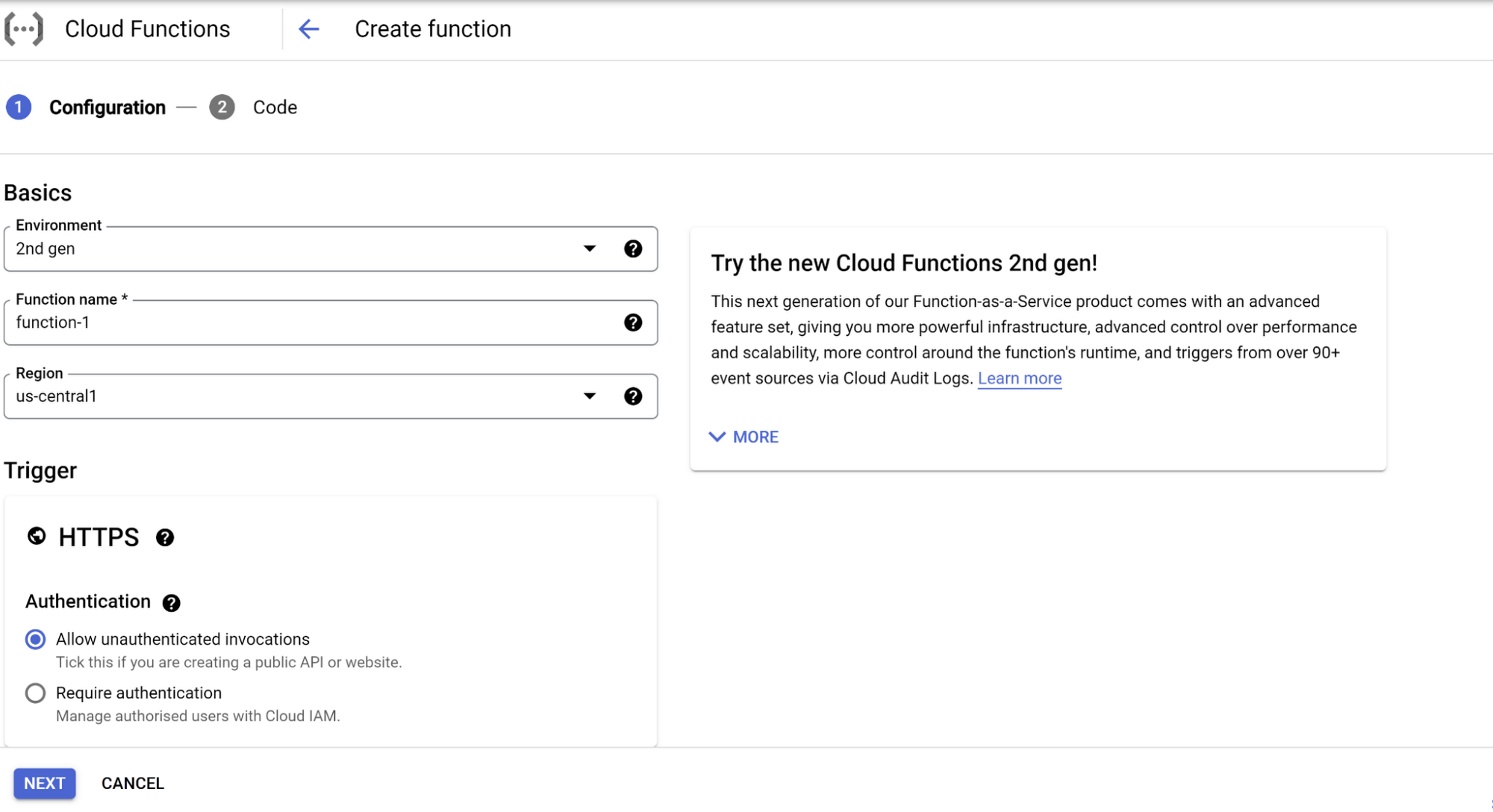
1. Google Cloud コンソールで Cloud Functions を検索し、[関数の作成] をクリックします。
2. 環境、関数名、リージョン、トリガー(ここでは HTTPS)、任意の認証などの構成の詳細を入力して [HTTPS が必須] をオンにし、[保存]、[次へ] の順にをクリックします。
3. 次のページで、ランタイム(Java 11)、ソースコード(インラインまたはアップロード)を選択し、編集を開始します。
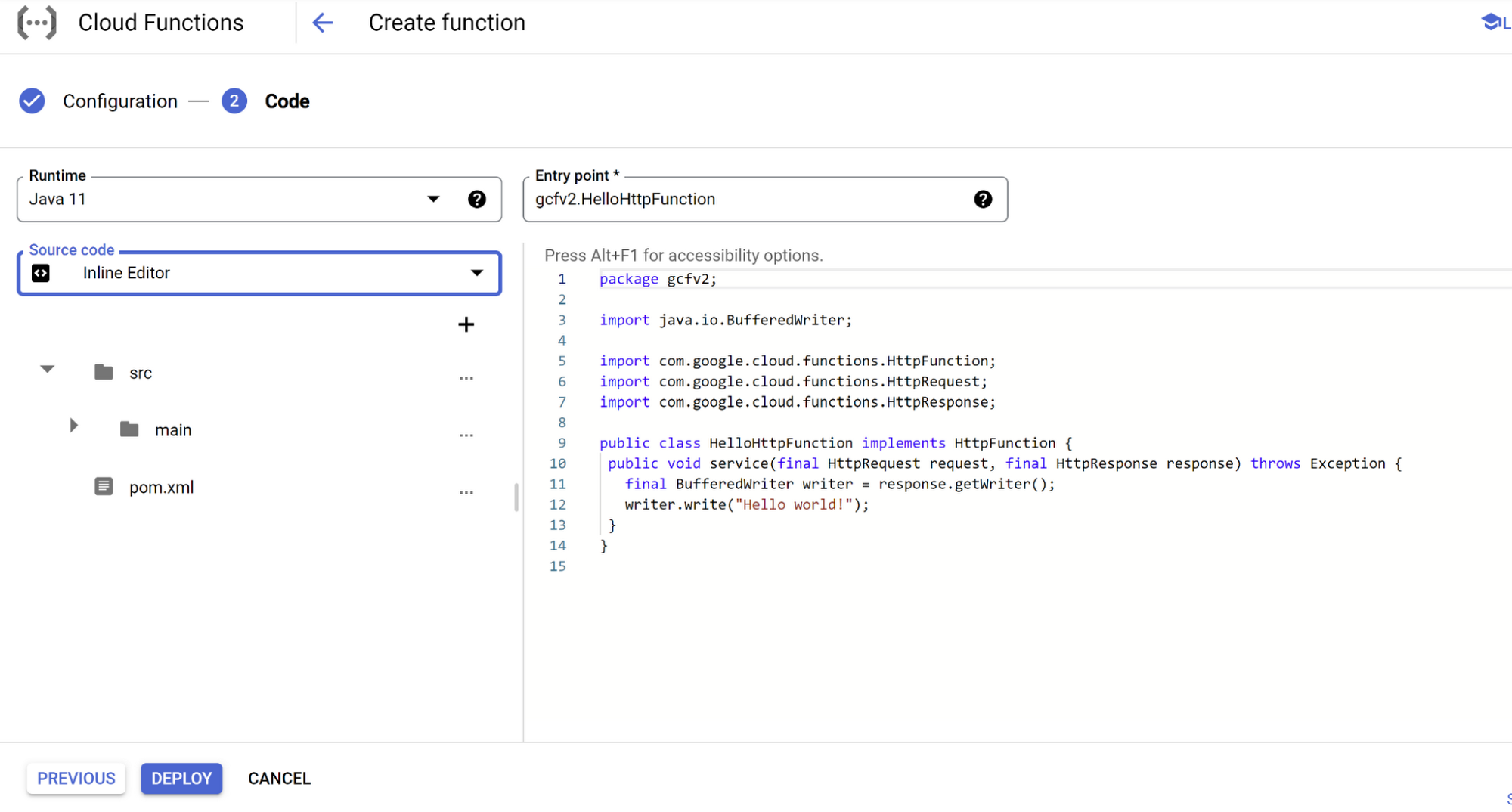
6. また、Java コードの ML モデル呼び出し部分にも注目してください(エンドポイントを使用します)。
7. すべての変更が完了したら、関数をデプロイします。クライアント アプリケーションでこの Cloud Functions のファンクションにリクエストを送信するために使用されるエンドポイント URL が表示されます。
これで完了です。このセクションで行う作業はこれですべてです。エンドポイントはユーザー インターフェースのクライアント アプリケーションで使用され、ユーザー パラメータをリクエストとして Cloud Functions のファンクションに送信し、映画のスコアをレスポンスとして受け取ります。また、エンドポイントはレスポンスとリクエストを MongoDB コレクションに書き込みます。
次のステップ
ここまでお付き合いいただきありがとうございました。その成果として、お好きな映画の予測スコアをぜひチェックしてみてください。
SQL を使用して、手動で BigQuery ML と Vertex AI Auto ML モデルの間で精度やその他の評価パラメータを分析し、比較します。
独立変数を微調整して、予測結果の精度を高めてみましょう。
さらに一歩進んで、概算の整数ではなく浮動小数点 / 小数点値としてスコアを予測することにより、線形回帰モデルと同じ問題を試しみてください。
本投稿の主要コンセプトの詳細については、以下のページをご覧ください。
- Google、Abirami Sukumaran
- MongoDB、Stanimira Vlaeva