Vertex Model Monitoring で活用する、Google の MLOps 監視手法
Google Cloud Japan Team
※この投稿は米国時間 2021 年 7 月 31 日に、Google Cloud blog に投稿されたものの抄訳です。
この記事では、MLOps の大きな課題のひとつである「本番環境で運用中の機械学習(ML)モデルの性能監視」を、Google Cloud における ML/AI 向け統合プラットフォーム Vertex AI で実現する方法を解説します。この監視を実現する Vertex Model Monitoring は、以下の 3 つの特徴を備えます。
Vertex AI のオンライン予測サービス Vertex Prediction にデプロイされたモデルの性能変化を検出できます。面倒な事前作業は不要で、いくつかのパラメータを指定してコマンドを実行するだけで監視を開始できます。
特徴量のスキューやドリフトを検出し、アラートを送出します。
コンソール UI で特徴量の分布とその変化を可視化します。問題を迅速に診断し、すばやい対応が可能になります。

Google が ML 実運用で直面した Training-serving skew とは
Vertex Model Monitoring は、トレーニング時にしたモデル性能とサービング時の性能の差である「Training-serving skew」を検出します。このスキュー(ずれ)は、以下のような原因で発生します(機械学習のルール: ML エンジニアリングのベストプラクティスより)。
トレーニング時とサービング用のデータパイプラインの間で生じたデータ処理方法の違い
トレーニング時とサービング時の間で起きるデータそのものの変化
モデルとアルゴリズムの間で生じるフィードバック ループ
この記事では、上記のうち最初の 2 つで説明されている問題の特定に焦点を当てます。つまり、トレーニングとサービングの間におけるデータ(特徴量)の変化です。これらはデータドリフトまたは共変量シフトとも呼ばれます。なお 3 つ目のフィードバック ループの問題は、適切な ML システム設計によって解決されるべきものです。この問題を回避する Vertex Feature Store の詳細については、こちらのブログ投稿をご参照ください。
データの変化は、本番環境のデータ パイプラインに誤ってバグが混入した場合や、モデルが学習した特徴量と予測値の関係が根本的に変化した場合、そしてサービスが不正アクセスを受けた場合など、さまざまな理由で発生します。
実際の例として、過去に Google のあるサービスが影響を受けたケースを見てみましょう。Data Validation for Machine Learning 論文では以下のような事例が紹介されています。
ML パイプラインが新しい ML モデルのトレーニングを一日一回実行している
あるエンジニアがサービス スタックのリファクタリングを行った際に、特定の特徴量を「-1」に固定してしまうバグが誤って生じた
ML モデルはデータの変化に対して堅牢であるがゆえに、エラーは出力されず、精度が低いまま予測値を生成し続けてしまう
次のモデルのトレーニング時にサービング データが再利用される。この問題はなかなか発見されず、事態はどんどん悪化していく
このシナリオが示すように、Training-serving skew は、時にプログラム コードにおける P0 バグと同じくらい有害なものになりえます。こうした問題を早期に発見するために、Google では実運用されている ML サービスにおいて Training-serving skew 検出の厳格な取り組みを導入しています。こちらの TFX 論文をご覧ください。

この取り組みにより、Google Play ではモバイルアプリのインストール率が大幅に向上しました。以下は、TFX 論文で紹介されている事例です。
Google Play チームでは、同じ日のサービスログとトレーニング データの統計情報を比較する手法を導入しました。これにより、ログでは常に欠落しているがトレーニングでは存在するいくつかの特徴量を発見しました。このスキューを取り除くことで、Google Play ストアのランディング ページでのアプリ インストール率が 2% 向上しました。
(TFX: TensorFlow ベースの本番環境規模の機械学習プラットフォームより)
この事例を通じて Google が学んだ MLOps の貴重な教訓のひとつは、モデルに入力するデータを継続的に監視し、その変化を検出することの重要さです。実運用の ML サービスにおいて、これは単体テストを記述するのと同じくらい大事なことです。
では、Vertex AI においてスキュー検出がどのように行われるのかを見てみましょう。
スキューの検出方法
Vertex Model Monitoring では、数値型またはカテゴリ型の特徴量におけるスキューとドリフトの検出を可能にします。まず監視対象の特徴量について、トレーニング データ内の分布が計算されます。これがベースラインとなります。
モデルのサービングが開始されると、推論時に入力された特徴量が一定間隔で記録されます。この間隔はデフォルトでは 24 時間に設定されていますが、1 時間以上であれば任意の値に設定できます。個々の時間枠において監視対象の各特徴量の分布が計算され、前述のベースライン分布との差(距離)が計算されます。このとき、数値型の特徴量には JS divergence を、カテゴリ型の特徴量には L 距離が用いられます。この距離が設定したしきい値を超えた場合、トレーニング時と運用時でスキューが発生したと見なされます。
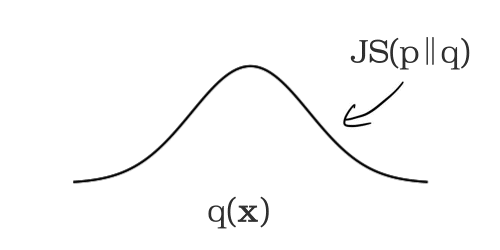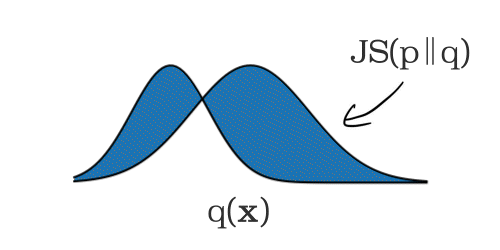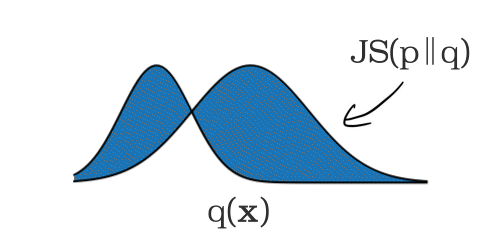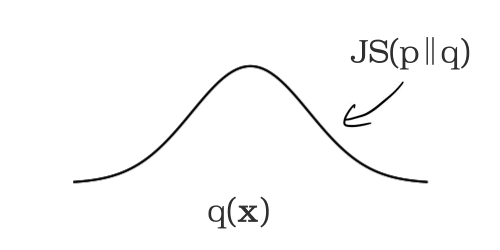
特徴量の分布変化の計測
ML モデルの監視を簡単コマンド設定
Model Monitoring の開発チームの目標は、Vertex Prediction にデプロイされたモデルの監視を、スイッチを入れるくらい簡単に開始できるようにすることでした。Vertex Prediction のエンドポイントが起動したあとに gcloud コマンドを 1 回実行するだけで Training-serving skew 検出が開始します(コンソール UI での設定も近日中に対応予定です)。前処理や追加の設定作業は一切必要ありません。
Model Monitoring によるスキュー検出を設定するには、以下のような gcloud コマンドを実行するだけです。
主なパラメータを見てみましょう(このコマンドのドキュメント全体はこちらを参照してください)
emails: アラートを受け取るメールアドレス
endpoint: 監視したいエンドポイント ID
prediction-sampling-rate: サンプリング率。多くの場合、推論時に入力された特徴量のすべてを監視する必要はありません。このパラメータでは、監視用に記録・分析される推論リクエストの割合を設定します。
feature-thresholds: 監視する特徴量とそのしきい値を指定します。このしきい値を超えるとアラートが送出されます。これは省略可能なパラメータです。デフォルトでは各特徴量に 0.3 のしきい値が使用されます。
dataset: ベースラインを算出するためのトレーニング データセットを指定します。BigQuery テーブル、Cloud Storage 上の CSV ファイル、Cloud Storage 上の TFRecord ファイル、または Vertex AI 上のマネージド データセットのいずれかから指定できます。「BigQuery の URI」、「データセット」、「データ フォーマット」、および「GCS の URI」のパラメータについて詳しくは、gcloud ドキュメントをご覧ください。
target-field: モデルの予測対象のフィールドまたはカラム(ラベルとも呼ばれます)を指定します。
monitoring-frequency: 監視の間隔を指定します。これは省略可能なパラメータです。デフォルトでは 24 時間に設定されています。
コンソール UI で特徴量分布を可視化
ある特徴量においてスキューが検出されると、メールでアラートが送信されます(モデルの学習パイプラインを起動する仕組みなど、アラートの処理方法が今後さらに追加される予定です)。
アラートを受信したら、コンソール UI にログインして特徴量の分布を可視化して分析できます。サービング環境で計測された特徴量の分布とトレーニング時の分布を並べて可視化することで、問題を診断できます。

次のステップ
現在、Vertex Model Monitoring はプレビュー版が公開されており、Model Monitoring ドキュメントからどなたでも試せます。また、Marc Cohen が作成した素晴らしいデモ動画とサンプル ノートブックもあり、モデルのエンドポイントへのデプロイから Model Monitoring による監視までのシナリオ全体を体験できます。Google が提案する ML システムの生産性向上のためのベスト プラクティスを参考に、MLOps の世界への第一歩を踏み出しましょう。
-Google Cloud デベロッパー アドボケイト Kaz Sato
-Cloud AI Platform プロダクト マネージャー Anand Iyer




