Google Cloud でレコメンデーション システムの構築をお考えですか?以下のガイドラインに沿って適切なソリューションをお選びください(パート I)
Google Cloud Japan Team
※この投稿は米国時間 2022 年 2 月 3 日に、Google Cloud blog に投稿されたものの抄訳です。
過去 20 年にわたり、消費者はインターネットを利用するあらゆる場面で、カスタマイズされたレコメンデーションを受け取ることが当たり前になっています。Amazon で買い物をすればおすすめ商品、Google Play ストアではおすすめアプリ、YouTube では関連動画が表示されます。実際に、Verge の記事「How YouTube perfected the feed: Google Brain gave YouTube new life(YouTube がフィードを最適化: Google Brain で YouTube が活気を取り戻す)」で、「人々が動画を視聴する時間の 70% 以上がアルゴリズムを利用した YouTube のおすすめ機能によるもの」であり、レコメンデーション エンジンのおかげで YouTube の視聴時間が 3 年間で 20 倍に増えたことを Google Brain チームが明らかにしています。
カスタマイズされたレコメンデーションはもはや組織にとって差別化要素ではなく、消費者にとって日常的なオンライン体験に当然のものとなっています。この流れに乗り遅れている、または既存のレコメンデーションを改善したい企業はどうすべきでしょうか?コンテンツベースのシステムからディープ ラーニングまで手法は数多くありますが、このブログ シリーズでは Google Cloud でレコメンデーション システムを構築する 3 つの方法を解説します。それは、BigQuery 機械学習での行列分解(BQML)、Recommendations AI、Two-Tower 組み込みアルゴリズムによるディープ リトリーブです。
この 3 つの方法は、パーソナライズを始めたばかりの企業や、かなり進んでいる企業など、どの段階の企業にも対応します。この 1 回目のブログ投稿では、3 つの方法の概要とそれぞれに適したケースを紹介します。
行列分解の概要と仕組み
コラボレーション フィルタリングは、入力データセットが単純でエンベディングが自動的に学習されるため、レコメンデーション システム構築の基本モデルです。では、行列分解はどこに使えばいいのでしょう?行列分解とは単にコラボレーション フィルタリングを応用するモデルです。BQML では、ユーザーが直接データ ウェアハウスで標準 SQL を使用し、行列分解モデルの作成と実行ができます。
コラボレーション フィルタリングは相互作用行列の作成から始まります。相互作用行列では、ユーザーを行、アイテムを列としてデータセット内で表現します。すべてのユーザーがカタログ内の多くのアイテムと相互作用を持つとは限らないため、通常、相互作用行列は本質的にスパースです。そこでエンベディングが役立ちます。ユーザーとアイテムのエンベディングを生成すれば、多くのスパースな特徴を下の次元のスペースに折りたためるだけでなく、類似度の基準を導くことで、エンベディング スペース内で類似のユーザーやアイテムを近くに配置できます。コラボレーション フィルタリングはユーザーとアイテムの類似度を使用して最終的なレコメンデーションを行うため、類似度の基準は非常に重要です。映画であれハンドバッグであれ、類似のユーザーは類似のアイテムを好むはずだというのが基本的なアイデアです。
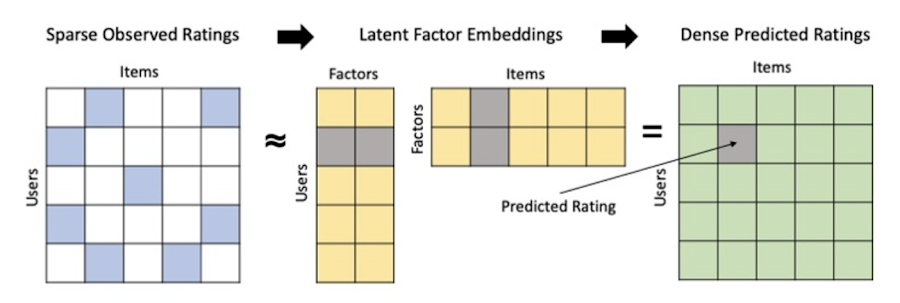
最初に必要なこと
行列分解モデルのトレーニングには、ユーザー、アイテム、暗黙的または明示的なフィードバック変数(明示的なフィードバックの例としてレーティングがあります)という 3 つの入力列を含むテーブルが必要です。基本入力データセットがあれば、CREATE MODEL SQL ステートメントでいくつかのハイパーパラメータを指定した後、BigQuery で簡単にモデルを実行できます。ハイパーパラメータでは、エンベディングの数、フィードバックの種類、適用する L2 正則化の量などを指定できます。
この方法を使用する理由と適したケース
前述のとおり、BQML の行列分解はレコメンデーション システムを初めて使用する方に最適です。行列分解には、次のような多くの利点があります。
ML に関する専門知識がほとんど不要: SQL を使用してモデルを構築すれば、ML に関する専門知識のレベルが低くて済みます。
入力の特徴がほとんど不要: データ入力が簡単なので、単純な相互作用行列で済みます。
他の分析情報: コラボレーション フィルタリングはユーザーの新しい関心やユーザーに適した新しい製品の発見に適しています。
行列分解はレコメンデーションを作成する優れたツールですが、注意事項がいくつかあり、ユースケースによっては不利な場合もあります。
多数の特徴群には不適: 入力テーブルには 2 つの特徴列しか含めることができません(ユーザーとアイテムなど)。コンテキスト シグナルなど他の特徴を含める必要がある場合は、行列分解が適していない可能性があります。
新しいアイテム: アイテムがトレーニング データにない場合、システムは対応のエンベディングを作成できず、類似アイテムを提案することが難しくなります。このコールド スタートの問題に対処する方法はいくつかありますが、アイテム カタログに新しいアイテムが多く含まれる場合は、行列分解が適していない可能性があります。
入力データの制限: 入力行列はスパースと想定されていますが、フィードバックのないトレーニング サンプルは問題を引き起こす可能性があります。少なくとも複数のフィードバック(レーティングなど)サンプルを持つアイテムとユーザーをフィルタすればモデルは改善されます。制限について詳しくは、こちらをご覧ください。
概して、パーソナライズ AI に向けた第一歩として、簡潔なデータセットを持ち、短時間で反復してベースラインとなるレコメンデーション システムを作成したいユーザーには行列分解が最適です。
Recommendations AI の概要と仕組み
Recommendations AI とは、Two-Tower エンコーダなどの最新アーキテクチャを含め、最先端のディープ ラーニング技術を使用したスケーラブルなレコメンデーション システムの導入を助けるフルマネージド サービスであり、カスタマー ジャーニー全般を通じて個人と状況に応じたレコメンデーションを提供します。
ディープ ラーニング モデルは、前述の行列分解の制限に簡単に対処できるため、レコメンデーションを表示する状況とレコメンデーションの妥当性を部分的に改善します。また、ユーザーとアイテムの特徴を幅広く含み、本質的に、これらの特徴から徐々に有意義な表現を学習していくことに重点を置いています。この柔軟性と表現度により、寿命の短いファッション トレンドや珍しいユーザー行動などの複雑な関係も捉えることができます。関連性は高いものの、ディープ ラーニング レコメンダーには、トレーニングが難しく、大規模な運用に高いコストがかかるという欠点があります。
Recommendations AI があれば、企業はこのようなディープ ラーニング モデルを利用し、低いレイテンシでグローバルにモデルを運用するために必要な MLOps を実践できます。モデルは毎日自動的に再トレーニングされ、四半期に 1 回の調整によって顧客の行動、品揃え、価格、プロモーションにおける変化も反映されます。新しくトレーニングされたモデルは、復元力の高い CI / CD プロセスによって運用に適していることが確認され、サービスの中断なしに本番環境に移行されます。モデルは、推論時に効率的にアイテムを取得するスケーラブルな近似最近傍探索(ANN)サービスの使用により低レイテンシを実現します。また、スケーラブルな特徴量ストアを使用してオンライン タスクとオフライン タスクの一貫性を維持し、データ漏洩やトレーニング サービング スキューなど、本番環境の一般的な問題を防ぎます。

最初に必要なこと
Recommendations AI の利用を開始するには、まず製品データとユーザーデータを API に取り込む必要があります。
製品カタログのインポート: 大規模な製品カタログの更新があった場合は、catalogItems.import メソッドを使用してカタログのアイテムを一括で取り込みます。頻繁なカタログの更新は Google Merchant Center または BigQuery でスケジュール設定します。
ユーザー イベントの記録: ユーザー イベントは、製品のクリック、カートへのアイテム追加、アイテムの購入などのアクションを追跡します。このようなイベントは、リアルタイムで取り込み、最新のユーザー行動を反映してから、製品カタログにインポートしたアイテムに結合する必要があります。
ユーザー イベント履歴のインポート: モデルが正確な予測を行うには十分なトレーニング データが必要です。推奨されるユーザー イベント データの量はモデルの種類によって異なります(詳しくはこちら)。
データの要件を満たせば、1 つまたは複数のモデルを作成し、レコメンデーションを提供できます。
レコメンデーションの種類と場所の判断: レコメンデーション パネルの場所とパネルの目的はモデルのトレーニングと調整に影響を与えます。使用可能なレコメンデーションの種類、最適化の目標、その他のモデル調整オプションを検討し、ビジネスの目標に最適なオプションを判断します。
モデルの作成: 初期のモデル トレーニングと調整には、ユーザー イベントの数や製品カタログの大きさにより 2~5 日かかります。
サービング設定の作成とレコメンデーションのプレビュー: モデルを有効化した後は、サービング設定を作成し、レコメンデーションのプレビューによって設定が予想どおりに機能することを確認した上で本番環境トラフィックに適用します。
サービングの準備ができたら A/B テストを設定し、新しくトレーニングしたモデルがカスタマー エクスペリエンスにどれだけ影響を与えるかをまず理解します。その後でトラフィックに 100% 適用することをおすすめします。Recommendations AI コンソールのモニタリング&アナリティクス ページでは、概要と配置ごとの指標(レコメンダーが関与した収益、クリック率、コンバージョン率など)を確認できます。
この方法を使用する理由と適したケース
Recommendations AI は、顧客とつながり、パーソナライズを通じてオンライン プレゼンスを高める優れた方法です。本番環境のレコメンデーション システムの技術的経験がないチームや、自社チームの技術能力を他の優先事項や課題に向けたい企業に使用されています。チームの技術的経験や余力にかかわらず、Recommendations AI には複数のメリットを期待できます。
フルマネージド サービス: データの前処理、機械学習モデルのトレーニングやハイパーパラメータ調整、負荷分散、インフラストラクチャの手動プロビジョニングなどは、すべて自動で行われるため不要です。Recommendations API は、パフォーマンスを長期的にモニタリングするための使いやすいコンソールも提供します。
最先端の AI: Google 広告、Google 検索、YouTube でレコメンデーションの提供に使用されているのと同じモデリング手法を利用できます。このようなモデルは、ロングテール商品のほか、ユーザーやアイテムのコールド スタートに適しています。
すべてのタッチポイントに対応: 初めてのユーザーにもリピーターにも、ウェブ、モバイル、メールなどあらゆる場所で質の高いレコメンデーションを提供します。
グローバルに提供: 完全に自動化されたグローバルなサービング インフラストラクチャにより、どの言語でも世界中どこでも低レイテンシでレコメンデーションを提供します。
データもモデルも自社が保有: データとモデルは利用者のものです。他の Google サービスで使用されたり、他の Google ユーザーが目にしたりすることは決してありません。
自社のレコメンデーション システムに最先端の AI を利用したいが、既存のソリューションですぐに運用を開始したいユーザーには、Recommendations AI が最適です。
Two-Tower エンコーダの概要と仕組み
ご存じのように、レコメンデーション システム デザインの目的は、特定のユーザーまたはユーザー グループに最も関連度の高いアイテム群を提示することです。通常、アイテムは候補と呼ばれ、アイテムのタイトルや説明のほか、言語、表示回数、特定期間におけるアイテムのクリック数など、他のメタデータも含める場合があります。ユーザーは通常、レコメンデーション システムへのクエリという形で表現され、ユーザーの位置、優先言語、過去の検索などの詳細情報が提供される場合もあります。
一般的な例から始めましょう。映画のレコメンデーション システムを作成するとします。そのようなシステムの入力候補には何千もの映画、クエリセットには何百万もの視聴者が含まれます。取得段階の目標は、少数の映画(候補)を選び出し、スコアや順位を付けた上で最終的なおすすめリストとしてクエリ / ユーザーに表示することです。
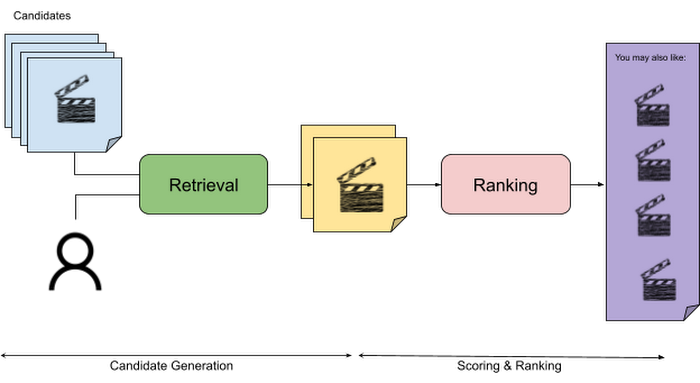
取得段階では、候補データとクエリデータの両方をエンコードして候補リストを絞り込み、同じエンベディング空間を共有させることができます。適切なエンベディング空間では、類似の候補が互いに近くに配置され、類似しないアイテムやクエリはエンベディング空間で離れて配置されます。
クエリと候補のエンベディングのデータベースを作成した後は、近似最近傍探索(ANN)を使用し、最終的な「類似」候補リストを生成します。つまり、特定のクエリ / ユーザーに対して所定数の最近傍を見つけ、最終的なレコメンデーションを作成します。
最初に必要なこと
最も基本的なレベルでは、Two-Tower モデルのトレーニングに以下の入力が必要です。
トレーニング データ: トレーニング データは、クエリ / ユーザーのデータと候補 / アイテムに関するデータを組み合わせて作成されます。トレーニング データは、ユーザー情報とアイテム情報の両方が揃った一致ペアを含む必要があります。また、トレーニング セットのデータには、テキスト、数値データ、さらには画像など、多くの形式を含めることができます。
入力スキーマ: 入力スキーマは、トレーニング データの組み合わせと任意の具体的な特徴設定のスキーマを説明します。
Vertex AI では、既存の Two-Tower 組み込みアルゴリズムを補完し、実行中に利用できる複数のサービスが提供されています。
最近傍(ANN)サービス: Vertex AI マッチング エンジンと ScANN は、類似したエンベディングの特定を容易にする高スケールかつ低レイテンシの近似最近傍(ANN)サービスを提供します。
ハイパーパラメータ調整サービス: Vizier などのハイパーパラメータ調整サービスは、隠れ層の数、隠れ層のサイズ、少ない試行回数での学習率など、最適なハイパーパラメータを特定できるようにします。
ハードウェア アクセラレータ: GPU や TPU などの専用ハードウェアは、テストを高速化し、トレーニング サイクルをスピードアップする意味でレコメンデーション システムにとって有益です。
この方法を使用する理由と適したケース
Two-Tower 組み込みアルゴリズムは、複数のメリットがある、レコメンデーション システムの「カスタム スポーツカー」と言えます。
強力なコントロール: Recommendations AI は利用可能なアーキテクチャの一つとして Two-Tower アーキテクチャを使用しますが、モデル トレーニング、サンプル生成、モデル検証の詳細について綿密な制御機能や可視化機能を備えていません。一方、Two-Tower 組み込みアルゴリズムではノートブック環境でモデルを直接トレーニングするため、より柔軟なカスタマイズが可能です。
特徴オプションが豊富: Two-Tower モデルはテキストから画像まで多くのコンテキスト シグナルに対応します。
コールド スタートのケース: 豊富な特徴群はパフォーマンスを高めるだけでなく、新しいユーザーや候補に対応する候補生成を可能にします。
Two-Tower 組み込みアルゴリズムはレコメンデーションを導く最高水準のソリューションですが、ユースケースによっては注意事項や欠点が伴う場合もあります。
ML に関する技術的な専門知識が必要: Two-Tower エンコーダは前述の他の方法のような「プラグ アンド プレイ」ではありません。有効に活用するには、コーディングと ML に関する適切な専門知識が必要です。
分析情報を得るまでの時間: Two-Tower エンコーダでカスタム ソリューションを構築した場合、ユーザー向けに構築済みのソリューションより時間がかかる場合があります。
強力なコントロールと高い柔軟性を望み、マネージド ノートブック環境で容易に作業する技術的知識を持つユーザーには、Two-Tower 組み込みアルゴリズムが最適です。
次のステップ
この記事では、Google Cloud Platform でレコメンデーション システムを構築する 3 つの一般的な方法を説明しました。ご覧いただいたように、最終的な方法を選ぶまでに多くの点を考慮する必要があります。なるべく短時間でお選びいただけるよう、決定の基準を少数の単純なステップ(詳細は以下を参照)として抜き出しました。
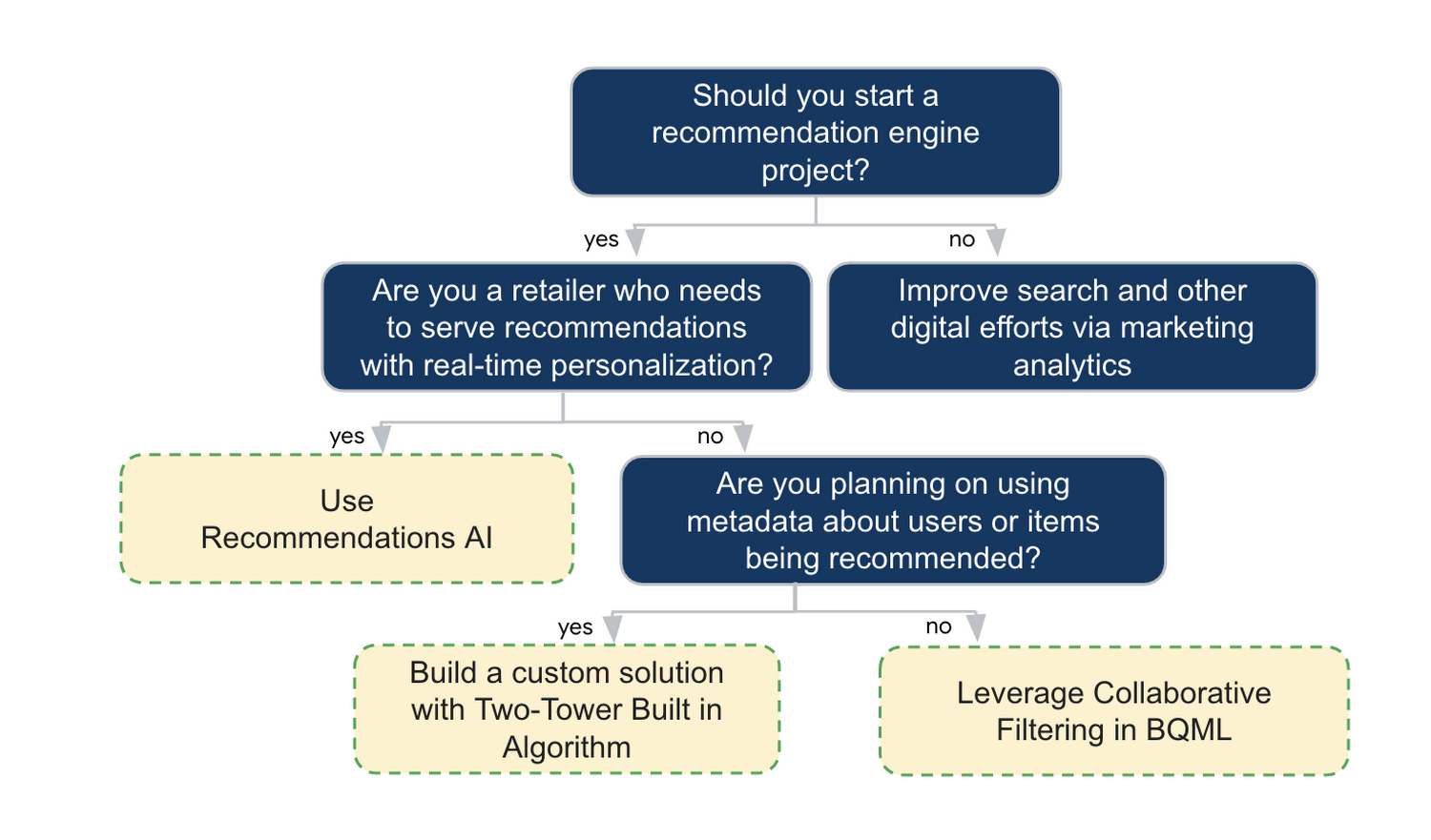
このシリーズの今後のブログ投稿では、それぞれの方法をさらに掘り下げるとともに、ハードウェア アクセラレータがレコメンデーション システムの設計に果たす重要な役割や、レコメンデーション システムを主要業種で活用する方法について説明します。レコメンデーション システムに関するシリーズの今後のブログ投稿にぜひご期待ください。ご精読ありがとうございました。質問がある場合やチャットを希望する場合は、こちらで著者をお探しください。R.E. [Twitter | LinkedIn]、Jordan [LinkedIn]、Vaibhav [LinkedIn]。
謝辞
この記事の査読を手伝ってくれた Pallav Mehta、Henry Tappen、Abhinav Khushraj、Nicholas Edelman に特に感謝します。
関連情報
- 機械学習スペシャリスト R.E. Wolfe
- 機械学習スペシャリスト Jordan Totten
- 機械学習スペシャリスト、アウトバウンド プロダクト マネージャー Vaibhav Singh



