Looking to build a recommendation system on Google Cloud? Leverage the following guidelines to identify the right solution for you (Part I)
R.E. Wolfe
Machine Learning Specialist
Jordan Totten
ML Specialist, Google Cloud
Over the past two decades, consumers have become accustomed to receiving personalized recommendations in all facets of their online life. Whether that be recommended products while shopping on Amazon, a curated list of apps in the Google Play store, or relevant videos to watch next on YouTube. In fact, in a Verge article “How YouTube perfected the feed: Google Brain gave YouTube new life,” the Google Brain team reveals how their recommendation engine has impacted the platform with “more than 70 percent of the time people spend watching videos on the site being driven by YouTube’s algorithmic recommendations” thereby increasing time spent on the platform by 20X in three years.
It’s become clear that personalized recommendations are no longer a differentiator for an organization but rather something consumers have come to expect in their day-to-day experiences online. So what should you do if you are behind the curve and want to get started or simply want to improve upon what you already have? While there are all sorts of techniques, from content-based systems to deep learning methods, our goal in this recommender-focused blog series is to demystify three available approaches to building recommendation systems on Google Cloud: Matrix Factorization in BigQuery Machine Learning (BQML), Recommendations AI, and deep retrieval techniques available via the Two-Tower built-in algorithm.
One of these approaches can be used to meet you where you are in your personalization journey, no matter if you are just starting or if you are well into it. This first blog post will introduce our three approaches and when to use them.
What is Matrix Factorization and how does it work?
Collaborative filtering is a foundational model for building a recommendation system as the input dataset is simple and the embeddings are learned for you. How does Matrix factorization fit into the mix you might be wondering? Matrix factorization is simply the model that applies collaborative filtering. BQML enables users to create and execute a matrix factorization model by using standard SQL directly in the data warehouse.
Collaborative filtering begins by creating an interaction matrix. The interaction matrix represents users as a row and items as columns in your dataset. This interaction matrix often is sparse in nature as not all users will have interacted with many items in your catalog. This is where embeddings come into play. Generating embeddings for users and items not only allows you to collapse many sparse features into a lower dimensional space but they also allow you to derive a similarity measure so that similar users/items fall nearby in the embedding space. These similarity measures are key as collaborative filtering uses similarities between users and items to make the end recommendations. The underlying assumption being that similar users will like similar items whether that be movies or handbags.
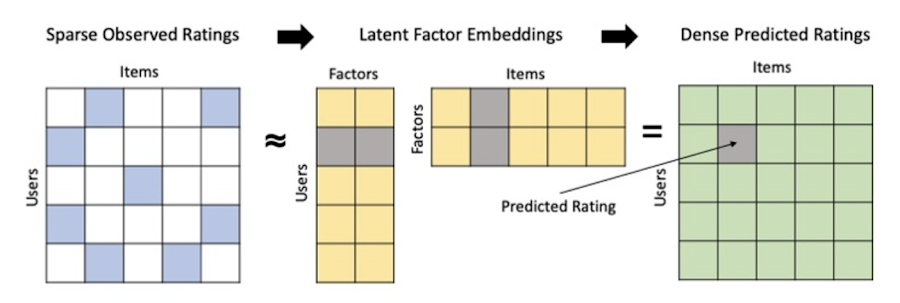
What's required to get started?
To train a matrix factorization model you need a table that includes three input columns: user(s), item(s), and an implicit or explicit feedback variable (e.g., ratings is an example of explicit feedback). With the base input dataset in place, you can then easily run your model in BigQuery after specifying several hyperparameters in your CREATE MODEL SQL statement. Hyperparameters are available to specify the number of embeddings, the feedback type, the amount of L2 regularization applied and so on.
Why use this approach and who is it a good fit for?
As mentioned earlier, Matrix Factorization in BQML is a great way for those new to recommendation systems to get started. Matrix factorization has many benefits:
Little ML Expertise: Leveraging SQL to build the model lowers the level of ML expertise needed
Few Input Features: Data inputs are straightforward, requiring a simple interaction matrix
Additional Insight: Collaborative filtering is adept at discovering new interests or products for users
While Matrix Factorization is a great tool for deriving recommendations it does come with additional considerations and potential drawbacks depending upon the use case.
Not Amenable to Large Feature Sets: The input table can only contain two feature columns (e.g., user(s), item(s)). If there is a need to include additional features such as contextual signals, Matrix factorization may not be the right method for you.
New Items: If an item is not available in the training data, the system can’t create an embedding for it and will have difficulty recommending similar items. While there are some workarounds available to address this cold-start issue, if your item catalog often includes new items, Matrix factorization may not be a good fit.
Input Data Limitations: While the input matrix is expected to be sparse, training examples without feedback can cause problems. Filtering for items and users that have at least a handful of feedback (e.g., ratings) examples can improve the model. More information on limitations can be found here.
In summary, for users with a simplified dataset looking to iterate quickly and develop a baseline recommendation system, Matrix Factorization is a great approach to begin your personalization AI journey.
What is Recommendations AI and how does it work?
Recommendations AI is a fully managed service which helps organizations deploy scalable recommendation systems that use state-of-the-art deep learning techniques, including cutting-edge architectures such as two-tower encoders, to serve personalized and contextually relevant recommendations throughout the customer journey.
Deep learning models are able to improve the context and relevance of recommendations in part because they can easily address the previously mentioned limitations of Matrix Factorization. They incorporate a wide set of user and item features, and by definition they emphasize learning successive layers of increasingly meaningful representations from these features. This flexibility and expressivity allows them to capture complex relationships like short-lived fashion trends and niche user behaviors. However, this increased relevance comes at a cost, as deep learning recommenders can be difficult to train and expensive to serve at scale.
Recommendations AI helps organizations take advantage of serving these deep learning models and handles the MLOps required to serve these models globally with low latency. Models are automatically retrained daily and tuned quarterly to capture changes in customer behavior, product assortment, pricing, and promotions. Newly trained models follow a resilient CI/CD routine which validates they are fit to serve and promotes them to production without service interruption. The models achieve low serving latency by using a scalable approximate nearest neighbors (ANN) service for efficient item retrieval at inference time. And, to maintain consistency between online and offline tasks, a scalable feature store is used, preventing common production challenges such as data leakage and training-serving skew.

What's required to get started?
To get started with Recommendations AI we first need to ingest product and user data into the API:
Import product catalog: For large product catalog updates, ingest catalog items in bulk using the catalogItems.import method. Frequent catalog updates can be schedule with Google Merchant Center or BigQuery
Record user events: User events track actions such as clicking on a product, adding items to cart, or even purchasing an item. These events need to be ingested in real time to reflect the latest user behavior and then joined to items imported in the product catalog
Import historical user events: The models need sufficient training data before they can provide accurate predictions. The recommended user event data requirements are different across model types (learn more here)
Once the data requirements are met, we are able to create one or multiple models to serve recommendations:
Determine your recommendation types and placements: The location of the recommendation panel and the objective for that panel impact model training and tuning. Review the available recommendations types, optimization objectives, and other model tuning options to determine the best options for your business objectives.
Create model(s): Initial model training and tuning can take 2-5 days depending on the number of user events and size of the product catalog
Create serving configurations and preview recommendations: After the model is activated, create serving configurations and preview the recommendations to ensure your setup is functioning as expected before serving to production traffic
Once models are ready to serve, consider setting up A/B experiments to understand how newly trained models impact your customer experience before serving them to 100% of your traffic. In the Recommendations AI console, see the Monitoring & Analytics page for summary and placement-specific metrics (e.g., recommender-engaged revenue, click-through-rate, conversion rate, and more).
Why use this approach and who is it a good fit for?
Recommendations AI is a great way to engage customers and grow your online presence through personalization. It’s used by teams who lack technical experience with production recommendation systems, as well as customers who have this technical depth but want to allocate their team’s effort towards other priorities and challenges. No matter your team’s technical experience or bandwidth, you can expect several benefits with Recommendations AI:
Fully managed service: no need to preprocess data, train or hypertune machine learning models, load balance or manually provision you infrastructure - this is all taken care of for you. The recommendation API also provides a user-friendly console to monitor performance over time.
State-of-the-art AI: take advantage of the same modeling techniques used to serve recommendations across Google Ads, Google Search, and YouTube. These models excel in scenarios with long-tail products and cold-starts users and items
Deliver at any touchpoint: serve high-quality recommendations to both first-time users and loyal customers anywhere in their journey via web, mobile, email, and more
Deliver globally: serve recommendations in any language anywhere in the world at low-latency with a fully automated global serving infrastructure
Your data, your models: Your data and models are yours. They’ll never be used for any other Google product nor shown to any other Google customer
For users looking to leverage state of the art AI to fuel their recommendation systems but need an existing solution to get up and running more quickly, Recommendations AI is the right solution for you.
What are Two Tower encoders and how do they work?
As a reminder, in recommendation system design, our objective is to surface the most relevant set of items for a given user or set of users. The items are usually referred to as the candidate(s) where we might include information about the items such as the title or description of the item, other metadata about the item like language, number of views, or even clicks on the item over time. User(s) are often represented in the form of a query to a recommendation system where we might provide details about the user such as the location of the user, preferred languages, and what they have searched for in the past.
Let’s start with a common example. Imagine that you are creating a movie recommendation system. The input candidates for such a system would be thousands of movies and the query set can consist of millions of viewers. The goal of the retrieval stage is to select a smaller subset of movies(candidates) for each user and then score and rank order them before presenting the final recommended list to the query/user.
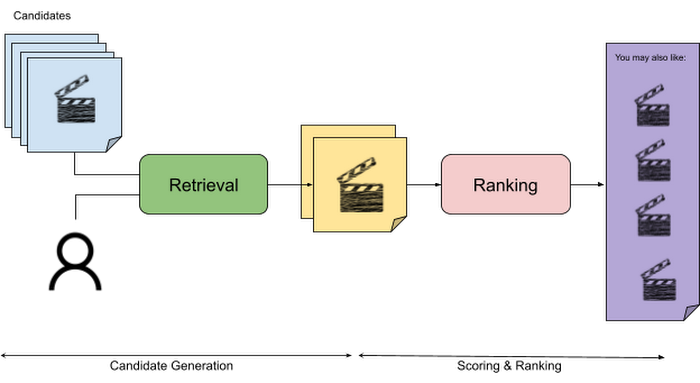
The retrieval stage is able to refine our list of candidates by encoding both the candidate and the query data so they share the same embedding space. A good embedding space will place candidates which are similar to one another closer together and dissimilar items/queries farther apart in the embedding space.
Once we have a database of query and candidate embeddings we can then use an approximate nearest neighbor search method to then generate a list of final “like” candidates, i.e. find a certain number of nearest neighbors for a given query/user and surface final recommendations.
What's required to get started?
At the most basic level, in order to train a two-tower model you need the following inputs:
Training Data: Training data is created by combining your query/user data with data about the candidates/items. The data must include matched pairs, cases where both user and item information is available. Data in the training set can include many formats from text, numeric data, or even images.
Input Schema: The input schema describes the schema of the combined training data along with any specific feature configurations.
Several services within Vertex AI have come available that complement the existing Two-Tower built-in algorithm and can be leveraged in your execution:
Nearest Neighbor (ANN) Service: Vertex AI Matching Engine and ScANN provide a high-scale and low-latency Approximate Nearest Neighbor (ANN) service so you can more easily identify similar embeddings.
Hyperparameter Tuning Service: A hyperparameter tuning service such as Vizier can help you identify the optimal hyperparameters such as the number of hidden layers, the size of the hidden layers, and the learning rate in fewer trials.
Hardware Accelerators: Specialized hardware, such as GPUs or TPUs, can be valuable in your recommendation system to help accelerate experiments and improve the speed of training cycles.
Why use this approach and who is it a good fit for?
The Two-Tower built-in algorithm can be considered the “custom sports car” of recommendation systems and comes with several benefits:
Greater Control: While Recommendations AI uses the two-tower architecture as one of the available architectures it doesn’t provide granular control or visibility into model training, example generation, and model validation details. In comparison, the Two-Tower built in algorithm provides a more customizable approach as you are training a model directly in a notebook environment.
More Feature Options: The Two Tower approach can handle additional contextual signals ranging from text to images.
Cold Start Cases: Leveraging a rich set of features not only enhances performance but also allows the candidate generation to work for new users or new candidates.
While the Two-Tower built in algorithm is an excellent and best-in class solution for deriving recommendations, it does come with additional considerations and potential drawbacks depending upon the use case.
Technical ML Expertise Required: Two tower encoders are not a “plug and play” solution like the other approaches mentioned above. In order to effectively leverage this approach, appropriate coding and ML expertise is required.
Speed to Insight: Building out a custom solution via two-tower encoders may require additional time as the solution is not pre-built for the user.
For users looking for greater control, increased flexibility, and have the technical chops to easily work within a managed notebook environment - the two-tower built in algorithm is the right solution for them.
What’s next?
In this article, we explored three common methods for building recommendation systems on Google Cloud Platform. As you can see thus far, there are alot of considerations to take into account before choosing a final approach. In an effort to help you align more quickly we have distilled the decision criteria down to a few simple steps (see below for more details).
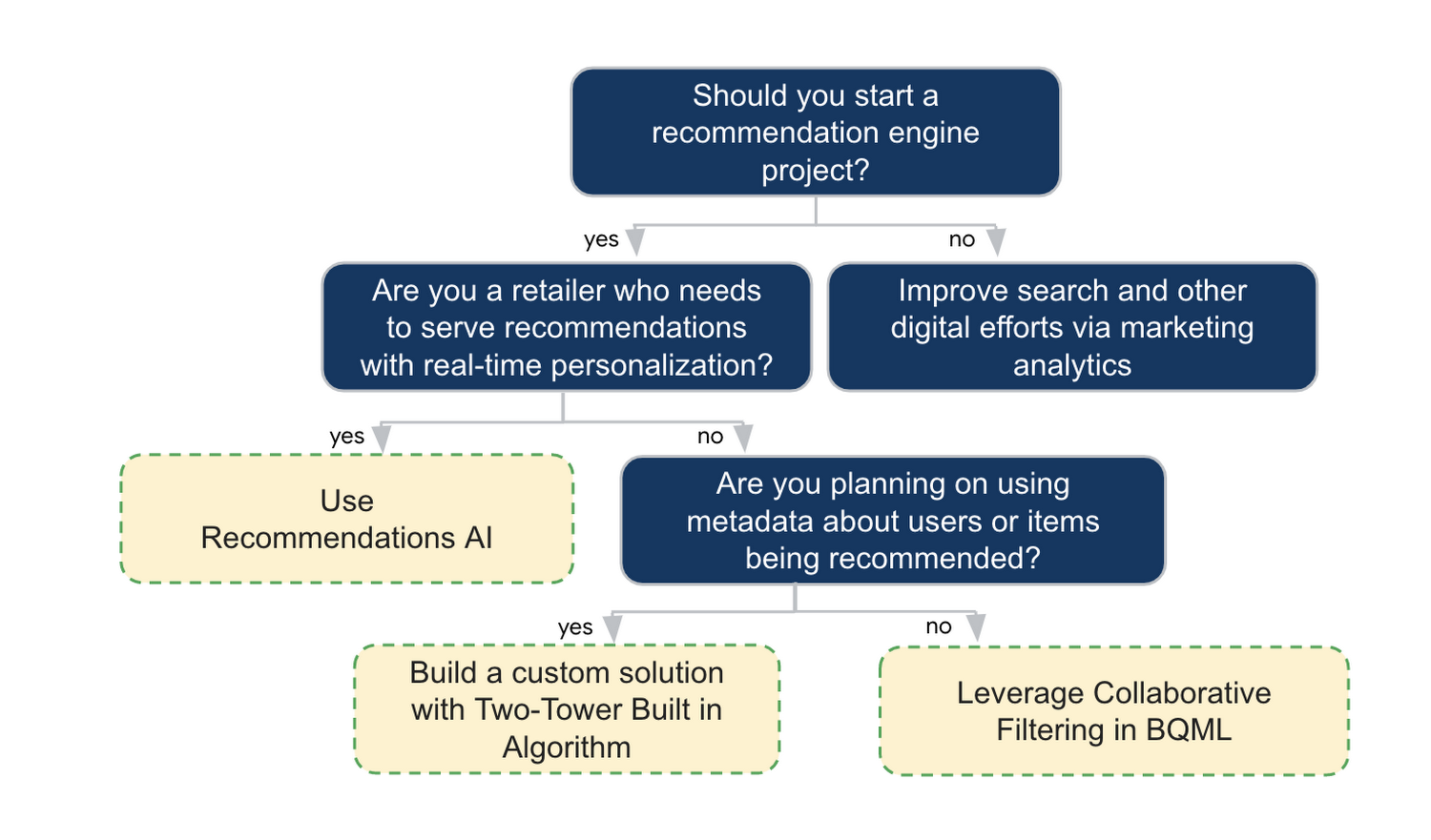
In the next installments of this series, we will dive more deeply into each method, explore how hardware accelerators can play a key role in recommendation system design, and discuss how recommendation systems may be leveraged in key verticals. Stay tuned for future posts in our recommendation systems series. Thank you for reading! Have a question or want to chat? Find authors here - R.E. [Twitter | LinkedIn], Jordan [LinkedIn], and Vaibhav [LinkedIn].
Acknowledgements
Special thanks to Pallav Mehta, Henry Tappen,Abhinav Khushraj, and Nicholas Edelman for helping to review this post.




