Google Cloud の AI と RDMA over Converged Ethernet ネットワーキング
Ammett Williams
Developer Relations Engineer
※この投稿は米国時間 2025 年 3 月 20 日に、Google Cloud blog に投稿されたものの抄訳です。
すべてのワークロードは、同じではありません。これは、AI、ML、科学の分野のワークロードの場合に特に当てはまります。このブログ投稿では、Google Cloud の高パフォーマンス ワークロードに RDMA over Converged Ethernet バージョン 2(RoCE v2)プロトコルを利用できる仕組みについて説明します。
従来のワークロード
従来のワークロードにおけるネットワーク通信には、よく知られたフローがあります。以下に例を示します。
-
送信元と宛先の間でのデータの移動。アプリケーションがリクエストを開始します。
-
OS がデータを処理し、TCP ヘッダーを追加して、ネットワーク インターフェース カード(NIC)に渡します。
-
NIC は、ネットワーク情報とルーティング情報に基づいてデータをネットワーク上に送信します。
-
受信 NIC がデータを受信します。
-
受信側の OS 処理では、ヘッダーが削除され、情報に基づいてデータが配信されます。
このプロセスには CPU と OS の処理の両方が含まれ、これらのネットワークは、正常に機能しながらレイテンシやパケットロスの問題から回復し、さまざまなサイズのデータを処理できます。
AI ワークロード
AI ワークロードは非常に機密性が高く、大規模なデータセットを伴ううえに、トレーニングと推論には高帯域幅、低レイテンシ、ロスレス通信が必要になる場合があります。このようなジョブの実行には通常よりも費用がかかるため、処理を最適化してできるだけ迅速に完了することが重要です。これは、AI アプリケーションのトレーニングと実行を大幅に高速化するように設計された専用ハードウェアである、アクセラレータを使用することで実現できます。アクセラレータの例としては、TPU や GPU などの特殊なハードウェア チップが挙げられます。
RDMA
リモート ダイレクト メモリ アクセス(RDMA)テクノロジーを利用すると、OS、ネットワーキング スタック、CPU を介さずにシステム間で直接データを交換できます。これにより、ボトルネックになり得る CPU をバイパスでき、処理時間が短縮されます。
GPU でこのテクノロジーがどのように機能するかを見てみましょう。
-
RDMA 対応アプリケーションが RDMA オペレーションを開始します。
-
カーネル バイパスにより、データは OS と CPU をバイパスします。
-
RDMA 対応のネットワーク ハードウェアが送信元 GPU メモリにアクセスしてデータを宛先 GPU メモリに転送します。
-
受信側では、アプリケーションが GPU メモリから情報を取得し、受け取りの確認として送信者に通知を送信します。
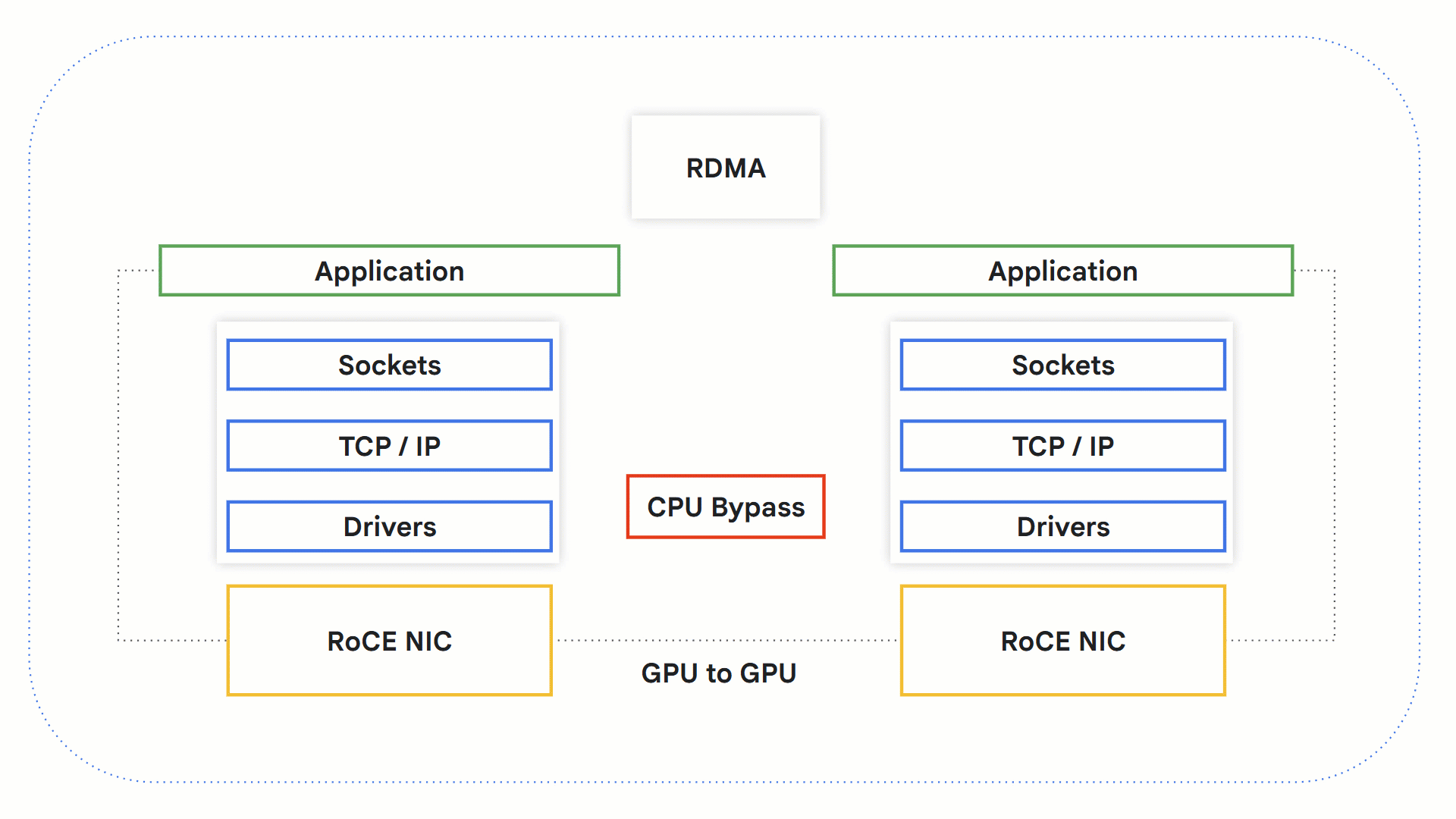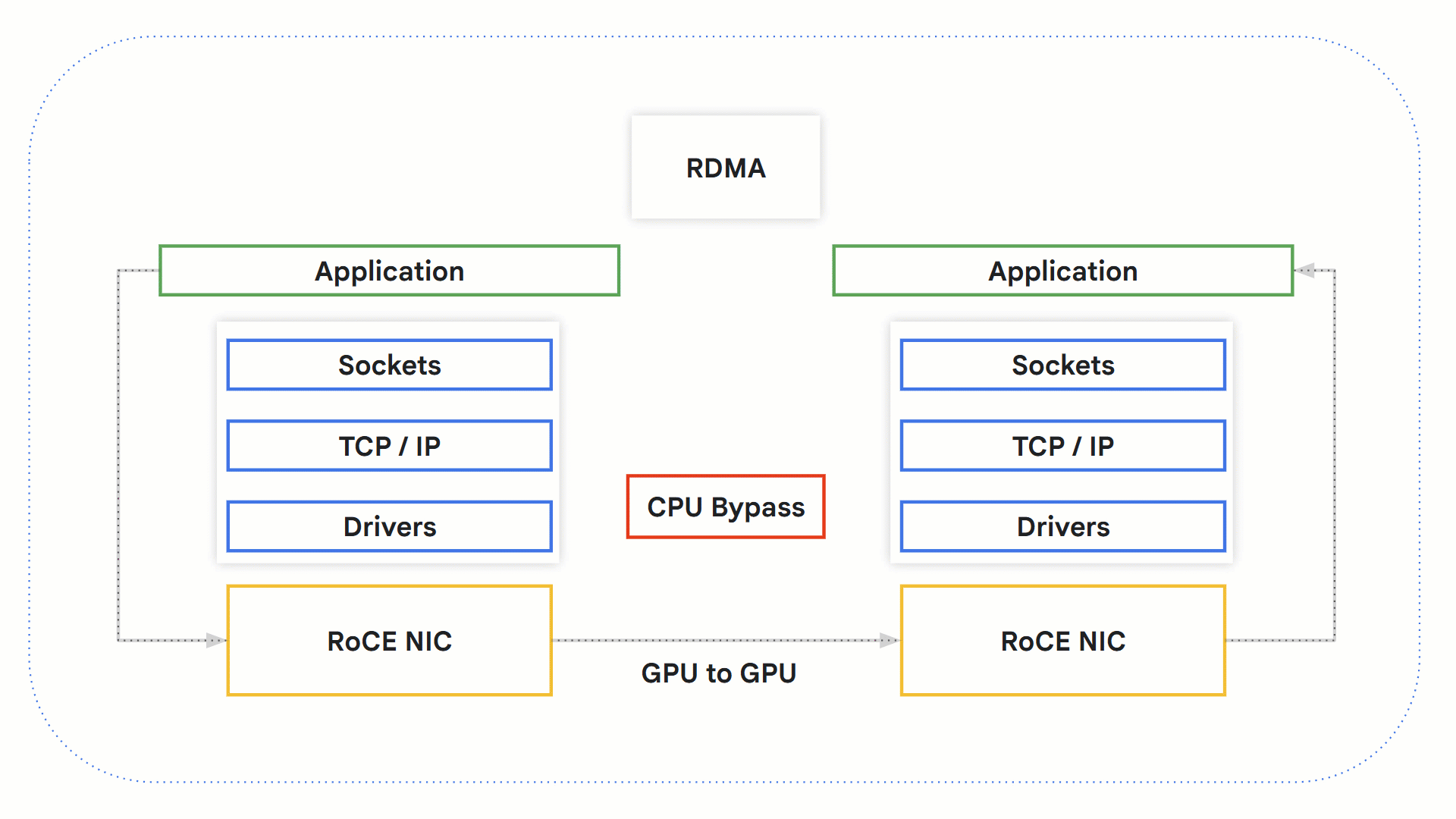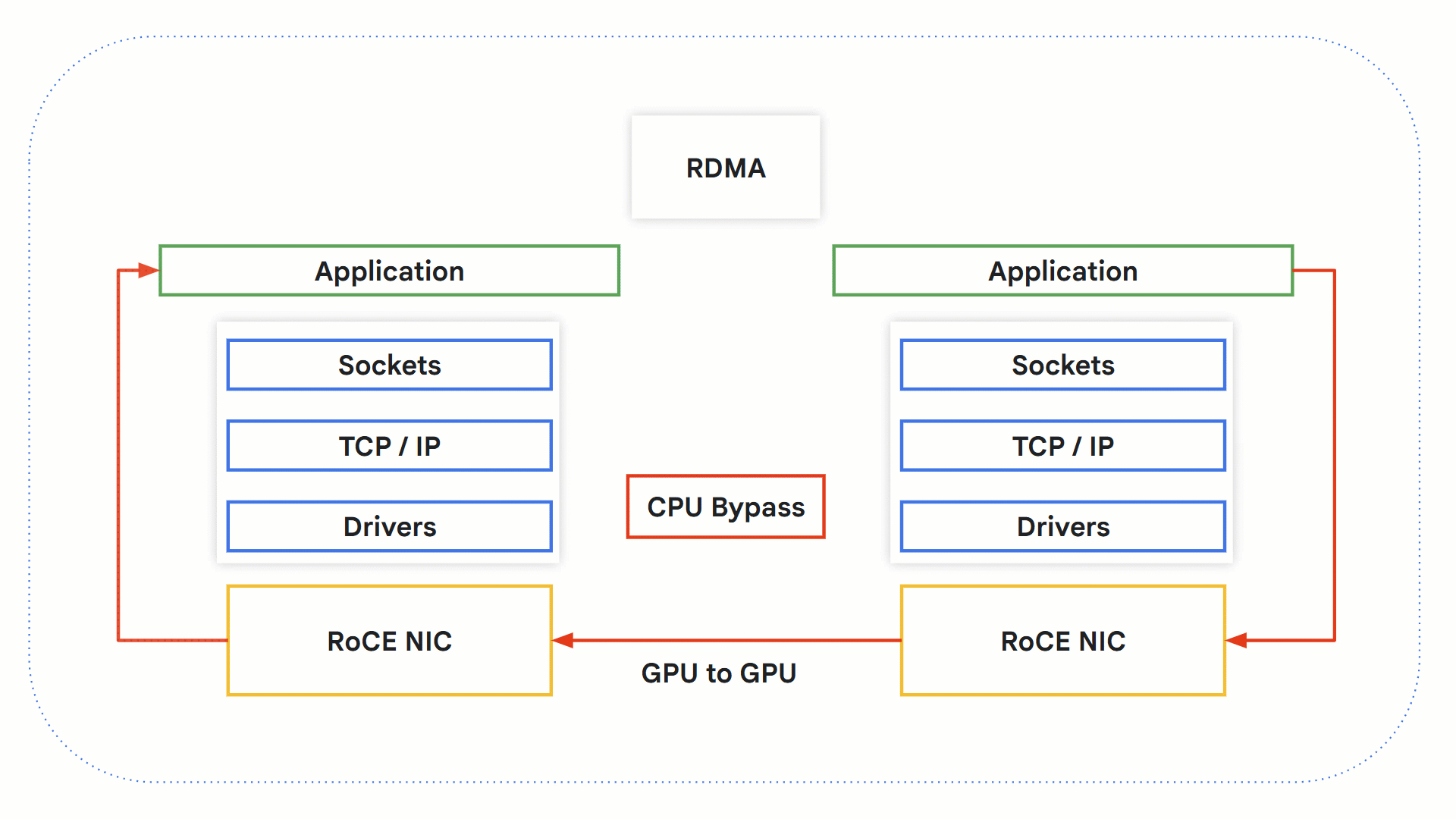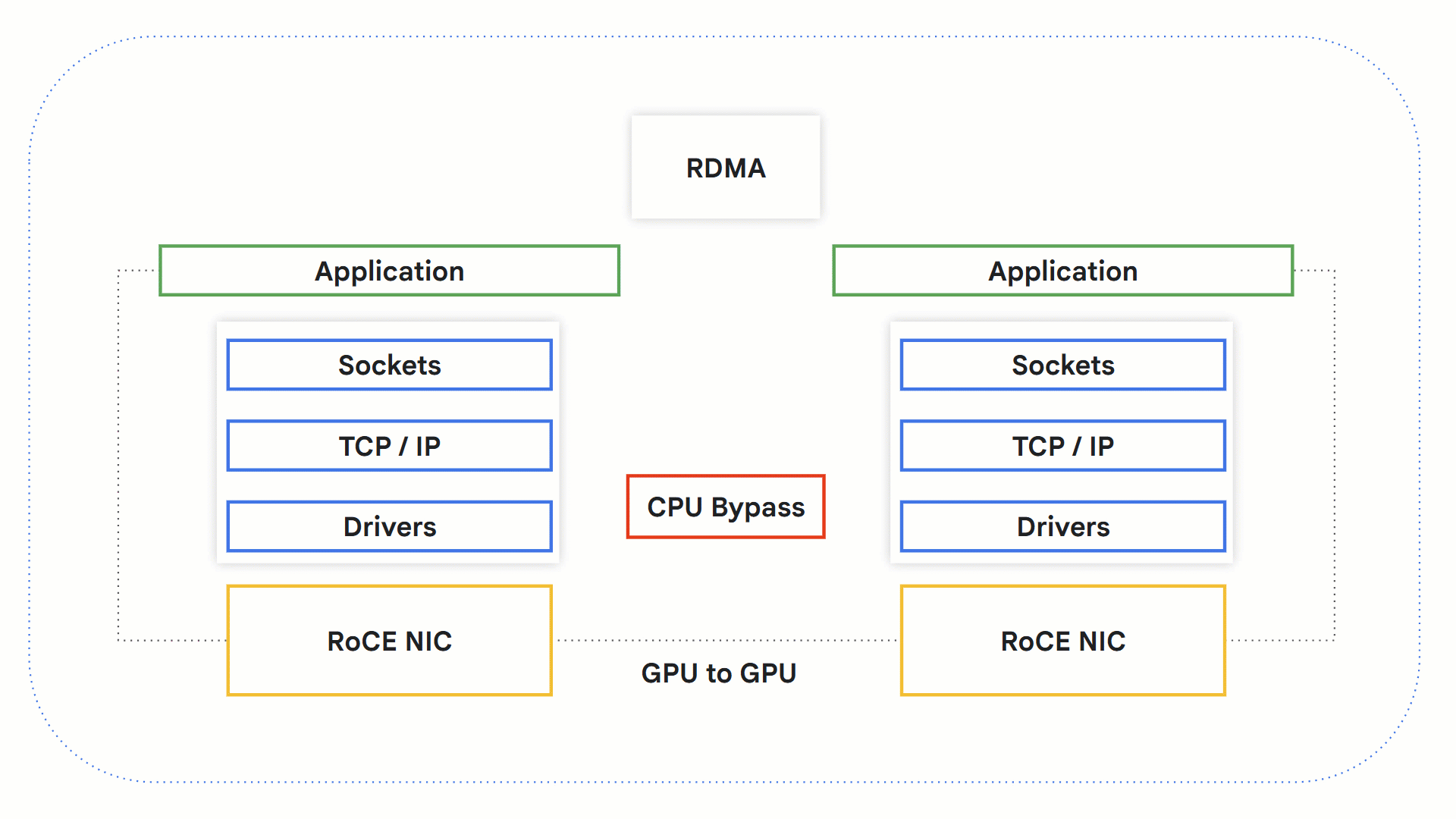
RoCE を使用した RDMA の仕組み
以前は、Google Cloud は GPUDirect-TCPX と GPUDirect-TCPXO という独自のネイティブ ネットワーキング スタックを使用して RDMA のような機能をサポートしていました。現在、この機能はイーサネット経由で RDMA を実装する RoCEv2 によって拡張されています。
RoCE v2 対応のコンピューティング
A3 Ultra と A4 の両 Compute Engine マシンタイプは、ハイ パフォーマンス ネットワーキングに RoCE v2 を活用しています。各ノードは、分離された RDMA ネットワークに接続された 8 個の RDMA 対応 NIC をサポートします。ノード内の GPU 間の直接通信は NVLink を介して行われ、ノード間の直接通信は RoCE を介して行われます。
RoCEv2 ネットワーキング機能を採用することで、次のようなメリットが得られます。
-
低レイテンシ
-
帯域幅の拡張 - ノード間および GPU 間のトラフィックの帯域幅を 1.6 Tbps から 3.2 Tbps に拡張
-
輻輳制御機能によるロスレス通信: 優先度ベースのフロー制御(PFC)と明示的輻輳通知(ECN)
-
UDP ポート 4791 の使用
-
A3 Ultras、A4 などの新しい VM シリーズのサポート
-
大規模クラスタ デプロイ向けのスケーラビリティのサポート
-
最適化されたレール設計ネットワーク
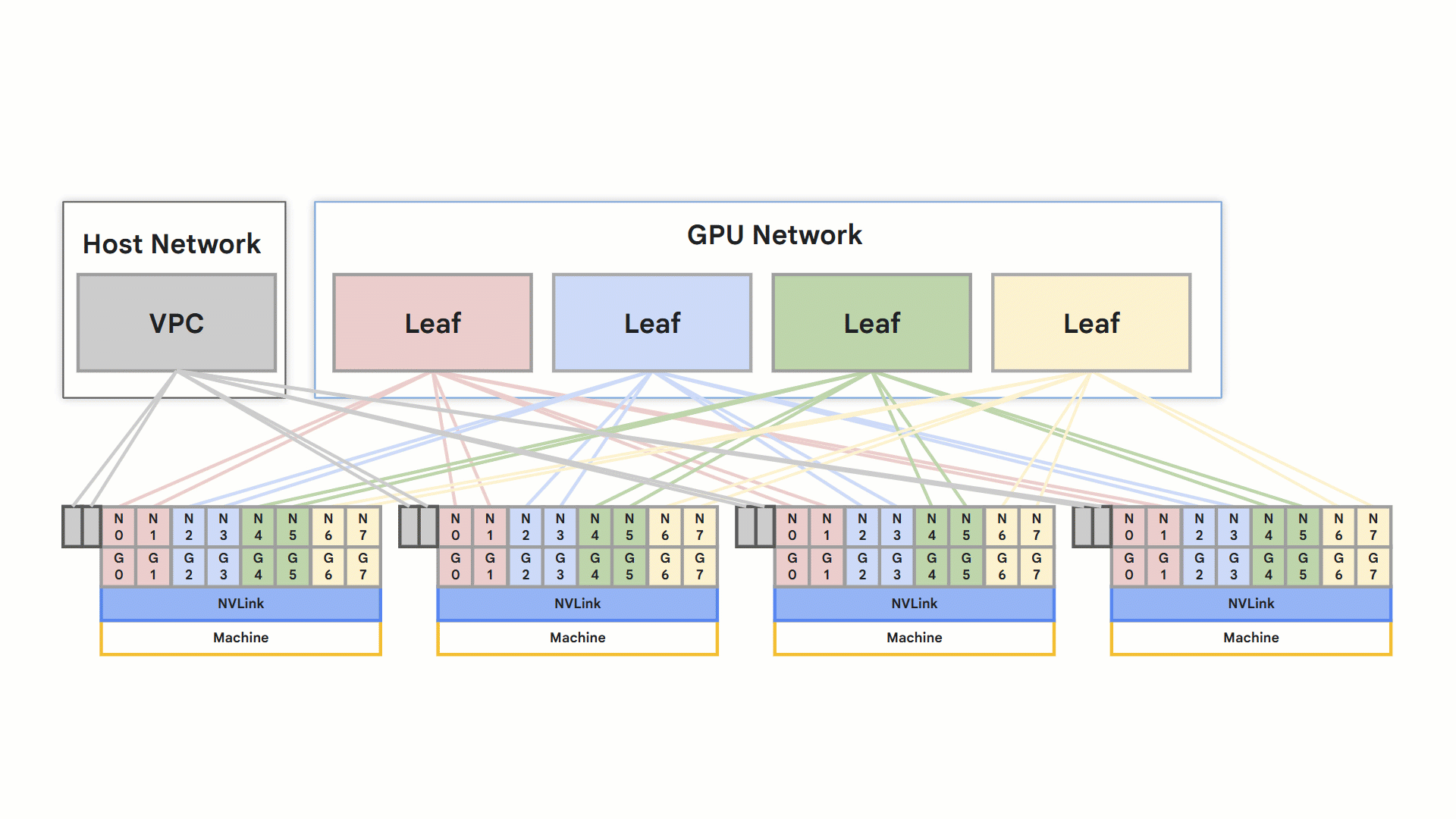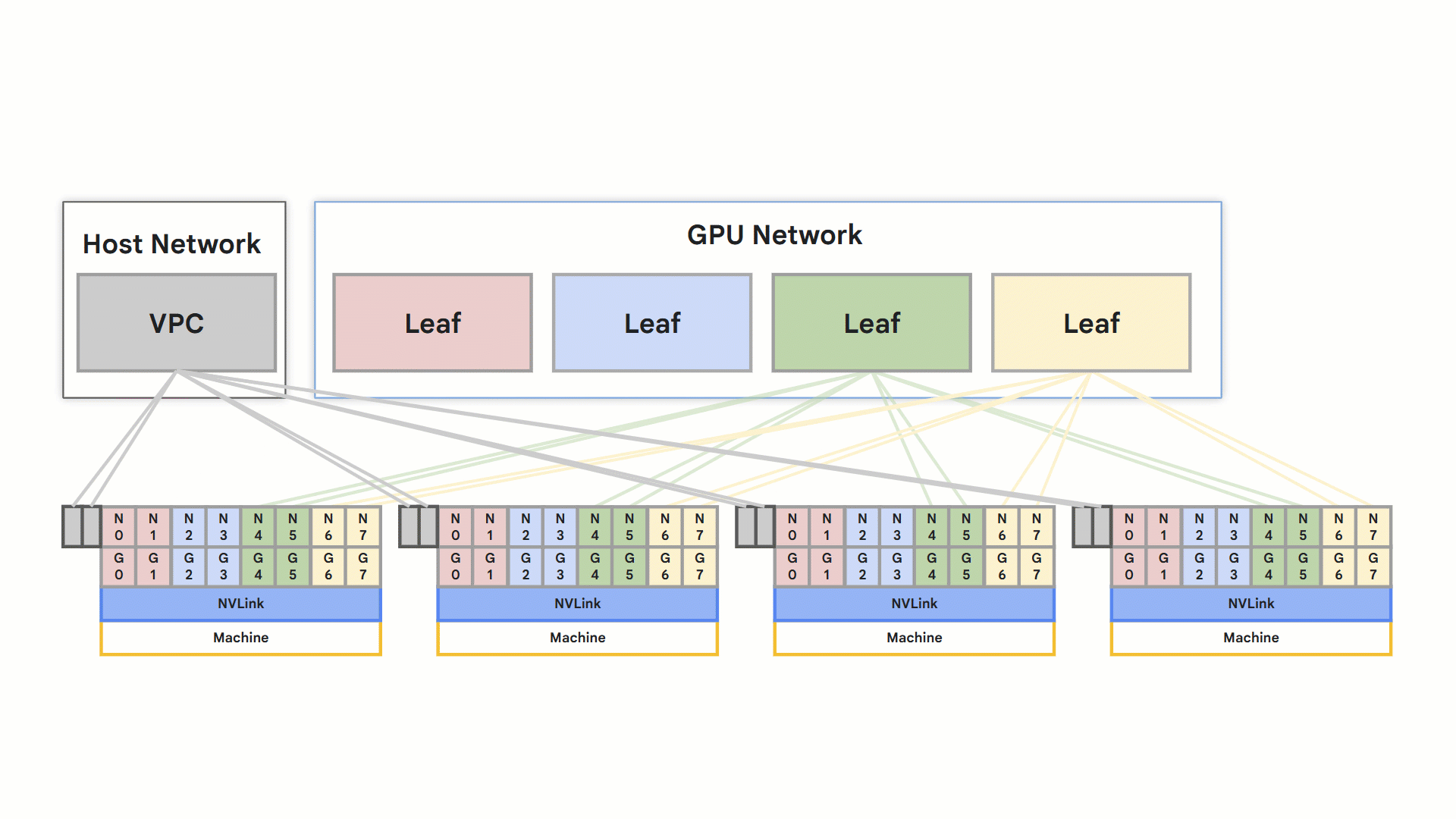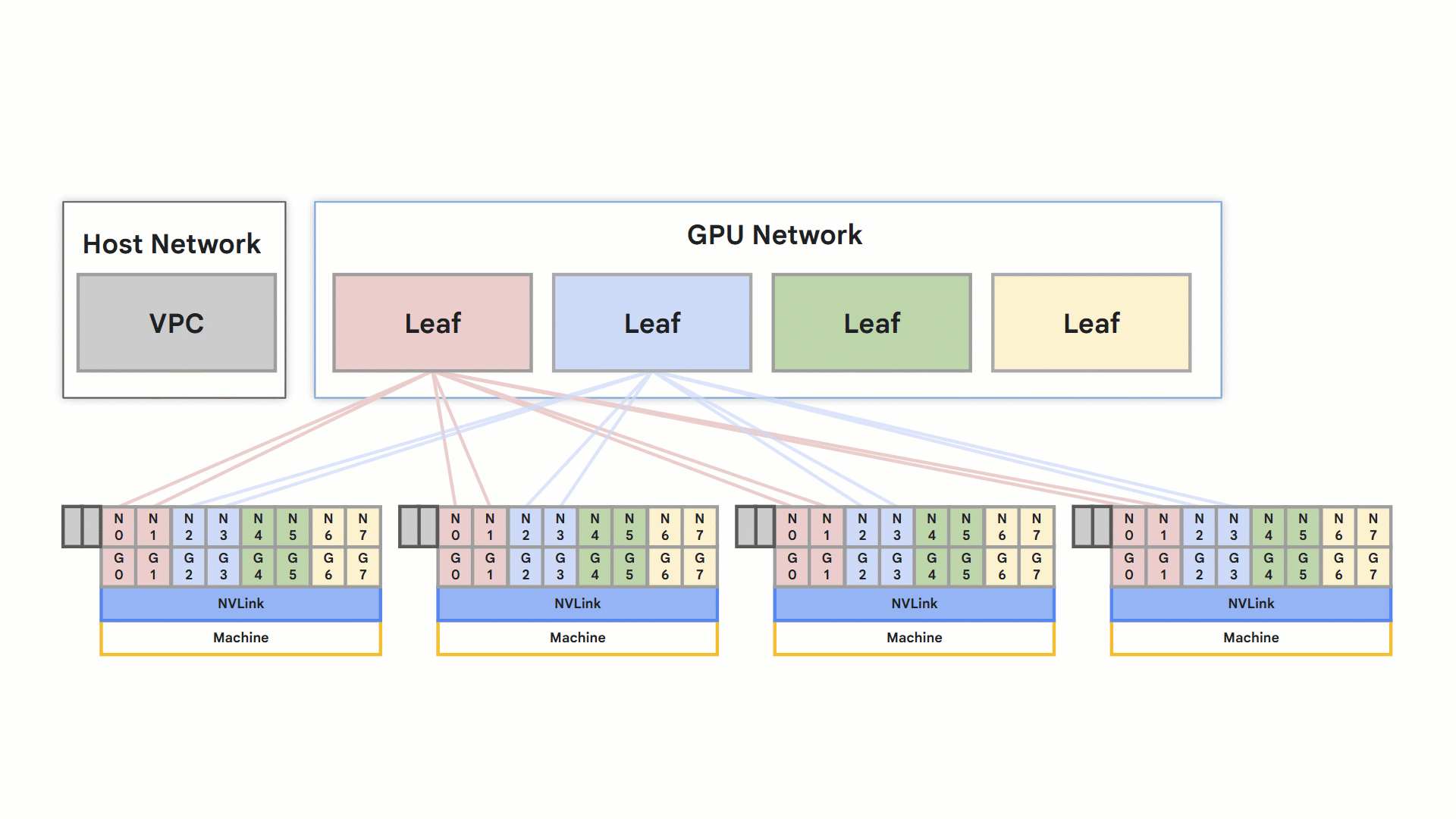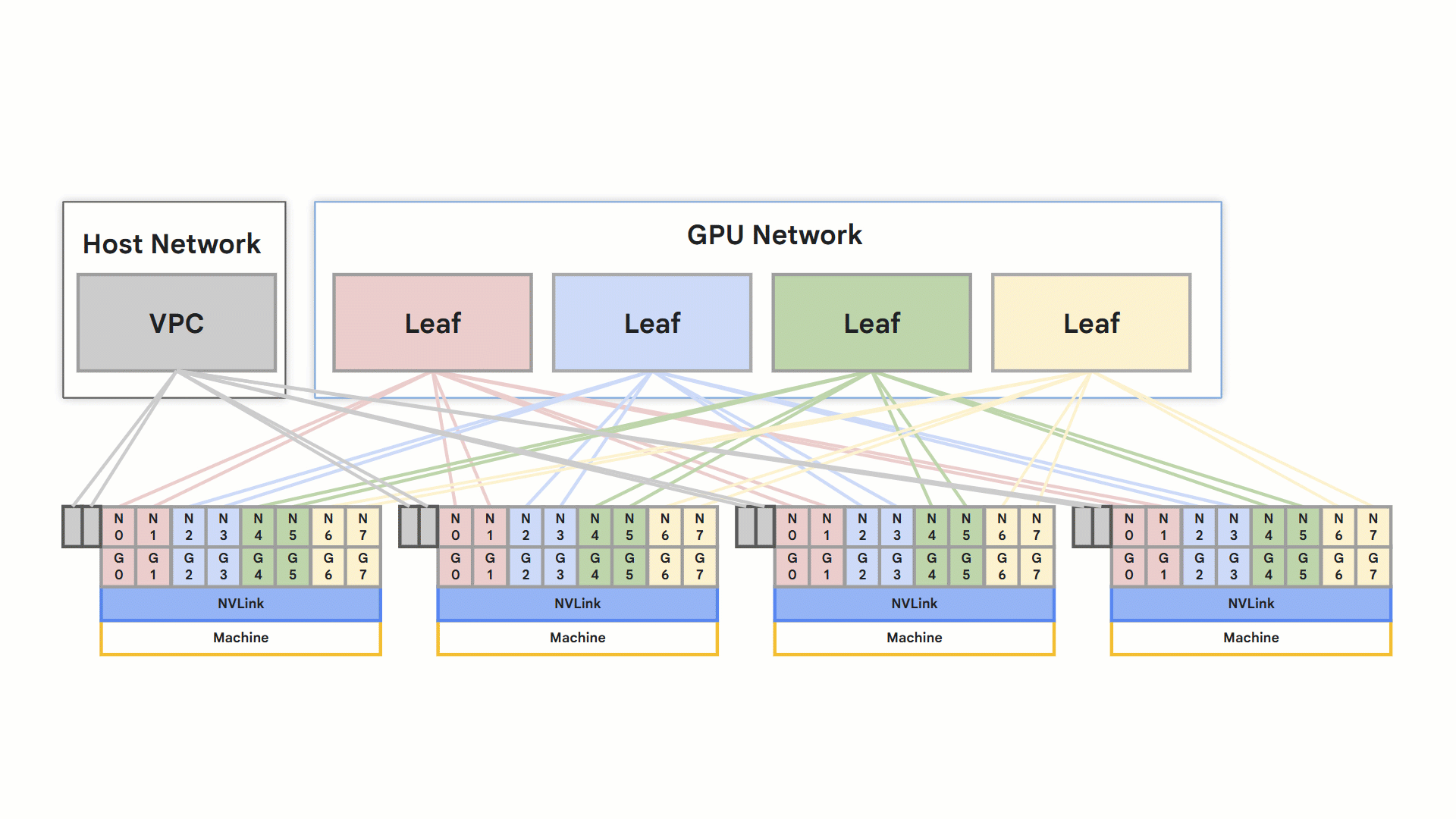
rail design
全体として、これらの機能によりトレーニングと推論の速度が向上し、アプリケーションの速度が直接的に向上します。こういった成果は、そのために最適化された専用の VPC ネットワークによって実現しています。この高パフォーマンスの接続性は、要求の厳しいアプリケーションにとって重要な差別化要因となります。
使ってみる
これらの機能は、次の手順に沿って有効化できます。
-
予約を作成: 予約 ID を取得します。サポートチームに連絡して容量をリクエストすることが必要になる場合があります。
-
デプロイ戦略を選択: デプロイするリージョン、ゾーン、ネットワーク プロファイル、予約 ID、デプロイ方法を指定します。
-
デプロイを作成します。
構成手順などについては、次のドキュメントをご覧ください。
-
ドキュメント: Hypercompute Cluster
-
GCT YouTube チャンネル: クラウド開発者向け AI ガイド
ご質問やご意見がございましたら、Linkedin 経由で筆者までご連絡ください。
-デベロッパーリレーションズ エンジニア、Ammett Williams




