ストラグラーの抑制: ストラグラーの自動検出で AI トレーニングのパフォーマンスを最大化
Elias Ahmed
Product Manager
Praveen Kumar
Software Engineer
※この投稿は米国時間 2025 年 8 月 12 日に、Google Cloud blog に投稿されたものの抄訳です。
ストラグラーは、大規模な ML ワークロードに取り組むデベロッパーにとって、業界全体の問題です。これらのシステムが大規模化し、より強力になるほど、単一のコンポーネントのわずかな誤動作によってパフォーマンスが左右されるようになります。次世代の大規模モデルをトレーニングするには、数万個の強力なアクセラレータを相互接続して構築された、新たなレベルのスーパーコンピュータが必要です。
このような分散システムでは、障害は 2 つのタイプに分類されます。1 つ目のフェイルストップ障害は、コンポーネントがクラッシュして無応答になるという、わかりやすい障害です。2 つ目は、はるかに厄介な「フェイル スロー」障害です。ここでは、コンポーネントが動作を停止するのではなく、動作が遅くなるだけです。パフォーマンスが低いノード(「ストラグラー」)は計算を続けますが、その動作の遅さがシステム全体に影響を及ぼし、ハードウェアやソフトウェアの小さな問題が大きなボトルネックとなって、トレーニング時間が大幅に増加します。

このような大規模システムの信頼性を向上させるには、2 つの重要な指標に焦点を当てる必要があります。それは、平均中断間隔(MTBI)を長くすることと、平均復元時間(MTTR)を短くすることです。復旧プロセス自体は 4 つの段階に分けることができます。まず、問題が発生したことを検出します。次に、障害を特定のコンポーネントに特定します。3 つ目は、問題の周辺でシステムを再構成してワークロードを復旧します。最後に、オフラインで根本原因分析を行い、問題の再発を防ぎます。
この投稿では、ストラグラーが発生する原因を探り、Google Cloud でストラグラーを自動検出する方法をご紹介します。
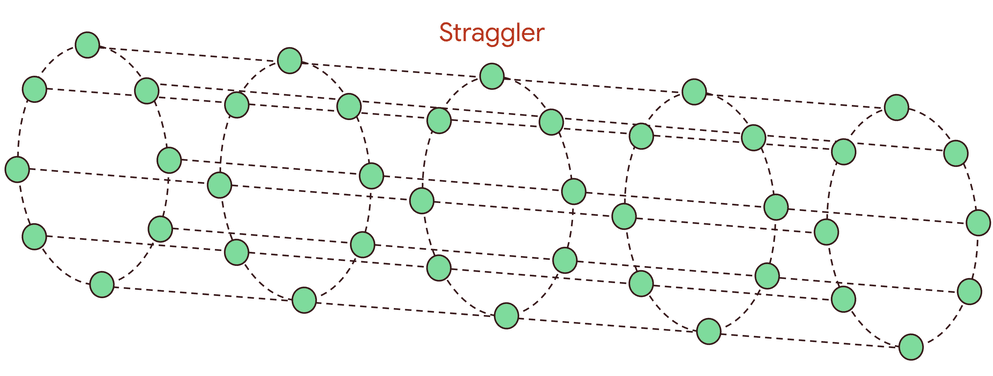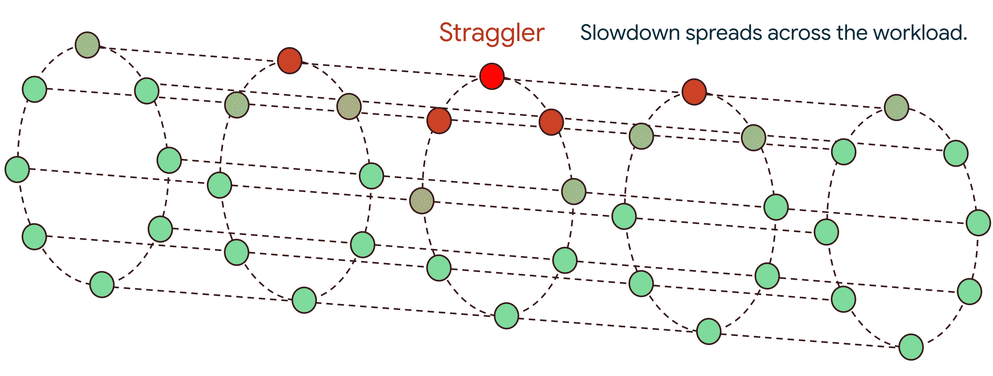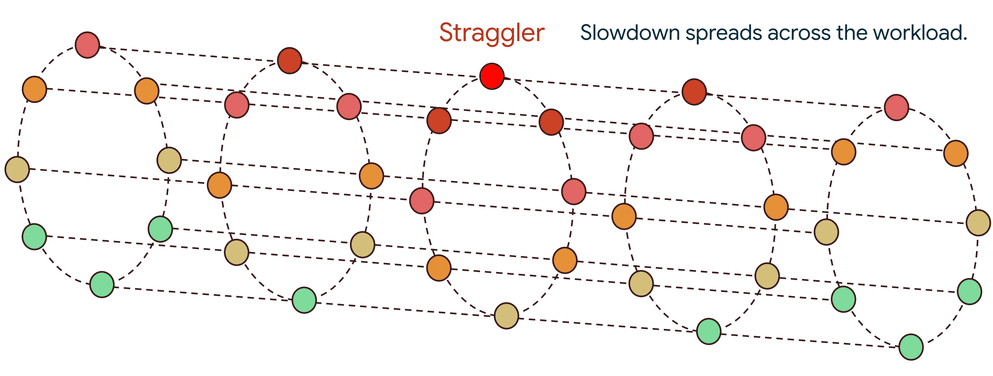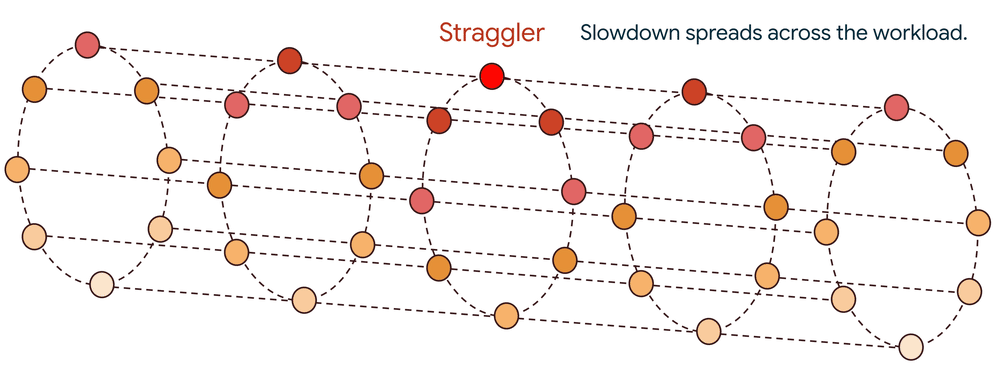
1 つのストラグラーによるドミノ効果
大規模な分散トレーニングは、数千のアクセラレータが足並みをそろえて動作する同期プロセスです。各トレーニング ステップは、ローカル更新(勾配など)を生成する計算フェーズと、これらの更新がすべてのノード間で交換および集約される通信フェーズで構成されます。多くの場合、all-reduce などの集団演算が使用されます。これにより、重要なデータ依存関係が生まれます。すべてのアセレーターがピアから集計された更新を受け取るまで、次のステップを開始できません。

1 つのストラグラーが遅いと、その貢献が遅れ、数千もの正常なアクセラレータがアイドル状態になります。この遅延は一度限りのペナルティではありません。次のステップに伝播し、非効率の繰り返しサイクルが作成され、全体的なパフォーマンスが大幅に低下します。場合によっては、1 つのストラグラーがワークロードのパフォーマンスを 60 ~ 70% 低下させることもあります。このような速度低下は、熱スロットリングされた GPU などのハードウェア障害から、スタックのあらゆる場所にある微妙なソフトウェア バグまで、幅広い問題が原因で発生する可能性があります。
速度低下の原因を特定することは、復旧プロセスのなかでも最も難しい部分です。このタスクの最高水準は、従来、エンジニアが数千のノードにわたって指標を丹念にスキャンしたり、ペアワイズ パフォーマンス ベンチマークなどの的を絞った反復テストを実行してシステムを二分したりする必要がある、苦痛を伴う手動のデバッグ プロセスでした。この面倒な作業には、何時間も、場合によっては何日もかかることがあります。
モニタリングを超えて: ストラグラー検出のための因果分析
従来のモニタリング ツールは、不完全な全体像を示す指標に焦点を当てているため、遅延しているものを特定できないことがよくあります。トレーニング ステップあたりの合計時間などのジョブ全体の指標は、問題の検出には効果的ですが、問題の特定には役立ちません。速度低下が起こっていることは確認できますが、その原因を特定することはできません。GPU 使用率やネットワークのラウンドトリップ時間など、個々のノードに関する低レベルの指標も誤解を招く可能性があります。ノードのネットワーク接続が完全に正常であっても、ソフトウェアのバグによってデータを時間どおりに送信できない場合は、ストラグラーになる可能性があります。
これらの手法は、コンポーネントを個別に分析するため、失敗します。ストラグラー検出に対する Google のアプローチは、因果分析の原則に基づいて構築されており、システムを時間依存の相互作用が相互接続されたグラフとして理解します。これは常時稼働のサービスで、GPU クラスタをパッシブにモニタリングします。お客様が診断を実行するために何かを行う必要はありません。このサービスは主に次の 2 つのステップで動作します。
ステップ 1. 通信グラフの構築: サービスは、ネットワーク トラフィックをパッシブに監視することから始まり、ワークロード内のすべてのノードがどのように通信しているかのリアルタイム マップを構築します。この有向グラフは、情報の流れと、特に、速度低下が伝播する経路を示しています。
ステップ 2. 速度低下の原因を特定: グラフが確立されると、システムは高度なグラフ走査アルゴリズムを使用して、パフォーマンス低下の因果関係を追跡します。このトラバーサルで回答する、核心となる疑問は、ノードがパフォーマンスの低い別のノードを待機しているために遅いのか、それともノード自体が遅延の根本原因なのかということです。
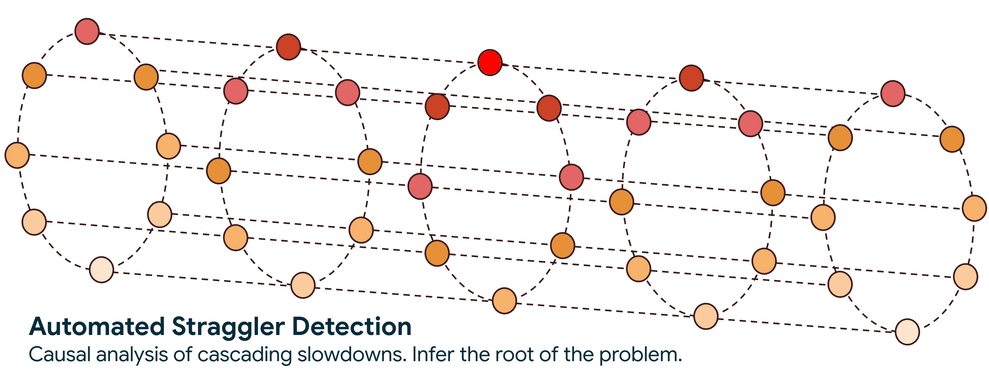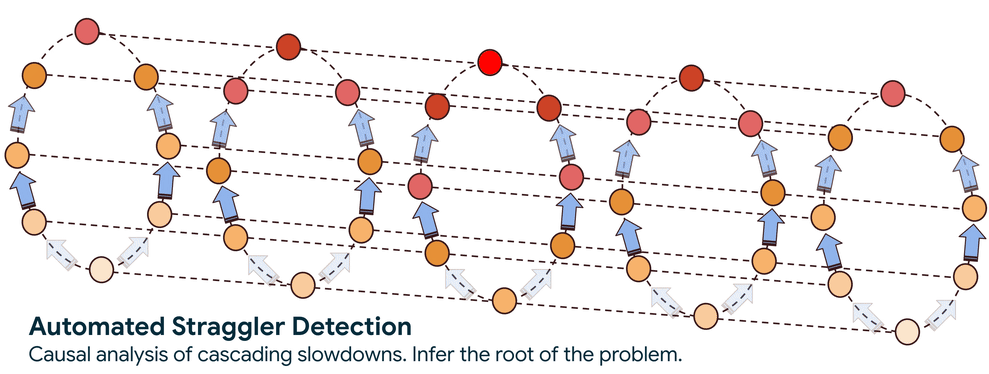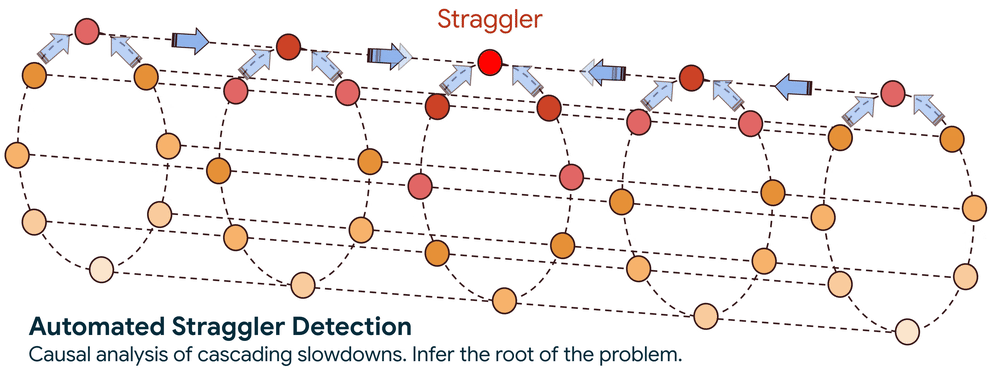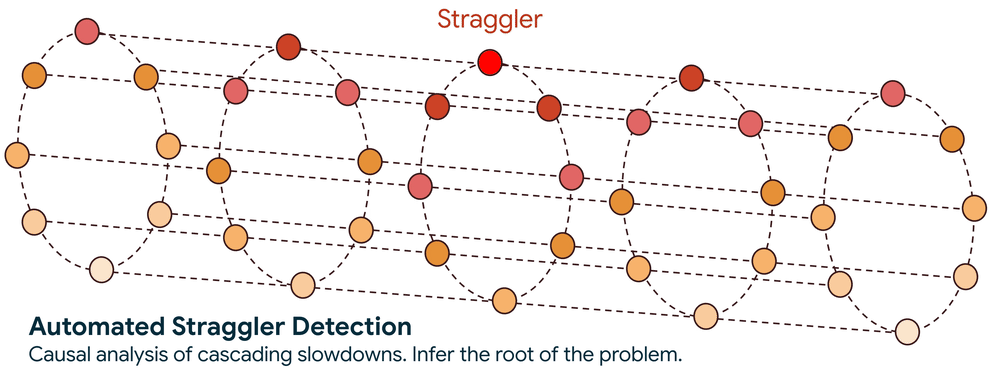
この自動化されたアプローチにより、検索範囲が数千のノードから数個に減り、検索時間が数日から数分に短縮されます。遅延が特定されると、サービスによってフラグが立てられるため、ノードの隔離やワークロードの正常なインフラストラクチャへの再スケジュールなどのアクションを実行できます。
現実世界への影響: AI イノベーションの加速
この自動化されたアプローチは、Google Cloud で最先端モデルをトレーニングする企業にすでに大きな影響を与えています。
そのうちの 1 社が Magic です。同社は Google と提携して、数千の GPU でトレーニングされた 1 億トークンのコンテキスト ウィンドウを備えたフロンティア LLM を開発しました。Google の自動ストラグラー検出アルゴリズムが導入される前は、ストラグラー ノードを特定するプロセスには、手動でのオブザーバビリティとトラブルシューティングが多数必要でした。
Magic の共同創業者兼 CEO である Eric Steinberger 氏は、同社が直面した困難な状況について次のように説明しています。「8,000 個の GPU で実行される Magic の主要なワークロードで、40 時間にわたってパフォーマンスが大幅に低下していました。これをデバッグするには、デバイスとネットワークのパフォーマンスに関する正確な低レベルの統計情報にアクセスする必要がありました。」Eric 氏は、自動化されたサービスによって迅速な解決が実現したと説明します。「Google の自動ストラグラー検出機能でストラグラー ノードを特定でき、問題が解決するまで Google のチームが 24 時間 365 日対応してくれました。現在では、ストラグラー検出がデフォルトで有効になっています。」
Allen Institute for AI(Ai2)は、オープンソースの言語モデルを Google Cloud でトレーニングし、研究の生産性を同様に向上させました。Ai2 の COO である Sophie Lebrecht 氏は、チームが直面した課題を次のように説明しています。「以前は、長いトレーニングの実行中にノードや GPU の障害の正確な原因を特定しようとして、貴重なサイクルを無駄にしていました。」Sophie 氏は、新しい機能によってワークフローがどのように変わったかを説明しました。「GCP でのストラグラー検出は、ML 研究チームの生産性を大幅に向上させました。遅延検出により、開発速度を大幅に向上させることができました。」
自動ストラグラー検出の使用を開始する
自動ストラグラー検出は、Google Cloud の Cluster Director 内で提供される常時稼働サービスです。GPU クラスタをパッシブにモニタリングし、ワークロードを遅くする可能性のあるストラグラーを自動的にフラグ付けします。
パフォーマンスの低下が発生した場合は、ダッシュボードで結果をすばやく確認できます。
-
Google Cloud コンソールの [ダッシュボード] ページに移動します。
-
[Cluster Director Health Monitoring] ダッシュボードを見つけてクリックします。
-
[Straggler Detection] セクションで、[Suspected Straggler Instances] テーブルを確認します。
この表には、速度低下の原因となっている可能性が高いノードが、すぐに対処できるシンプルなリストで表示されます。結果の解釈とトラブルシューティングの手順に関する詳細なガイドについては、パフォーマンスの低下のトラブルシューティングに関するドキュメントをご覧ください。
-プロダクト マネージャー、Elias Ahmed
-ソフトウェア エンジニア、Praveen Kumar

