BigQuery の一般公開境界データセットを活用した地理空間分析
Google Cloud Japan Team
※この投稿は米国時間 2021 年 6 月 22 日に、Google Cloud blog に投稿されたものの抄訳です。
地理空間データは、包括的な分析戦略にとって欠かせない要素です。地理空間パラメータを使用してデータを可視化するにしても、顧客の分布や近接地について詳細な分析やモデリングを行うにしても、たいていの組織はなんらかの地理空間データを使用します。たとえば、お客様の郵便番号、店舗の場所、配送先住所などがそうです。ところが、地理データをさまざまなレベルでの分析、集計のために適切な形式に変換することは、困難な場合があります。この投稿では、Google Cloud Platform を Google Cloud 一般公開データセットと一緒に活用して、地理データに強固な分析を実施する方法をいくつか例を挙げてご紹介します。すべてのクエリは、こちらのノートブックからアクセスできます。
米国の地理的境界の一般公開データセット
BigQuery では、ユーザーがアクセスして独自の分析に統合できる、多くの一般公開データセットがホストされています。Google はこうしたデータセットの保存費用を負担し、bigquery-public-data プロジェクト経由でデータを一般提供しています。料金は、データに対するクエリにのみ発生します。さらに、毎月 1 TB までは無料です。一般公開データセットはそれ自体だけでも価値がありますが、ユーザー独自のデータと結合することで、新しい分析のユースケースを活用できるようになり、チームの時間を大幅に節約できます。
Google Cloud 一般公開データセット プログラムには、地理データセットがいくつかあります。以下では、geo_us_boundaries データセットを使用しています。このデータセットには、さまざまな地理空間領域の境界が中心点(BigQuery の GEOGRAPHY 列型)に基づいたポリゴンや座標として格納された、一連のテーブルが含まれています。データは米国国勢調査局によって公開されているものです。
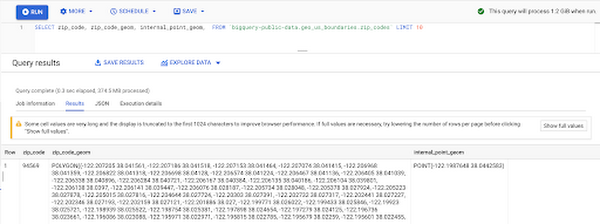
階層エリアへの地理空間ポイントのマッピング
住所を文字列で表している状況に、幾度となく遭遇されるかと思います。しかし、大半のツールは、実際にポイントをプロットするために緯度と経度の座標を必要とします。Google Maps Geocoding API を使用すれば、住所を緯度と経度に変換し、その結果を BigQuery テーブルに保存できます。
ポイントを緯度と経度で示し、ST_WITHIN 関数を使用して、初期データセットを任意のテーブルに結合し直すことができます。これにより、ポイントが指定したポリゴン内にあるかどうかを確認できます。
この方法は、さまざまな名称で呼ばれる可能性がある大都市圏などで、正式名称を徹底するのに便利です。以下のクエリは、それぞれのお客様の住所が特定の大都市圏名にマッピングされます。
また、対象を絞ったデジタル マーケティング キャンペーンの作成によく使用される、指定マーケット エリア(DMA)への変換にも有効です。
あるいは、欠落している情報を入力する場合にも役立ちます。たとえば、郵便番号が欠落している住所があると、郵便番号レベルまで集計する場合に、計算が正しくなくなってしまいます。zip_codes テーブルに結合することで、すべての座標が適切にマッピングされるようになり、そこから集計できます。
この郵便番号テーブルは米国の郵便番号をすべて網羅したリストではなく、郵便番号集計エリア(ZCTA)です。両者の違いについて詳しくは、こちらをご覧ください。また、郵便番号テーブルによって階層情報が得られるため、より有意義な分析を実行できます。一例として、Looker での階層ドリルダウンの活用があります。国レベルまでの総売上高を集計し、都道府県、市、郵便番号にドリルダウンすることで、売上高が最も高い場所を特定できます。BigQuery Geo Viz ツールを使用して地理空間データを可視化することもできます。
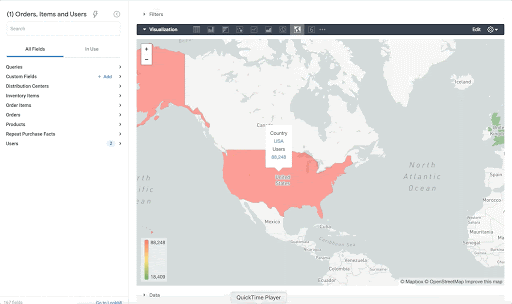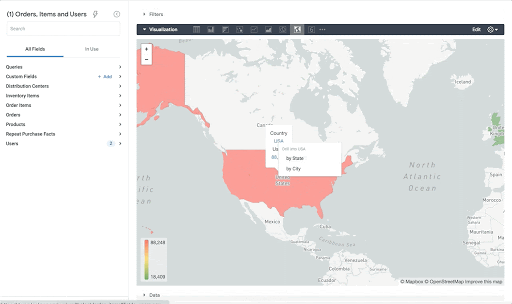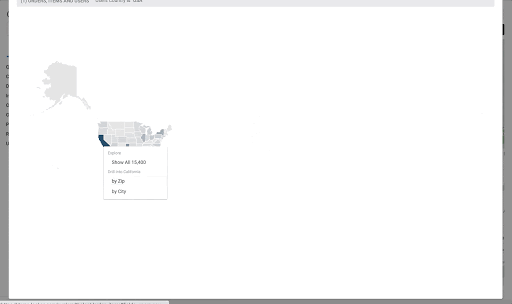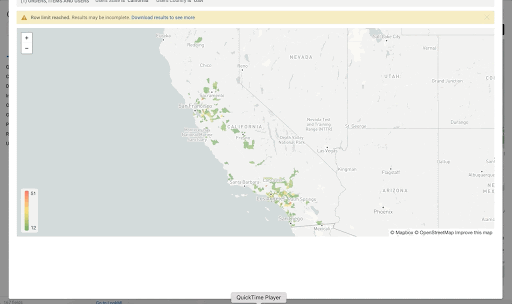
ポイントがエリア内にあるかどうかを確認するだけでなく、ST_DISTANCE を使用することで、大都市圏テーブルの中心点を使用して最も近い都市を見つけるなどの操作を行えます。
この考え方が当てはまるのはポイントだけではありません。他の GIS 関数を利用して、境界データセットにリストされているエリア内に地理空間エリアが含まれているかどうかを確認することもできます。データが GeoJSON 文字列として BigQuery に入力されると、ST_GEOGFROMGEOJSON 関数を使用して GEOGRAPHY 型に変換できます。データが GEOGRAPHY 型になると、ST_WITHIN または ST_INTERSECTS を使用して部分的なカバレッジを考慮し、該当地域がどの都市エリアにあるかを確認するなどの操作を実行できます。以下では、顧客の郵便番号を使用して、郵便番号ポリゴンと大都市ポリゴンが交差する大都市圏をすべて検索しています。次に、レポートに使用するお客様の大都市として、重複が最も多い(交差するエリアが最も広い)大都市圏を選択します。
同じ考えを、郡、都市部、米国国立気象局の予報地域など、データセット内の他のテーブルにも適用できます(これは、データセットを気象データに結合する場合にも役立ちます)。
データの不一致を修正する
地理空間データの使用時に発生する可能性のある問題の一つは、異なる各データソースが同じ情報をそれぞれ別の形で表している可能性があることです。たとえば、1 つのシステムでは州が 2 文字の略語として記録され、もう 1 つのシステムでは完全な名前で記録されているとします。この場合、state テーブルを使用して、それぞれのデータセットを結合できます。
別の例としては、ファジー一致の信頼できるソースとしてテーブルを使用することが挙げられます。アプリケーション内のどこかのフィールドに手動で住所が入力される場合、誤ったスペルで入力される可能性が十分にあります。同じものが別の名前で表現されていると、テーブルが互いに結合できなくなったり、集計時にエントリが重複したりすることになりかねません。以下では、こちらのブログ投稿のヘルパー関数を使用して、簡単な Soundex アルゴリズムで郡名ごとにコードを生成しています。スペルが間違っていても、同じ Soundex コードが使用されていることがわかります。
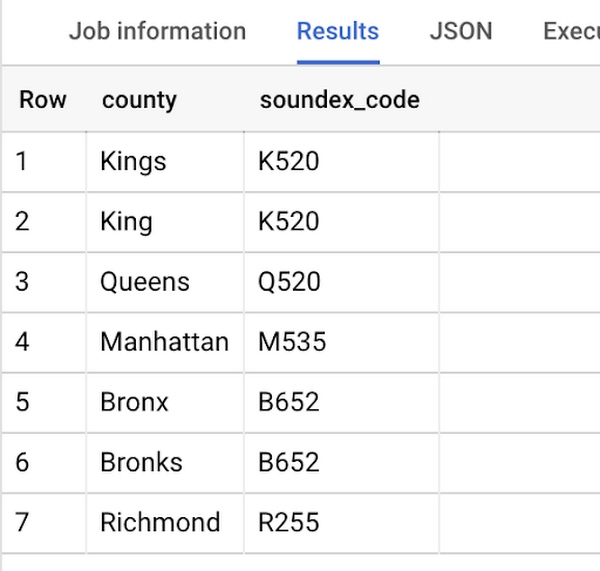
次に、郡テーブルに結合し直して、郡名の正しいスペルが使用されていることを確認します。そして、データを単純に集計して、より正確なレポートを作成できます。
ファジー一致は決して完全ではありません。データの詳細に応じて、さまざまな方法をお試しになるか、特定のフィルタを適用して最適に機能させる必要があることがあります。
米国の地理的境界データセットを使用すると、有意義な分析を地域ごとに実施でき、追加のデータセットを抽出、変換したり、BigQuery に読み込んだりする心配もいりません。これらのデータセットは、他のすべての Google Cloud 一般公開データセットとともに、Analytics Hub で利用可能になる予定です。2021 年第 3 四半期にリリース予定の Analytics Hub のプレビュー版にぜひご登録ください。ご登録は g.co/cloud/analytics-hub から行えます。
-デベロッパー アドボケイト Leigha Jarett




