Leveraging BigQuery Public Boundaries datasets for geospatial analytics
Leigha Jarett
Developer Advocate, Looker at Google Cloud
Geospatial data is a critical component for a comprehensive analytics strategy. Whether you are trying to visualize data using geospatial parameters or do deeper analysis or modeling on customer distribution or proximity, most organizations have some type of geospatial data they would like to use - whether it be customer zipcodes, store locations, or shipping addresses. However, converting geographic data into the correct format for analysis and aggregation at different levels can be difficult. In this post, we’ll walk through some examples of how you can leverage the Google Cloud platform alongside Google Cloud Public Datasets to perform robust analytics on geographic data. The full queries can be accessed from this notebook here.
Public US Geo Boundaries dataset
BigQuery hosts a slew of public datasets for you to access and integrate into your analytics. Google pays for the storage of these datasets and provides public access to the data via the bigquery-public-data project. You only pay for queries against the data. Plus, the first 1 TB per month is free! These public datasets are valuable on their own, but when joined against your own data they can unlock new analytics use cases and save the team a lot of time.
Within the Google Cloud Public Datasets Program there are several geographic datasets. Here, we’ll work with the geo_us_boundaries dataset, which contains a set of tables that have the boundaries of different geospatial areas as polygons and coordinates based on the center point (GEOGRAPHY column type in BigQuery), published by the US Census Bureau.
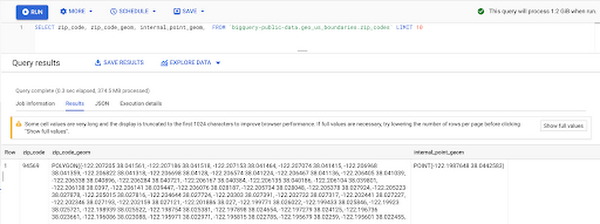
Mapping geospatial points to hierarchical areas
Many times you will find yourself in situations where you have a string representing an address. However, most tools require lat/long coordinates to actually plot points. Using the Google Maps Geocoding API we can convert an address into a lat/long and then store the results in the BigQuery table.
With a lat/long representation of our point, we can join our initial dataset back onto any of the tables here using the ST_WITHIN function. This allows us to check and see if a point is within the specified polygon.
ST_WITHIN(geography_1, geography_2)
This can be helpful for ensuring standard nomenclature; for example, metropolitan areas that might be named differently. The query below maps each customers’ address to a given metropolitan area name.
It can also be useful for converting to designated market area (DMA), which is often used in creating targeted digital marketing campaigns.
Or for filling in missing information; for example, some addresses may be missing zip code which results in incorrect calculations when aggregating up to the zipcode level. By joining onto the zip_codes table we can ensure all coordinates are mapped appropriately and aggregate up from there.
Note that the zip code table isn’t a comprehensive list of all US zip codes, they are zip code tabulation areas (ZCTAs). Details about the differences can be found here. Additionally, the zip code table gives us hierarchical information, which allows us to perform more meaningful analytics. One example is leveraging hierarchical drilling in Looker. I can aggregate my total sales up to the country level, and then drill down to state, city and zipcode to identify where sales are highest. You can also use the BigQuery GeoViz tool to visualize geospatial data!
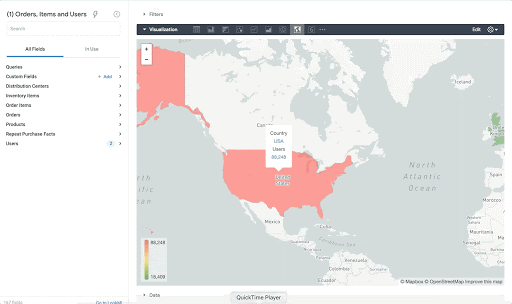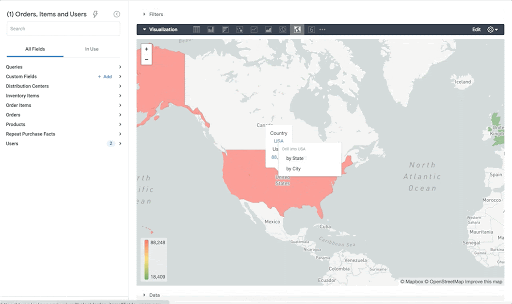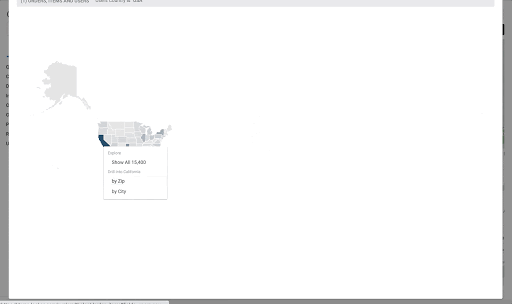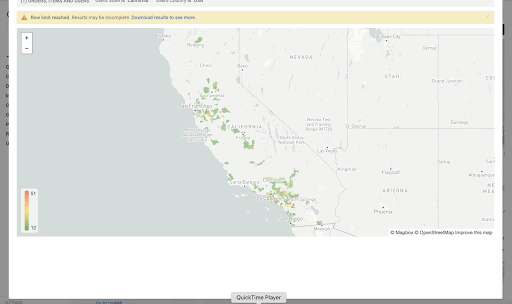
Aside from simply checking if a point is within an area, we can also use ST_DISTANCE to do something like find the closest city using the centerpoint for the metropolitan area table.
This concept doesn’t just hold true for points, we can also leverage other GIS functions to see if a geospatial area is contained within areas that are listed in the boundaries datasets. If your data comes into BigQuery as a GeoJSON string, we can convert it to a GEOGRAPHY type using the ST_GEOGFROMGEOJSON function. Once our data is in a GEOGRAPHY type we can do things like check to see what urban area the geo is within - using either ST_WITHIN or ST_INTERSECTS to account for partial coverage. Here, I am using the customer's zip code to find all metropolitan divisions where the zip code polygon and the metropolitan polygon intersect. I am then selecting the metropolitan area that has the most overlap (or the intersection has the largest area) to be the customer’s metro that we use for reporting.
The same ideas can be applied to the other tables in the dataset including the county, urban areas and National Weather Service forecast regions (which can also be useful if you want to join your datasets onto weather data).
Correcting for data discrepancy
One problem that we may run into when working with geospatial data is that different data sources may have different representations of the same information. For example, you might have one system that records state as a two letter abbreviation and another using the full name. Here, we can use the state table to join the different datasets.
Another example might be using the tables as a source of truth for fuzzy matching. If the address is a manually entered field somewhere in your application, there is a good chance that things will be misspelled. Different representations of the same name may prevent tables from joining with each other or lead to duplicate entries when performing aggregations. Here, I use a simple Soundex algorithm to generate a code for each county name, using helper functions from this blog post. We can see that even though some are misspelled they have the same Soundex code.
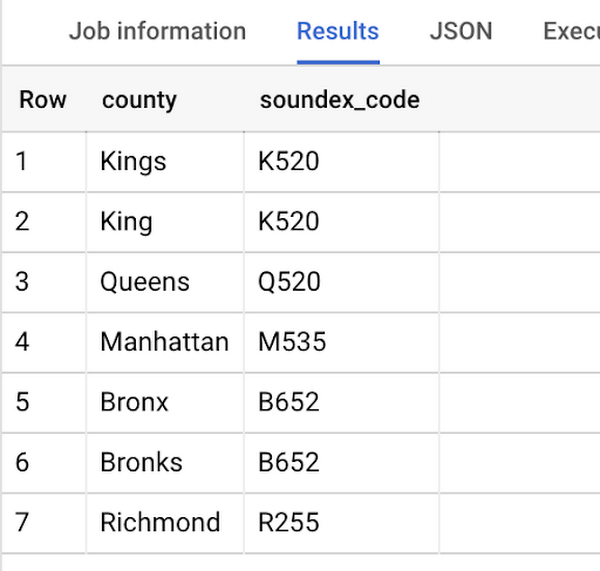
Next, we can join back onto our counties table so we make sure to use the correct spelling of the county name. Then, we can simply aggregate our data for more accurate reporting.
Note that fuzzy matching definitely isn’t perfect and you might need to try different methods or apply certain filters for it to work best depending on the specifics of your data.
The US Geo Boundary datasets allow you to perform meaningful geographic analysis without needing to worry about extracting, transforming or loading additional datasets into BigQuery. These datasets, along with all the other Google Cloud Public Datasets, will be available in the Analytics Hub. Please sign up for the Analytics Hub preview, which is scheduled to be available in the third quarter of 2021, by going to g.co/cloud/analytics-hub.