Data Fusion でデータサイロを統合
Google Cloud Japan Team
※この投稿は米国時間 2021 年 7 月 24 日に、Google Cloud blog に投稿されたものの抄訳です。
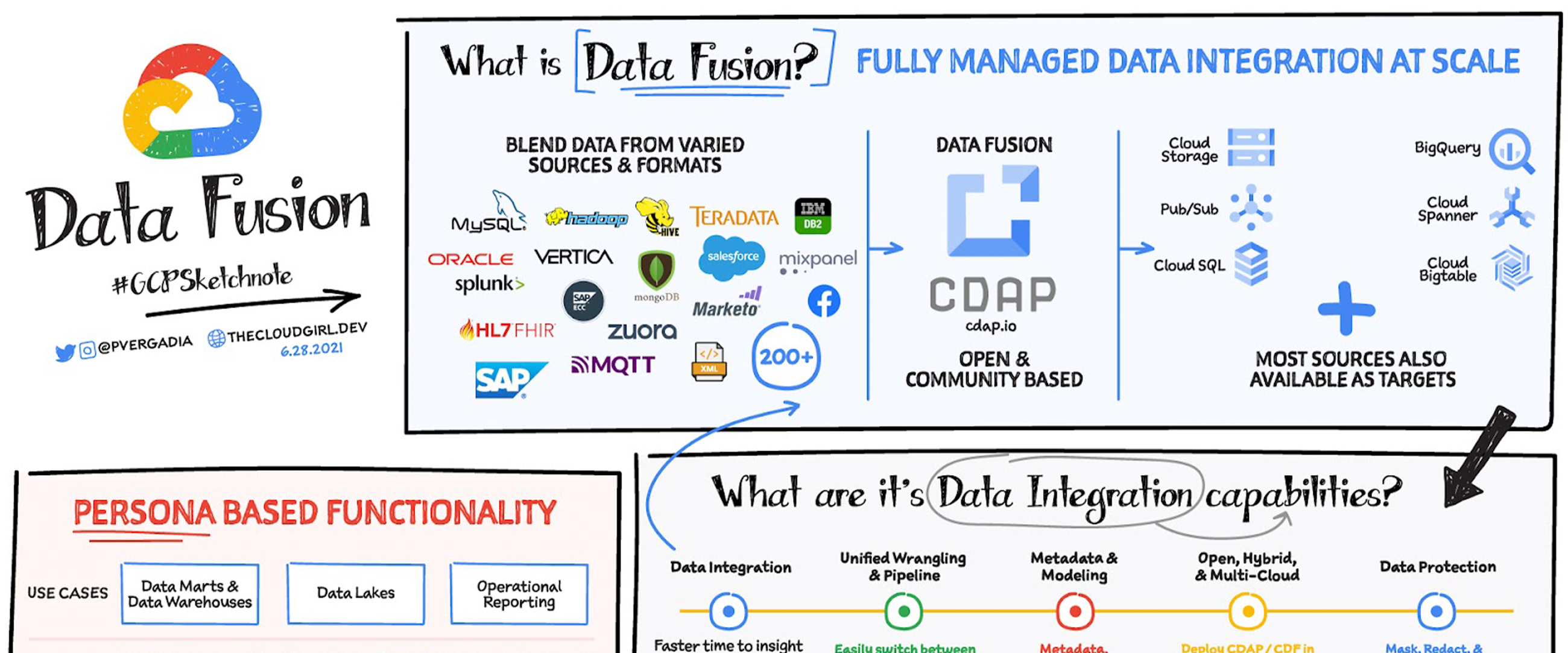
データ分析の大きな課題は、データがあちらこちらに散在していて、形式もさまざまであることです。その結果、データから分析情報を得るには、たいていは数多くの統合アクティビティがまず必要になります。Data Fusion は、取り込み、ETL、ELT、ストリーミングを含むあらゆるエンタープライズ データ統合アクティビティを一元管理でき、SLA と費用に対して最適化された実行エンジンを提供します。また、Google Cloud、ハイブリッド クラウド環境、マルチクラウド環境を使用する ETL デベロッパー、データ アナリスト、データ エンジニアの負担を軽減するように設計されています。
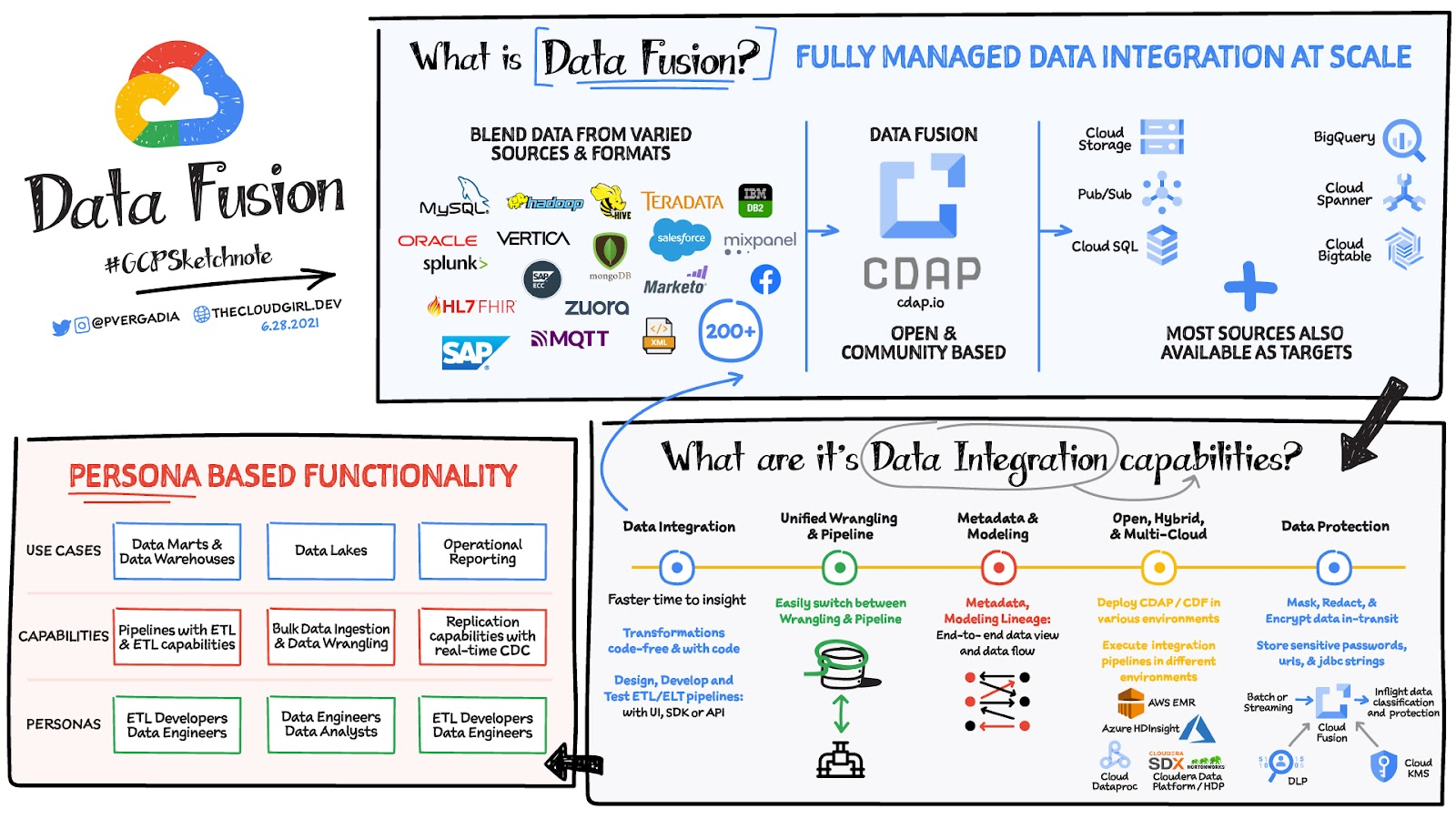
Data Fusion は、Google のクラウド ネイティブでスケーラブルなフルマネージド エンタープライズ データ統合プラットフォームです。データベース、アプリケーション、メッセージング システム、メインフレーム、ファイル、SaaS、IoT デバイスからさまざまな形式のトランザクション、ソーシャル、マシンのデータを取り込むことができます。また、使いやすいビジュアル インターフェースを備え、Spark 内のエフェメラルまたは専用の Dataproc クラスタでデータ パイプラインを実行するデプロイ機能を提供します。Cloud Data Fusion はオープンソースの CDAP を利用しているため、Google Cloud、ハイブリッド クラウド、マルチクラウド環境間でパイプラインを移植できます。
データ統合機能
分析を最適化しデータ変換を高速化するデータ統合
Data Fusion は 200 を超える幅広いコネクタと形式をサポートするため、データの抽出やブレンドが可能です。視覚的にデータ パイプラインを開発し、生産性の向上を図ることができます。
Data Fusion にはデータを準備するためのデータ ラングリング機能があり、データ ラングリングを運用化する機能でビジネス IT コラボレーションを改善できます。
豊富な REST API を活用して、パイプラインのライフサイクルを設計、自動化、オーケストレーション、管理できます。
Data Fusion はバッチ、ストリーミング、リアルタイムを含むすべてのデータ配信モードがサポートされているため、バッチとストリーミングの両方に関連したユースケースに対応する包括的なプラットフォームになっています。
データ統合プロセスをモニタリングできるように、運用に関する分析情報が提供されます。SLA を管理し、統合ジョブの最適化と微調整をすることが可能です。
Data Fusion は Cloud AI を使用して非構造化データを解析し拡充する各種機能を提供します。たとえば、音声ファイルのテキスト変換、NLP を適用した感情の検出、画像やドキュメントからの特徴の抽出、HL7 から FHIR への形式変換などが可能です。
データの整合性
Data Fusion の高度なデータ整合性機能があれば、自信を持ってビジネス上の意思決定ができるようになります。
Data Fusion では、変換、Wrangler によるデータ品質チェック、事前定義済みのディレクティブを指定する方法が構造化されているため、間違うリスクが最小限に抑えられます。
Data Fusion は統合されるデータのプロファイルを追跡し、データのオブザーバビリティに基づいて意思決定できるようにするため、品質の問題を特定しやすくなります。
データ形式は時間の経過とともに変化します。Data Fusion では変更を特定してエラー処理をカスタマイズすることでデータ ドリフトに対応できます。
メタデータとモデリング
Data Fusion では、メタデータを使用して分析情報を簡単に得られます。
データセットとパイプラインの技術、ビジネス、運用上のメタデータを収集し、検索で簡単にメタデータを見つけられます。
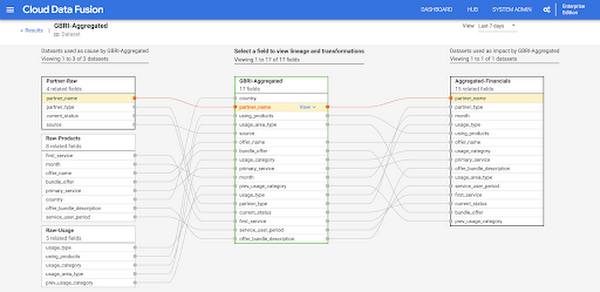
Data Fusion はデータモデルを理解し、データ、フロー、データセットの関係をプロファイルできるエンドツーエンドのデータビューを提供します。
カタログ間のメタデータの交換や、REST API を使用したエンドユーザーのワークベンチとの統合が可能になります。
Data Fusion のデータ リネージ機能を使用すると、データフローや、ビジネス上の意思決定に合わせたデータの準備方法を把握できます。
オープン クラウド、ハイブリッド クラウド、マルチクラウド
Data Fusion はクラウド ネイティブで CDAP を利用しています。CDAP は、オンプレミスとクラウドのデータ分析アプリケーションを構築するための 100% オープンソースのフレームワークです。つまり、ビジネスニーズに合わせて、変更を加えることなくさまざまな環境で統合パイプラインをデプロイして実行できます。
データ保護
Data Fusion は次の方法でデータのセキュリティを確保します。
プライベート IP でオンプレミス データへのアクセスを保護します。
デフォルトで、または顧客管理の暗号鍵(CMEK)を使用して保存データを暗号化し、サポートされているストレージ システム内のすべてのユーザーデータを制御します。
プラットフォーム リソースのセキュリティ境界である VPC Service Controls を通じてデータの引き出し保護機能を提供します。
機密性の高いパスワード、URL、JDBC 文字列を Cloud KMS に保存し、外部の KMS システムと統合できます。
Cloud DLP と統合して、転送中のデータをマスキング、秘匿化、暗号化します。
まとめ
お客様の組織にも、さまざまなプラットフォームにばらばらに閉じ込められているデータがきっとおありでしょう。データをまとめ、変換を適用し、データパイプラインを作成して、すべてのデータチームの満足度と生産性を向上させる作業をお客様の部署が担当されているなら、Cloud Data Fusion を使えば必要なものがすべて揃います。また、Cloud Storage や Dataproc でデータレイクをキュレートしたり、データ ウェアハウジング用にデータを BigQuery に移動したり、Cloud Spanner などのリレーショナルストア用にデータを変換したりするために Google Cloud データツールをすでに使用している場合、Data Fusion の統合によって開発とイテレーションがさらに迅速かつ容易になります。Data Fusion の詳細については、ドキュメントをご確認ください。

#GCPSketchnote をさらにご覧いただくには、GitHub リポジトリをフォローしてください。同様のクラウド コンテンツについては、Twitter で @pvergadia で発信しています。thecloudgirl.dev もぜひ定期的にご確認ください。
-Google Cloud プロダクト管理データ分析担当 Chaitanya(Chai)Pydimukkala
-Google デベロッパー アドボケイト Priyanka Vergadia




