Bridge data silos with Data Fusion
Chai Pydimukkala
Product Lead, Google Cloud
Priyanka Vergadia
Staff Developer Advocate, Google Cloud
? Prefer to listen? Check out this episode on the Google Cloud Reader podcast
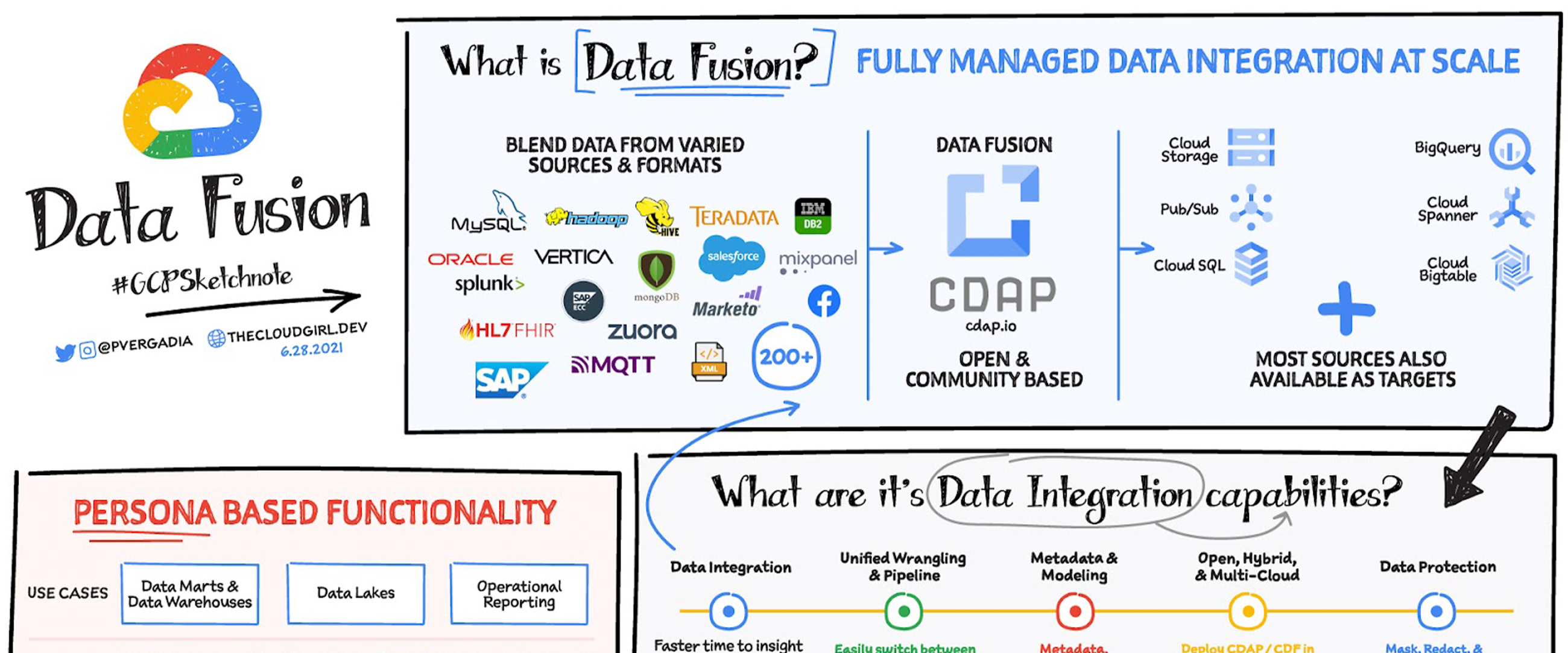
A huge challenge with data analytics is that the data is all over the place and is in different formats . As a result, you often need to complete numerous integration activities before you can start to gain insights from your data. Data Fusion offers a one-stop-shop for all enterprise data integration activities including ingestion, ETL, ELT and Streaming and with an execution engine optimized for SLAs and cost. It is designed to make lives easier for ETL developers, data analysts, and data engineers on Google Cloud, Hybrid Cloud or Multi Cloud environments.
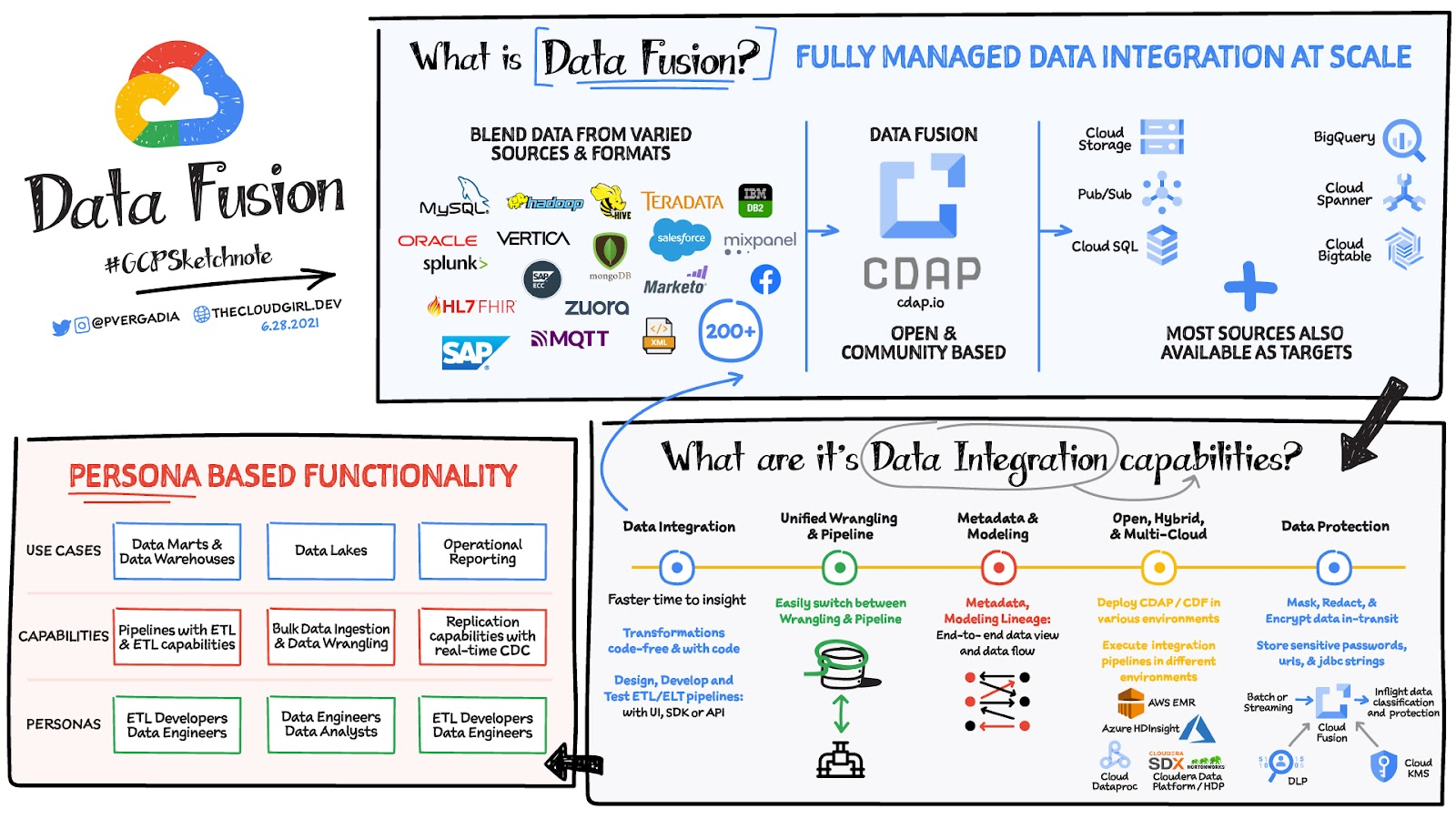
Data Fusion is Google’s cloud native, fully managed, scalable enterprise data integration platform. It enables bringing transactional, social or machine data in various formats from databases, applications, messaging systems, mainframes, files, SaaS and IoT devices, , offers an easy to use visual interface , and provides deployment capabilities to execute data pipelines on ephemeral or dedicated Dataproc clusters in Spark. Cloud Data Fusion is powered by open source CDAP which makes the pipelines portable across Google Cloud or Hybrid or multi cloud environments..
Data integration capabilities
Data integration for optimized analytics and accelerated data transformations
- Data Fusion supports a broad set of more than 200 connectors and formats, which enables you to extract and blend data You can develop data pipelines in a visual environment to improve productivity. .
- Data Fusion provides data wrangling capabilities to prepare data and provides capabilities to operationalize the data wrangling to improve business IT collaboration
- You can leverage the extensive REST API to design, automate, orchestrate and manage the lifecycle of the pipelines .
- Data Fusion supports all data delivery modes including batch, streaming or real-time making it a comprehensive platform to address both batch and streaming related use cases.
- It provides operational insights so that you can monitor data integration processes. Manage SLA’s and help optimize and fine tune integration jobs.
- Data Fusion provides capabilities to parse and enrich unstructured data using Cloud AI, for example, converting audio files to text, applying NLP to detect sentiment, or extracting features from images and documents or converting HL7 to FHIR formats
Data consistency
Data Fusion builds confidence in business decision-making with advanced data consistency features:
- Data Fusion minimizes the risk of mistakes by providing structured ways of specifying transformations, data quality checks with Wrangler, and predefined directives.
- Data Fusion helps identify quality issues by keeping track of profiles of the data being integrated and enabling you make decisions based on data observability.
- Data formats change over time, Data Fusion helps handle data drift with the ability to identify change and customize error handling.
Metadata and modeling
Data Fusion makes it easy to gain insights with metadata:
- You can collect technical, business, and operational metadata for datasets and pipelines and easily discover metadata with a search.
- Data Fusion, provides end-to-end data view to understand the data model, and to profile data, flows, and relationships of datasets.
- It enables exchange of metadata between catalogs and integration with end-user workbenches using REST APIs.
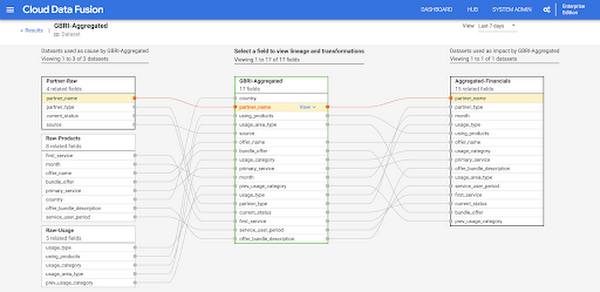
The Data Fusion data lineage feature enables you to understand the flow of your data and how it is prepared for business decisions.
Open, hybrid, and multi-cloud
Data Fusion is cloud-native and powered by CDAP, a 100% open-source framework for building on-premises and cloud data analytics applications . This means you can deploy and execute integration pipelines in different environments without any changes to suit business needs.
Data protection
Data Fusion ensures data security in the following ways:
- It provides secure access to on-premises data with private IP.
- It encrypts data at rest by default or with Customer Managed Encryption Keys (CMEK) to control across all user data in supported storage systems.
- It provides data exfiltration protection via VPC Service Controls, a security perimeter around platform resources.
- You can store sensitive passwords, URLs, and JDBC strings in Cloud KMS, and integrate with external KMS systems.
- It integrates with Cloud DLP to mask, redact, and encrypt data in transit.
Conclusion
Chances are that in your enterprise there is data siloed in various platforms. If it’s your job to bring it together, apply transformations, create data pipelines, and make all your data teams happier and more productive then Cloud Data Fusion has what you need. And if you already use Google Cloud data tools for curating a data lake with Cloud Storage and Dataproc, moving data into BigQuery for data warehousing, or transforming data for a relational store like Cloud Spanner, then Data Fusion integrations make development and iteration fast and easy. For a more in-depth look into Data Fusion check out the documentation.
For more #GCPSketchnote, follow the GitHub repo. For similar cloud content follow me on Twitter @pvergadia and keep an eye out on thecloudgirl.dev.




