Better together: orchestrating your Data Fusion pipelines with Cloud Composer
Rachael Deacon-Smith
Developer Advocate, Google
The data analytics world relies on ETL and ELT pipelines to derive meaningful insights from data. Data engineers and ETL developers are often required to build dozens of interdependent pipelines as part of their data platform, but orchestrating, managing, and monitoring all these pipelines can be quite a challenge.
That’s why we’re pleased to announce that you can now orchestrate and manage your Data Fusion pipelines in Cloud Composer using a rich set of Cloud Data Fusion operators.
The new Cloud Data Fusion operators let you easily manage your Cloud Data Fusion pipelines from Cloud Composer without having to write lots of code. By populating the operator with just a few parameters, you can now deploy, start, and stop your pipelines, letting you save time while ensuring accuracy and efficiency in your workflows.
Managing your data pipelines
Data Fusion is Google Cloud’s fully managed, cloud-native data integration service that is built on the open source CDAP platform. Data Fusion helps users build and manage ETL and ELT data pipelines through an intuitive graphical user interface. By removing the coding barrier, data analysts and business users can now join developers in being able to manage their data.
Managing all your Data Fusion pipelines can be a challenge. Determining how and when to trigger your pipelines, for example, is not as simple as it sounds. In some cases, you may want to schedule a pipeline to run periodically, but quickly realize that your workflows have dependencies on other systems, processes, and pipelines. You may find that you often need to wait to run your pipeline until some other condition has been satisfied, such as receiving a Pub/Sub message, data arriving in a bucket, or dependent pipelines in which one pipeline is dependent on data outputted by the other pipeline.
This is where Cloud Composer comes in. Google’s Cloud Composer, built on the open source Apache Airflow, is our fully managed orchestration service that lets you manage these pipelines throughout your data platform. Cloud Composer workflows are configured by building directed acyclic graphs (DAGs) in Python. And while DAGs describe the collection of tasks in a given workflow, it’s the operators that determine what actually gets done by a task. You can think of operators as a template, and these new Data Fusion operators let you easily deploy, start and stop your ETL/ELT Data Fusion pipelines by providing just a few parameters.
Let’s look at a use case where Composer triggers a Data Fusion pipeline once a file arrives in a Cloud Storage bucket:
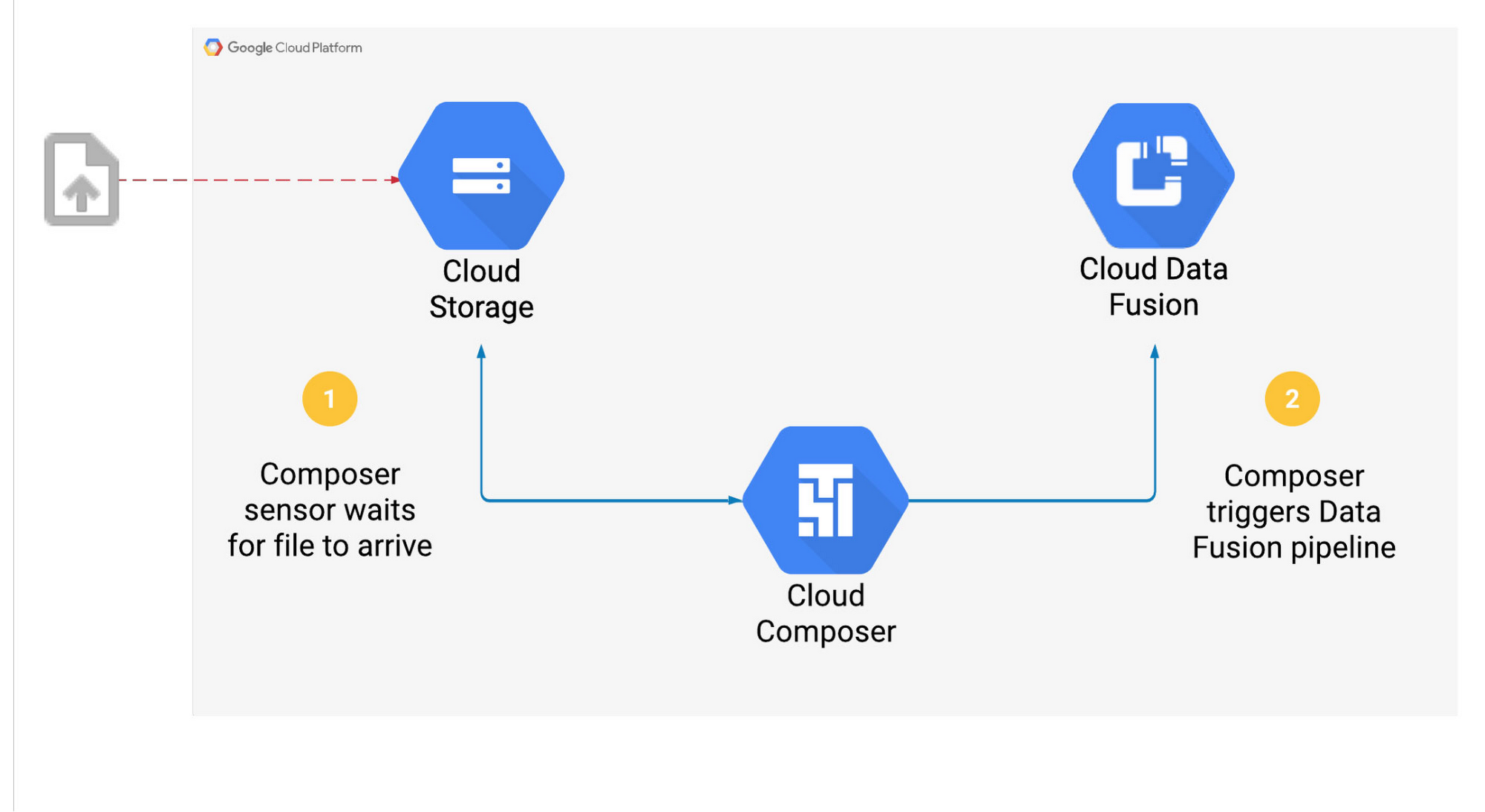
The steps above will be carried out as a series of tasks in Composer. Once an operator is instantiated, it will become a single task in a workflow. We will use the CloudDataFusionStartPipeline operator to start the Data Fusion pipeline.
Using these operators simplifies the DAG. Instead of writing Python code to call the Data Fusion or CDAP API, we’ve provided the operator with details of the pipeline, reducing complexity and improving reliability in the Cloud Composer workflow.
Getting started: orchestrating pipelines
So how would orchestrating these pipelines with these operators work in practice? Here’s an example of how to start one pipeline. The principles here can easily be extended to start, stop, and deploy all your Data Fusion pipelines from Cloud Composer.
Assuming there’s a Data Fusion instance with a deployed pipeline ready to go, let’s create a Composer workflow that will check for the existence of a file in a Cloud Storage bucket. (Note: If you’re not familiar with Cloud Composer DAGs, you may want to start with this Airflow tutorial.) We’ll also add one of the new Data Fusion operators to the Cloud Composer DAG so that we can trigger the pipeline when this file arrives, passing in the new file name as a runtime argument.
We can then start our Cloud Composer workflow and see it in action.
1. Check for existence of object in Cloud Storage bucket
Add the GCSObjectExistenceSensor sensor to your DAG. Once this task is started, it will wait for an object to be uploaded to your Cloud Storage bucket
2. Start the Data Fusion pipeline
Use the CloudDataFusionStartPipelineOperator operator to start a deployed pipeline in Data Fusion. This task will be considered complete once the pipeline has started successfully in Data Fusion.
You can check out the airflow documentation for further details on the parameters required for this operator.
3. Set the order of the task flow using the bit shift operator
When we start this DAG, the gcs_sensor task will run first, and only when this task has completed successfully will the start_pipeline task execute.
Now your DAG is complete, click the link to the DAGs Folder from the Cloud Composer landing page and upload your DAG.

Click on the Airflow web server link to launch the Airflow UI and then trigger the DAG by clicking the run button.
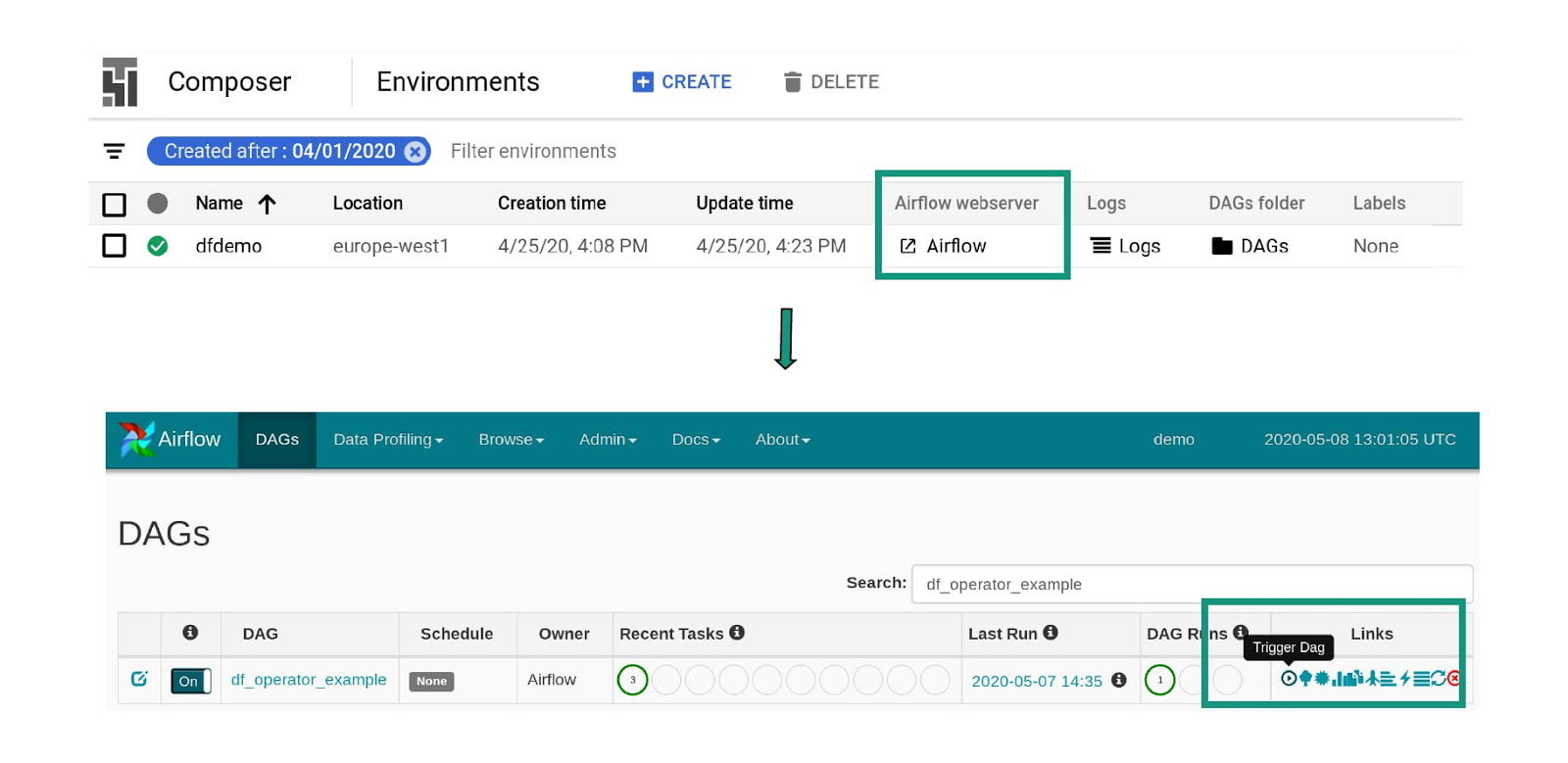
5. The tasks are now running. Once a file is uploaded to our source bucket, the Data Fusion pipeline will be triggered.
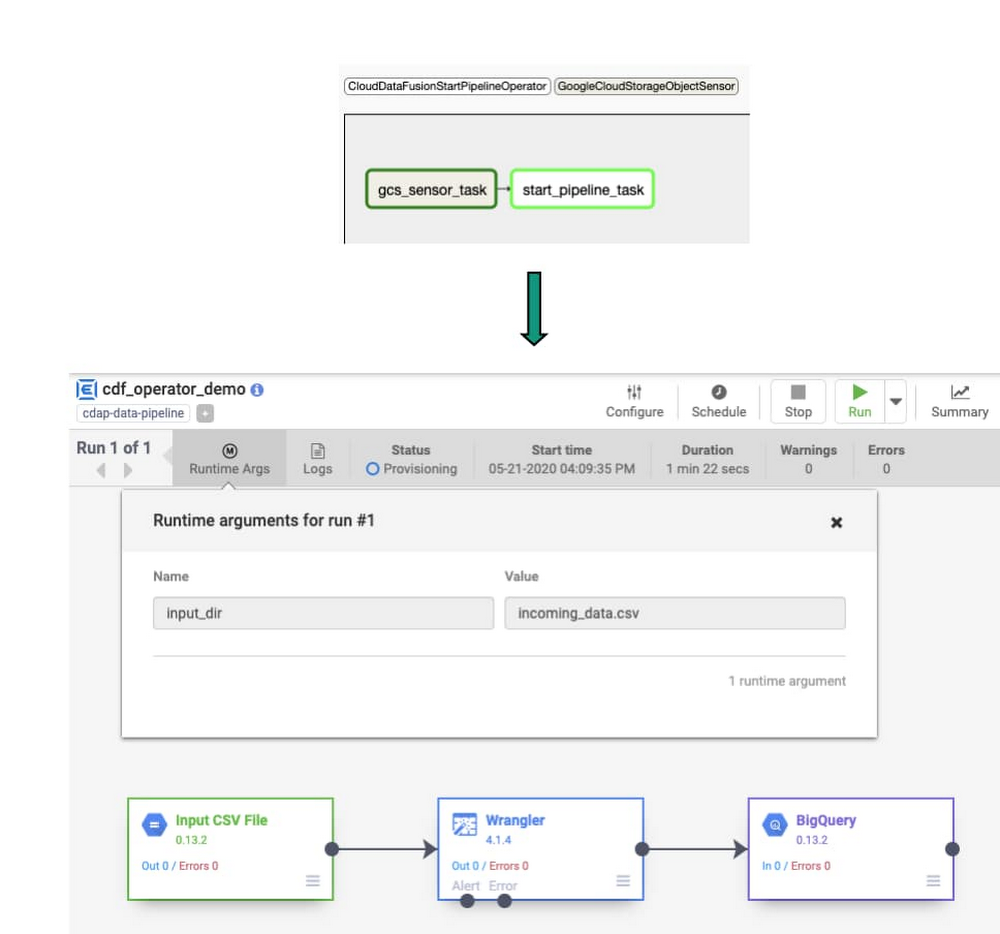
Operate and orchestrate
Now that you no longer have to write lines of Python code and maintain tests that call the Data Fusion API, you have more time to focus on the rest of your workflow. These Data Fusion operators are a great addition to the suite of operators already available for Google Cloud. Cloud Composer and Airflow also support operators for BigQuery, Cloud Dataflow, Cloud Dataproc, Cloud Datastore, Cloud Storage, and Cloud Pub/Sub, allowing greater integration across your entire data platform.
Using the new Data Fusion operators is a straightforward way to yield a simpler and more easy-to-read DAG in Cloud Composer. By reducing complexity and removing the coding barrier, managing ETL and ELT pipelines becomes more accessible to members of your organization. Check out the Airflow documentation to learn more about these new operators.

