機械学習モデルの解釈を支援する BigQuery Explainable AI が一般提供開始
Google Cloud Japan Team
※この投稿は米国時間 2022 年 1 月 19 日に、Google Cloud blog に投稿されたものの抄訳です。
Explainable AI(XAI)は、機械学習モデルの意思決定を理解し、解釈するのに役立ちます。このたび、BigQuery Explainable AI の一般提供(GA)を開始いたしました。BigQuery は、Explainable AI を XAI の手法とモデルタイプの両面から最も包括的にサポートするデータ ウェアハウスです。BigQuery のスケールで実行され、1 つの SQL クエリで数百万件の説明を数秒以内に導き出します。
Explainable AI はなぜそれほど重要なのでしょうか。AI や ML への投資を続ける企業の間で、機械学習モデルの内部構造を理解するために、Explainable AI の必要性が急速に高まりつつあります。2021 年の IT 関連の予算編成において、76% の組織が人工知能(AI)と機械学習(ML)を他の取り組みよりも優先度の高いものと考えており、PwC の調査によると、82% の CEO が、AI による意思決定を信頼できるものにするためには、その決定に説明性があることが不可欠であると考えています。
このブログ投稿は BigQuery Explainable AI に焦点を当ててはいますが、Google Cloud は、Vertex Explainable AI(AutoML Tables、AutoML Vision、カスタム トレーニングされたモデルを含む)などの、BigQuery 以外のモデルの解釈を支援するさまざまなツールやフレームワークも提供しています。
BigQuery の Explainable AI はどのような仕組みなのでしょうか。また、実際にどのように使うのでしょう。
2 種類の Explainable AI: グローバルな説明可能性とローカルな説明可能性
Explainable AI において最初に知っておくべきことは、ML モデルのトレーニングに使われる特徴量の説明可能性が、グローバルな説明可能性とローカルな説明可能性の 2 つに大別されるということです。
次の 3 つの特徴量から、住宅価格(米ドル)を予測する ML モデルがあるとします。(1)寝室の数、(2)最寄りの市中心部までの距離(3)築年数。
グローバルな説明可能性(またはグローバルな特徴量の重要度)は、モデルに対する特徴量の全体的な影響を表し、モデルの予測に関し、ある特徴量が他の特徴量よりも大きな影響を及ぼしたかどうかを把握するのに役立ちます。たとえば、グローバルな説明可能性によると、一般的に住宅価格の予測においては、寝室の数や市中心部までの距離が、建築年月日よりもはるかに強い影響を与えていることがわかります。グローバルな説明可能性は、数多くの特徴量があり、そのうちどれがモデルに対して最も重要な影響を与えるかを知りたい場合に特に有用です。また、モデルの一般化可能性向上のため、重要度の低い特徴量を特定してプルーニングするのに、グローバルな説明可能性を利用してもよいでしょう。
ローカルな説明可能性(または、特徴アトリビューション)は、それぞれの特徴量が特定の予測に対してどう寄与しているかの内訳を示します。たとえば、あるモデルが ID#1001 の住宅の予測価格を 23 万ドルと提示したとします。この場合、ローカルな説明可能性は、基準額(たとえば 5 万ドル)と、各特徴量がその基準額への上乗せにどう影響するかを示します。たとえば、基準額である 5 万ドルに加え、ベッドルームが 3 つあることでプラス 5 万ドル、市中心部に近いことでプラス 10 万ドル、建築時期が 2010 年であることでプラス 3 万ドル、合計 23 万ドルのようにモデルが予測したことがローカルな説明可能性によって明らかになります。つまり、予測を行うためにモデルが使用する各特徴量が、どれだけ判断に寄与しているかを正確に把握することが、ローカルな説明可能性の主な目的なのです。
BigQuery Explainable AI が適用される ML モデル
BigQuery Explainable AI は、IID データの教師あり学習モデルや時系列モデルなど、さまざまなモデルに適用されます。BigQuery Explainable AI のドキュメントには、モデルごとに異なる説明可能性を適用する方法の概要が記載されています。なお、各説明可能性のメソッドには、Shapley 値などの独自の計算方法があります。詳しくは上記のドキュメントをご覧ください。
BigQuery Explainable AI の使用例
次のセクションでは、BigQuery Explainable AI をそれぞれ異なる ML アプリケーションで使用する 3 つの例をご紹介します。
BigQuery Explainable AI の回帰モデル
まず、ブーストツリー回帰モデルを使って、乗客数、支払いタイプ、支払い総額、走行距離などの特徴から、タクシー運転手が乗客を載せたときにチップをいくら受け取るかを予測してみましょう。次に、BigQuery Explainable AI を使って、グローバルな説明可能性(どの特徴量が最も重要であったか)とローカルな説明可能性(モデルがどのようにして各予測を導き出したか)の観点から、モデルが予測を行う仕組みを理解します。
タクシー乗車のデータセットは、BigQuery の一般公開データセットに由来し、以下のテーブルで一般に公開されています。最初に、ブーストツリー回帰モデルを以下のようにトレーニングします。
次に、BigQuery ML で標準的に使われている ML.PREDICT で、説明可能性を使わずに予測をしてみましょう。

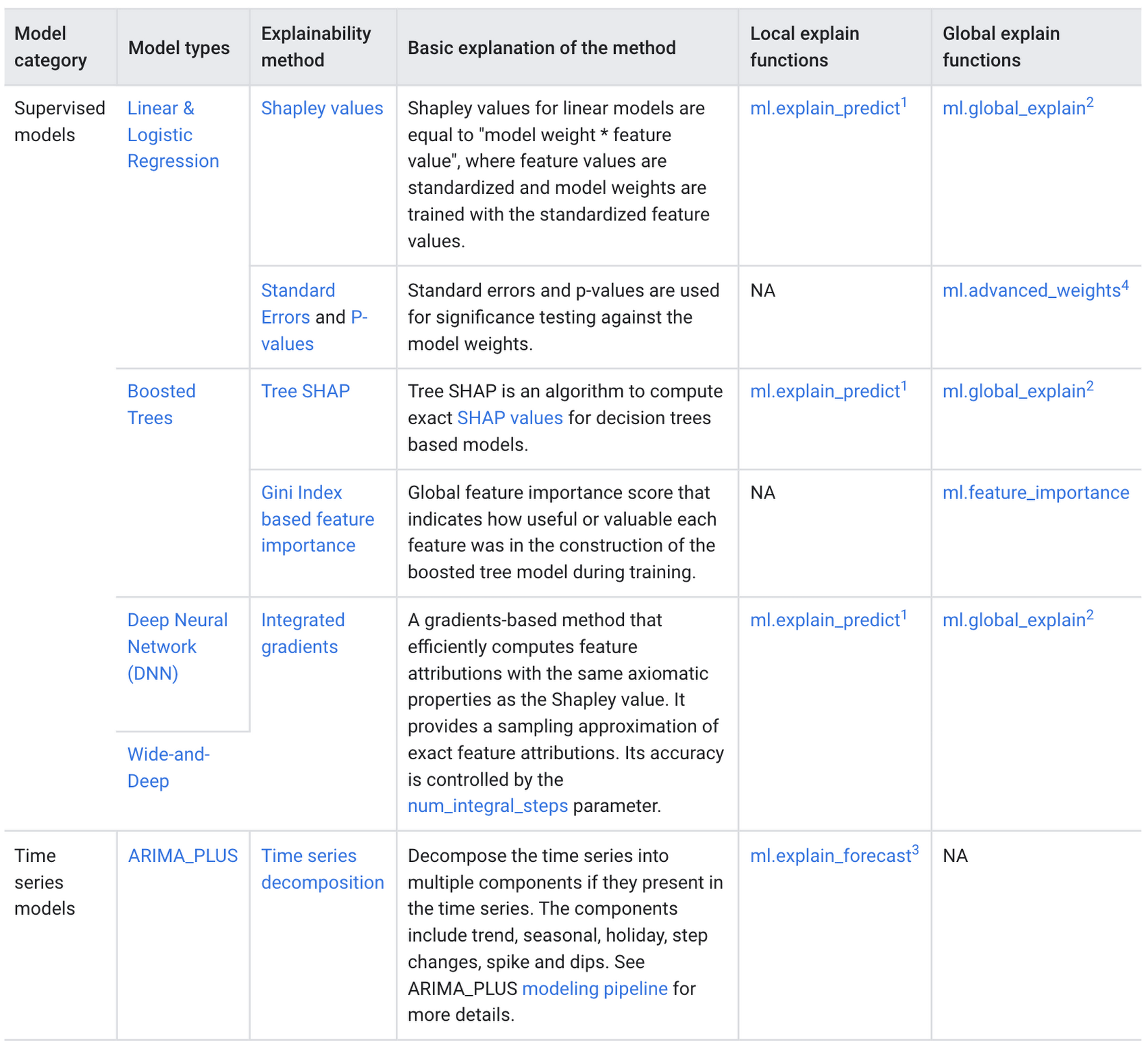
ここで不思議に思うかもしれません - モデルはどうやってこの ~11.077 という予測を生成したのでしょうか。
BigQuery Explainable AI は、その疑問にお答えします。ML.PREDICT を使う代わりに、ML.EXPLAIN_PREDICT にオプションのパラメータ top_k_features を追加したものを使います。ML.EXPLAIN_PREDICT は、ML.PREDICT の機能を拡張し、各特徴量が予測値にどう寄与するかを説明する列を追加して出力します。実際のところ、ML.EXPLAIN_PREDICT は ML.PREDICT からのすべての出力を含んでいるので、代わりに毎回 ML.EXPLAIN_PREDICT を使ってもいいかもしれません。
これらの列の解釈方法:
Σfeature_attributions + baseline_prediction_value = prediction_value
詳しく見てみましょう。prediction_value は ~11.077 で、これは単純な predicted_tip_amount の値です。baseline_prediction_value は ~6.184 で、これは平均的なチップ料金の例です。top_feature_attributions は、各特徴量が予測値に対してどの程度寄与しているかを示します。たとえば、total_amount は predicted_tip_amount に対し、~2.540 の寄与度があります。
ML.EXPLAIN_PREDICT は、回帰モデルのローカル特徴量の説明可能性を示します。グローバルな特徴量の重要性について詳しくは、ML.GLOBAL_EXPLAIN のドキュメントをご覧ください。
BigQuery Explainable AI の分類モデル
ロジスティック回帰モデルを使って、分類モデルによる BigQuery Explainable AI の例をご紹介します。先ほどと同じ一般公開データセット、bigquery-public-data.new_york_taxi_trips.tlc_yellow_trips_2018 を使用できます。
ロジスティック回帰モデルを以下のようにトレーニングして、タクシー料金に占めるチップの金額の割合の範囲を予測させます。
次に、ML.EXPLAIN_PREDICT を実行すると、分類結果とローカルな特徴量の説明可能性についての追加情報の両方を入手できます。グローバルな説明可能性については、ML.GLOBAL_EXPLAIN を使用します。先ほどと同じく、ML.EXPLAIN_PREDICT は ML.PREDICT からのすべての出力を含んでいるので、代わりに毎回 ML.EXPLAIN_PREDICT を使ってもいいかもしれません。
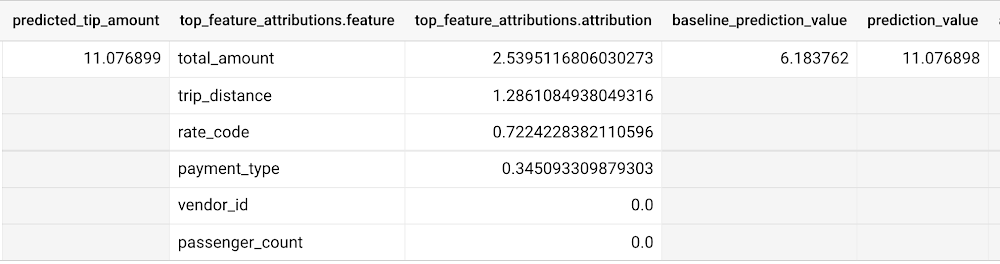
先ほどの回帰の例と同様、prediction_value を導き出すための以下のような式が使用されます。
Σfeature_attributions + baseline_prediction_value = prediction_value
上のスクリーンショットにあるように、baseline_prediction_value は ~0.296 です。total_amount はこの予測を行う上で最も重要な特徴量で、prediction_value に ~0.067 寄与し、trip_distance がそれに続きます。特徴量 passenger_count の prediction_value への寄与は少なく、-0.0015 となっています。特徴量 vendor_id、rate_code、payment_type は、prediction_value にはあまり寄与していないことが見受けられます。
なぜ prediction_valueの値である「~0.389」が、probability の値である 「~0.359」と一致しないのかと、不思議にお思いかもしれません。これは、回帰モデルと異なり、分類モデルにおいては、prediction_value は確率スコアではないためです。その代わり、prediction_value は予測されたクラスのロジット値(すなわち log-odds)であり、この値に softmax 変換を適用することで、別途確率に変換できます。例えば、3 クラス分類の場合、log-odds の出力は [2.446、-2.021、-2.190] となります。softmax 変換を適用すると、これらのクラス予測の確率は [0.9905、0.0056、0.0038] となります。
BigQuery Explainable AI の時系列予測モデル
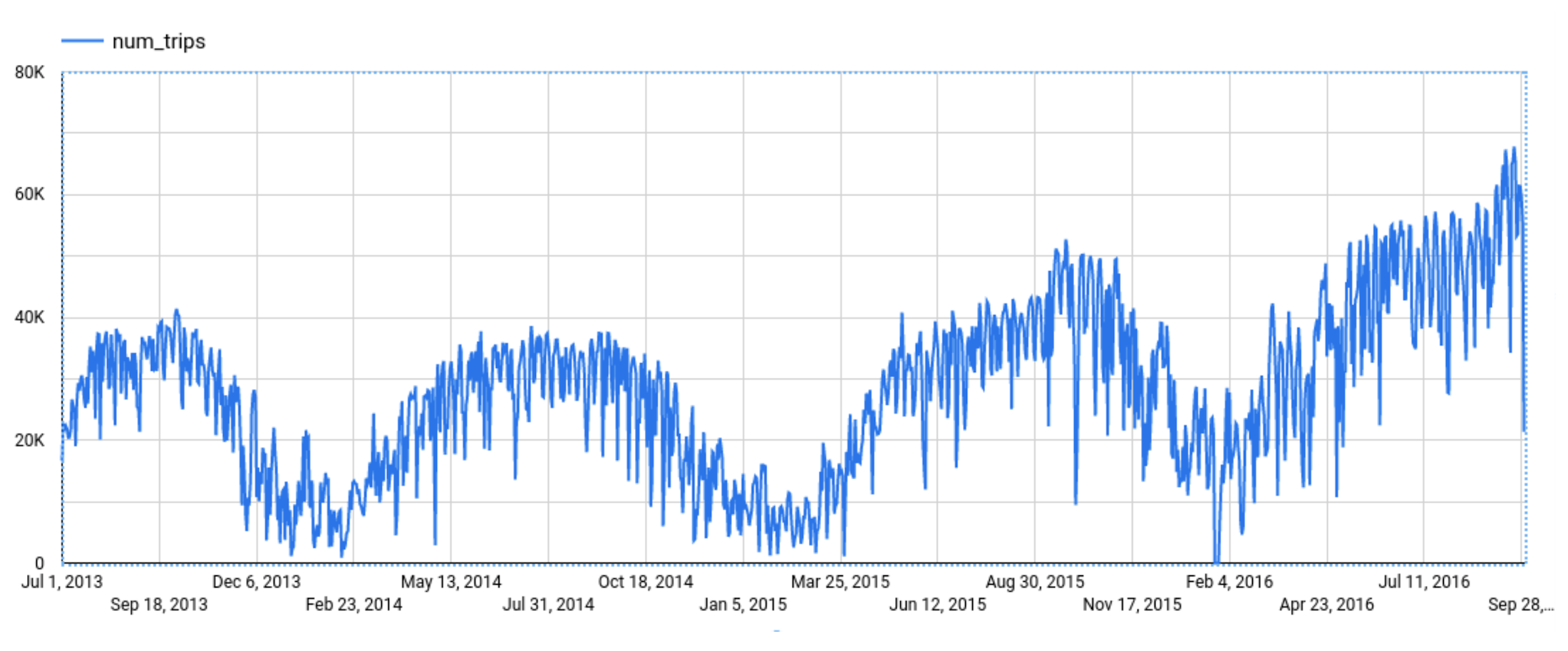
予測のための Explainable AI は、予測モデルがどのようにその予測をするに至ったかの経緯についての解釈を助けます。BigQuery の一般公開データである new_york.citibike_trips を使って、ニューヨーク市の自転車の移動の総数を予測する例を見てみましょう。
時系列モデルである ARIMA_PLUS を以下のようにトレーニングします。
この関数は、予測値および予測区間を出力します。入力時系列に追加してプロットすると下図のようになります。
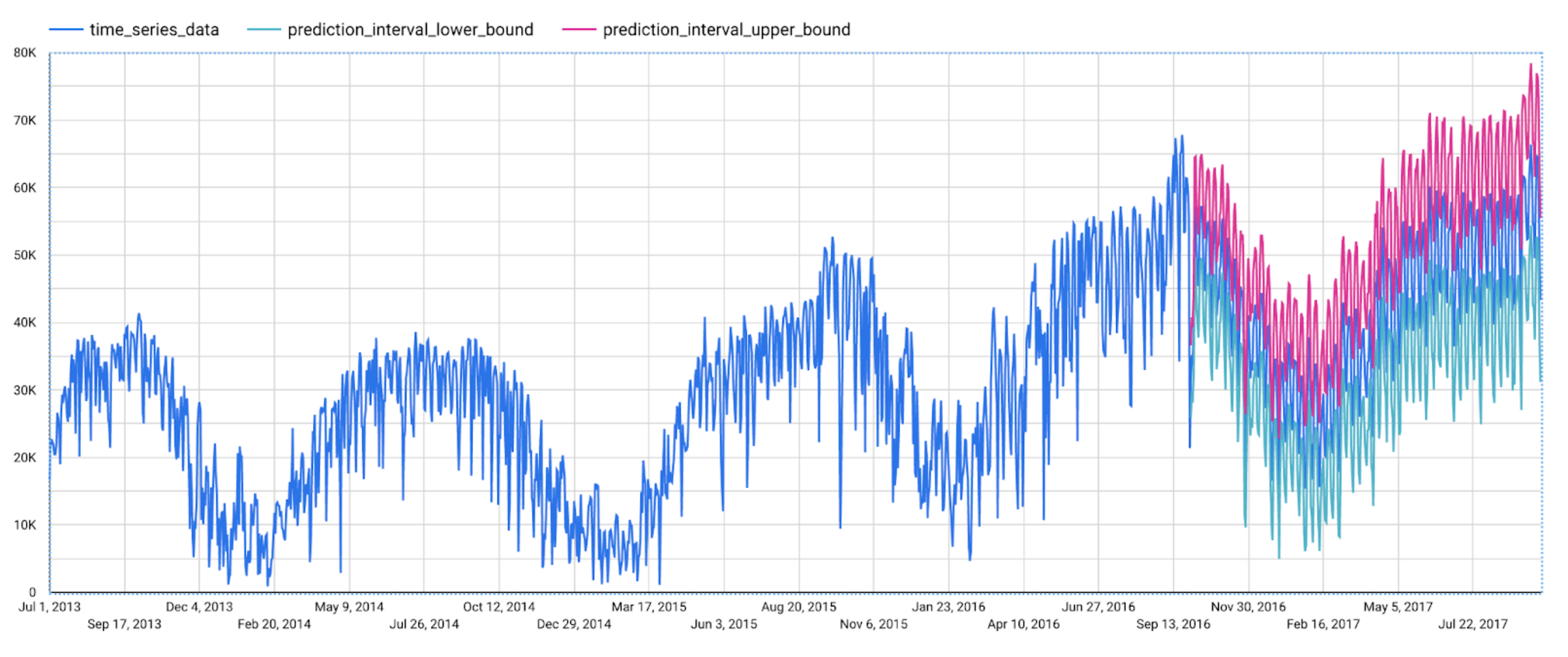
けれど、この予測モデルは、どのようにしてこの予測を導き出したのでしょう。説明可能性は、このようにモデルが予想外の予測をした際に非常に有用です。
ML.EXPLAIN_FORECAST により、BigQuery Explainable AI は、季節性、トレンド、休日効果、レベル(ステップ)変化、急上昇や急降下の外れ値の除去などへの透明性をさらに高めることができます。事実、ML.EXPLAIN_FORECAST は ML.FORECAST からのすべての出力を含んでいるので、代わりに毎回 ML.EXPLAIN_FORECAST を使ってもいいかもしれません。
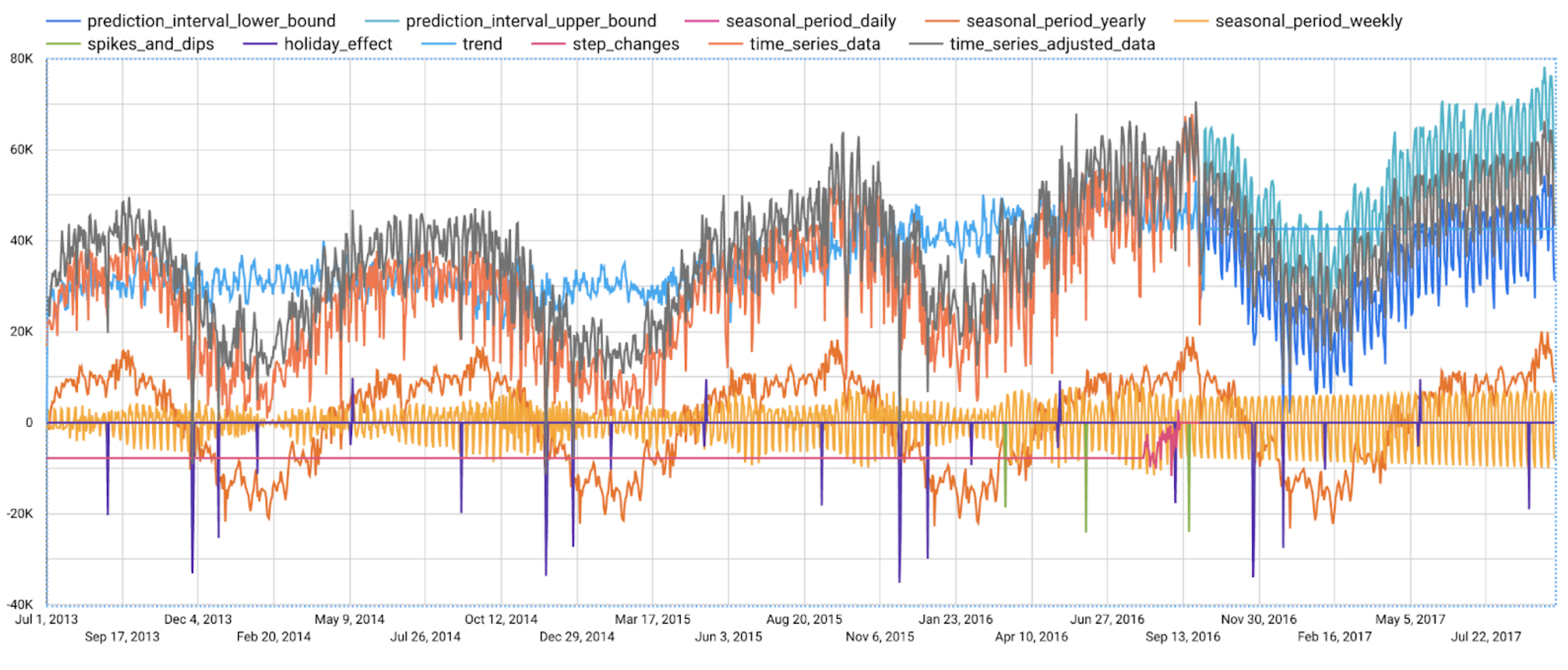
予測の結果のみを示している前の図に比べて、この図は予測がどのように行われるのか、より豊富な情報を示しています。
まず、急上昇や急降下の異常値を除去し、レベル変化を補正することで、入力時系列を調整する様子が示されています。つまり、次のようになります。
次に、調整された入力時系列を週次と年次の季節、休日効果、トレンドなどの異なるコンポーネントに分解する様子が示されています。つまり、次のようになります。
最後に、これらのコンポーネントがどのように予測され、最終的な予測結果を構成するかが示されます。つまり、次のようになります。
時系列のコンポーネントについて詳しくは、こちらのドキュメントをご覧ください。
まとめ
BigQuery Explainable AI の一般提供により、皆さまが機械学習モデルを容易に解釈できるようになることを願っています。
BigQuery ML チーム、特に Lisa Yin、Jiashang Liu、Amir Hormati、Mingge Deng、Jerry Ye、そして Abhinav Khushraj に感謝します。また、Vertex Explainable AI チーム、特に David Pitman と Besim Avci にもお礼を言いたいと思います。
- BigQuery ML ソフトウェア エンジニア、Xi Cheng
- デベロッパー アドボケイト、Polong Lin




