株式会社Sprocket: 顧客行動データの保管先を Spanner に移行、運用コスト削減とサービスの拡充を推進

Google Cloud Japan Team
ウェブサイトやアプリケーション上における顧客の行動を分析し、パーソナライズされた顧客体験(CX: Customer Experience) を実現する CX 改善プラットフォーム「Sprocket(スプロケット)」。その開発・運用を行っている株式会社Sprocket(以下、Sprocket) では、サービスの核となる顧客行動データを格納するデータベースを刷新し、Google Cloud の Spanner へ移行しました。同社は将来的に、社内のコンピューティング環境全体を Google Cloud へ集約することも計画しています。今回は、この移行プロジェクトに携わったメンバーに話を伺いました。
利用しているサービス:
Spanner, BigQuery, Looker, Gemini, Dataflow
利用しているソリューション:
Database Migration
サービスに不可欠なデータ処理の効率化とコスト削減を Spanner への移行で達成
Sprocket は顧客体験を高めるサービスを幅広く提供。CX 改善プラットフォームの「Sprocket」では、ウェブサイトやアプリにおけるユーザーの行動データを収集し、分析結果に基づいて、顧客ごとにパーソナライズされた体験を提供しています。その方法は、ウェブ接客やアプリ接客、ページ内ポップアップ、EFO(入力フォーム最適化)、チャットボット、アンケートなど多岐にわたります。
ウェブ接客は「Sprocket」で提供される特長的な機能の 1 つです。これはユーザーの行動をリアルタイムに観察し、最適な情報を最適なタイミングで提示するサービスで、実店舗における「声かけ」や「案内」にあたるきめ細かな接客を実現します。
そこで重要になるのは、ユーザーごとにデータの管理や更新を高速かつ適切に行うシステムです。Sprocket では創業以来、他社クラウド プラットフォームの NoSQL サービスを、接客用の顧客行動データの保管先として利用してきました。しかし CTO の中田 稔氏は、事業規模の拡大に伴い、インフラの保守コストの増加が大きな問題になってきたと語ります。

「『Sprocket』で扱う顧客行動データの特長として、1 ユーザー当たりの情報量が非常に多いことと、データベースへの読み込みと書き込みの頻度が高いことが挙げられます。顧客の心理を正しく理解するためには、できるだけたくさんの情報をステータスとして保持し、ユーザーの行動に応じてリアルタイムに参照・更新する必要があるからです。従来のサービスはデータの読み込みと書き込みをするたびにリクエスト単位で課金される料金体系だったため、費用が増大し、インフラの維持コストを圧迫していました。また、NoSQL サービスを採用していたことから、障害時の調査や復旧の難易度が高いという問題も抱えていました。」
そこで同社がデータベース移行先として採用したのが Google Cloud の Spanner です。中田氏は、採用理由を次のように説明します。
「Spanner はノード単位の料金体系となっており、その高いパフォーマンスによって多くのデータの読み取り・書き込みを処理することができ、結果として約 45% のコスト削減が見込めることを確認できました。また Spanner は弊社で扱うデータの特性にも合っており、SQL が使えるため保守が簡単なことや、BigQuery とのシームレスなデータ連携、導入済みの Looker との相性の良さなどが魅力的で連携を検討しています。もともとログデータの集約と分析の基盤には BigQuery を活用していたので、プラットフォーム全体のデータ管理を Google Cloud に統合すれば、コストを抑えながら効率的に顧客にビジネス価値を提供できると考えました。」
【データベース移行前のシステム構成】
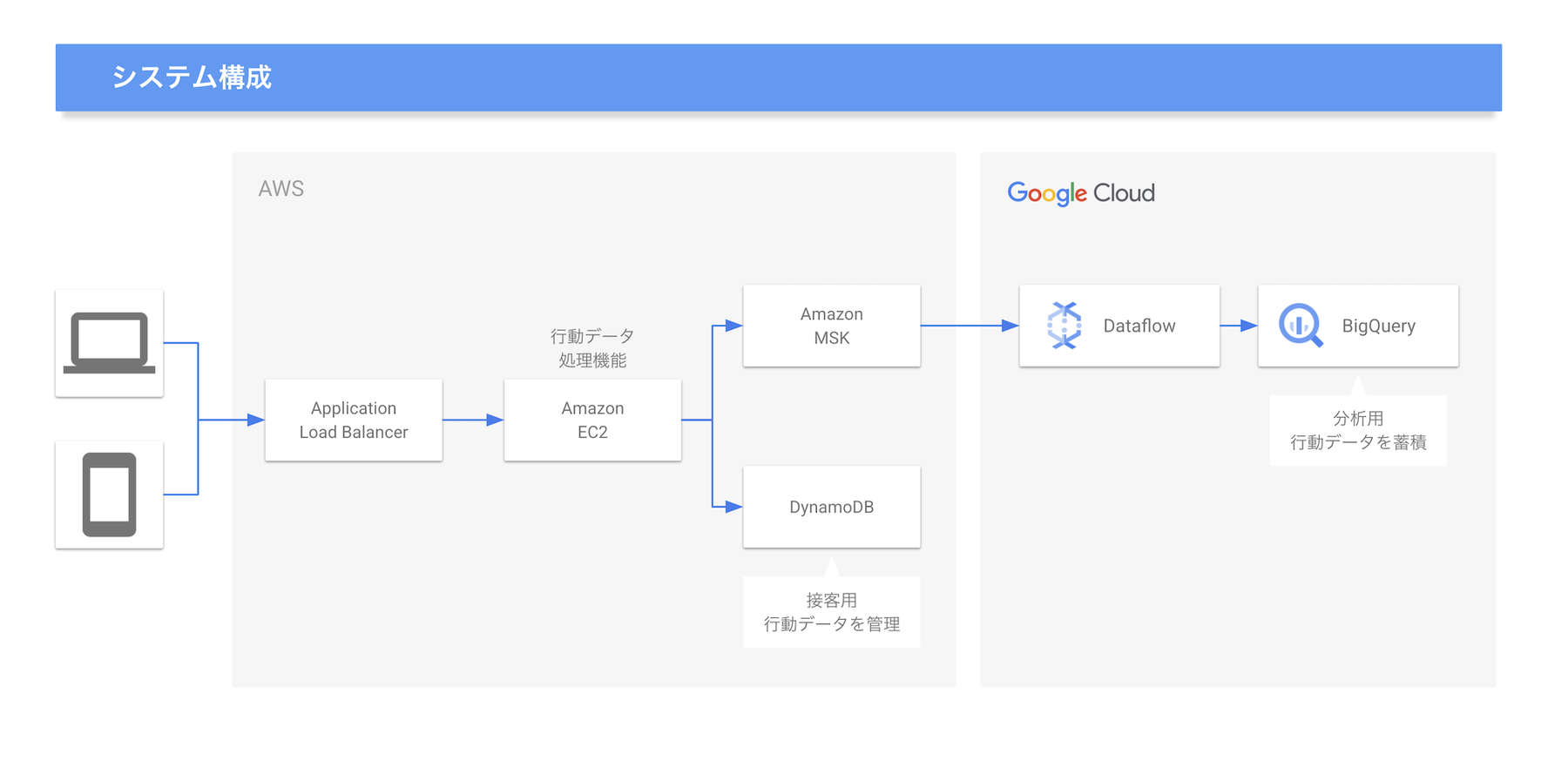
【データベース移行後のシステム構成】

システム移行で高速スケーリングやデータの可視化・多角的運用も可能に
Spanner への移行プロジェクトで最も重要なのは、サービスの提供を続けながら移行作業を実施しなければならないことでした。データが膨大だということもあり、事前の PoC(概念実証)ではデータ移行の可否も入念に検証されています。
この移行プロジェクトの進行を担当した、リサーチ&ディベロップメント本部 バックエンドエンジニアの山下 寛人氏は、一連の作業をこう振り返ります。

「今回は NoSQL からリレーショナル データベースへの移行となり、スキーマが異なるために複雑な手順が必要でしたが、Google Cloud 公式の移行ガイドが丁寧で、サンプルコードも用意されていたので大いに助かりました。移行プロジェクトでは Google Cloud の Tech Acceleration Program(TAP)を利用しつつ、Google Cloud のアカウント チームや Google Cloud プレミア パートナーである株式会社G-gen の担当者からタイムリーにサポートいただき、不明点を事前に解消できたこともスムーズな作業につながりました。」
Spanner への移行プロジェクトは順調に進行。山下氏によれば、その効果はすでに現れ始めています。
「一番強く実感しているのはスケーリングの速さです。業務では一時的に処理性能を拡大しなければならない場合もあるのですが、管理コンソールの操作だけでも数秒でスケーリングできるため、リソース管理が非常に便利です。また、オブザーバビリティがしっかりしているのも印象的です。CPU 使用率やスループットなどのメトリクスが自動的にモニタリングされるので、運用の可視化という点でも大きなメリットを感じています。」
一方、Sprocket では、データベースを Spanner へ移行するだけでなく、将来的にはコンピューティング環境を含めたインフラ全体を Google Cloud へ移行することも検討しています。CTO の中田氏はこれを実現すべく、Spanner と BigQuery の連携の強化や、Looker を使った可視化に力を入れていきたいと語ります。
「『Sprocket』では、ログデータのような長期間にわたるデータと、ユーザーにその都度提供するようなよりリアルタイム性の高いデータで、BigQuery と Spanner を使い分けています。両方のデータを連携させることで、これまでとは違う角度からの分析ができるようになります。今回、2 つのデータソースが Google Cloud に統合されたことで、その道筋が見えてきました。」
Google Cloud へのデータ統合、そして生成 AI の積極活用へ
Sprocket では、サービスやプラットフォーム自体の見直しも進めています。従来はウェブサイトやアプリケーションが主な顧客接点となっていましたが、今後は実店舗やコールセンターなども含めた、さまざまな領域における、より良い顧客体験の提供を目指しています。事業開発本部 本部長の曾我 博規氏は、これを達成するために Gemini をはじめとした生成 AI の活用にも挑戦していると説明します。

「私たちが取り組んでいるのは顧客心理の解明です。お客さまが何を考えていて、どういう情報に触れたら、どのような行動変容が生まれるのか。この謎解きをして情報をフィードバックすることで、企業と顧客が互いを高めあう関係性を作りたいと考えています。その実現に向け、Google Cloud へのデータ統合を軸とした次のステップとして、生成 AI の活用を積極的に進めています。」
新たなチャレンジの一環として、Sprocket ではコールセンターの応対履歴の解析と課題の可視化を実施しました。オペレータが入力した膨大なテキストを BigQuery に読み込ませてデータとして加工し、Gemini を使って分析すれば、問い合わせがあった顧客の本質的な意図を把握することが可能になります。最後に曾我氏は、今後のビジョンについてこう締めくくりました。
「コールセンターやカスタマーサービスのような部署には、顧客心理をひもとくヒントになる情報がたくさん埋もれています。そういった膨大なデータの処理には BigQuery と生成 AI が適していますし、分析結果の可視化には BigQuery と相性が良い Looker も利用できます。これからも Google Cloud を活用し、最適な形でビジネスサイクルを展開しながら、顧客体験の改善に取り組んでいきたいと考えています。」

株式会社Sprocket
2014 年 4 月 1 日設立。CX 改善プラットフォーム「Sprocket」の開発・運用とコンサルティングによる成果創出コミットメント サービスを提供。主要サービスである「Sprocket」では、ウェブサイトやアプリケーション上におけるユーザーの行動を分析し、そのデータに基づいてパーソナライズされたユーザー体験を実現している。近年では、インターネット上の顧客体験にとどまらない、コールセンターや実店舗などといったあらゆる顧客接点における体験向上のサポートにも力を入れている。
インタビュイー(写真左から)
・リサーチ&ディベロップメント本部 バックエンドエンジニア 山下 寛人 氏
・事業開発本部 本部長 曾我 博規 氏
・CTO 中田 稔 氏
その他の導入事例はこちらをご覧ください。

