株式会社エウレカの導入事例:Stackdriver Logging でのログ監視や、BigQuery を駆使した分析・活用などにより、SLO 99.95% を達成
Google Cloud Japan Team

恋愛・婚活マッチング サービス「Pairs」を運営する株式会社エウレカは、現在、そのシステム モニタリング環境に Google Cloud Platform を活用中。数年前から SRE チームを発足させることで、サービス品質の向上を追求してきました。そこで今回は同社 SRE チームの中心メンバーに、GCP の採用背景や、SRE 導入から目標達成まで、そしてこれからについて語っていただきました。

利用している Google Cloud Platform サービス
BigQuery、Stackdriver Logging、Cloud Pub/Sub、Cloud Dataflow、 Google Cloud Storage など写真左から
- Senior Engineer 山本 真嗣氏
- Senior Engineer 坂田 純氏
- Head of SRE 恩田 拓也氏
恋愛・婚活マッチング サービス「Pairs」および、カップル向けコミュニケーション アプリ「Couples」の開発・運営を行う事業会社。「Pairs」の会員数は 2018 年 2 月時点で約 700 万人(日本・台湾・韓国合計)、マッチング数は 5,600 万組を突破しています。2015 年、オンライン デーティングサービスをグローバル展開する IAC / Match Group に参加し、今後は東南アジアを中心にサービスを拡大していく予定。社としてのモットーは「全ての人が人生に可能性を開いていける世界を作る」。従業員数は 130 名(アルバイト含む)。
100 倍にログが増えても耐えられるシステム モニタリング環境がほしかった
株式会社エウレカが「Pairs」のサービスを開始したのは、2012 年 10 月のこと。その後、2014 年 7 月に会員数 100 万人を突破するなど、順調にサービス規模を拡大していくことになるのですが、その過程で、徐々にシステム モニタリングの必要性が高まっていったそうです。「お恥ずかしい話、サービス開始直後の数年間は立ち上げも含めた目先の作業が最優先になっており、ログの収集や活用が後回しになっていました。そんな中、2015 年に、当時、PHP で稼働させていたアプリケーションを、高速かつ先進的な Go で書き換えるフルスクラッチ プロジェクトがスタート。あわせてインフラやミドルウェア レイヤーなども全て刷新するということになり、このタイミングで、ログ基盤についても整備しようということになりました。ここで Google Cloud Platform(GCP)を選んだのは、コストはもちろん、スケーラビリティの面で GCP が有利だったから。データ分析基盤は、データの増加に対して、いかにスケーラブルであるかがとても大事。実際、現在と 2015 年当時ではデータの規模が数十倍にもなっています。ユーザー数の増加と、能動的に取得していくログの拡大を想定すると、今後、10 倍、100 倍にログが増えていったとしても耐えられるプラットフォームがほしかったのです。もちろん、BigQuery の存在も大きかったです。」(恩田さん)

その導入と運用にまつわる苦労についても聞いてみました。
「さほど複雑なことはやっていなかったので、導入について、大きなトラブルはありませんでした。ただ、運用についてはいくつかの苦労がありました。具体的には、サービス改善の PDCA を回していくためには、非エンジニアによる分析ニーズを満たす必要があります。導入初期は ETL 処理を行うレイヤーもなく、生データをひたすら溜め込んであるので利用してね、といった形で提供していたので、分析者が複雑なクエリを書かねばならず負担を強いていました。また、テーブル設計やクエリの投げ方についての社内教育不足などが原因で意図せぬコスト増を招くといった事態もありました。」(恩田さん)
「ユーザーログに関しては、テーブルの切り方をまちがえて、BigQuery の UI 上にテーブルが全部出せなくなったり、切り方が微妙でクエリが投げづらかったり、ミドルウェアの変更反映のミスが原因でログが欠損するなどいろいろな問題がありましたね……。最終的には山本を中心に、Cloud Pub/Sub と Cloud Dataflow を使うなど、ログの入れ方を工夫するようにしてからは、安全なかたちに改善されたと思います。」(坂田さん)
その後、さらなる BigQuery の有効活用を企図して、Stackdriver Logging の導入も決定。2017 年頃から、主にシステム系、アプリケーション系のモニタリングに活用しているとのことです。
「Stackdriver Logging は、他のモニタリング サービスと比べて多くの点で優秀でした。その第一の価値は、単純にログデータを飛ばすだけで、GCP のコンソール上でログを見られること。これまでは皆が本番環境に入ってやっていたことを、G Suite の 2 段階認証の設定により GCP 環境もセキュアに行えるようになったことは SLA の観点でも大きかったですね。セキュリティの観点からも本番サーバーへ開発者が入らなくても困らないような体制を目指していたので Stackdriver によってこれが実現できました。また、Stackdriver Logging にはログのエクスポート機能があるので、主要なログに関しては BigQuery にエクスポートして、いつでも集計できるように工夫しています。そのほか、システムログを Google Cloud Storage にエクスポートして長期保存したりなんて使い方もしています。GCP のサービスは、マネージドだけど柔軟性・拡張性に富んでいるところが良いと感じています。」(坂田さん)

SRE チームを発足し、戦略的にサービスの信頼性向上を追求
株式会社エウレカでは、近年、話題に上ることも多い SRE(Site Reliability Engineering)チームを早期に発足。恩田さんを中心に、戦略的にサービスの信頼性向上に取り組んできました。「SRE チームが発足したのは 2015 年の春頃。当時はまだインフラ チームという名称で、何となくミドルウェアや各種パブリック クラウド周りの技術を扱う集団という位置付けだったのですが、2016 年 1 月に正式に『SRE チーム』に改称。そのタイミングで、チームがどのようなミッションを持ち、どのような戦略で実現していくかを少しずつ練り込んでいきました。実際にかたちになってきたのは 2017 年の春くらいです。」(恩田さん)
エウレカの SRE チームのミッションは「ビジネスの阻害要因になる事象を全て排除する」こと。そのための具体的な戦略として 5 つの施策を掲げています。
「1 つ目が可用性の向上。SLO(Service Level Objective / サービスレベル目標)です。99.95% という具体的な目標を置き、事業的な機会損失の最小化を目指しています。2 つ目がブランド イメージの失墜に繋がるセキュリティ リスクの排除、3 つ目が事業規模に比例して組織が肥大化していかないような運用の自動化・自動修復(オート ヒーリング)体制の実現です。そして、4 つ目が適切なキャパシティ プランニングによる利益率の向上、5 つ目が開発チームの生産性をシステム面から支えることによる顧客価値提供速度の高速・安定化です。先ほどお話しした本番環境からの開発エンジニアの排除など、この多くに GCP のプロダクトが貢献してくれています。」(恩田さん)
「SLO 導入前は『今週はこんなエラーが見つかったので直していこう』という感じで五月雨に対応していたのですが、SLO を定めた後は サーバーサイド チーム合同で定例ミーティングを行い、毎週 SLI(Service Level Indicator / サービスレベル指標)を中心にエラーレートや Endpoint 単位でのパフォーマンスを Cloud Datalab を利用して毎週自動でレポート化しています。そして毎週のミーティングでシステムに問題が発生していないかを確認、何か問題が起きたときに誰が対応するのかといったことを決め、少しずつ改善を重ね SLO を目標に近づけていきました。」(坂田さん)
Cloud Datalab を利用したパフォーマンスの自動レポート
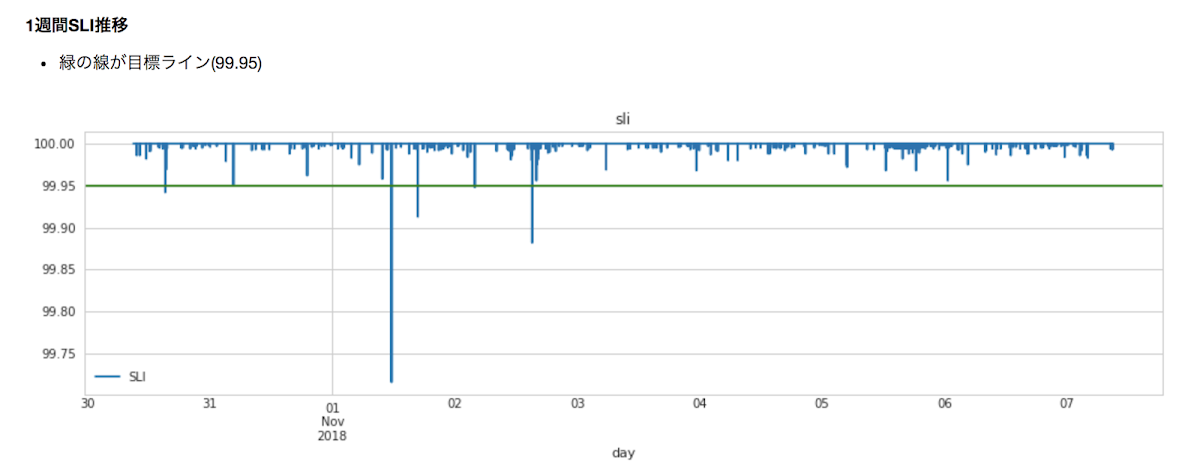
1 週間の SLI 推移
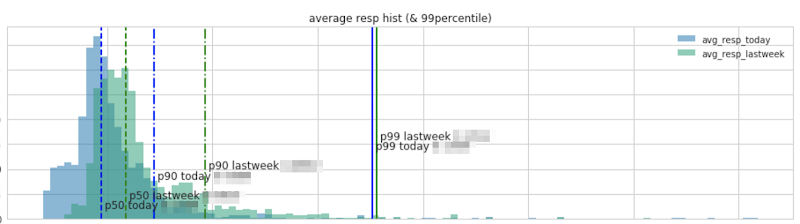
サービスのレスポンス(サーバーサイド)時間を示すヒストグラム
「システムの運用において健全な状態とは、エラーがでたら直さなければいけないという状態を保つこと。常にエラーが垂れ流されていると、僕らがデプロイをした時に問題の有無を定義できないのです。割れ窓理論的と言いますか……。実はこうすることで、それまで気づいていなかったエラーがたくさんでていることも分かったんです。だいぶ意識が変わりました。」(山本さん)

その結果、当初は目標値に届いていなかった SLO が徐々に改善。「ひたすら地道に改善していった。」(坂田さん)甲斐あって、現在は目標値である SLO を達成、またそれを維持しているそうです。
「今後の課題は、より広範なモニタリングです。現在はサーバー サイドしか見られていないのですが、今後はクライアント(スマートフォン アプリ)のクラッシュ ログやイベントログ、CDN のログなど、クライアント サイドからサーバー サイドまで、エンド トゥ エンドでログやメトリクスを取得・分析していくことで、さらにユーザー体験を向上させていきたいと考えています。また、それに加えて、Google Cloud Machine Learning Engine を活用した協調フィルタリングを実現していきたいと考えています。趣味や嗜好が近しい人やコミュニティをより適切に紹介するようなイメージですね。実は一部、既に実装されているのですが、まだ自動化ができていないなど理想的な形にはなっておらず、改善を行っています。」(坂田さん)
「アプリケーション サイドでは、マイクロ サービス化をより進めていく予定です。ただ、マイクロ サービス化を進めるということは、接合点が多くなるということでもありますから、結果として、障害を把握するのが難しくなります。そのため、今後は全てのログを入口から一貫性を持って追えるようにしていかねばならないと思っています。後は、Cloud Functions をもう少し上手に使っていきたいですね。1 日 1 度しかできない重めのバッチ処理も、Cloud Functions を上手に使えば定常的にやっていけるはず。何かの不整合が起きたときにイベントを飛ばして自動修復させるなんてことも実現できそうです。」(山本さん)
その他の導入事例はこちらをご覧ください。