COVID-19 関連の学術研究に対する Google Cloud の支援
Google Cloud Japan Team
※この投稿は米国時間 2020 年 4 月 14 日に、Google Cloud blog に投稿されたものの抄訳です。
COVID-19(新型コロナウイルス感染症)の影響が拡大し続ける中、医療やライフ サイエンス分野の研究者たちは新型コロナウイルス感染症について早急に理解を深めるべく取り組んでいます。そして、その作業を支援する技術としてクラウド テクノロジーへの注目が高まっています。
Google はこのようなエキスパートの皆様による尽力に対し心から謝意を表すとともに、この世界的な健康危機との戦いにおいてツールとテクノロジーという側面からお手伝いできればと考えています。本日は、研究者とその所属組織やコミュニティをサポートするために Google が関わっているさまざまな取り組みについての情報をさらにご案内します。
COVID-19 の拡大と影響に関する研究者の予測を支援
ノースイースタン大学の Network Science Institute にある Laboratory for the Modelling of Biological + Socio-technical Systems(MoBS)では、1 月から Google Cloud で大規模なデータドリブン モデル シミュレーションの実行を開始し、渡航規制や社会的距離を保つ措置などの緩和戦略が感染拡大にどのように影響するか試算しています。各モデルはさまざまなパラメータや膨大なデータで構成され、複雑さを極めているため、莫大な計算能力やデータ処理能力、ストレージを必要とします。
ノースイースタン大学の研究者たちは、Cloud Life Sciences API によるバッチ処理をはじめとした Google Cloud のハイ パフォーマンス コンピューティング(HPC)機能を利用することで、数千ものプリエンプティブル仮想マシン(PVM)を同時に実行しながら作業を進めることができました。これにより、複雑なシミュレーションの実行にかかる時間が数日から数時間に短縮されています。さらに、シミュレーションが完了したら、その結果は BigQuery を利用して分析できます。
そこから得られる利点は非常に大きなものです。ノースイースタン大学の研究者は、これまでに 900 万種類を超えるモデルを生成し、5,500 テラバイト以上の結果データを分析できました。また、中国国外および国内に患者が流入した場合の相対リスクも評価(Google の無料ツールであるデータポータルを使用して可視化)し、中国本土外での持続的な集団感染リスクを評価したうえで、その知見を『Science』誌上で発表しました。
「COVID-19 の感染拡大と潜在的影響の予測を目的としたデータドリブン モデルの開発は、ウイルス急増に対抗するうえで画期的なことです」と MoBS のアソシエイト研究員 Chinazzi 博士は述べています。
不可欠な研究を継続的に支援
Google は 2,000 万ドル分に相当する Google Cloud クレジットを投入し、COVID-19 対策において研究者の皆様がクラウドを活用できるようにしています。また、このクレジットを効果的に運用するために、Harvard Global Health Institute と連携して有望な研究機会を特定し、それぞれを支援できるように Google Cloud の機能を適用しています。Harvard Global Health Institute は、さまざまな分野の科学アドバイザーで構成されたチームで申請を審査しています。COVID-19 への取り組みを目的として Google Cloud の能力を必要とする研究者は、提案書を Google に直接提出できます。申請は受付順に検討されます。
「可能性のある治療法の発見に迫られている学術研究者にとって、これまで以上に共同作業が重要になっています。COVID-19 に対して世界規模で迅速に対応するために、このような研究者が待ち望んでいたリソースが Google との提携により提供されます」と、Harvard Global Health Institute の Ashish K. Jha 博士は述べています。また、「私たちは、パンデミックの緊急性に対処するために、臨床研究、非臨床科学研究、薬物送達と治療法の研究、医療サービスと政策の研究、疫学的研究など、あらゆる種類の研究方法を考慮しています」と続けています。
Google は、流行のシミュレーションを Google Cloud で日常的に実施しているバージニア大学の Biocomplexity Institute の研究者も支援しています。各シミュレーションの結果は、国や地方公共団体が COVID-19 拡大の追跡や介入効果の評価、介入を緩和する方法と時期の特定、リソースを割り当てる方法と対象の決定を行うためのデータセットとして活用されています。
多数の研究者にデータ分析と機械学習を提供
Google Cloud は研究者の皆様からデータを広範に利用しアクセスしていただけるように、BigQuery で COVID-19 関連のデータセットを無料で照会できる COVID-19 一般公開データセット プログラムを立ち上げました。これには、広く参照されているジョンズ・ホプキンス大学の症例データ(インターネット接続されたシート機能を使用して、ダッシュボードとして Google スプレッドシートで可視化、分析することも可能)だけでなく、アメリカ地域社会調査や OpenStreetMap などの COVID-19 研究で関連性を証明できる可能性があるデータセットも含まれています。さらに、健康の社会的決定要因(SDoH)の新しいデータセットを 7 種類導入し、プログラムで利用できるようにしました。これにより、パンデミックの影響を最も受けやすい米国のコミュニティを特定できます。
この 3 月に、ホワイトハウスとその諮問機関は、新型コロナウイルスに関する文献のコレクションとして機械が読み取れる形式のものでは現時点で最も広範な COVID-19 Open Research Dataset(CORD-19)を検証するために、テキストやデータの新しいマイニング技術を開発するよう AI コミュニティに求めました。Google はその支援のため、データ サイエンティストで構成される Kaggle コミュニティに対して、この取り組みに参加することと、COVID-19 の拡大を予測する別の取り組みにも参加するよう要請しました。機械学習によって選定された文献のレビューなど、このような取り組みによる貢献については、こちらをご覧ください。
創薬研究の取り組みを低コストで加速
COVID-19 について理解を深め、健康とグローバル経済への影響を最小限に抑えるべく、研究者たちは 24 時間体制で作業を続けています。このような作業は、Google Cloud で何万もの仮想マシンに分散させることでモデルと分析を高速化できるため、時間とリソースが大幅に削減されます。Google Cloud プリエンプティブル VM は、このような分散しやすいフォールト トレラントな研究アプリケーションを実行できる効果的な手段です。研究作業の中で計算にかかる時間が短縮され、標準の VM と比較してコストを数分の 1 に削減できます。
Google では、できるだけ多くの COVID-19 関連の研究プロジェクトを促進するという目標を掲げています。その実現に向け、前述の一般的な Cloud クレジットに加え、COVID-19 に対する取り組みを支援するために、プリエンプティブル VM クレジットに 10 億コンピューティング時間を割り当てています。Google は COVID-19 研究の提案書を受け取ると、プリエンプティブル VM を利用して作業を加速およびスケールアップできる方法を研究者と協力して特定します。その例を以下でご紹介します。
米国で新薬を開発するには、通常 20~30 億ドルの費用とおよそ 10 年の時間を要します。ハーバード大学医学部とダナファーバーがん研究所(DFCI)のチームは VirtualFlow を利用して有望な創薬ターゲットを迅速かつ正確に絞り込み、COVID-19 患者の治療法の発見にかかる時間を短縮しています。VirtualFlow は Google Cloud で実行されるスケーラブルなオープンソースの仮想創薬プラットフォームであり、プリエンプティブル VM を利用します。
VirtualFlow を使用すれば SARS-CoV-2 タンパク質に対して数十億の薬剤化合物を数日のうちに標的にできるため、COVID-19 の潜在的な治療法を研究、分析する能力が大幅に向上します。
「私たちが使用している仮想評価手法により、薬剤や治療法の発見に必要な時間が大幅に削減され、疾患の治療法の開発期間が短縮されることが期待されています」と、ハーバード大学医学部の博士研究員 Christoph Gorgulla 氏は述べています。
「SARS-CoV-2 タンパク質に対して利用できる豊富な構造データを活用し、Google Cloud のテクノロジーを使用してウイルス タンパク質の阻害物質を特定しています。Google Cloud で数十万の演算コアを使用すると、10 億の化合物(約 120 億種類の結合事例)をスクリーニングするタスクを数週間で完了できます。この作業を標準的なノートパソコンで完了するには 1,500 年はかかるでしょう」と、ハーバード大学医学部の助教授 Haribabu Arthanari 氏は話しています。
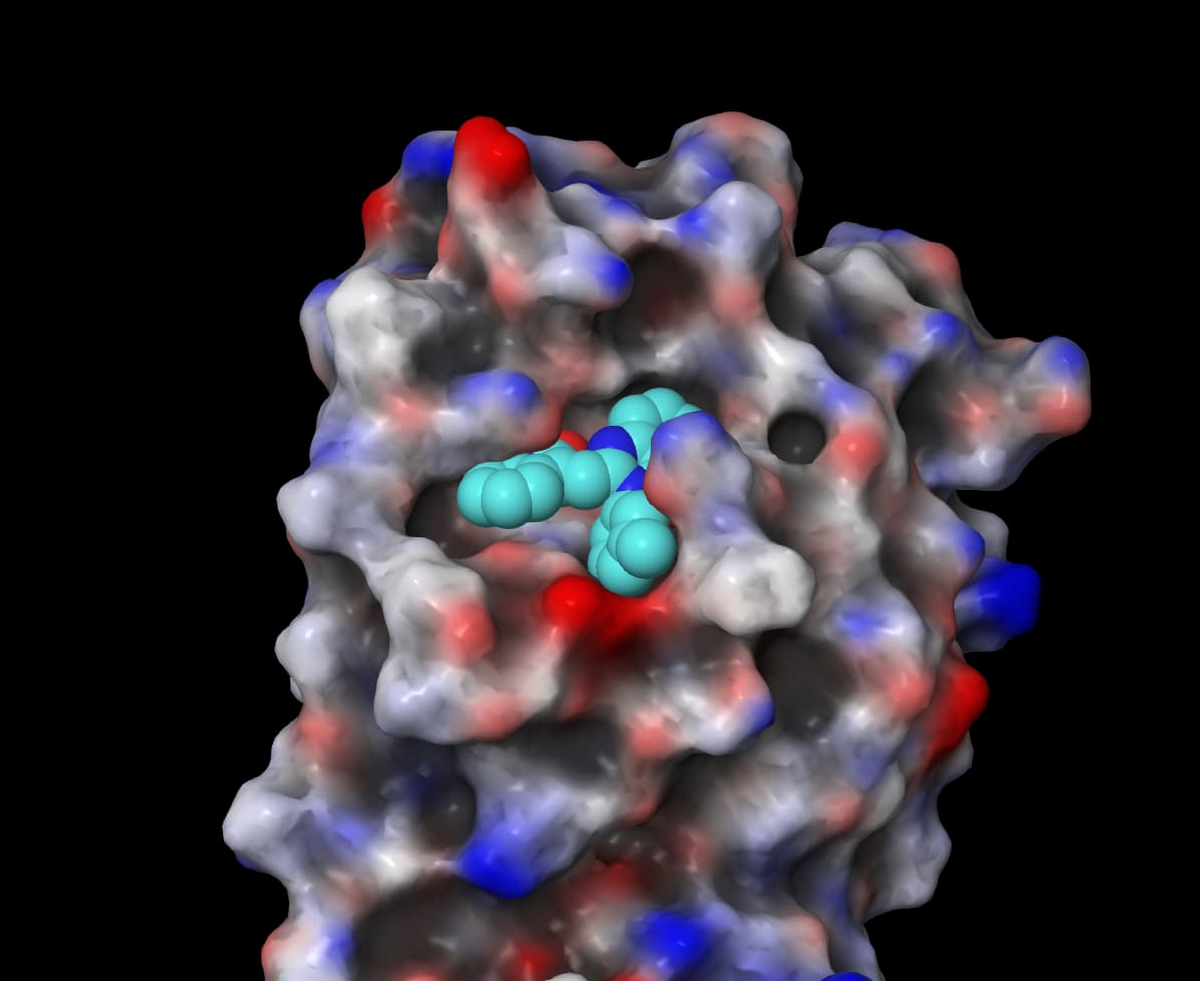
タンパク質活性部位に仮想ヒット化合物をドッキングさせた SARS-CoV-2 メインプロテアーゼ
有望な薬剤化合物の候補リストが特定されたら、ハーバード大学医学部のチームは設備が整っている他の機関の研究者と協力してテストを開始します。VirtualFlow チームは、これと並行して承認済みの薬剤のデータベースに対して追加のスクリーニングを実施し、これらの化合物が含まれているかどうかを確認します。また、ハーバード大学医学部は最も有望な薬剤化合物と照合するために、別の機関と並行して他のさまざまな共同研究も行っているため、作業を迅速に進められます。
データのプライバシーとセキュリティを引き続き優先
データは教育研究や学術研究の土台であり、データのプライバシーとセキュリティは非常に重要です。Google Cloud の信頼に関する原則では、広く認知されている患者のプライバシーとデータのセキュリティに関する慣行に従って Google Cloud のデータが取り扱われることと、Google Cloud を使用する企業や組織が所有データの完全な制御を維持できることを定めています。
教育研究や学術研究の支援に対する Google Cloud の取り組みは、Google が掲げる理念の中核を成すものです。研究者や組織がクラウド テクノロジーを応用して、すべての人にとっての利益を生み出せるよう、お役に立てる方法をこれからも模索して参ります。
- By 医学博士 Joe Corkery, Director of Product, Healthcare & Life Sciences, Google Cloud