Google Cloud VMware Engine のデプロイにかかるコストを最適化する
Google Cloud Japan Team
※この投稿は米国時間 2022 年 1 月 29 日に、Google Cloud blog に投稿されたものの抄訳です。
Google Cloud VMware Engine を使用すると、専用ハードウェアを備えた VMware マネージド環境を数分でデプロイして、ESXi ノードをオンデマンドで柔軟に追加および削除できます。この柔軟性は、コンピューティング容量を必要に応じてすばやく追加する際に特に便利です。ただし、予想外のコスト増に見舞われることのないよう、コスト最適化戦略を実装してプロセスを確認しておくことが重要です。ワークロード容量の増加に対応するには、ESXi クラスタにハードウェアを追加する必要があるため、プライベート クラウドをスケールアウトする場合はさらなる注意が必要となります。
このブログでは、全体的なコストの最適化に重点を置き、Google Cloud VMware Engine プライベート クラウドを運用するためのベスト プラクティスをご紹介します。
Google Cloud VMware Engine の請求について
お客様への料金の請求は、デプロイされている VMware ESXi ノードの数に基づいて時間単位で行われます。仮想マシン インスタンスに対する Compute Engine のコミットメント ベース料金モデルと同様に、Google Cloud VMware Engine は 1 年と 3 年の契約期間について確約利用割引を提供します。料金の詳細については、Google Cloud VMware Engine のプロダクト概要ページの料金セクションをご覧ください。
コスト最適化戦略 1: 確約利用割引を適用する
確約利用割引(CUD)は、特定のリージョンで 1 年または 3 年の期間にわたって一定数の Google Cloud VMware Engine ノードを運用するというコミットメントに基づく割引です。3 年間のコミットメントの CUD では、契約の開始時に費用を全額支払う場合、最大 50% の割引が提供されます。ご想像のとおり、コミットメント ベースの割引を購入後にキャンセルすることはできないため、プライベート クラウドで運用するノードの数が確かなものであることが必要です。Google Cloud VMware Engine がデータセンター移行のターゲット プラットフォームである場合は、1 年または 3 年の期間に運用するノードの最小数にこの割引を適用し、必要なノードの数を定期的に見直してください。
コスト最適化戦略 2: ストレージ消費を最適化する
ワークロード(バックアップ システム、ファイルサーバー、大規模データベースなど)が大量のストレージを消費している場合は、クラスタをスケールアウトして vSAN ストレージ容量を追加する必要が生じることがあります。ストレージ消費量を低く抑えるために、次の最適化戦略を検討してください。
1. 許容障害数(FTT)は同じにしたまま、RAID 1(デフォルト ストレージ ポリシー)ではなく RAID 5 または RAID 6 を使用するカスタム ストレージ ポリシーを適用します。FTT 数は、ESXi クラスタの月間稼働時間に関する SLA に直接関係する重要な指標です。RAID 1 エンコード スキームは冗長性確保のためにデータのブロックをミラーリングするため、RAID 1 を FTT=1 で使用するストレージ ポリシーでは、100% のストレージ オーバーヘッドが発生します。同様に、FTT=2 が必要な場合(たとえば、99.99% の稼働時間の可用性を必要とする重要度の高いワークロードの場合)、RAID 1 は 200% のストレージ オーバーヘッドを生成します。FTT=1 のストレージ ポリシーはわずか 33% のストレージ オーバーヘッドで達成できるため、RAID 5 構成の方がストレージ効率が高くなります。同様に、RAID 6 はわずか 50% のストレージ オーバーヘッドで FTT=2 を提供できます。つまり、RAID 1 でデフォルト ストレージ ポリシーを使用する場合と比べて、ストレージ消費量の 50% を節約できます。ただし、RAID 1 の方がストレージ デバイスへの I/O 操作が少なくて済むため、パフォーマンスの向上につながる可能性があることに注意してください。
2. 「シン プロビジョニング」形式を使用して新しいディスクを作成します。シン プロビジョニング形式のディスクは、小規模で始めて、ディスクに書き込まれるデータの増加に応じて拡張することが可能なため、保存容量の節約につながります。
3. バックアップで vSAN ストレージがいっぱいにならないようにします。Actifio などのバックアップ ツールにより、VMware 環境とクラウド ストレージを統合でき、オペレータはバックアップをより低コストの保存場所に移動できます。長期間保持する必要のあるバックアップ データは、一定の期間が経過したデータをより低コストのストレージ クラスに移動するライフサイクル ポリシーが適用された Cloud Storage バケット内に保存する必要があります。
4. vSAN クラスタで重複除去と圧縮を有効にして、冗長データブロックの量を減らすことで、全体的なストレージ消費量を減らします。
コスト最適化戦略 3: ESXi クラスタを適切なサイズに設定する
1. CPU、メモリ、ストレージの使用率を高く保ちつつも、ワークロードの失敗を招くことなく ESXi ノードの停止に対応できるサイズに ESXi クラスタを設定します。最大容量に近いリソース使用率でクラスタを運用すると、突然ハードウェア障害が発生した場合にサービスが停止する可能性があります。リソース(CPU、メモリ、またはストレージ)使用率指標の上限を約 70% に設定すると、クラスタの安全な運用とクラスタの機能の使用を両立させることができます。
2. 新しいプライベート クラウドのデプロイを単一ノード クラスタで開始して、必要に応じてデプロイを拡張します。Google Cloud VMware Engine は最近、テストと概念実証のための単一ノードからなるプライベート クラウドを作成する機能を追加しました。単一ノード クラスタは最大保持期間が 60 日に限られており、SLA はありません。ただし、運用管理段階のツール、設定、テストとの統合中にコストを最小限に抑えるための優れた手段を提供します。プライベート クラウドのランディング ゾーンの設定が完了したら、1 ノードクラスタを 3 ノードクラスタに拡張して、SLA の対象にすることができます。
3. 可能であれば ESXi クラスタを統合します。複数のクラスタでワークロードを実行している場合は、クラスタを統合することで、クラスタ間でリソースをより効率的に分散させられるかどうかを確認します。たとえば、ワークロードが OS タイプ別または本番環境と非本番環境で分かれている場合は、クラスタを統合することでリソースの使用率が向上する可能性があります。ただし、ライセンス要件など、統合を妨げる他の制約があるかどうかを確認する際には注意が必要です。ライセンス要件を満たすために VM を特定のノードで運用する必要がある場合は、ワークロードを特定のノードに固定する DRS アフィニティ ルールを検討してください。
4. 可能であればプライベート クラウドを統合します。複数のプライベート クラウドを運用している場合は、それらのクラウドを統合できるかどうかを確認してください。プライベート クラウドはそれぞれに独自の管理 VM のセットが必要です。それが原因で、全体的なリソース消費にオーバーヘッドが生じます。
コスト最適化戦略 4: ワークロードのリソース使用率を確認する
1. 定常状態でアプリケーションを実行した後で、VM のリソース使用率を継続的に確認します。vCenter 指標をプログラムで抽出するか視覚的に抽出して、適切なサイズに関する推奨事項を提供します。たとえば、VM が CPU とメモリのリソースを必要以上に消費していることがわかった場合は、アプリケーションの計画的ダウンタイム中に VM パラメータを調整します(再起動が必要です)。
vCenter から CPU とメモリの使用率の統計情報を抽出し、CSV ファイルなどの便利な形式でデータを保存するスクリプトの実行をスケジュール設定することを検討してください。たとえば、この操作は、スクリプト実行ホストから PowerShell を使用して行うことができます。
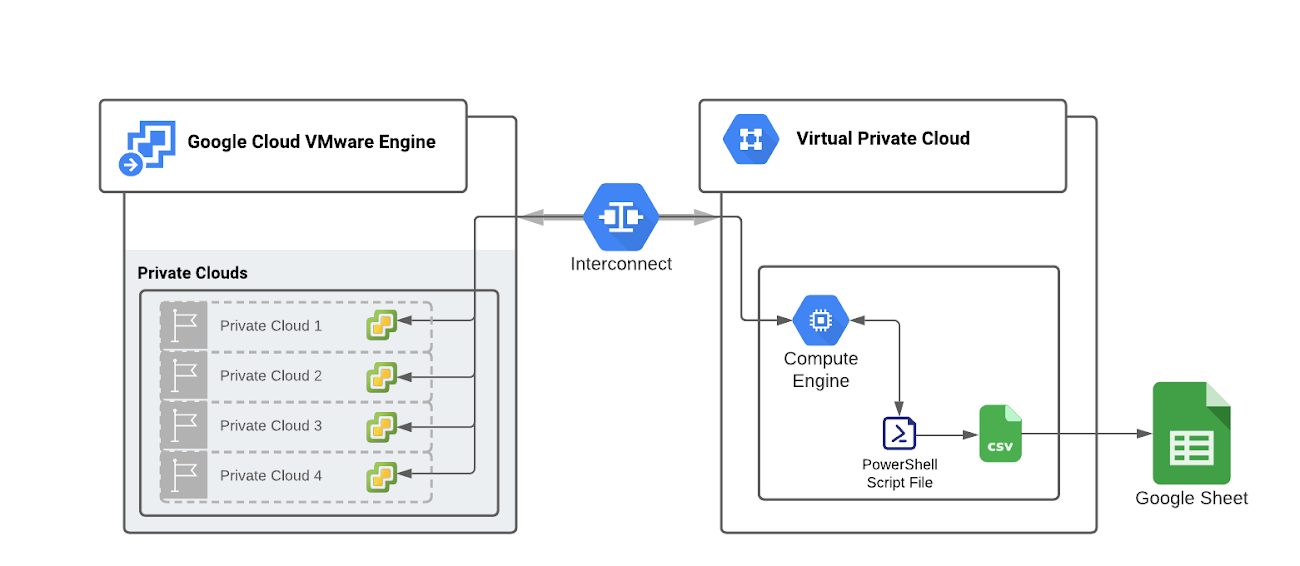
少なくとも 30 日間の CPU およびメモリの平均使用率を妥当なしきい値と比較することにより、過剰に使用されているリソースまたは十分に使用されていないリソースとしてワークロードを分類する基準を定義します。
条件の例(しきい値は要件に合わせて調整可能):
CPU の使用率(30 日間と 1 年間の平均値)が 50% 未満
CPU の使用率(30 日間と 1 年間の最大値)が 80% 未満
上記の推奨事項を使用する場合でも、突然の変更は避け、データをワークロードの要件に照らして常に精査してください。
2. Cloud Monitoring とスタンドアロン エージェントの統合を使用して、クラスタとワークロードの指標を確認します。インストール ガイドに沿って指標転送を有効にして、vCenter 指標を Cloud Monitoring と統合します。
3. VMware vROps などのサードパーティ製ツールを使用して容量と使用率に関する分析情報を得て、ワークロードが CPU / メモリバウンドである場合の適切なサイズ設定に役立てることを検討します(詳細はブログ投稿を参照)。vROps には追加のライセンスが必要であり、VM やホストごとに vROps をインストールする必要があることに注意してください。
コスト最適化の管理 - 人員とプロセス
コスト最適化の有効性は、オペレーションをサポートし、実施する人員とプロセスの準備状況にも左右されます。
1. コスト最適化の役割を設定する - どのクラウド運用モデルにおいても、コストの管理と最適化は単一チームの責任ではなく、複数のチームや役割による協調的な取り組みが必要です。最適化を共通の最優先事項とし、Cloud Center of Excellence(CoE)、財務(最適化目標の定義と支出のモニタリング)、アーキテクチャ(最適化オプションの評価)、運用 / SRE(オプションの実行)の各チーム内にコスト最適化の中心的な役割を確立するには、経営幹部からの支援とサポートが必要です。また、ワークロードに対する可用性とパフォーマンスの影響を検証できるよう、ビジネスやアプリケーションの関係者を関与させます。
2. 簡単なことから着手し、徐々に範囲を拡大する - コスト最適化は継続的な取り組みであり、企業のクラウド導入成熟度曲線をたどります。補助的なプロセスとツールを定義することから始めて、規模の拡大に応じて改良を加えます。
3. 最適化オプションに優先順位を付ける - 最適化は大幅なコスト削減をもたらしうる反面、リソースを投じるべき労力と時間の面で犠牲を伴います。コスト節約の可能性と推定される労力レベルに基づいてオプションに優先順位を付け、コスト削減と短期的な成果達成に最も効果的な方法を特定してください。
4. レポートを作成し、成果を測定する - 関心のある主要な指標(ユーザー / テナント顧客あたりのコストなど)を特定し、KPI を定義して、最適化の成果と達成状況を継続的に測定します。
財務アカウンタビリティを果たし、ビジネス価値を実現するための包括的なフレームワークについては、Cloud FinOps に関するホワイトペーパーをご確認ください。また、ツールとコスト最適化のベスト プラクティスに関する追加のガイダンスについては、クラウドコスト最適化の原則に関するブログをご覧ください。
次のステップ
このブログでは、実装にかかる労力がそれぞれ異なるプライベート クラウドの全体的なコストを削減する戦略をいくつかご紹介しました。短期間でコスト削減を達成できる戦略の例としては、CUD の使用(特に、VMware Engine をワークロード用プラットフォームとして少なくとも 1 年間使用する場合)のほか、全体的な vSAN ストレージ消費を最適化するカスタム ストレージ ポリシーが挙げられます。
クラスタと VM の使用率指標をモニタリングするプロセスの導入を含んだ最適化戦略は、ワークロードのサイズが過大であるかどうかに関する有益な分析情報を提供します。ただし、ワークロードのサイズ設定は性急に行うべきではなく、定常状態での指標を注意深く評価することが必要です。このようにして行ったコスト最適化は、長期的な視点で効果をもたらします。
Google Cloud は、クラウドへの移行から最大の価値を引き出すと同時に、Google Cloud VMware Engine の導入とコストの最適化を支援するアーキテクチャ フレームワークを開発しました。詳細にご興味がありましたら、Google Cloud のアカウント担当者までお問い合わせください。
このブログ投稿に協力し、企業のお客様を対象としたコスト最適化プロセスの実装を支援してくれた Wayne Chu に感謝いたします。
- テクニカル アカウント マネージャー Rachith Kavi


