Optimize the cost of your Google Cloud VMware Engine deployments
Konrad Schieban
Strategic Cloud Engineer, Google Cloud Professional Services
Rachith Kavi
Technical Account Manager
Google Cloud VMware Engine allows you to deploy a managed VMware environment with dedicated hardware in minutes with the flexibility to add and remove ESXi nodes on-demand. This flexibility is particularly convenient to quickly add compute capacity as needed. However, it is important to implement cost optimization strategies and review processes such that increased cost does not come as a surprise. Since hardware needs to be added to ESXi clusters to accomodate for increased workload capacity, additional care needs to be taken when scaling out the Private Clouds.
In this blog, we explore best practices for operating Google Cloud VMware Engine Private Clouds with a focus on optimizing overall cost.
Google Cloud VMware Engine Billing Principles
Customers are billed hourly by the number of VMware ESXi nodes that have been deployed. Similar to the commitment-based pricing model that Compute Engine offers for Virtual Machine instances, Google Cloud VMware Engine offers committed use discounts for one and three-year terms. For detailed pricing information refer to the pricing section on the Google Cloud VMware Engine Product Overview page.
Cost Optimization Strategy #1: Apply Committed Use Discounts
Committed Use Discounts (CUDs) are discounts based on a commitment to running a number of Google Cloud VMware Engine nodes in a particular region for either a one- or three-year term. CUDs for a three-year commitment can provide up to a 50% discount if their cost is invoiced in full at the start of the contract. As you might expect, commitment-based discounts cannot be canceled once purchased so you need confidence in how many nodes you will run in your Private Cloud. Apply this discount for the minimal amount of nodes you will run over a one- or three-year period and revise the number of needed nodes regularly if Google Cloud VMware Engine is the target platform of your data center migration.
Cost Optimization Strategy #2: Optimize your Storage Consumption
If your workloads consume a lot of storage (e.g. backup systems, file servers or large databases), you may need to scale out the cluster to add additional vSAN storage capacity. Consider the following optimization strategies to keep storage consumption low:
1. Apply custom storage policies which use RAID 5 or RAID 6 rather than RAID 1 (default storage policy) while achieving the same Failures to Tolerance (FTT). The FTT number is a key metric as it is directly linked to the monthly uptime SLA of the ESXi cluster. A storage policy using RAID 1 with FTT=1 incurs a 100% storage overhead since a RAID 1 encoding scheme mirrors blocks of data for redundancy. Similarly, if FTT=2 is required (e.g. for more critical workloads that require a 99.99% uptime availability) RAID 1 produces a 200% storage overhead. A RAID 5 configuration is more storage efficient, as a storage policy with FTT=1 can be achieved with only a 33% storage overhead. Likewise, RAID 6 can provide FTT=2 with only 50% storage overhead which means 50% of storage consumption can be saved compared to using the default storage policy with RAID 1. Note, however, that there is a tradeoff: RAID 1 requires fewer I/O operations to the storage devices and may provide better performance.
2. Create new disks using the “Thin Provisioning” format. Thin provisioned disks save storage space as they start small and expand as more data is written to the disk.
3. Avoid Backups filling up vSAN storage. Backup tools such as Actifio provide integrations of VMware environments and Cloud Storage allowing operators to move backups to a cheaper storage location. Backup data which needs to be retained long-term should be stored inside Cloud Storage buckets with life-cycle policies to move data to a cheaper storage class after a certain time period.
4. Enable deduplication and compression on the vSAN cluster to reduce the amount of redundant data blocks and hence the overall storage consumption.
Cost Optimization Strategy #3: Rightsize ESXi Clusters
1. Size ESXi clusters such that CPU, Memory and storage utilization are at a high level but support the outage of an ESXi node without any failure of workloads. Operating a cluster with resource utilization close to full capacity might cause an outage in case of a sudden hardware failure. Having the highest resource utilization metric (CPU, Memory or Storage) at approximately 70% allows a safe operation of the cluster while also using the capabilities of the cluster.
2. Start new Private Cloud deployments with single-node clusters and expand them when needed. Google Cloud VMware Engine has recently added the ability to create private clouds that contain a single node for testing and proofs of concept. Single node clusters can only be kept for a maximum of 60 days and do not have any SLA. However, they provide a great method to minimize cost during the integration with day-2 tooling, configurations and testing. Once the Private Cloud landing zone is fully configured, the one-node cluster can be extended to a three-node cluster to be eligible for an SLA.
3. Consolidate ESXi clusters if possible: If you are running workloads on multiple clusters, review if clusters can be consolidated for a more efficient balancing of resources across clusters. As an example, if workloads are divided by OS type or by production and non-production, a higher resource utilization may be achieved if clusters are consolidated. However, there should be care taken in reviewing whether there are other constraints which would prevent consolidation, such as licensing requirements. If VMs need to run on specific nodes for licensing requirements, consider DRS Affinity rules to pin workloads to specific nodes.
4. Consolidate Private Clouds if possible: Review if Private Clouds can be consolidated if you run more than one. Each Private Cloud requires its own set of management VMs which causes an overhead to the overall resource consumption.
Cost Optimization Strategy #4: Review Resource Utilization of Workloads
1. Review the resource utilization of VMs on an on-going basis after running applications in a steady state. Extract vCenter metrics programmatically or visually to provide right-sizing recommendations. For instance, if it is noticed that VMs consume more CPU and memory resources than needed, tune the VM parameters during a scheduled downtime of the application (requires reboot).
Consider scheduling the execution of a script which extracts CPU and memory utilization statistics from vCenter and stores the data in a convenient format such as in a CSV file. As an example, this can be implemented using PowerShell from a script execution host.
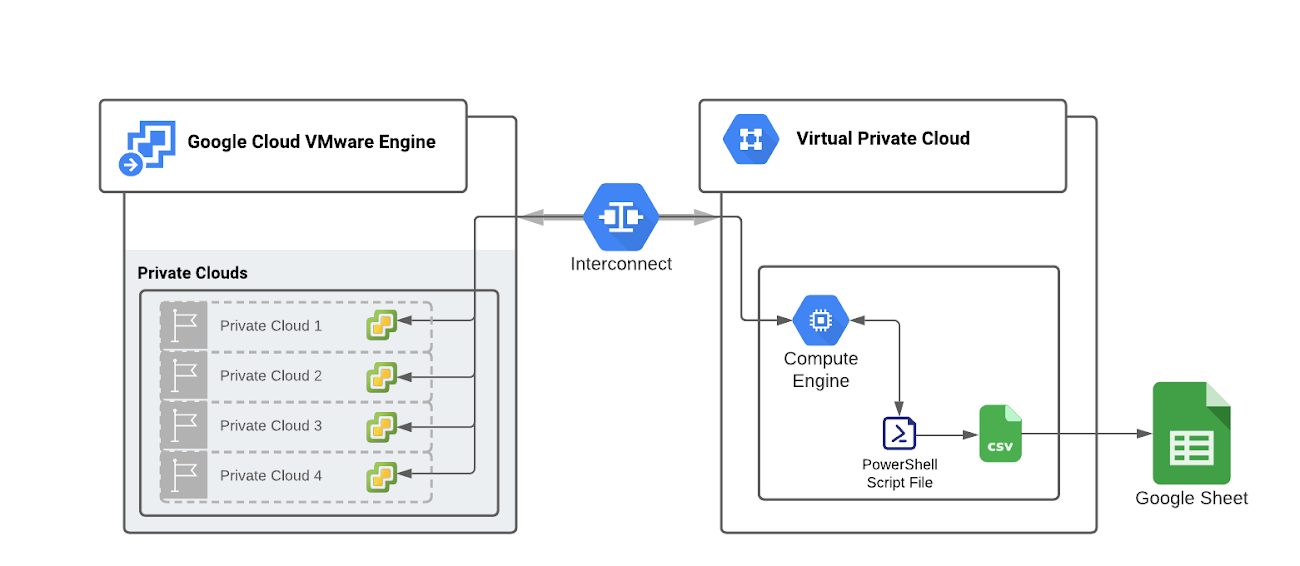
Define criteria to characterize workloads as over- or underutilized resources by comparing their average CPU and memory utilization over a minimum of 30 days with a reasonable threshold value.
Example conditions (thresholds can be tuned to meet your requirements):
CPU Usage (30-day and 1-year average) % is less than (<) 50%, and
CPU Usage (30-day and 1-year maximum) % is less than (<) 80%
Despite the above recommendations, avoid making abrupt changes and always carefully review the data against the requirements of the workloads.
2. Use Cloud Monitoring with the Standalone agent integration to review cluster and workloads metrics. Follow the installation guide to enable metrics forwarding to integrate vCenter metrics with Cloud Monitoring.
3. Consider using third-party tooling, such as VMware vROps, to get insights into the capacity and utilization to help with right-sizing if the workload is CPU/memory bound (blog post for more details). Note that vROps requires additional license and needs to be installed on a per VM/host.
Managing Cost Optimization - People and Process
The efficacy of cost optimization hinges also on the people and processes readiness to support and run the operations.
1. Set up a cost optimization function - In any cloud operating model, cost management and optimization is not a responsibility of a single team but requires a coordinated effort from multiple teams/roles. Sponsorship and support from executive leadership is needed to make optimization a shared top priority and build a central cost optimization function within your Cloud Center of Excellence (CoE), Finance (for defining optimization goals and monitoring spend), Architecture (for reviewing optimization options) and Operations/SRE (for implementing the options). Additionally, engage business/application stakeholders for validating availability and performance impact on workloads.
2. Adopt a crawl-walk-run approach - Cost optimization is a continuous and ongoing operation and follows an enterprise’s cloud adoption maturity curve. Define supporting processes and tools as you start and refine them as you scale.
3. Prioritize the optimization options - While optimization can bring in significant cost savings, it comes at a cost of resource effort and time. Prioritize your options based on the potential savings vs estimated level of effort to identify the most impactful ways to reduce spend and realize quick wins.
4. Report and measure - Identify key metrics of interest (e.g. cost per user / tenant-customer) and define KPIs to continuously measure optimization outcomes and success against them.
Refer to our Cloud FinOps whitepaper for a holistic framework on driving financial accountability and business value realization. Also check the principles of cloud cost optimization blog for additional guidance on tools and cost optimization best practices.
Call to Action
In this blog we have listed several strategies to reduce the overall cost of Private Clouds which differ in their implementation effort. Quick wins that can be implemented to reduce cost in the short-term include the use of CUDs, specifically if VMware Engine will be used as a platform for workloads for at least one year, as well as custom storage policies to optimize overall vSAN storage consumption.
Optimization strategies which include the adoption of processes to monitor utilization metrics of clusters and VMs provide helpful insights on whether workloads are oversized. Yet, adjustments to workload sizing should not be made swiftly and require careful review of metrics in a steady state. This cost optimization does rather take effect in a longer term.
At Google Cloud, we have developed an architecture framework to help you optimize your spend and adopt Google Cloud VMware Engine while maximizing your returns on your journey to cloud. If you are interested in more information, please contact your Google Cloud account team.
A special thanks to Wayne Chu for his contributions and help with the implementation of cost optimization processes with our enterprise customers.

