SAP HANA: メモリエラーの影響に対するソリューション

Google Cloud Japan Team
※この投稿は米国時間 2021 年 9 月 4 日に、Google Cloud blog に投稿されたものの抄訳です。
どのクラウド システムも、高品質のハードウェア インフラストラクチャがなければ始まりません。しかし、ときにはハードウェアが故障することもあります。そのような場合、お客様とお客様のクラウド ワークロードへの影響を最小限に抑えることが、Google の最も重要な目標となります。
メモリエラーは、ハードウェア障害の中で最も一般的なものであると同時に、本番環境のワークロードやシステムの信頼性への影響という点で特に対応が難しいエラーでもあります。そこで、メモリエラーの影響を最小限に抑えるために Google Cloud が取り組んできたことをご紹介します。SAP HANA をクラウドで運用している企業にとって、これは重要なイノベーションです。Google Cloud は誇りを持ってこれをお客様に提供しています。
メモリエラー: 長い歴史を持つ大きな問題
まず何をおいても強調しておきたいのは、メモリエラーは頻繁に発生するため、優先度の高い問題であるということです。メモリエラーが発生すると、お客様やビジネスの広範囲にわたって影響が及ぶ可能性があります。
2009 年、Google Cloud は、メモリの信頼性に関する初めての大規模調査を発表しました。その調査で、本番システムに導入されている DIMM モジュールの年間平均エラー率が、8% を超えていることがわかりました。DDR RAM が世代を重ねるたび、パッケージは小さくなり、詰め込まれる容量は増えていることを考えると、当時よりメモリ ハードウェアの信頼性は低下していると考えてよいでしょう。
メモリエラーの影響: 抑えられてはいるものの、まだまだ問題あり
システムで DIMM モジュールの不良セグメントが検出されるとどうなるでしょうか?メモリエラーでデータの損失や破損が生じることはあまりありませんが、エラーの中には訂正可能なものとそうでないものがあり、重大なシステム障害を引き起こす可能性もあります。
最近の CPU はエラー訂正メモリ機能を備えており、単純なエラーの多くを誤り訂正符号(ECC)で訂正することができます。課題は、ハイパーバイザ、仮想マシン、オペレーティング システム、データベース、アプリケーションなど、ホストシステム上で動作するソフトウェアのほとんどが、訂正不能なメモリエラーに遭遇すると即座にクラッシュしてしまうことです。クラウド環境では、このようなクラッシュにより、キャッシュ データだけでなく、ローカルの SSD に保存されているデータまで消えてしまう場合があります。クラッシュしたアプリケーションは復旧しますが、その処理のために数分のダウンタイムが発生します。データが多ければ多いほど、この処理には時間がかかります。
これは単に不便なだけの場合もあれば、非常に大きな問題となる場合もあります。ビジネス クリティカルな SAP アプリケーションやインメモリ HANA データベースを運用している Google Cloud のお客様の場合、収益の損失やその他の直接的な影響によるダウンタイムのコストが 1 分あたり 10,000 ドルをはるかに超えることも考えられます。多くの HANA データベースはテラバイト単位のメモリにロードされるため、クラッシュ後にすべてを再起動して正常な状態に戻すには 1 時間以上かかる場合があります。SAP HANA の場合、最長 10 分のダウンタイムで高速復旧するには、プロビジョニングされた冗長レプリカが常に必要となるため、コストが倍増します。
また、統計的に見て、HANA インスタンスがホストシステム上のメモリをほぼ占有している場合、メモリエラーに遭遇する可能性が最も高いアプリケーションにもなります。これが問題を引き起こすことは明らかです。
VM の「被害者の隣人」問題
メモリエラーにより本番環境のアプリケーションが停止した場合に、最後に検討すべき問題があります。私たちはこの問題を「被害者の隣人」と呼んでいます。
どのクラウドでも、単一の物理ホストがマルチテナント環境になっています。マルチテナント環境では、多数の VM が運用されている場合があります。また、これらの VM は多数の異なるお客様が所有している可能性があります。メモリエラーは、実際に不良箇所を使用している VM をクラッシュさせるだけでなく、システム上で動作しているすべての VM をクラッシュさせます。これは、ホストシステム上のメモリエラーに対する VM の標準的な反応です。メモリ破損を回避するため、今日の市場で利用可能な、どの VM アーキテクチャでも発生します。
全体として、物理サーバー上のメモリエラーによりダウンする VM の 90% 以上は、この「被害者の隣人」効果によるものです。よくある問題とはいえ、影響する範囲は非常に大きいのです。
メモリエラーの影響に対する実用的なソリューション
この問題の対処が、Google Cloud にとって重要であることがおわかりいただけたと思います。避けようのない障害もあることはわかっていますが、Google はこの問題に対処する別の方法を開発しました。Google Cloud には、ライブ マイグレーションなど、役に立つ独自ツールがすでに用意されており、予期せぬダウンタイムをお客様が最小限に抑えられるようにしています。これらのツールと、CPU(Intel 提供)や特定のアプリケーション(特に SAP HANA)に組み込まれたエラー処理機能を活用した最近の取り組みを統合すると、メモリエラーに関連するダウンタイムや混乱を大幅に削減するソリューションとなります。多くの場合、お客様は問題があったことにすら気付きません。
Google Cloud ソリューション: メモリ ポイズニングからの回復
大局的なレベルでは、私たちはこのソリューションをメモリ ポイズニングからの回復(MPR)と呼んでいます。このソリューションは、Google Cloud の既存機能と新機能、CPU(Intel)およびアプリケーション(SAP HANA)レベルの重要なサードパーティ機能を組み合わせたものです。MPR は主に 2 つのプロセスに分けられます。
メモリエラーの隔離
ステップ 1: VM テクノロジーを強化し、メモリエラーに対してより強固なものにしました。システムから送られてくるメモリエラーをインターセプトして分析し、訂正不能なエラーが発生したメモリ DIMM の信号領域に「重大エラー発生」フラグを立てます。
ステップ 2: 次に、これらの重大なエラーが発生した領域とその領域が影響する VM を追跡するプロセスを起動し、データの整合性に影響が及ばないようにします。
メモリエラーの回復
ステップ 3: メモリエラーが記録されたことをゲスト OS と MCE 対応アプリケーションに通知し、それぞれに適したメモリエラー処理を各アプリケーションが実行できるようにします。
ステップ 4: 同時に、Google Cloud ライブ マイグレーションと通信し、影響を受けたホストからゲスト VM を移動させます。これにより、お客様の環境は正常なホストで運用されることになり、訂正不能なエラーがさらに発生する可能性を低下させ、ダウンタイムの増加を回避できます。
下の図は、この仕組みを簡単に表したものです。
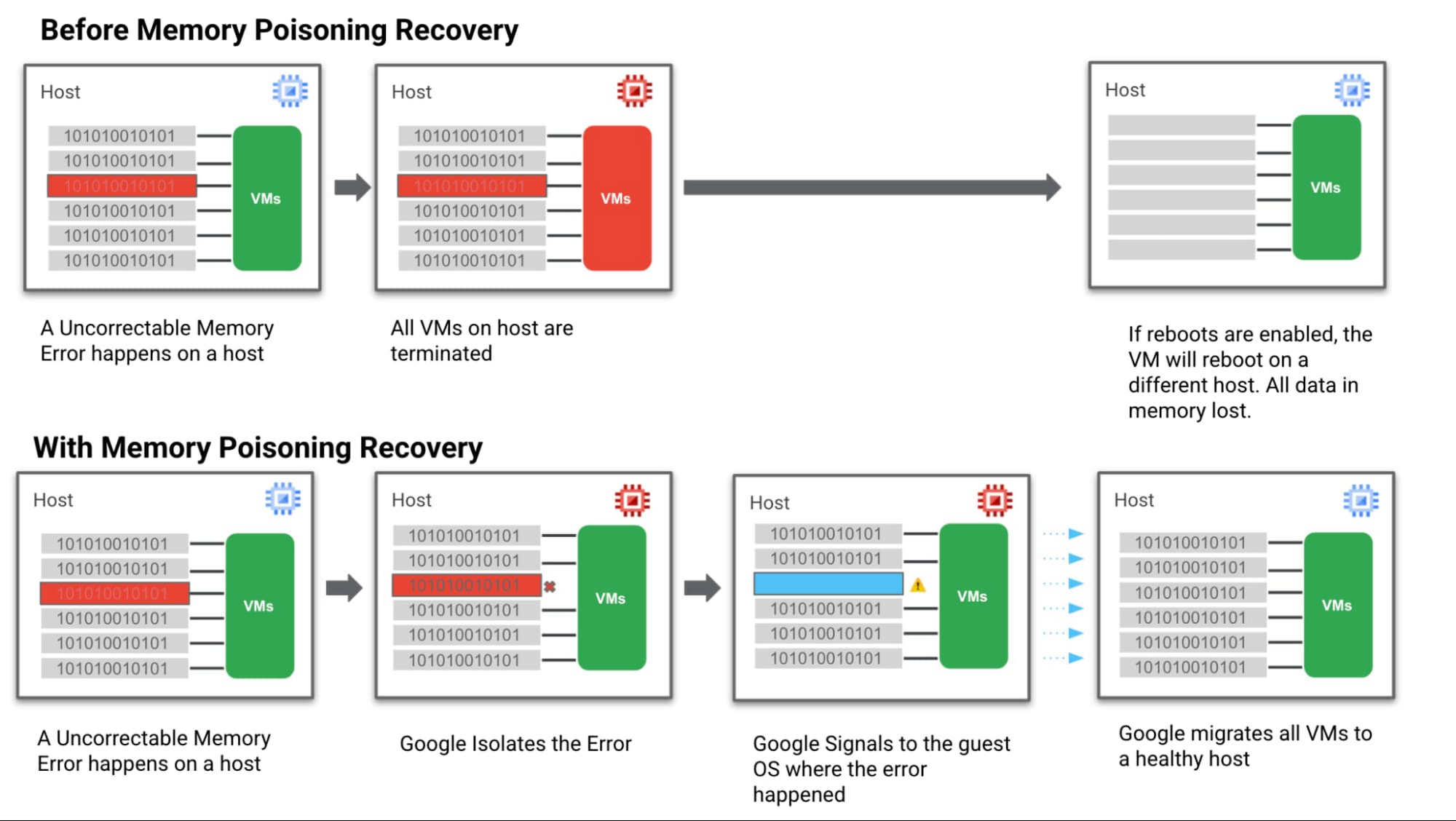
MPR によるお客様環境の改善
メモリエラーに巻き込まれた Google Cloud のさまざまなお客様のグループと、より望ましい解決を実現するためにクラッシュ後に Google がどのような支援を行うかについて、もう一度考えてみましょう。まずは、実際にメモリエラーを引き起こした VM やアプリケーションを実行しているお客様からです。
お客様のグループ: メモリエラーの影響を直接受けた VM 上で MCE 対応の SAP HANA を運用し、高速再起動を有効にしているお客様

お客様のグループ: メモリエラーの影響を直接受けた VM 上で、他の MCE 非対応アプリケーションを実行しているお客様

次に、「被害者の隣人」グループは、おそらくホストシステムに問題があったことさえ気付かないでしょう。Google Cloud ライブ マイグレーションは、彼らを瞬時に新しいホストへ自動的に移動させ、クラッシュと再起動が生じないようにします。
お客様のグループ: メモリエラーの影響を直接受けていない VM 上で、他のなんらかのアプリケーションを実行しているお客様

MPR を利用するための簡単なステップ
Google の MPR 機能は、2021 年の第 4 四半期に Google Cloud のメモリ最適化 Compute Engine 第 2 世代のインスタンスで利用可能になります。今後数か月の間に、その他のインスタンスにもこの機能を展開し、MCE 対応アーキテクチャを採用するアプリケーションと連携する新たな方法を模索していきます。
「被害者の隣人」カテゴリのお客様のほとんどは、何もしなくてもその恩恵を受けられます。ライブ マイグレーション機能と MCE のシグナル認識を連携させることにより、ゲスト VM に問題が発生する前にアラームを受け取り、移行プロセスを速やかに開始できます。お客様は安全に新しいホストへ移動し、アプリケーションを稼働させ続けられます。
HANA を運用している SAP のお客様にとって、MPR とは損失からの保護を意味します。HANA 環境の予期しないダウンタイム コストはきわめて高額で、ハード クラッシュからの復旧プロセスには非常に長い時間がかかり、ビジネスの中断は実際にビジネスに大きなダメージを与える可能性があります。しかし、MPR を活用すれば、そのようなコストや懸念はほとんどゼロに圧縮されます。高速再起動により、1 時間以上かかるダウンタイムが数秒に短縮されます。
ただし、SAP のお客様がこうしたメリットを享受するには、重要な第一歩を踏み出す必要があります。高速再起動は MPR ソリューションの重要な要素ですが、デフォルトでは有効化されていません。SAP HANA インスタンスを高速再起動用に設定するには、構成設定をいくつか変更する必要があります。このプロセスは迅速かつ簡単で、リスクを伴いません。
最後に、SAP やその他のワークロードを Google Cloud で運用していないのであれば、あらゆる規模や業種の企業で発生するハードウェアの信頼性の問題が軽減されるという、クラウドで運用することのメリットを検討してみてください。また、ライブ マイグレーションなどのツールの価値も考慮してください。これらのツールは、Google Cloud のお客様が稼働時間を向上させ、リスクを軽減するのにすでに役立っています。
ハードウェアに障害はつきものであり、今後もなくなることはないでしょう。しかし、メモリ障害が発生するとたいてい起きる悪い事態を回避することの重要性は、私たちが証明しています。今のところ、この非常に難しい問題に対する実用的なソリューションを用意しているのは Google Cloud だけです。
SAP HANA の高速再起動、ライブ マイグレーション、その他の SAP 環境向け Google Cloud 主要機能についてもご確認ください。
-Google Cloud テクニカル プログラム マネージャー Abdelkader Sellami
-Google Cloud プロダクト マネージャー Eddie DeJesus


