SAP HANA: A solution to memory error impacts

Abdelkader Sellami
Technical Program Manager, Google Cloud
Eddie DeJesus
Product Manager, Google Cloud
Try Google Cloud
Start building on Google Cloud with $300 in free credits and 20+ always free products.
Free trialEvery cloud system begins with high-quality hardware infrastructure. Sometimes, however, hardware breaks — and when it happens, our most important goal is to minimize the impact on our customers and their cloud workloads.
Memory errors are the most common type of hardware failure, and they're also one of the most challenging in terms of their impact on production workloads and system reliability. That's why we're excited to share what Google Cloud has been doing to minimize the impact of memory errors. If your business runs SAP HANA in the cloud, this is an important innovation — one that Google Cloud is proud to deliver to our customers.
Memory errors: A big problem with a long history
First things first: Memory errors are a high priority because they happen often. And when they happen, the disruption can have far-reaching effects on your customers and your business.
In 2009, Google Cloud published the first major study on memory reliability. We found an average error rate of over 8% per year in DIMM modules installed in production systems. Given that each generation of DDR RAM packs more capacity into smaller packages, it’s safe to think that memory hardware has become less reliable since then.
Memory error impacts: They could be worse, but they're far from good
What happens when a system detects a bad segment in a DIMM module? While data loss or corruption from memory errors is not common, some errors are correctable but some are not, potentially resulting in a critical system failure..
Modern CPUs are equipped with error-correcting memory features and are very good at correcting simple errors with ECC (Error Correction Code). The challenge is that most of the software that runs on a host system — whether it's a hypervisor, a virtual machine, an operating system, a database or an application — will crash instantly when it encounters an uncorrectable memory error. In a cloud environment, this kind of crash can take down cached data and even data saved to a local SSD. The crashed applications will recover, but the process means several minutes of downtime. The more data you have, the longer this process will take.
Sometimes, that's merely an inconvenience. Other times, it's a very big deal. A Google Cloud customer running business-critical SAP applications and an in-memory HANA database might measure downtime costs well over $10,000 per minute in lost revenue and other direct impacts. Many HANA databases load into terabytes of memory, and it can take an hour or longer to get everything restarted and back to normal after a crash. For SAP HANA, a fast recovery with up to 10 minutes of downtime requires a redundant replica provisioned all the time, doubling the cost.
And statistically speaking, when a HANA instance occupies almost all of the memory on a host system, it's also the most likely application to stumble across a memory error. You can see why this would be a problem.
The 'victim neighbor' VM challenge
There's a final problem to consider when a memory error takes out production applications: what we call the "victim neighbor" issue.
In any cloud, a single physical host is a multi-tenant environment that might run dozens of VMs, potentially owned by dozens of different customers. A memory error won't just crash the VM actually using the bad section, it will crash every VM running on the system. That's a standard VM response to memory errors on a host system, and it will happen to any VM architecture available on the market today to avoid memory corruption.
Overall, this "victim neighbor" effect accounts for more than 90% of the VMs that get knocked down by a memory error on a physical server. That's a huge blast radius for such a common problem.
A practical solution to memory-error impacts
You can see why managing this problem is a big deal for Google Cloud. While we know that some failures are inevitable, we have developed another way to tackle the problem. Google Cloud already maintains some unique and valuable tools, such as Live Migration, that help our customers minimize unplanned downtime.When we integrate these tools with recent work that leverages error-handling capabilities built into CPUs (courtesy of Intel) and into certain applications (in particular, SAP HANA), we get a solution that dramatically reduces downtime and disruptions related to memory errors — in many cases, to the point where customers won't even know there was a problem.
The Google Cloud solution: Memory poisoning recovery
At a big picture level, we refer to our solution as Memory Poisoning Recovery (MPR). It combines some existing Google Cloud capabilities, some new capabilities, and some important third-party capabilities at the CPU (Intel) and application (SAP HANA) levels. MPR can be broken down into two main processes:
Memory Error Isolation
- Step 1: We hardened our VM technology to be more robust against memory errors. We intercept and analyse the memory error coming from the system. Then we flag the signaled region of a memory DIMM with an uncorrectable error as “poisoned”.
- Step 2: Then we trigger processes to keep track of these “poisoned” regions and the VMs they affect so they can't affect data integrity.
Memory Error Recovery
- Step 3: Then we notify the Guest OS & the MCE-aware applications that a memory error has been recorded, in a manner that allows the applications to execute application relevant memory error handling.
- Step 4: At the same time we communicate with Google Cloud Live Migration to begin moving guest VMs off the affected host. This ensures customers are running on a healthy host which reduces the probability of more uncorrectable errors happening and avoids further downtime.
Below is a simple visual of how this all works:
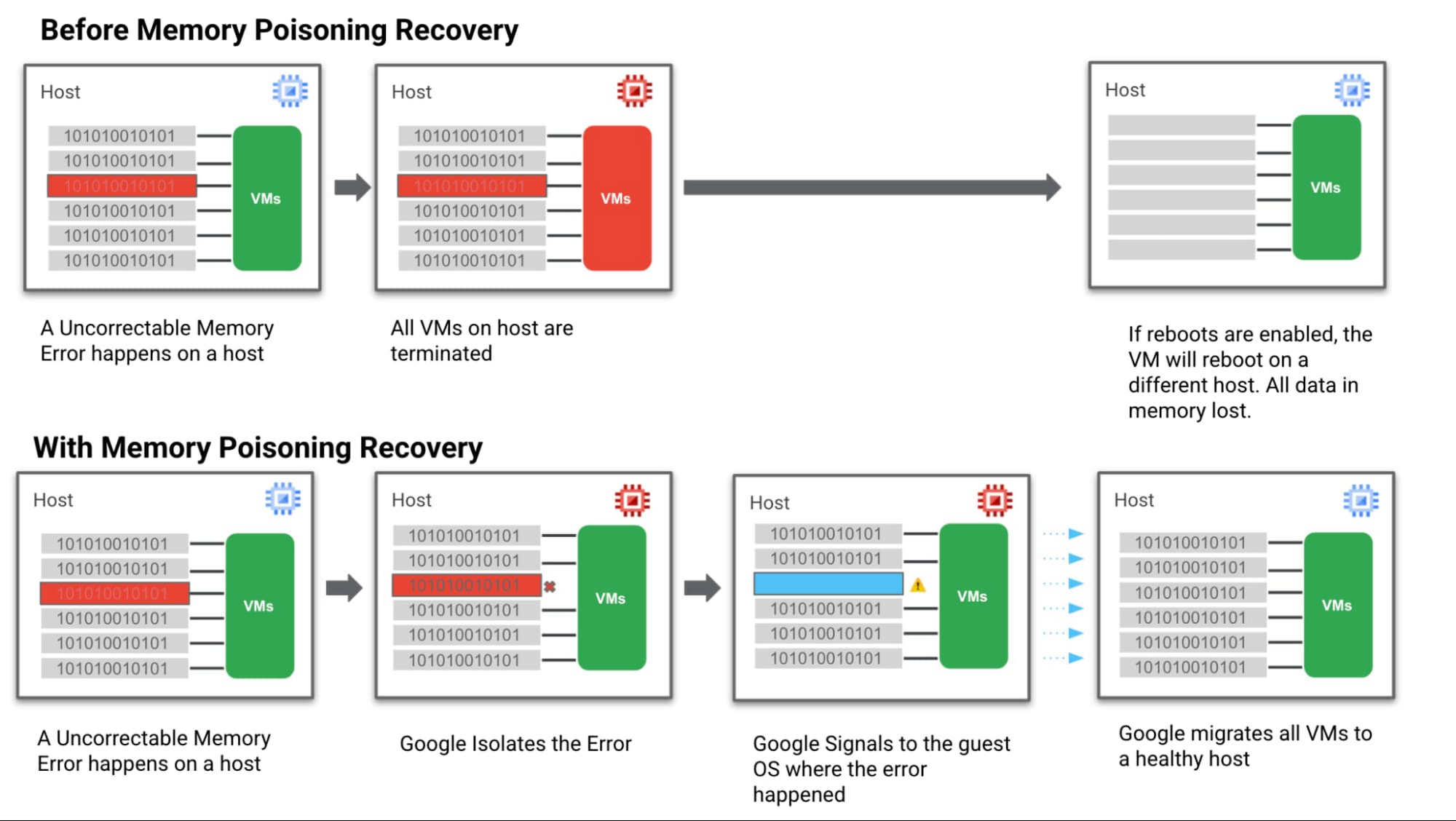
How MPR makes life better for customers
Let's look again at the different groups of Google Cloud customers involved in a memory error scenario and how we can help them achieve a happier ending after a crash — starting with the customer running the VM and application that actually triggered the memory error.
Customer Group: MCE-Aware SAP HANA with Fast Restart enabled on a VM directly affected by a memory error.

Customer Group: Customers running other, non MCE Aware applications on a VM directly affected by a memory error

Next, our "victim neighbors" group probably won't even know there was a problem with the host system. Google Cloud Live Migration will move them to a new host, instantly and automatically, and avoid the crash-and-restart scenario.
Customer Group: Customers running other, any application on a VM not directly affected by a memory error

Simple steps for taking advantage of MPR
Our MPR capabilities will be available on our Google Cloud memory-optimized Compute Engine second generation instances in Q4 of 2021. We'll continue to roll out the capability during the months ahead to additional instances and look for new ways to work with applications that adopt a MCE Aware architecture.
Most customers in the "victim neighbor" category will not need to lift a finger to experience the benefits. By marrying our Live Migration feature to some awareness of those MCE signals, we ensure that it hears the alarm first and gets a critical head start on the migration process before issues begin with the guest VMs. Our customers land safely on a new host, and their applications keep running.
For our SAP customers running HANA, MPR is all about protecting against loss. Unplanned downtime for a HANA environment is incredibly expensive, the recovery process from a hard crash is extremely long, and the business disruptions can be truly damaging to the business. Thanks to MPR, all of that cost and worry can get compressed almost to nothing — with Fast Restart reducing what can be an hour or more of downtime to a matter of seconds.
But our SAP customers have to take a critical first step to claim these benefits. Fast Restart is a crucial piece of the MPR solution, and it is not enabled by default. Configuring your SAP HANA instance for Fast Restart involves changing a few configuration settings; the process is fast, easy, and doesn't involve risk.
Finally, if you're not running your workloads — SAP or otherwise — on Google Cloud, consider the benefits of running on a cloud that mitigates a hardware reliability issue affecting businesses of every size and industry. And consider the value of tools like Live Migration that already help Google Cloud customers improve uptime and reduce risk.
Hardware failures happen, and they probably always will. But we're proving how valuable it can be to avoid the bad things that usually happen when memory failures occur. Right now, only Google Cloud has a practical solution to this very difficult problem.
Learn more about Fast Restart for SAP HANA, Live Migration and other key Google Cloud capabilities for your SAP environment.



