Google Cloud での効果的なアラート
Google Cloud Japan Team
※この投稿は米国時間 2023 年 9 月 7 日に、Google Cloud blog に投稿されたものの抄訳です。
エンジニアリング組織には、技術的な問題をすばやく特定して解決することが求められます。しかしこのニーズは、他の優先事項に比べて後回しにされがちです。追跡すべきものが多すぎて、どれがアラートを必要とするか判断しにくいのです。アラートを設定しすぎるとノイズが多くなり、現実の問題に直面したときに関連性の高いものがわからなくなる可能性があります。そのため、アラートを作成する理由を、次の 2 つの点から明確にする必要があります。
モニタリングしている内容とビジネスの目標との関連性
問題があることを知らせることで得られる成果
モニタリングしている内容の関連性を理解することで、事前の優先順位付けが促進されます。問題が発生した場合、ユーザーへの影響、潜在的な費用、他のどの問題を優先するかを判断できるだけのコンテキストが必要になります。関連性はまた、目標設定の根拠になるシグナルを特定するのにも有効です。たとえば、レイテンシは、リアルタイム データを提供する顧客向けアプリケーションでは非常に重要ですが、システム全体で古いファイルをクリーンアップする毎週の cron ジョブには無関係です。コンテキストに基づく関連性は、アラートの理由、内容、タイミングを判断する一助となります。
アラート通知に期待する結果は、即時の対応から状況認識までさまざまです。自動化で解決できるような些細な問題のために、オンコール エンジニアを起こすべきではありません。また、重要度の高い問題を見逃す可能性があるため、アラートをメールの中に埋もれさせてしまうのもよくありません。Google では、誰にどのようにアラートすべきかを判断できるように、期待する結果と影響の重大度を決定しています。
一部の事象に対してのみアラートを作成しなければならない理由
何かのアラートを作成する場合には、通知されれば誰かがそれに対処できる、またそうすべきであるという前提があります。
日常生活で遭遇しそうなアラートについて考えてみましょう。
スマートフォンに表示される鉄砲水警報
クレジット カード決済の不承認に関するテキスト メッセージ
「新しいデバイスからのログイン」に関するメール
これらのアラートはそれぞれウェブサイトやログに存在する可能性がありますが、それぞれのアラートについて直接通知を受け取ることができます。また、次のような指示を受けることもよくあります。
道路を避け、自宅にとどまり、非常持ち出し袋を準備する
取引を行うつもりであったことに同意し、再試行するか、詐欺として報告する
新しいデバイスを信頼するか、アクセスをブロックして直ちにパスワードを変更する
場合によっては、アラートが無関係だと感じたり、すでに問題に気づいていたりしても、アラートが常時オンになっていることに価値を置くことがあります。また、取引が行われた店舗名を調べる、あるいは、デバイスが使用しているものと一致するかどうかを確認するなど、さらに深く調べる必要がある場合にも、アラートは良い出発点になります。
多くの指標にアラートを出すというゾンビ戦略をとると、重要な問題が目立たなくなる可能性があります。ことわざにあるように、「すべてが重要であれば、何も重要ではなくなる」のです。
自分の住んでいる地域だけでなく、地球上のすべての鉄砲水警報が届くことを想像してみてください。取引だけでなく、自分が興味を持ちそうな新しいタイプのクレジット カードを銀行が提供するたびにテキスト メッセージを受け取るとしたらどうでしょうか。同じデバイスからログインしても、そのたびにメールが届くというケースも考えられます。こんな状態では、関連性の高いアラートも見逃してしまいます。それでなくても、ノイズで常に注意が削がれます。
物事を修正し、それに影響を与え、制御できる限り、またアラートを知らないことが悪い結果を招く可能性がある限り、アラートは設定するべきです。それが出発点になります。とはいえ、まずはさまざまな選択肢を絞り込んで、何にアラートを発するべきかを考えなければなりません。
アラートすべき対象
どんなに自動化を進めたとしても、常に注目すべきはユーザーとの関連性です。「原因ではなく症状に注目する理由」では、原因よりもユーザーが直面している症状に注意を払うほうがアラートの焦点として適している理由を説明しました。
ユーザーにとって対応可能で関連性のあるものをアラートの対象にすべきです。SRE ハンドブックでは、ユーザーがシステムに期待する事項に基づいて、ユーザーにとって重要なサービスレベル指標の例を示しています。注目すべき SLI を以下にいくつか示します。
利用状況。500 件、意図しない 400 件、ハングアップしたリクエスト、悪意のあるサイトへのリダイレクトなど、どれも重要です。サイト全体であれ、小さなサードパーティ コンポーネントであれ、クリティカル ユーザー ジャーニーを中断させるものはすべて、「利用不能」と考えるべきです。
レイテンシ。高速であること(待機しているのが人間である限り)。
完全性 / 耐久性。データは常に安全でなければなりません。データが一時的に利用できなくなったとしても、復旧したときには正しいデータになっている必要があります。
各 SLI に個別の目標を設定する、つまり「SLO」を設定するには、ユーザーがサービスの低下に気づき始める、あるいは約束されたものを得られていないと感じ始めるしきい値を想定することになります。SLO 設定のプロセスを標準化するには、ユーザー ジャーニーをモデル化し、各インタラクションの重要性を評価する必要があります。
ユーザーが感じる「症状」を発端として、アラートを発する必要のある「原因」がシステム内に残っていることに気づく場合があります。これはスタックの奥深くにある先行指標であり、その動作はユーザーには見えないかもしれませんが、今後ユーザーに影響を与える可能性があるものです。
理想的には、これらの問題への対応を自動化できる状態にします。アラートの目標を設定するための効果的な方法は、「SLO のみに基づいてアラートするには何が必要か?」という問いから始めることです。それに続くギャップ分析では、システムが脆弱すぎる箇所や、対応するための手作業が多すぎて組織的なプロセスが不十分である箇所が明らかになります。
SLO を設定する時間がない場合
SLO の設定や重要な指標の詳細な分析には、特にサービスがすでに複雑な場合、時間と組織の成熟度を要します。アラートとダッシュボードの出発点を見つけやすくするために、Cloud Monitoring には、50 以上のオブザーバビリティ バンドルを備えたインテグレーション ポータルがあります。これらのバンドルには、人気の Google Cloud サービスやサードパーティ サービスを使い始めるための、上位の指標、サンプル アラート ポリシー、サンプル ダッシュボードが含まれています。
これを出発点にして、チームはニーズに合わせてアラート トリガーを構成し、順次アラートを拡張していくことができます。
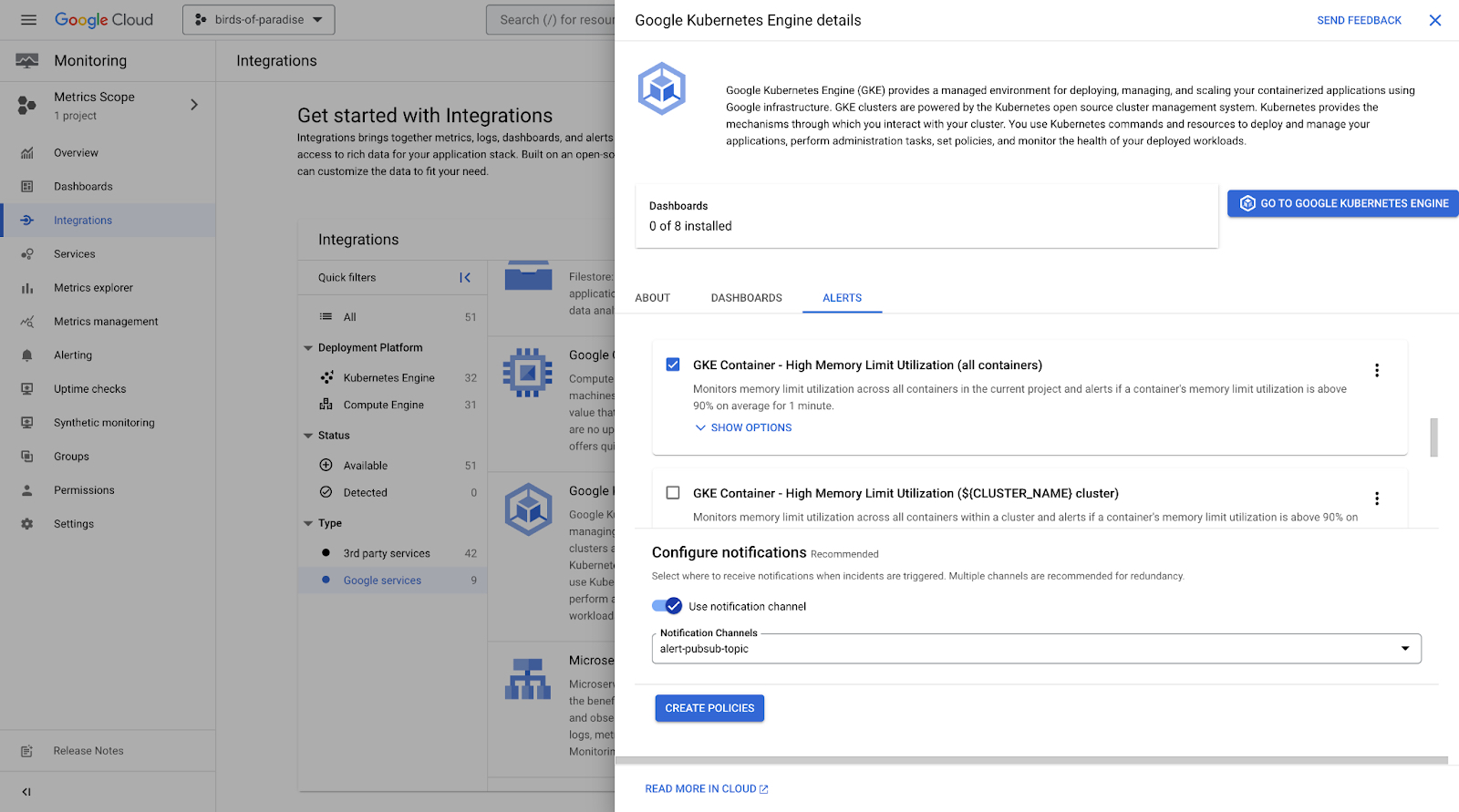
忘れてはならない重要な経験則は、アラートはアクションや調査の「始まり」にすぎず、戦略全体を形成するものではないということです。必ずしもすべての指標に、対応するアラートが必要なわけではありません。システムが成長し、自動化が進むと、より多くのモニタリングが行われ、アラートの対象が少なくなるのが通常です。
Google Cloud の指標ベースとログベースのアラート
トップレベルの指標を選択する基準がわかったところで、実際にどのようにしてシステムから指標を収集すればよいのでしょうか。また Google Cloud では、指標はどのような形式になっているのでしょうか。
指標ベースのアラートは、指標がしきい値を超えるとトリガーされます。たとえば、特定のインスタンスの CPU 使用率が 80% を超えたときにトリガーされる指標ベースのアラートを作成できます。指標ベースのアラートは、エラー メッセージが表示された回数など、ログから得られる指標にも適用できます。
一方、ログベースのアラートは、特定のメッセージがログに 1 回でも表示されるとトリガーされます。たとえば、特定のサービスのログに「エラー: データベース接続に失敗しました」というメッセージが表示されたときにトリガーされるログベースのアラートを作成できます。
指標とログから最も関連性の高いインジケーターを見つけたら、アラートをトリガーするしきい値を決定する必要があります。
アラートをトリガーするタイミング
すべての問題が同じ影響を与えるわけではなく、多くの場合、影響は時間経過や強度によって変化します。このため、チームはアラートをトリガーするタイミングのしきい値を選択して調整できる必要があります。またさまざまな重大度に基づいて、同じシグナルに対して複数のポリシーを作成することもできます。
問題の期間と範囲は影響度に影響を与えます。このため、アラート ポリシーは、問題が影響を与えるとチームが判断した「範囲の広さ」または「期間」に合わせて設定する必要があります(ちなみに、このタイプの推定はまさに SLO の設計と調整に必要なものです)。
たとえば、インスタンスの CPU 使用率についてアラートする場合、使用率が 80% を超えたインスタンスすべてについてアラートを出すのか、あるいは特定のゾーンの平均使用率が 80% を超えた場合にアラートを出すのかなどです。前者の場合はそれぞれの VM ごとにアラートがトリガーされるため、何百ものアラートが発生する可能性があります。後者では、広範囲に及ぶ問題に対して 1 つのアラートが出されます。アラートの数を統合するには、アラート ポリシーに「グループ条件」を追加します。ドキュメントのステップ 3.d をご覧ください。
数秒間、500 件のエラーが急増したとします。この場合、異常について調査する意義はあるかもしれませんが、エラー率が数分間続く場合よりも重大度は低くなります。時間枠に基づいてポリシーを設定することで、時間経過に伴う影響を示すことができます。そこから、1 分というわずかな継続時間に対しては「警告」アラート ポリシーを、5 分以上の継続時間に対しては「重大」アラート ポリシーを設定したい場合、それぞれ定義された時間枠を持つ 2 つの個別のポリシーを作成し、それぞれに異なる重大度レベルを適用します。
アラートは、一旦事態が発生すると対処が非常に困難な状況に対する早期警告となる、先行指標として機能する場合もあります。たとえば、クラウド サービスの割り当て消費量をモニタリングする場合、サービスが最大使用量に近づいていることを事前に把握し、お客様が手動で上限の引き上げをリクエストできるようにする必要がありますが、この承認には時間がかかる場合があり、自動化することもできません。
発生する可能性がある問題や現在進行中の問題については直接的な介入が必要ですが、すでに発生している問題については、調査が必要になるかもしれません。介入の緊急性についてあらかじめ考えておくことで、優先順位付けのための適切なしきい値を設定できます。それによって、差し迫った問題が、多数の小さなノイズのような問題で覆い隠されることを回避できます。
通知する相手と手段
どのように堅牢な自動化システムであっても、やはりアラートを送信しなければならない場面もあります。そのような状況では、問題についてのコンテキストが多いほど良い結果が得られます。アラート ポリシーを作成するときは、[ドキュメント] セクションを使用して、社内ハンドブックや Google Cloud ランディング ページ、オンコール担当者が調査を開始するためのその他のリンクや、コンテキストに関連するラベルを追加できます。
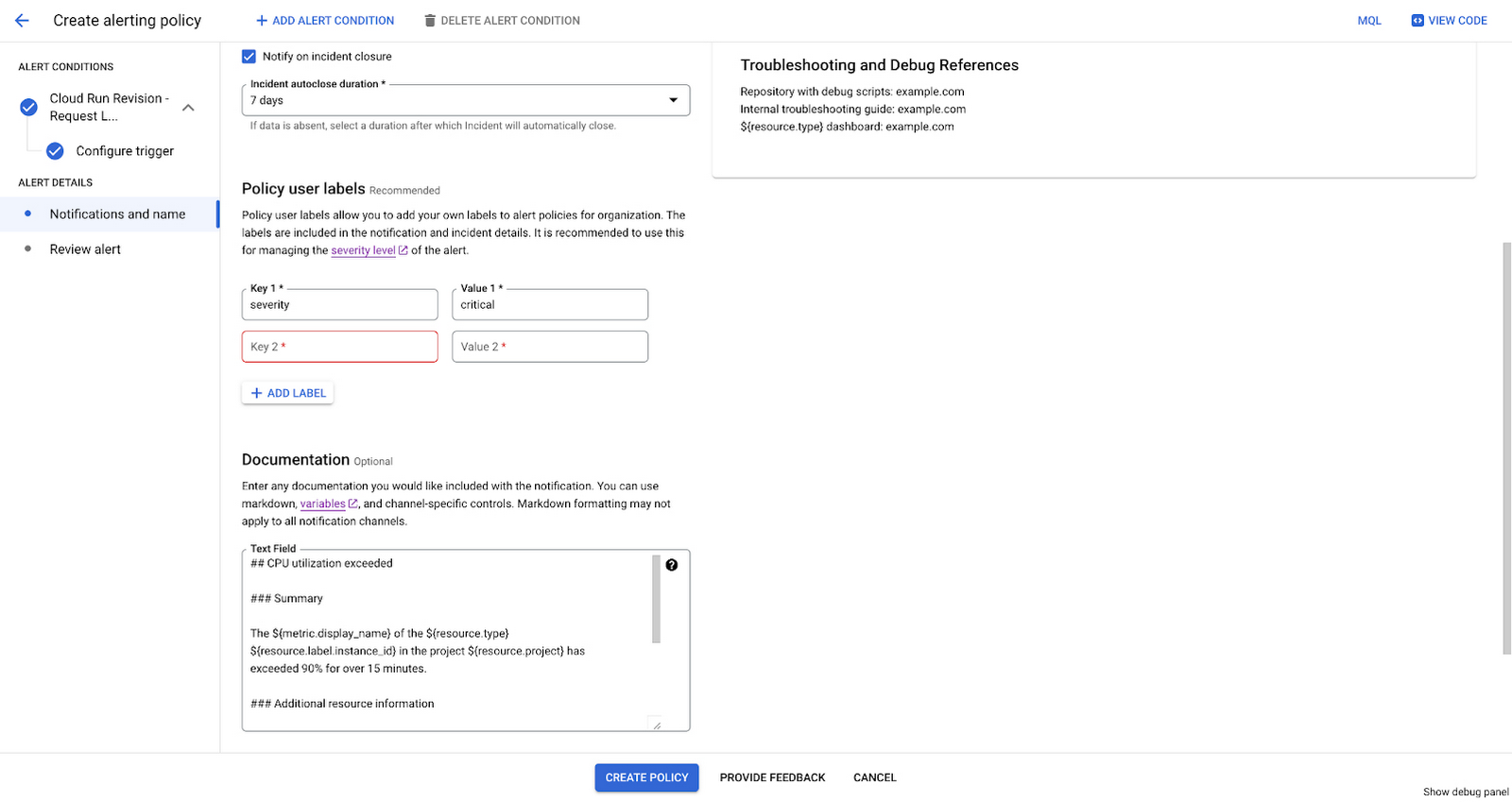
問題を把握する必要がある人を特定したら、通知方法を決定できます。Google Cloud では、通知チャンネルの使用に加えて、サードパーティ統合のために、任意のパブリック エンドポイントに通知を送信する Webhooks と任意のプライベート エンドポイント用の Pub/Sub を提供しています。サードパーティ ツールとの統合。
たとえば、緊急な問題の場合は、SMS またはサードパーティのページング ツールを使用して、担当者に直接通知する必要があるかもしれません。問題は重要であるものの緊急性が低い場合は、サードパーティ ツールを使用してチケットを作成し、キューに入れることが可能です。さまざまなチャンネルを使用することは単純すぎるように思えるかもしれませんが、よくある問題は、緊急度や重大度のレベルにかかわらず、通知チャンネルを 1 つしか使用しないことなのです。たとえ小さな問題でも、毎回緊急の通知を受け取っていると、チームはストレスを感じたり鈍感になったりし、その結果、次第に優先順位から注意がそれてしまいます。
グループメール(クラウド割り当て消費量のデフォルトになりがち)など、優先度の低いチャンネルにアラートが送信されると、手遅れになってからしかアラートに気づかないかもしれません。問題が発生していることを知る必要がある人にのみ通知し、他の人に知らせるかどうかはその人の裁量に任せましょう。多少の計画が必要かもしれませんが、目的は、無関係な通知をスパムのように人々に送信するのを避けることです。さまざまなチャンネルにより、優先順位付けと適切な可視化が可能になります。
緊急の問題を解決できるのがオンコール担当者しかいない場合は、その担当者に電話をかける必要があります。オンコール担当者だけでは解決できない緊急事態は多いため、オンコール担当者への連絡は緊急エスカレーションの第一歩にすぎません(インシデント管理に関する具体的な問題と例については、こちらをご覧ください)。問題が重大でない場合、アラートはキューにチケットを生成します。オンコール担当者は、「中断」としてではなく、引き続きその作業に取り組めます。
最終ガイドライン
アラートの関連性と意図した結果を確立し、簡単な経験則を使用して高い信号対雑音比を維持することで、アラートを最大限に活用できます。
アラートすべき内容:
アラートは運用チームにとって実用的であり、エンドユーザーに関連するものである必要があります。
成熟した運用チームの場合は、SLO でのアラートに移行します。
モニタリングを開始するには、インテグレーション ページにあるアラート、ダッシュボード、指標の「すぐに使用できるパッケージ」を参照してください。
アラートはアクションまたは調査の「開始点」であり、モニタリング対象のごく一部にすぎない場合があります。
アラート ポリシーの目的の粒度を確認します。どのレベルでシステムが影響を受けると考えるか。違反しているインスタンスごとか、すべてのインスタンスの平均か。
アラートをトリガーするタイミング:
アラートが問題の先行指標か遅行指標かを判断します。影響は時間の経過とともに変化することを考慮してください。
変化のキーポイントを反映するしきい値を選択します。この時点以降、ユーザーに何か問題が発生していますか。チームが介入するのに十分な時間はありますか。
必要に応じて、しきい値を同じ指標に対して異なる重大度レベルに分割します。影響、必要な対応時間、リスクをどの程度軽減し、許容するか(SLO のエラー バジェットなど)に関する仮定に基づいて、しきい値を選択します。
アラートする相手と手段:
対応する予定の人にのみ通知し、必要に応じてさらに多くの人に通知してくれると通知相手を信頼します。
オンコール チームが調査を開始できるように、ドキュメント セクションにプレイブックとラベルを追加します。
緊急対応が必要な状況であれば、特定の通知チャンネルまたはサードパーティ ツールを使用して、オンコール担当者に直接通知します。
緊急性の低い問題については、アラート疲れを軽減するため、直接通知の代わりに別のチャンネルまたはサードパーティのチケット発行システムを使用します。
使ってみる
プロジェクトでアラートを開始するには、Google Cloud コンソールの [アラート] にアクセスしてください。
アラートの設定方法に関する入門ガイドについては、以下を参照してください。
* アラート: Pub/Sub トピックへの稼働時間チェック
* アラート: Pub/Sub トピックへのログベース エラー
この記事のガイドラインが効果的なアラートの作成に役立った場合、またはご質問がある場合は、次回の信頼性エンジニアリング ディスカッションにご参加ください。
- Cloud Operations アドボケイトAron Eidelman
- プロダクト マネージャーAlisa Goldstein


