メンテナンスの時間枠がエラー バジェットに与える影響 - SRE のヒント
Google Cloud Japan Team
※この投稿は米国時間 2020 年 6 月 23 日に、Google Cloud blog に投稿されたものの抄訳です。
サイト信頼性エンジニアリング(SRE)の仕事を始めたとします。サービスを開設しました。ユーザーがこのサービスをどのように利用するかについてすでに分析していたので、ユーザーの満足度と相互に関連する主な指標を策定できました。サービスレベル目標を設定したので、エラー バジェットも指定したことになります。よくできました。
次に検討すべきことは、サービスを停止させるメンテナンスの時間枠のスケジュールを管理することです。このダウンタイムをエラー バジェットの対象とする必要があるでしょうか。分析してみましょう。
エラー バジェット
簡単に言うと、エラー バジェットは、ユーザーが不満を感じ始めるまでの一定の期間にサービスで累積できるエラーの量です。これをユーザーの忍耐度と考えることができますが、可用性やレイテンシなどサービスの特定のディメンションに適用されます。
SLI の定義に関する Google のおすすめの方法に沿うと、多くの場合、次のような SLI 計算式を使用することになります。
これによって SLI はパーセンテージで表されます。これらの SLI ごとに目標を定義する、つまりサービスレベル目標(SLO)を定義すると、100 からの余りがエラー バジェットになります。
次に例を示します。ホームページの可用性を測定するとします。可用性は、エラーで終了したリクエスト数をホームページが受信した有効なリクエスト総数で割って測定し、パーセンテージで表されます。例えばその可用性の目標を 99.9% に設定すると、エラー バジェットは 0.1% になります。これにより、エラーが 0.1% に達するまで(0.1% より少な目が望ましい)エラーが許容され、ユーザーに不満なくサービスの利用を続けてもらえます。
目標の値を選択することは、エンジニアリング上の意思決定だけでなく、多くの関係者の意見を基に下したビジネス上の意思決定でもあることを忘れないでください。この選択には、ユーザーの行動の分析、ビジネスニーズ、プロダクトのロードマップが必要です。
メンテナンスの時間枠
SRE の実践環境では、メンテナンスの時間枠は、技術スタッフが前もって計画する時間帯で、サービスを中断させる可能性のある予防的なメンテナンスはこの間に実施されます。
メンテナンスの時間枠は、従来からサービス プロバイダによってさまざまなアクティビティの実施に利用されています。システムによっては、均質な環境を維持する必要があります。たとえば、複数のターミナルのオペレーティング システムを一括で更新する必要がある場合などです。互換性のない API や ABI の変更を伴う更新が必要な場合もあります。金融関連のソリューションによっては、データベース サーバーとクライアント ソフトウェアのバージョンの互換性を確保する必要がある、つまりソフトウェアのメジャー アップグレードにおいて、同時にすべてのシステムのアップグレードが必要なものもあります。メンテナンスの時間枠の従来からの利用例としては他にも、データベースの移行時に、このダウンタイム中に古いリリースと新しいリリースでデータテーブルを同期させる、パソコンのシャットダウン時にデバイスを物理的に再配置するための物理的な移動を行うなどがあります。
SLO を決定するのと同様に、メンテナンスの時間枠のスケジュール設定は、ユーザーとの契約(ある場合)、システムの技術上の制限事項、システムを担当するスタッフの快適性を考慮する必要のあるビジネス上の意思決定です。これには必然的に調整が必要になります。
この投稿の残りの部分で説明しているメンテナンスの時間枠は、サービス プロバイダが実施でき、ユーザーに直接影響を与え、実質上サービスのパフォーマンスを低下させ、サービスを完全に停止させることもあるタイプのものです。
メンテナンスの時間枠を選択する方法
近年は、マルチスレッド プロセッサ、仮想化、コンテナ化などのテクノロジーが注目されています。こういったテクノロジーをマイクロサービス アーキテクチャや優れたソフトウェア開発のプラクティスと組み合わせて利用すれば、メンテナンスの時間枠の利用を軽減するか、完全になくすことさえできます。
ところが、ほとんどすべてのビジネス オーナーやプロダクト マネージャーがダウンタイムの最小化に取り組みながらも、それが不可能である場合もあります。従来のソフトウェアの使用、ビジネスに適用される規制、サービスのメンテナンスの最善の方法が定期的にスケジュールされたダウンタイムであると意思決定者が信じている環境で働くことが、一定の期間にサービスを停止させることを余儀なくしているのです。
こういった状況では、メンテナンスの時間枠はエラー バジェットにどのような影響を与えるでしょうか。メンテナンスの時間枠が必要なシナリオをいくつか分析してみましょう。
営業時間
ウォール街の取引所のような、マーケットで取引の時間帯にサービスを提供している会社で働いているとします。サービスは毎日午前 9 時 30 分に稼動を開始し、午後 4 時ちょうどに終了します。開始と終了のいずれにも遅れは許されません。
この場合、1 日に約 15 時間のメンテナンスの時間枠があるとみなすことができます。これでエラー バジェットを使い切ってしまうのでしょうか。
そこで、エラー バジェットの目的を思い出しましょう。エラー バジェットは、指定した期間にユーザーに不便を強いているかどうかを基準として、使用シナリオの信頼性指標(SLI)を策定するときに使用できるツールです。
このシナリオでは、ユーザーは営業時間外にサービスを利用することはできません。実際には、ユーザーはサービスを利用してはいけない可能性が高いです。このため、実質的に、このサービスの停止ではユーザーには何の不便もなく、この時間帯ではエラー バジェットには何の影響もありません。
エラー バジェットの使用は両刃の剣
別のタイプのサービスについて考えてみましょう。きわめて局所的で、1 か国のユーザーのみに提供されるサービスです。1 つの小さな地域だけに展開されている小売企業を思い浮かべてください。ここで提供するサービスのトラフィック パターンは次のとおりです。
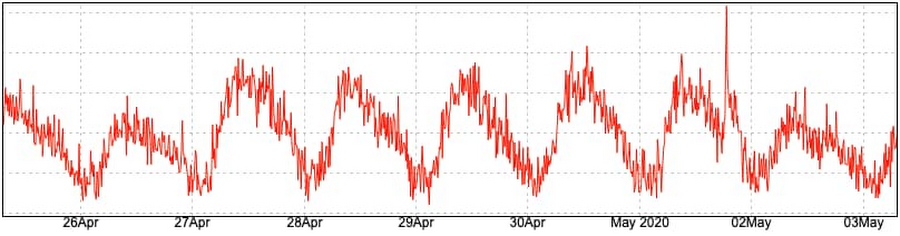
ユーザーが眠っている時間などトラフィックが少ない時間帯は簡単に識別できますが、そのような谷間の時間帯でも受信するリクエストが完全にゼロになることはありません。この谷間の時間帯にメンテナンスの時間枠を計画すると、エラーからの回復に十分な時間を当てることができますが、メンテナンスの時間が超過すると、トラフィックが上昇する時間帯に入ってしまうリスクがあります。
こういった両刃の剣のケースのために、次のようないくつかの戦略を分析してみます。
トラフィックの予測
このアプローチでは、過去のデータを確認して、以前のトラフィックの分析と、受信が見込まれるトラフィック量の計算により、サービスが使用不可になる時間帯に受信することが見込まれる有効なトラフィックの量を推定します。処理対象のデータが限定されている場合でも、収集したあらゆるデータを使用して、トラフィック パターンを算出します。
ここで留意しておくべき重要な要素が、このアプローチは過去のパフォーマンスに基づいているため、予期せぬイベントは考慮されないことです。ダウンタイム期間にサイトで受信するトラフィックが通常の範囲を超えていないことを確認できるように、受信リクエストを記録してすべてのトラフィック(ディープリンクを含む)をメンテナンス ページにリダイレクトするキャプティブ ポータルを設定します。これらの受信リクエストから簡単にトラフィックのログを分析して、有効なトラフィックをカウントできます。このようにして、実際のトラフィックではなく、トラフィック パターンを測定します。このパターンを、妥当な乗数を使用して実際に受信を逃したトラフィックに関連付けると、サービス提供におけるエラー数を計算できるため、消費するエラー バジェットを算出できます。
メンテナンスをダウンタイムとして扱う
サービスの可用性に関連付けられているエラー バジェットを使い切る場合は通常、サービスで生じるエラー数をカウントすることで、消費しているエラー バジェットを測定できます。ただし、サービスが停止している場合は、SLO で許可されている合計ダウンタイムに対してサービスが停止している時間を割合で表すことで、消費しているエラー バジェットを測定することもできます。
サービスの可用性における SLO が 99% であると仮定しましょう。28 日間(ローリング ウィンドウを使用して計測)では、サービスは合計およそ 7 時間 20 分停止できます。メンテナンスの時間枠に 2 時間取られた場合、エラー バジェットの 27% を費やしたことになります。つまり、ローリング ウィンドウの残り 28 日間で、サービスでは (100 - 27) * 0.01 = 0.73% のエラーのみをスローでき、これは、合計エラー 1% の最初の値から減少しています。メンテナンスが完了すれば、SLI 計算式を再度使用して、受信しているトラフィックの量(有効なリクエスト)とユーザーに返しているエラーの数を確認して、時間の経過とともに消費しているエラー バジェットの量を計算できます。
このアプローチには、すべての受信トラフィックがサイズと重大度において等しく扱われるという短所があります。トラフィックがピークになる日中にメンテナンスの時間枠が生じる場合でも、費やされるエラー バジェットの量はトラフィックが減少する真夜中の場合と同じです。したがって、このアプローチは、トラフィックの状態が一日を通して大きく変化する場合は慎重に使用する必要があります。
エッジケースについて考える
上記のような状況では、エラー バジェットの詳細を考慮する必要があります。エラー バジェットの大部分を費やすような障害が発生したとします。これは、残りのバジェットがゼロに近くなるかマイナスになるぐらいの規模で、次に計画されているメンテナンスの時間枠が、今回消費したエラー バジェットの計算に使用する時間枠内にスケジュールされています。このダウンタイムによってエラー バジェットが使い果たされてしまうリスクがある場合、どうすればよいでしょうか。
このような状況には、いくつかの「特効薬」を定義することで対処します。真にビジネス クリティカルな緊急事態発生時のごくわずかな例外を定義します。これによってバジェットのメンテナンスの時間枠がフリーズするかどうかは関係ありません。たとえ小さな更新であってもやはりサービスを停止する必要があると仮定して、「特効薬」の使用により、ターゲットを絞って短くしたメンテナンスの時間枠を実施して、その間に重要なバグの修正だけをリリースできます。
一般的に、他のタイプの例外を検討することはおすすめしません。そういった例外では、サービスの信頼性維持の失敗が受け入れられる文化を生み出す可能性が高いからです。それはサービスの信頼性に取り組むやる気をそいでしまいます。障害による影響は、単に問題をエスカレーションすることで回避できてしまうからです。
エラー バジェットを消費しない興味深いケース
もう一度、エラー バジェットの用途について確認しましょう。定義されているように、エラー バジェットは機能の開発と信頼性の向上の間でエンジニアリング チームが費やす時間の優先度のバランスを取るためのツールです。エラー バジェットを使い果たした場合、それは、低可用性、高レイテンシ、サービスの信頼性を表す指標でのその他の低スコアの結果とみなされます。
メンテナンスの時間枠でエラー バジェットの一部が消費されているが、メンテナンスの時間枠を完全に撤廃する(または少なくとも時間枠を短縮する)ことは計画していない場合、優先することが必要な可能性のあるメンテナンスの時間枠を、バジェットを使い果たした結果として削減することは信頼のおける取り組みとはいえません。エラー バジェットを使い果たす原因になっているメンテナンスの時間枠を排除する計画がないのであれば、エラー バジェットを繰り返し使い果たすことを暗黙的に受け入れていることになります。エラー バジェットのポリシーで影響を定義して、作業項目に優先順位を付け、今後メンテナンスの時間枠がエラー バジェットを消費しないようにする計画もありません。
したがって、ここで伝えたいのは、メンテナンスの時間枠でエラー バジェットを使い果たすことを決定できるのは、そのダウンタイム時間を信頼性の取り組みの一部とみなし、ダウンタイムを最小限に抑えるためにメンテナンスの時間枠を削減する計画がある場合だけだということです。
サービスが停止する時間が生じるリスクを負うことに決め、スケジュールされたダウンタイムが生じることにビジネス オーナーが納得し、現状を変える計画がない場合、そのダウンタイムをエラー バジェットの対象とするのは避けた方がよいでしょう。このようにリスクを受け入れる場合、メンテナンスの時間枠について以下のことが必要なため、ビジネスに強い影響を及ぼすことになります。
中断ができる限り小規模になるように、できる限り短くする
できる限り多くの人間に連絡できるチャネルを使用して、十分な余裕をみてユーザーや顧客に明確かつ適切に伝達する
ビジネスの別の部署で中断が生じないように、社内に伝達する
実施計画、終了条件、予期される結果、ロールバック アクション計画を明確に定義しておく
トラフィックが少ないと予測される時間帯にスケジュールする
計画した時間枠に従って実行する
時間枠が超過した場合のエラー バジェットへの影響(場合によっては深刻な影響)を明確にしておく
エラー バジェットを定義する方法によっては、以下のことに留意してください。エラー バジェットの対象としないメンテナンスの時間枠では、サービスを自由に停止できます。ユーザーに不便を強いる可能性がありますが、その責任は負いません。
グローバル サービスでの変化のない(少ない)プロファイル
グローバル サービスでは、あらゆることがまったく異なります。トラフィック プロファイルにトラフィックの谷間はあるものの、地域が限定されたサービスで生じるトラフィックの深い谷間ほど目立っておらず、このときにサービスを停止しても比較的少数のユーザーにしか影響を与えないことが考えられます。
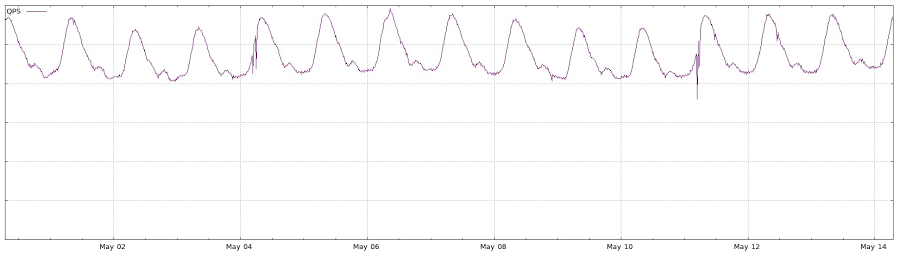
ただし同時に、サービスのグローバル性により、マルチリージョン プレゼンスが必要な場合もあります。つまり、マルチリージョン アーキテクチャを活用し、トラフィックの少ない地域から他の地域にトラフィックを転送することで、地域を限定したメンテナンスの時間枠を回避できるようにする状況です。
この場合のおすすめの方法は、やはりメンテナンスのために一部のシステムを停止することが必要な場合に、アーキテクチャの分散の性質を活用して、指定した時間にリージョンを切断できるようにサービスを設計することです。もちろんこのアプローチでは、切断したリージョンからこれまで対応していたアクティブなリクエストすべてに残りのサービス容量で対応できるように、容量のニーズを考慮する必要があります。また、カスケード障害が生じないように、一部の過剰なトラフィックをブラックホールにする必要がある場合に切れるサーキット ブレーカーを設計する必要があります。
これが長期的な目標で、(最初のシナリオのように)グローバル サービスに稼働時間を定義しないことを想定する場合は、対応されない(またはエラーで終了した)リクエストをすべて考慮に入れ、エラー バジェットの消費の対象とする必要があります。
包括的に考える
すべてのサービスに適するたった 1 つのおすすめ方法というものはありませんが、SLO とエラー バジェットの視点でメンテナンスの時間枠について調査しておくと、サービスに対して情報に基づいた意思決定を行うことができます。お客様とお客様のプロダクト オーナーは、お客様のサービスとユーザーの両方を理解しやすくなり、ユーザーの行動を把握して、お客様のビジネスに最適な意思決定を行うことができます。
実施する必要のある最も重要な分析は、メンテナンスの時間枠がユーザーにどのような影響を与えるか(影響を与えている場合)、そしてエラー バジェットを使い果たした場合にメンテナンスの時間枠の影響を軽減するために信頼性の取り組みで軌道修正を行うことが必要になるかどうかを確認することです。
サービスにメンテナンスの時間枠を採用することを検討している場合は、ここで説明した基準に照らして長所と短所を評価してください。すでにメンテナンスの時間枠を設定している場合は、実施する方法や実施するタイミングを変更する必要があるかどうかを確認してください。
関連リソース
SRE の運用プラクティス、サービスを分析する方法、SLI を策定する方法、アプリケーションに SLO を定義する方法の詳細については、SRE ブックをご覧ください。Coursera で Google の Measuring and Managing Reliability コースを受講することもできます。ここではさらに詳しく自分のペースで SLI、SLO、エラー バジェットについて学べます。



