Compute Engine の説明: 大規模な OS 更新のベスト プラクティス

Google Cloud Japan Team
※この投稿は米国時間 2020 年 9 月 15 日に、Google Cloud blog に投稿されたものの抄訳です。
すべての VM に最新のパッチを適用して最新の状態に保つのはシステム管理者の最優先の職務ですが、大規模なデプロイメントにおいては更新の速度と信頼性へのリスクの可能性を比較考量する必要があります。Google Cloud の OS Patch Management サービスは、大規模なマシン群のすべてに更新を安全かつ効果的にインストールできる強力なツールです。
あらゆる組織に独自のパッチ管理プロセスが存在し、パッチの適用についてすべての状況に対応できる方法は存在しませんが、ベスト プラクティスというべきものはいくつか存在します。この投稿では、大規模な Compute Engine 環境を持つ Google Cloud のお客様が使用されているベスト プラクティスのいくつかを要約します。以下の推奨事項から、御社で役立つものを選んでください。
1. ラベルを使用して柔軟なデプロイ グループを作成する
ラベルを使用してマシン群を分割し、更新用のデプロイ グループを柔軟に作成できます。ラベルを使用してインスタンスのロール(ウェブまたはデータベース)、環境(開発、テスト、本番)、特定のビジネス アプリケーションやインスタンス OS ファミリー(Windows または Linux)への所属を指定でき、または単一のアプリケーションに属するすべての VM をグループ化できます。一貫したラベルポリシーを整備することで、マシン群の管理とパッチのデプロイ ターゲットの指定をよりアジャイルに行うことができます。Google Cloud でのラベルについて詳しく学習する。
2. まずゾーン単位、次にリージョン単位で更新をデプロイする
一般にアプリケーションのデプロイにあたっては、複数のゾーンと複数のリージョンにわたる高可用性を持つフォールト トレラントな構成を採ることをおすすめしています。これにより、単一のゾーンまたはリージョンまでの規模で、予期しないコンポーネント障害に対応できます。
Google の経験から、グローバルまたはリージョンのデプロイを行うとき、1 ゾーンずつ更新を適用することをおすすめします。開発 / ステージング環境で更新をテストした後でも、予期しない競合が本番環境で発生するリスクが存在します。問題が起きた場合、単一のゾーンなら簡単に問題を分離して更新をロールバックできます。すべてのゾーンを同時に更新する場合は修正に多くの時間が必要となり、アプリケーションの可用性に影響を及ぼす可能性があります。
デフォルトで、OS Patch Management には更新をゾーン単位でインストールするロールアウト計画が用意されています。
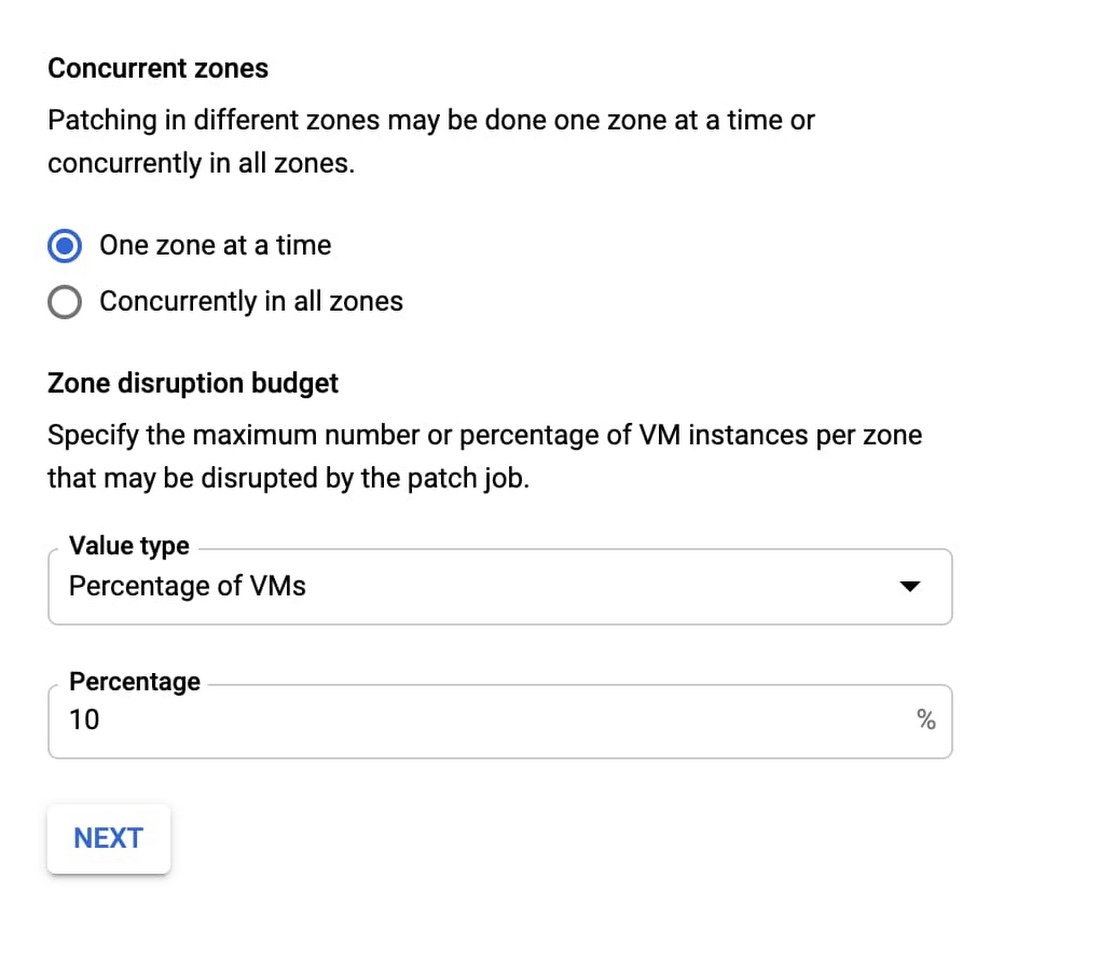
より厳格な推奨事項は、各パッチのデプロイ先を 1 つのパッチジョブにつき 1 ゾーンに制限することです。
3. パッチ適用前スクリプトとパッチ適用後スクリプトを使用して、安全にパッチを適用します。
以前のブログ投稿で解説したように、OS の更新が円滑に行われるようにするためにパッチ適用前スクリプトとパッチ適用後スクリプトを使用できます。
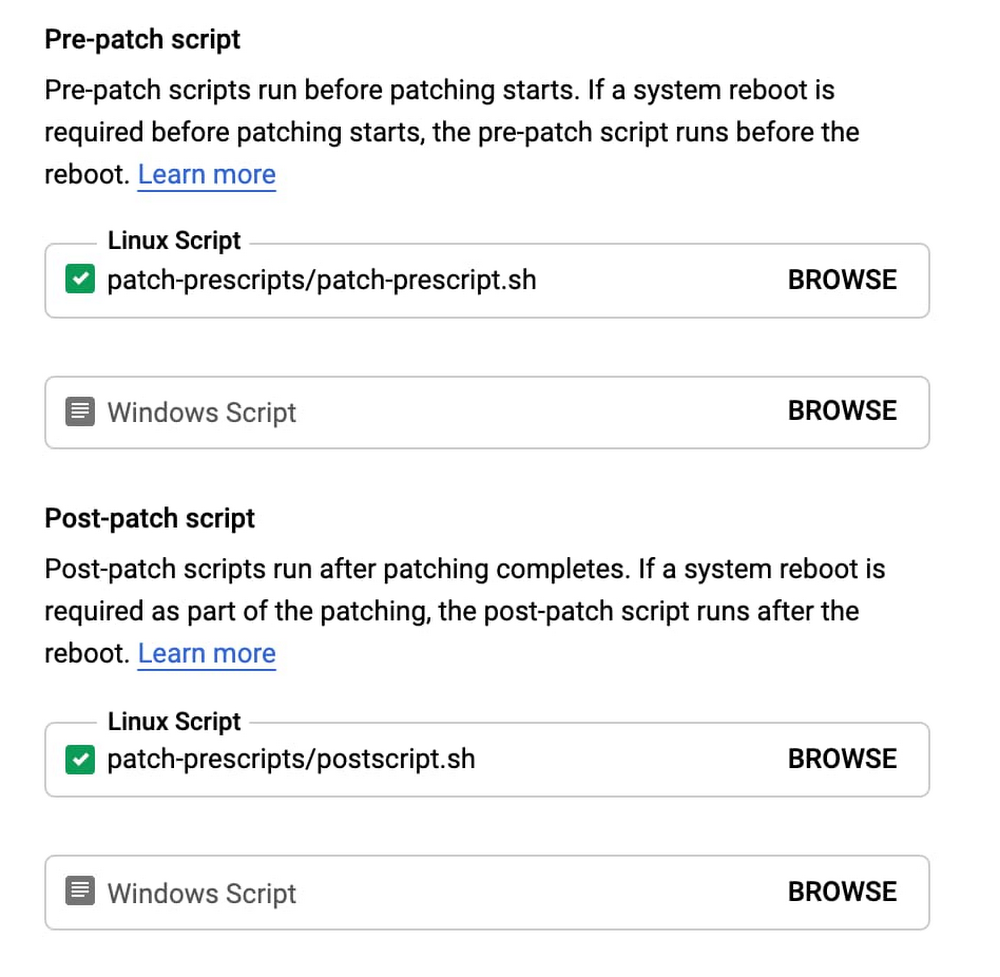
パッチ適用前スクリプトは、その名が示すようにパッチをインストールする前に実行され、更新を安全にインストールできるかどうかを判断します。たとえば、スクリプトの一部で特定のアプリケーションを停止する、インスタンスにアクティブな接続が存在しないことを確認するなどの動作を行えます。パッチ適用前スクリプトでエラーが返された場合、インスタンスの更新は失敗とみなされます。
パッチ適用後スクリプトは、パッチがインストールされた後のインスタンスとアプリの状態をチェックします。アプリケーションが実行されているか、データベースにアクティブな接続が存在するか、ログにエラー メッセージが記録されているか、モニタリング アラートが起動したかなどです。パッチ適用後スクリプトでエラーが返された場合、インスタンスの更新は失敗とみなされます。
これらのパッチ適用前とパッチ適用後のシグナルにより、パッチのデプロイ プロセス全体をプロアクティブに停止させ、影響範囲を制限できます。
4. 停止予算を設定します。
停止予算により、OS Patch Management はパッチ適用プロセスを遅くして、最大数のインスタンスで同時にパッチが適用されることを保証できます。また、更新のインストール後にインスタンスがオンラインに戻らない場合、プロセスはプロアクティブに停止されます。

停止予算は、更新中のいずれかの時点で利用不能になっても問題ないインスタンスの最大数として定義されます。更新には時間がかかり、再起動を行うこともあるため、インスタンスが一時的に利用不能になることもあります。更新のインストール中はインスタンスはサービスを行えません。インスタンスは、VM がパッチ適用後のチェックに合格しなかったため利用不能になることもあります。これらのインスタンスは失敗とみなされ、更新中は恒久的に利用不能になります。
具体例で考えてみましょう。20 台のウェブサーバーのグループを更新するとします。最初に数台だけを更新し、残りのインスタンスがワークロードを処理できることを確認するのが妥当です。ここでは停止予算を 5 インスタンスに設定します。
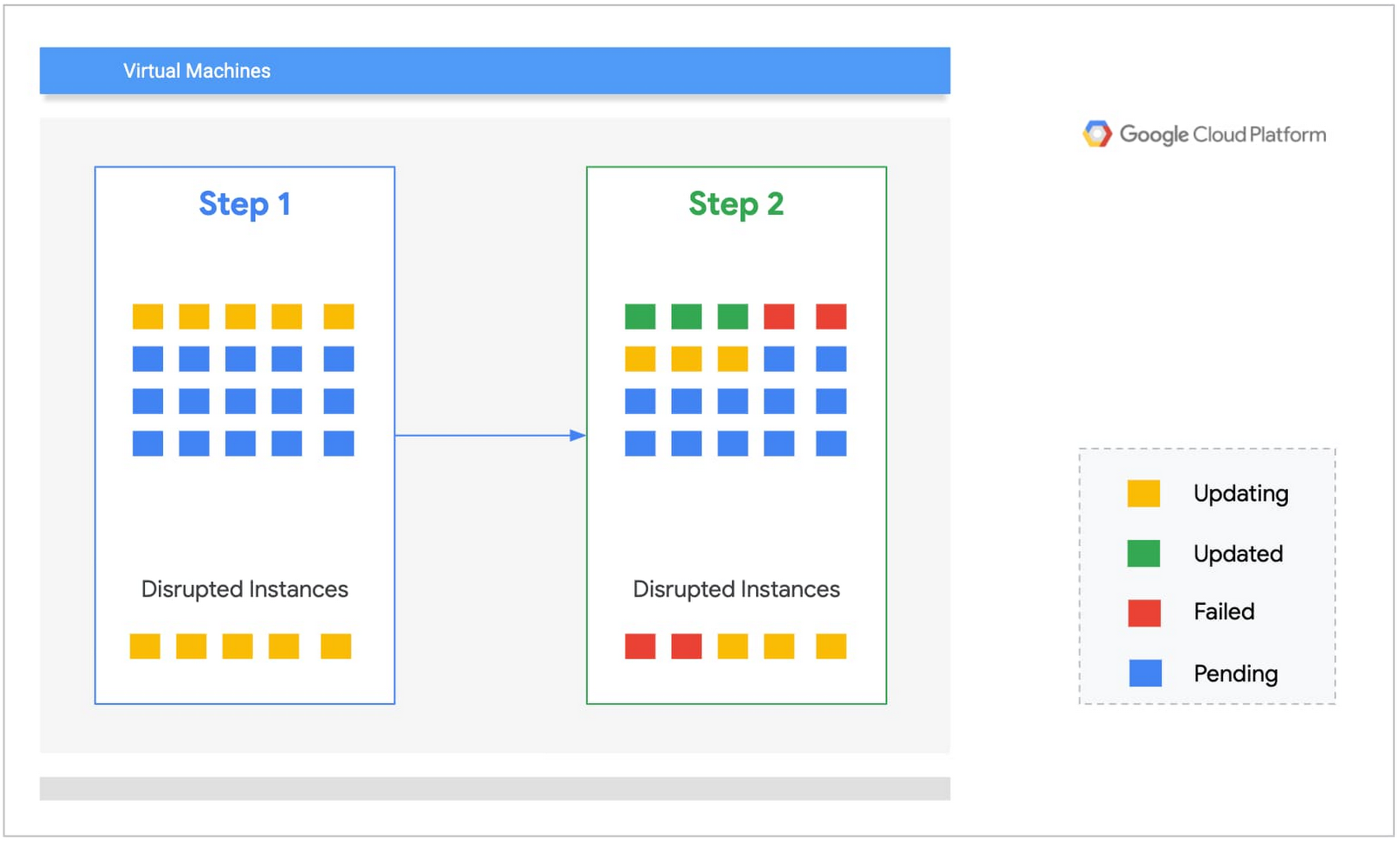
先ほど述べたように、停止予算は、パッチ適用プロセスの間に利用不能になる VM の最大数に相当します。
停止予算 ≥ 失敗したインスタンスの数 + 更新インストール プロセス中のインスタンスの数です。
ステップ 1: 5 つのインスタンスを最初に更新し、サービスを開始します。インスタンスの 3 つは更新に成功し、2 つは失敗したとします。
ステップ 2: 2 つの失敗したインスタンスは停止予算の 2/5 を占めることになります。このステップでは、同時にパッチ適用できるインスタンスが 3 つのみになります。
いずれかの時点で失敗したインスタンスの数が停止予算と一致すると、そのゾーンの更新プロセスは停止します。
5. 独自のパッチ インストール プロセスを作成します。
すべての組織には相違点があり、更新戦略はビジネスの要件、アプリケーションのアーキテクチャ、セキュリティ要件などさまざまな要因によって異なります。その結果、2 つの組織で更新戦略がまったく同じであることは稀です。
OS Patch Management には、会社の継続的デリバリー プロセスに更新プロセスを統合するため、非常に柔軟な API が用意されています。この API を既存のツールと統合するか、ネイティブの Google Cloud サービスを使用してパッチのデプロイをオーケストレートできます。たとえば、Cloud Composer や新しい Workflows サービスを使用できます。これらは更新のデプロイなど長時間実行オペレーションを自動化するための優れたツールです。
破棄ありのパッチ
OS インスタンスにパッチを適用するのは、システムの信頼性を維持するため最も重要な作業の一つです。OS Patch Management サービスと、ベスト プラクティスを活用することにより、ユーザーやアプリケーションへの影響を心配することなく、必要な頻度でパッチを適用できます。詳細および開始方法については、OS Patch Management サービスのドキュメントを参照してください。
-プロダクト マネージャー Sergey Maximov

