NVIDIA Tesla T4 GPU のベータ提供を開始
Google Cloud Japan Team
※この投稿は米国時間 2019 年 1 月 16 日に Google Cloud blog に投稿されたものの抄訳です。
私たち Google Cloud は昨年 11 月、NVIDIA Tesla T4 GPU を Google Cloud Platform(GCP)で提供することを発表し、この最新のデータセンター GPU をサポートする最初で唯一の大手クラウド プロバイダーになりました。そのときはプライベート アルファという形での提供でしたが、私たちはこのたび、T4 GPU インスタンスのパブリック ベータ提供を、ブラジル、インド、オランダ、シンガポール、日本(東京)、米国で開始しました。ブラジル、インド、日本、シンガポールの各 GCP リージョンでの GPU 提供は、今回の T4 が初めてとなります。
T4 GPU は、機械学習(ML)やビジュアライゼーションなど、GPU を活用できるさまざまなワークロードに適しています。個々の T4 は 16 GB の GPU メモリを搭載し、最高精度(FP32、FP16、INT8、INT4)のサポートを提供します。また、NVIDIA Tensor Core と RTX リアルタイム ビジュアライゼーション技術を組み込み、260 TOPS *1 のコンピューティング性能を発揮します。最大で 4 個の GPU、96 個のvCPU、624 GB のホスト メモリと、最大 3 TB のサーバー ローカル SSD をオプションで組み合わせれば、ニーズに最も適したカスタム VM シェイプを作ることができます。
料金は、プリエンプティブル VM インスタンスの場合で GPU 1 個あたり、わずか 0.29 ドル / 時間です。オンデマンド インスタンスでは、GPU 1 個あたり 0.95 ドル / 時間からスタートし、継続利用割引が最大 30 % まで適用されます。確約利用割引も利用すれば、T4 GPU のオンデマンド利用コストを最大限に引き下げることができます。詳細は営業担当にお問い合わせください。
広範な地域で GPU 利用をサポート
私たちは世界各地にある 8 つの GCP リージョンで T4 GPU を提供し、お客様がどこにいても低レイテンシのソリューションを利用できるようにしました。従来の NVIDIA K80、P4、P100、V100 GPU に T4 が加わったことで、ハードウェア アクセラレータ付きのコンピューティング環境を幅広い選択肢の中から選ぶことができます。T4 GPU は現在、us-central1、us-west1、us-east1、asia-northeast1、asia-south1、asia-southeast1、europe-west4、southamerica-east1 の各リージョンで利用できます。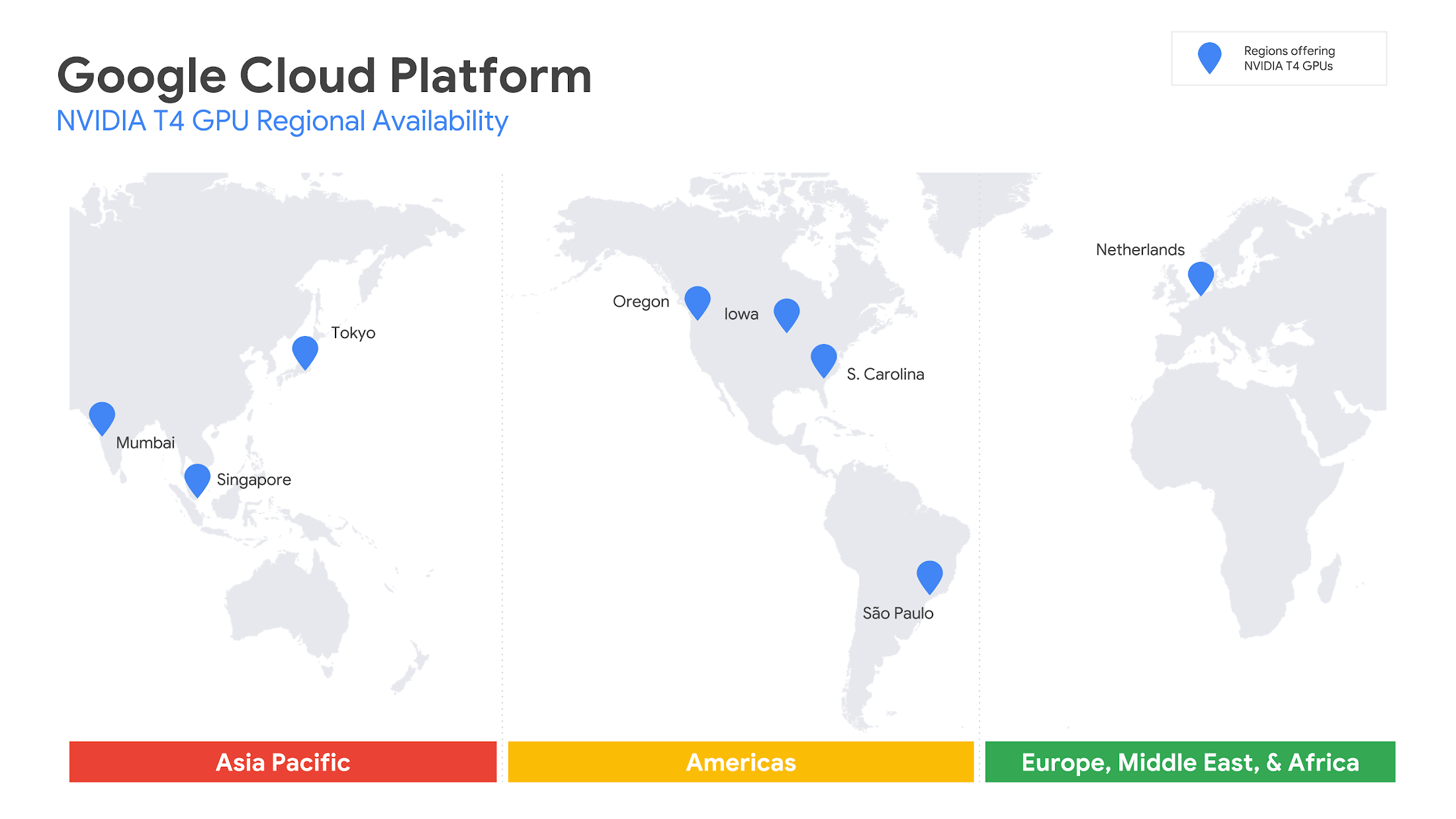
機械学習の推論
T4 は、Google Cloud のプロダクト ポートフォリオの中で、推論ワークロードに最も適した GPU です。正確度と性能のトレードオフを柔軟に調整しながら、FP16、INT8、INT4 の高い性能特性により大規模な推論を実行できることは、他の GPU には見られない特長です。16 GB のメモリにより大規模な ML モデルをサポートし、中小規模のモデルなら複数の推論を同時に実行できます。Google Compute Engine における T4 の ML 推論性能は最高 4267 イメージ / 秒 *2 で、レイテンシはわずか 1.1 ミリ秒 *3 です。T4 の料金と性能、8 つのリージョンによるグローバルな展開、さらには Google の高速ネットワークのおかげで、Compute Engine の T4 インスタンスは本番ワークロードの実行に非常に適しています。T4 GPU で ML 推論を実行するうえでの参考資料として、Compute Engine の T4 搭載 VM でマルチゾーンの自動スケーリング ML 推論サービスをデプロイする方法を説明したテクニカル チュートリアルも用意されています。
機械学習のトレーニング
クラウドにおける ML トレーニング ワークロードでは、高い性能と Tensor Core テクノロジー、16 GB の GPU メモリで大規模 ML モデルをサポートする V100 が主力 GPU になりました。これに対して T4 は、それらすべてをより低料金でサポートしており、分散トレーニングをスケールアウトしたいときや V100 GPU ほどのパワーを必要としないときは最良の選択肢になります。多くのトレーニング ワークロードがほぼ線形にスケーリングし、T4 を多数使用すればその分だけトレーニング スピードが上がるので、私たちのお客様からも高い評価をいただいています。Compute Engine での機械学習コストの削減
V100 GPU は、T4 と組み合わせて使うと効果的です。最大 8 個の V100 を搭載できる大規模 VM にスケールアップしたり、低コストの T4 を使用してスケールダウンしたりできるほか、ワークロードの特性に応じて T4 と V100 を使い分けてスケールアウトすることも可能です。Google Cloud は T4 GPU を提供する唯一の大手クラウド プロバイダーであり、その多彩なプロダクト ポートフォリオを活用すれば、コストを削減したり、同等のリソースでより多くの処理を実行したりすることができます。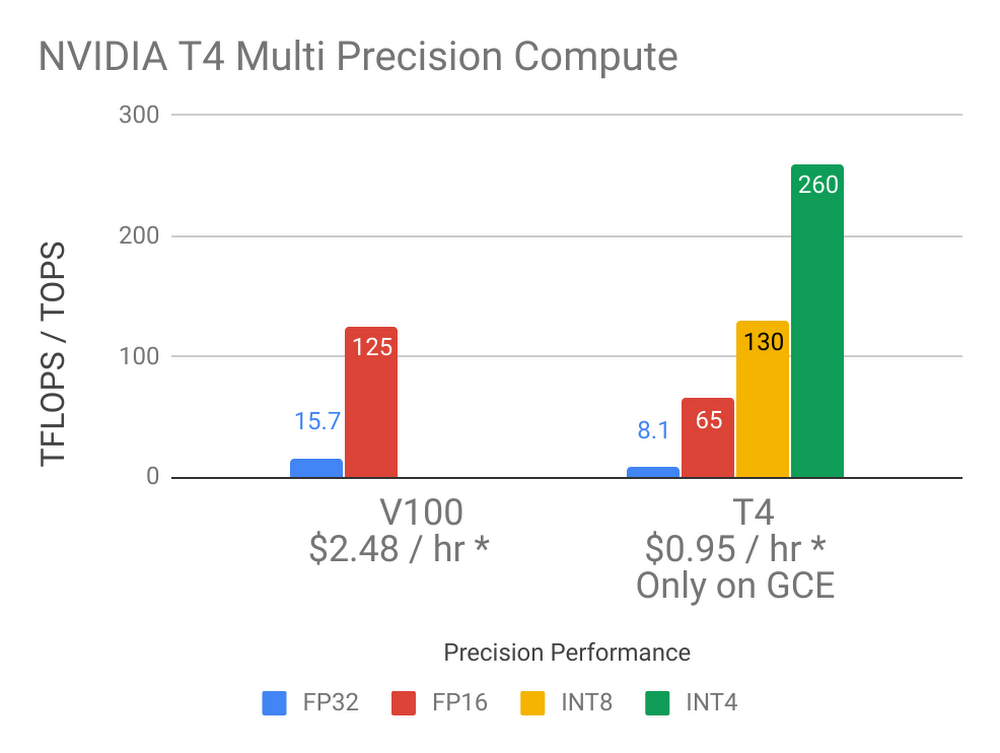
* 図中の料金は現在の一部リージョンでの Compute Engine オンデマンド料金です。料金はリージョンごとに異なる場合があり、SUD やプリエンプティブル GPU を通じて、より低料金での利用が可能です。
RTX による強力なビジュアライゼーション
Turing アーキテクチャを採用した NVIDIA T4 は、データセンター GPU としては初めて専用のレイトレーシング プロセッサを内蔵しています。これは RT Core と呼ばれ、3D 環境における光の動きの計算を高速化します。Turing は、NVIDIA の OptiX レイトレーシング API を通じてハードウェア アクセラレーションを提供しており、従来の Pascal アーキテクチャよりも高速にリアルタイム レイトレーシングを実行でき、CPU よりも速くフィルム エフェクトの最終フレームをレンダリングできます。さらに私たちは T4 GPU で動作する仮想ワークステーションも用意しており、次世代のコンピュータ グラフィックス性能と、どこからでもどんなデバイスでも作業できるという柔軟性をクリエーターや技術のプロフェッショナルに提供します。
使ってみましょう
私たちは T4 GPU を、ML やコンピューティング、ビジュアライゼーションで簡単に利用できるようにしました。T4 をはじめとする GPU プロダクトの詳細はこちらのページをご覧ください。GPU と Compute Engine をすぐに使いたいお客様のために、NVIDIA ドライバとさまざまな ML ライブラリがプリインストールされた Deep Learning VM Image も用意しています。まだ Google Cloud をご利用でない方は、今すぐサインアップして 300 ドルの試用枠をご活用ください。* 1. 260 TOPS は INT4 での性能。INT8 では 130 TOPS、FP16 では 65 TFLOPS、FP32 では 8.1 TFLOPS
* 2. INT8、resnet50、バッチサイズ 128
* 3. INT8、resnet50、バッチサイズ 1
- By Chris Kleban, Product Manager, Cloud GPUs



