その SLO は現実的ですか?SRE 的なリスク分析手法
Google Cloud Japan Team
※この投稿は米国時間 2022 年 5 月 5 日に、Google Cloud blog に投稿されたものの抄訳です。
サービスレベル目標(SLO)の設定は、サイト信頼性エンジニアリング(SRE)プラクティスの基本タスクの一つです。SLO があることで、SRE チームは、設定された目標に照らしてサービスが十分な信頼性をもって稼働しているかどうか評価できます。SLO の反面となるのがエラー バジェットです。これは、許容される信頼性損失の度合いを示します。このような目標を特定して SLO を設定する方法を学習したら、次に、アプリケーション アーキテクチャとチームのプラクティスに照らして、対象の SLO が現実的かどうかを考えます。つまり、SLO は達成可能か、エラー バジェットを消費する可能性が最も高いものは何かを検証します。
Google では、稼働準備レビュー(PRR)の一部として、SRE が新しいサービスの引き受け時にこのような問題を直接評価します。このリスク分析の目的は、SLO の変更を促すことではなく、対象となるサービスに対するリスクを優先順位付けして明確化することです。これにより、サービスの変更により、あるいはサービスを変更せずに SLO を実際に達成できるかどうかを評価できます。さらに、利用可能な最良のデータを使用して、最優先で低減すべきリスクを特定できます。
リスクを特定および低減することで、サービスの信頼性を向上できるのです。
リスク分析の基本
リスクを評価して優先順位を付ける前に、注意すべき事項を網羅したリストを用意する必要があります。この投稿では、アプリケーションのあらゆる潜在的リスクについてブレインストーミングするという任務を担うチーム向けに、ガイドラインをいくつか提示します。次に、リストに照らしながら、特定したリスクを実際にどのように分析して優先順位を付けるかを紹介します。
検討すべきリスクとは?
リスクを検討する際は、依存関係、モニタリング、容量、オペレーション、リリース プロセスに関連するリスクを、それぞれのカテゴリにマッピングすることが重要です。それぞれに対し、特定の障害が発生した場合、たとえば、サードパーティがダウンした場合や、アプリケーションまたは構成のバグがあった場合に、どのような問題が発生するかを想定します。したがって、評価をする際に検討すべき点は以下のとおりとなります。
オブザーバビリティのギャップがあるか?
この特定の SLI にアラートがあるか?
そもそもこれらの指標を現在収集しているか?
また、モニタリングとアラートの依存関係も必ずマッピングします。たとえば、使用しているマネージド システムがダウンしたらどうなるかなどです。
可能であれば、クリティカル ユーザー ジャーニー(CUJ)における重要なコンポーネントそれぞれに対して、各障害点に関連するリスクを特定します。そして、これらのリスクを特定したら次の点を数量化します。
障害の影響を受けたユーザーの割合
今後の障害発生頻度の推定
障害検出にかかった時間
また、CUJ に影響を及ぼした前年のインシデントの情報を収集することも有効です。直感ではなく過去のデータに頼ることで、より正確な推定値が得られ、実際のインシデントに対しても適切な初動対応ができます。たとえば、次のようなインシデントを検討します。
容量低減につながる構成上の問題により、過負荷とリクエストのドロップが発生
新しいリリースにより少数のリクエストで障害が発生。障害は 1 日にわたって検出されず、検出後は迅速にロールバック
クラウド プロバイダの単一のゾーンの VM / ネットワークのサービス停止
クラウド プロバイダのリージョン VM / ネットワークのサービス停止
オペレーターが誤ってデータベースを削除し、バックアップからの復元が必要
さらに、リスク要因(全体の検出時間(TTD)と修復時間(TTR)に影響を及ぼすグローバル要因)も考慮する必要があります。これらは多くの場合、サービス停止の検出にかかる時間(ログベースの指標を使用している場合など)やオンコール エンジニアへのアラートにかかる時間を長引かせるような、運用上の要因です。別の例として、ハンドブックやドキュメントの不足や自動的な手順の不足もあります。たとえば、次のようなことが考えられます。
ノイジー アラートなどの運用上の過負荷により、推定検出時間(ETTD)が 30 分以上かかる
事後調査やアクション アイテムのフォローアップが不足しているため、考えられる障害の頻度が 10% 上昇
ブレインストーミングのガイドライン: ファシリテーターへの推奨事項
サービスの潜在的リスクは何かという技術的な側面のほかに、チームとブレインストーミング セッションをする際に検討すべきベスト プラクティスがいくつかあります。
最初に、サービスと、そのユーザーおよび依存関係のハイレベル ブロック図について検討します。
自分とは異なる形でプロダクトに関係するさまざまな役割の人の意見を含め、ミーティング ルーム内で多様な意見を出し合います。1 つのグループだけが話すということのないようにします。図の各要素について、ユーザーにとってエラーがどのように現れる可能性があるかを参加者に訊ねます。類似する根本原因を 1 つのリスクカテゴリにグループ化します(「データベースの停止」など)。
ある障害の推定発生間隔が 2 年より長い場合、または障害の影響を受けるユーザーが非常に少ない場合は、討論にあまり時間をかけないようにします。
リスクカタログの作成
リスクのリストは長いものである必要はありません。サービスレベル指標(SLI)あたり 7~12 項目で十分です。重要なのは、そのデータに発生確率が高いリスクと重大なリスクが含まれていることです。
実際に発生した停止事象を出発点とするのがベストです。これらは、依存しているサービスまたはネットワークが利用できないだけといった単純なものでかまいません。
インフラストラクチャ関連の問題とソフトウェア関連の問題の両方をカバーします。
SLI、検出時間、解決にかかる時間、頻度に影響を与える可能性のあるリスクを検討します(このような指標の詳細は後述)。
リスクカタログとリスク要因(グローバル要因)の両方をカバーします。たとえば、ハンドブックの欠如は修復時間を長引かせますし、CUJ のアラートがないことは検出時間に影響します。また、ログ同期が x 分遅延すれば、検出時間が同じ時間だけ長くなります。次に、このようなリスクと関連する影響をすべて、グローバル インパクト タブにカタログ化します。
以下はリスクの例です。
新しいリリースにより少数のリクエストで障害が発生。障害は 1 日にわたって検出されず、検出後は迅速にロールバック。
新しいリリースにより多数のリクエストで障害が発生。自動ロールバックなし。
構成上の障害により容量が低減。リソース使用量が増大し上限に達したことに気づかない。
推奨事項: SLI 導入のデータと結果を検証することで、目標達成までの現況を把握できます。最初に、各 CUJ に 1 つずつダッシュボードを作成することをおすすめします。可能であれば、SLO 達成における問題のトラブルシューティングとデバッグが可能になるような指標を、このダッシュボードに含めます。
リスクの分析
潜在的リスクのリストを作成したら、次はリスクを分析します。リスクの発生可能性を順位付け、それらを緩和する方法を検討します。つまり、リスク分析に入ります。
リスク分析では、4 つの主要項目(上述の TTD と TTR、次の障害が発生するまでの間隔(TBF)、ユーザーへの影響)を評価します。これにより、データドリブンのアプローチが可能になり、重要なリスクに対処して優先順位を付けることができます。
SRE の原則で本番環境でのインシデントの影響を低減する(英語)では、本番環境でのインシデント サイクルの図を紹介しました。青色はユーザーが満足しているときを示し、赤色はユーザーが不満なときを示します。
サービスの信頼性が失われてユーザーが不満を感じる時間は、障害の検出時間と修復時間を合わせたもので、インシデントの頻度(次の障害が発生するまでの間隔)に影響されます。
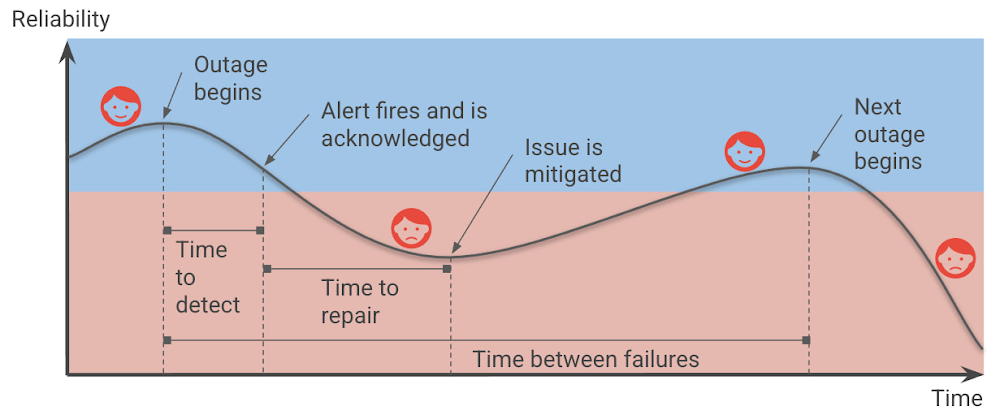
したがって、次の障害が発生するまでの間隔を長くする一方で検出時間または修復時間を短縮し、そして何よりサービス停止の影響を低減することで、信頼性を向上させることができます。
復元性に優れたサービスを設計することで、全体の障害頻度を減らすことができます。アーキテクチャにおいては、それが個別のインスタンスであれ、アベイラビリティ ゾーン、またはリージョン全体であれ、単一障害点を作らないようにする必要があります。これは、局所での小規模なサービス停止が雪だるま式に世界各地に広がるのを防ぐためです。
影響を受けるインフラストラクチャやユーザーの割合を減らすか、リクエストを減らすことでユーザーへの影響を小さくできます(リクエストの全体ではなく一部をスロットリングするなど)。サービス停止の影響を軽減するには、グローバルな変更は避け、変更を徐々にデプロイできる高度なデプロイ戦略を採用します。数時間、数日、または数週間かけた漸進型のカナリア ロールアウトを行うことを検討します。これにより、リスクを減らして、すべてのユーザーが影響を受ける前に問題を特定できます。
さらに、堅固な継続的インテグレーションと継続的デリバリー(CI / CD)パイプラインを持つことで、デプロイを安心して行い、必要に応じてロールバックを行うことが可能になり、お客様への影響を小さくできます(SRE ブックの第 8 章 - リリース エンジニアリングをご覧ください)。また、コードレビューとテストの統合プロセスを作成することで、ユーザーが影響を受ける前に早期に問題を見つけることが可能になります。
検出時間の短縮は、サービス停止検出の迅速化を意味します。なお、推定 TTD は、人間が問題に関する情報を得るまでにかかる時間を表します。誰かがページを受信して処理をする場合を想定してみましょう。TTD には、データ処理のような「検出」までの遅延も含まれます。たとえば、ログベースのアラートを使用していて、ログシステムの取り込み時間が 5 分の場合、各アラートの TTD が 5 分間長くなります。
ETTR(推定修復時間)は、担当者がアラートを目にした時点からユーザーが満足した時点までの時間です。修復時間の改善とは、基本的にサービス停止の修復の迅速化を意味します。一方で、焦点はあくまでも「このインシデントはまだユーザーに影響を与えているか」である必要があります。ほとんどの場合、新しいリリースのロールバックや、影響を受けていないリージョンへのトラフィックの迂回といった緩和策は、パッチの適用された新しいビルドへロール フォワードするより、はるかに迅速に進行中のサービス停止のユーザーへの影響を低減または除去できます。根本原因はまだ解決されていませんが、ユーザーがそれを意識することはありません。ユーザーが気にするのは、サービスが再度機能しているということだけです。
自動化は、人間の関与をなくす一方で、TTR を短縮し、さらに高いレベルの信頼性の目標を達成するうえで不可欠です。しかしながら、自動化によって TTR がなくなるわけではありません。異なるリージョンへのフェイルオーバーなどの緩和措置がたとえ自動化されても、それが反映されるまで時間はまだかかるからです。
「推定」値に関する注意: リスク分析を始める際、各指標に対しておおまかな推定値を使用することがあるかもしれません。ただし、インシデント データからデータが集まるのに伴い、過去のサービス停止から得られたデータに基づいてこれらの推定値を更新することが可能になります。
リスク分析プロセスの概要
リスク分析プロセスは、まず各 SLO に対するリスクのブレインストーミングから始まります(SLO はより正確には SLI。異なる SLI は異なるリスクにさらされるため)。次のフェーズではリスクカタログを作成し、徐々にその完成度を高めていきます。
このテンプレートを使用して、2 つまたは 3 つの SLI についてリスク分析シートを作成します。詳細は、敵を把握する: リスクを明確化し、優先順位をつける方法: CRE が現場で学んだこと(英語)をご覧ください。
社内でリスクについてブレインストーミングし、SLO に影響を与える移行を検討して、初期データを収集します。最初にエンジニアリング チームとこれを行ってから、次にプロダクト チームに参加してもらいます。
各 SLI のリスク分析シートには、ETTD、ETTR、影響、頻度を含める必要があります。グローバル要因と示唆されたリスク、そしてこれらのリスクが許容可能かどうかも含めます。
SLO のビジネスニーズについて過去のデータを収集して、プロダクト チームに相談します。
本番環境でのインシデントに基づき、データの完成度を徐々に高めて更新します。
リスクの許容
リスクカタログを作成してリスク要因を把握したら、ビジネスニーズとリスク分析に従って SLO を最終決定します。このステップでは、リスクを前提として SLO が達成可能かどうか、達成可能でない場合は目標を達成するために何をすべきかを評価します。この際、PM がレビュー プロセスに参加することが重要です。PM は特に、許容できないリスクを緩和または排除するエンジニアリング作業に優先順位を付ける必要があるためです。
敵を把握する: リスクを明確化し、優先順位をつける方法: CRE が現場で学んだことでは、「リスク スタック ランク」シートを使用してリスクの「コスト」がどの程度か確認し、SLO に対してどのリスクを許容できるか(またはできないか)検討する方法を紹介しました。たとえば、テンプレート シートでは、すべてのリスクを許容することで 99.5% の信頼性を、一部のリスクを許容することで 99.9% を、リスクを一切許容しないことで 99.99% を達成する、というような計算ができます。SLO で許容される以上のエラー バジェットが消費されるためにリスクを許容できない場合、根本原因解決と緩和方法構築のいずれかにエンジニアリング時間を費やす明確な価値があります。
最後の注意点: SLO と同様、リスクについて、サービス停止中に観察された実際の TTD に基づきリスク分析のイテレーションを行い ETTD を改善します。ETTR についても同様です。インシデント発生後は、データを更新し、これらの推定値に関して現状を把握する必要があります。また、定期的にこれらの推定値を再確認し、リスクがまだ影響を与えているか、推定値は正しいか、考慮すべきリスクが他に発生しているかを評価する必要があります。継続的な改善の SRE 原則と同様、これは終わりのない作業ですが、労力を費やす価値は十分にあります。
このトピックに関する詳細は、バーミンガムで 5 月 6 日、およびプラハで 5 月 24 日に行われる DevOpsDays 2022 での私のスピーチをご覧ください。
その他の読みものとリソース
- インフラ、SRE、AppMod 担当戦略クラウド エンジニア Ayelet Sachto



