Shrinking the impact of production incidents using SRE principles—CRE Life Lessons
Myk Taylor
Site Reliability Engineer
Editor's note: Post was edited on Dec 12, 2019 to clarify the source of the "production incidents as unplanned investments" metaphor.
If you run any kind of internet service, you know that production incidents happen. No matter how much robustness you’ve engineered in your architecture, no matter how careful your release process, eventually the right combination of things go wrong and your customers can’t effectively use your service.
You work hard to build a service that your users will love. You introduce new features to delight your current users and to attract new ones. However, when you deploy a new feature (or make any change, really), it increases the risk of an incident; that is, something user-visible goes wrong. Production incidents burn customer goodwill. If you want to grow your business, and keep your current users, you must find the right balance between reliability and feature velocity. The cool part is, though, that once you do find that balance, you’ll be poised to increase both reliability and feature velocity.
In this post, we’ll break down the production incident cycle into phases and correlate each phase with its effect on your users. Then we’ll dive into how to minimize the cost of reliability engineering to keep both your users and your business happy. We’ll also discuss the Site Reliability Engineering (SRE) principles of setting reliability targets, measuring impact, and learning from failure so you can make data-driven decisions on which phase of the production incident cycle to target for improvements.
Understanding the production incident cycle
A production incident is something that affects the users of your service negatively enough that they notice and care. Your service and its environment are constantly changing. A flood of new users exploring your service (yay!) or infrastructure failures (boo!), for example, threaten the reliability of your service. Production incidents are a natural—if unwelcome—consequence of your changing environment. Let’s take a look at the production incident cycle and how it affects the happiness of your users:
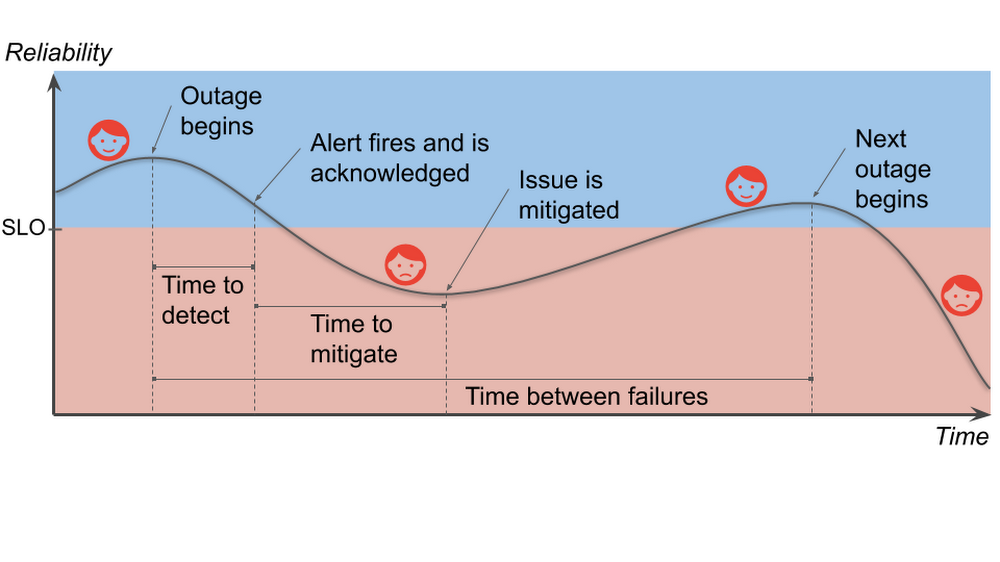
Note that the time between failures for services includes the time for the failure itself. This differs from the traditional measure since modern services can fail in independent, overlapping ways. We want to avoid negative numbers in our analysis.
Your service-level objective, or SLO, represents the level of reliability below which your service will make your users unhappy in some sense. Your goal is clear: Keep your users happy by sustaining service reliability above its SLO. Think about how this graph could change if the time to detect or the time to mitigate were shorter, or if the slope of the line during the incident were less steep, or if you had more time to recover between incidents. You would be in less danger of slipping into the red. If you reduce the duration, impact, and frequency of production incidents—shrinking them in various ways—it helps keep your users happy.
Graphing user happiness vs. reliability vs. cost
If keeping your reliability above your SLO will keep most of your users happy, how much higher than your SLO should you aim? The further below your SLO you go, of course, the unhappier your users become. The amazing thing, though, is that the further above the target level for your SLO you go, users will become increasingly indifferent to your reliability. You will still have incidents, and your users will notice them, but as long as your service is, on average, above its SLO, the incidents are happening infrequently enough that your users stay sufficiently satisfied. In other words, once you’re above your SLO, improving your reliability is not valuable to your users.
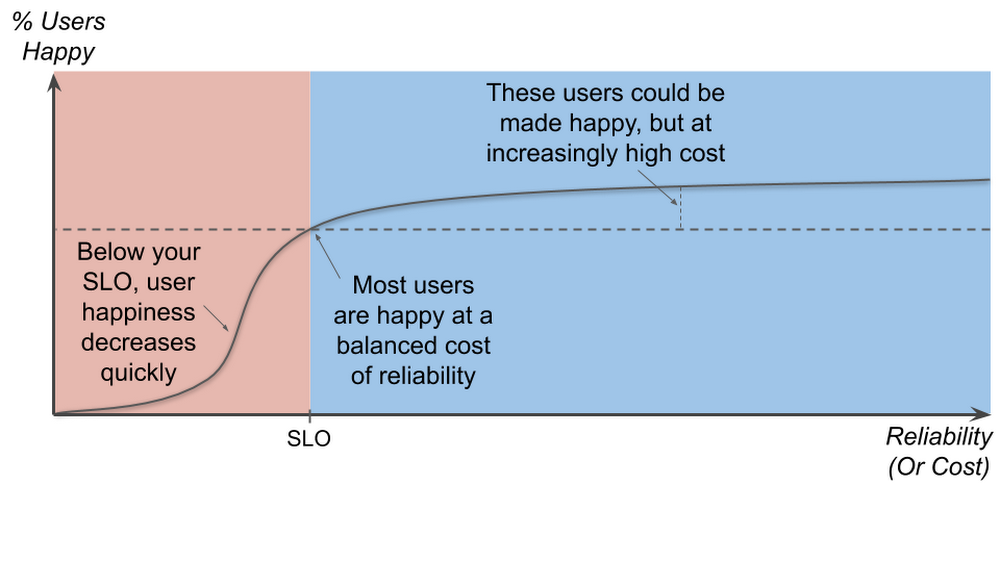
Reliability is not cheap. There are costs not only in engineering hours, but also in lost opportunities. For example, your time to market may be delayed due to reliability requirements. Moreover, reliability costs tend to be exponential. This means it can be 100 times more expensive to run a service that is 10 times more reliable. Your SLO sets a minimum reliability requirement, something strictly less than 100%. If you’re too far above your SLO, though, it indicates that you are spending more on reliability than you need to. The good news is that you can spend your excess reliability (i.e., your error budget) on things that are more valuable than maintaining excess reliability that your users don’t notice. You could, for example, release more often, run stress tests against your production infrastructure and uncover hidden problems, or let your developers work on features instead of more reliability. Reliability above your SLO is only useful as a buffer to prevent your users from noticing your instability. Stabilize your reliability, and you can maximize the value you get out of your error budget.
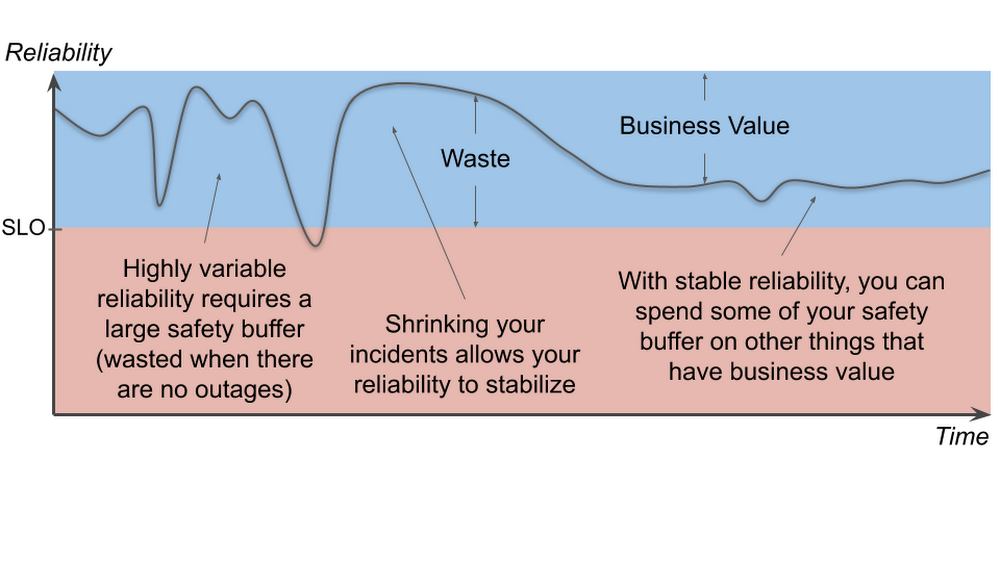
Laying the foundation to shrink production incidents
When you’re thinking about best practices for improving phases of the production incident cycle, there are three SRE principles that particularly matter for this task. Keep these in mind as you think about reliability.
1. Create and maintain SLOs
When SREs talk about reliability, SLOs tend to come up a lot. They’re the basis for your error budgets and define the desired measurable reliability of your service. SLOs have an effect across the entire production incident cycle, since they determine how much effort you need to put into your preparations. Do your users only need a 90% SLO? Maybe your current “all at once” version rollout strategy is good enough. Need a 99.95% SLO? Then it might be time to invest in gradual rollouts and automatic rollbacks.
During an incident, your SLOs give you a basis for measuring impact. That is, they tell you when something is bad, and, more importantly, exactly how bad it is, in terms that your entire organization, from the people on call to the top-level executives, can understand.
If you’d like help creating good SLOs, there is an excellent (and free, if you don’t need the official certification) video walkthrough on Coursera.
2. Write postmortems
As Dave Rensin, head of Google Cloud CRE, is fond of framing it1, think of production incidents as unplanned investments where all the costs are paid up front. You may pay in lost revenue. You may pay in lost productivity. You always pay in user goodwill. The returns on that investment are the lessons you learn about avoiding (or at least reducing the impact of) future production incidents. Postmortems are a mechanism for extracting those learned lessons. They record what happened and why it happened, and they identify specific areas to improve. It may take a day or more to write a good postmortem, but they capture the value of your unplanned investment instead of just letting it evaporate.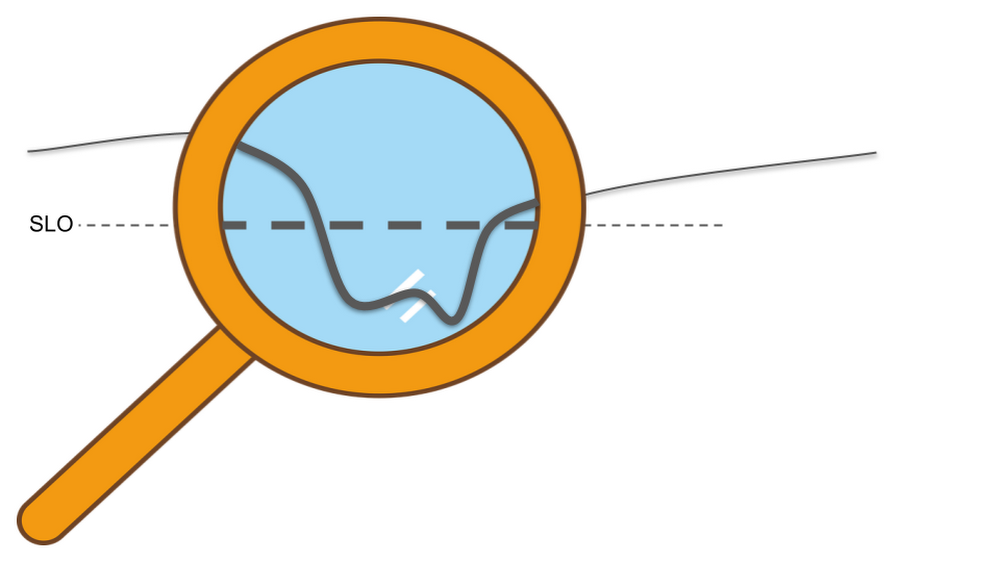
When should you write a postmortem? Write one whenever your SLO takes a significant hit. Your postmortems become your reliability feedback loop. Focus your development efforts on the incident cycle phases that have recurring problems. Sometimes you’ll have a near miss when your SLO could have taken a hit, but it didn’t because you got lucky for some reason. You’ll want to write one then, too. Some organizations prefer to have meetings to discuss incidents instead of collaborating on written postmortems. Whatever you do, though, be sure to leave some written record that you can later use to identify trends. Don’t leave your reliability to luck! As the SRE motto says: Hope is not a strategy. Postmortems are your best tool for turning hope into concrete action items.
For really effective postmortems, those involved in the incident need to be able to trust that their honesty in describing what happened during the incident won’t be held against them. For that, you need the final key practice:
3. Promote a blameless culture
A blameless culture recognizes that people will do what makes sense to them at the time. It's taken as a given that later analysis will likely determine these actions were not optimal (or sometimes flat-out counterproductive). If a person’s actions initiated a production incident, or worsened an existing one, we should not blame the person. Rather we should seek to make improvements in the system to positively influence the person’s actions during the next emergency.
For example, suppose an engineer is paged in the middle of the night, acknowledges the page, and goes back to bed while a production incident develops. In the morning we could fire that engineer and assume the problem is solved now that there are only “competent” engineers on the team. But to do so would be to misunderstand the problem entirely: competence is not an intrinsic property of the engineer. Rather, it's something that arises from the interaction between the person and the system that conditions them, and the system is the one we can change to durably affect future results. What kind of training are the on-call engineers given? Did the alert clearly convey the gravity of the incident? Was the engineer receiving more alerts than they could handle? These are the questions we should investigate in the postmortem. The answers to these questions are far more valuable than determining just that one person dropped the ball.
A blameless culture is essential for people to be unafraid to reach out for help during an emergency and to be honest and open in the resulting postmortem. This makes the postmortem more useful as a learning tool. Without a blameless culture, incident response is far more stressful. Your first priority becomes protecting yourself and your coworkers from blame instead of helping your users. This could come out as a lack of diligence, too. Investigations may be shallow and inconclusive if specifics could get someone—maybe you—fired. This ultimately harms the users of your service.
Blameless culture doesn’t happen overnight. If your organization does not already have a blameless culture, it can be quite a challenge to kick-start it. It requires significant support from all levels of management in order to succeed. But once a blameless culture has taken root, it becomes much easier to focus on identifying and fixing systemic problems.
What’s next?
If you haven’t already, start thinking about SLOs, postmortems, and blameless culture to discuss all of them with your coworkers. Think about what it would take to stabilize your reliability curve, and think about what your organization could do if you had that stability. And if you’re just getting started with SRE, learn more about developing your SRE journey.
Many thanks to Nathan Bigelow, Matt Brown, Christine Cignoli, Jesús Climent Collado, David Ferguson, Gustavo Franco, Eric Harvieux, Adrian Hilton, Piotr Hołubowicz, Ib Lundgren, Kevin Mould, and Alec Warner for their contributions to this post.
1. John Allspaw teaches a similar lesson with similar words in his contribution to the book Seeking SRE


