複雑さの解消: Spanner がマイクロサービス ベースのアーキテクチャを簡素化
Szabolcs Rozsnyai
Senior Staff Solutions Architect
Karthi Thyagarajan
Senior Staff Solutions Architect
※この投稿は米国時間 2024 年 5 月 4 日に、Google Cloud blog に投稿されたものの抄訳です。
最新のアプリケーション設計の分野では、シンプルであるだけでなく、スケーラブルでパフォーマンスが高く復元力のあるアーキテクチャを作成するためのさまざまな選択肢をデベロッパーが利用できます。Kubernetes(K8s)などのコンテナ プラットフォームでは、ユーザーがノードと Pod の仕様をシームレスに調整してサービスをスケールできます。このスケーラビリティは弾力性を犠牲にせずに済み、サービス ユーザーの一貫したパフォーマンスも確保します。それゆえ、Kubernetes が、中規模から大規模の組織で復元性のある分散システムを構築するための事実上の標準になったのも当然と言えます。
残念ながら、アプリケーション レイヤでシステム設計者が利用できる Kubernetes スペースの成熟度と標準化のレベルは、通常、これらのサービスを支えるデータベース レイヤには及びません。また、言うまでもなくデータベース レイヤは、弾力性、スケーラビリティ、高可用性、復元力も備えている必要があります。
さらに、これらのサービスが次の条件に当てはまる場合、課題は大きくなります。
-
(トランザクション)状態の管理が必要、または
-
複数の(マイクロ)サービスにわたる分散プロセスのオーケストレーションが必要
従来のリレーショナル データベース管理ソフトウェア(RDBMS)には、マイクロサービスの考え方に合わない副作用があり、かなり大きなトレードオフを伴います。以下のセクションでは、特にデータベース階層内でアプリケーション設計者が直面するスケーラビリティ、可用性、運用上の課題について詳しく掘り下げます。最後に、アプリケーション レイヤとデータベース レイヤの間でよく生じる暗黙の「インピーダンス ミスマッチ」を解消してマイクロサービス ベースのシステムを構築するために、Spanner がどのように役立つかについて説明します。
この問題をスケーラビリティと可用性の観点から、特に OLTP ワークロードに対応するデータベースに照らして検討します。変動性の高いワークロードに対応する際の複雑さを検討し、レプリカとシャーディングの両方技術を利用した高い需要の管理に伴う複雑さを明らかにします。
スケーラビリティと可用性が必要
従来のリレーショナル データベースをスケールする場合、キャッシュ戦略はさておき、次の 2 つの選択肢があります。
-
スケールアップ: データベースを垂直方向にスケールするには、通常、CPU 性能の向上、メモリの増加、より高速なディスクの追加によってリソースを増強します。ただし、このようなスケールアップ手順では、一般にダウンタイムが発生し、依存するサービスの可用性に影響が生じます。
-
スケールアウト: データベースを垂直方向にスケールアップすると、初めは効果的ですが、最終的には限界に達します。代替手段は、追加のリードレプリカの導入、シャーディング技術の利用、あるいはその両方の組み合わせにより、データベース トラフィックをスケールアウトすることです。これらの方法は独自のトレードオフを伴い、複雑さが生じ、運用上のオーバーヘッドを招きます。
可用性の点では、データベースにはメンテナンスが必要であり、定期的なダウンタイム期間の調整が欠かせません。リレーショナル データベースは、ハードウェアの欠陥、ネットワークのパーティション、データセンターの停止の影響を受けやすく、計画や対処の必要がある DR シナリオの課題が数多く発生します。
計画的ダウンタイムの例:
-
OS またはデータベース エンジンのアップグレードやパッチ
-
スキーマの変更 - ほとんどのデータベース エンジンには、スキーマの変更時にダウンタイムが必要です
計画外のダウンタイムの例:
-
ゾーンまたはリージョンの停止
-
ネットワークのパーティション
従来の RDBMS を処理する「成熟した」プラクティスの大半は、最新のアプリケーション設計原則に反しており、サービスの可用性とパフォーマンスに大きな影響を与える可能性があります。ビジネスの性質によっては、収益源や規制の遵守に影響を及ぼしたり、顧客満足度に悪影響を与えたりする可能性もあります。
RDBMS に関連する主な課題をいくつか見ていきましょう。
リードレプリカに関連する課題
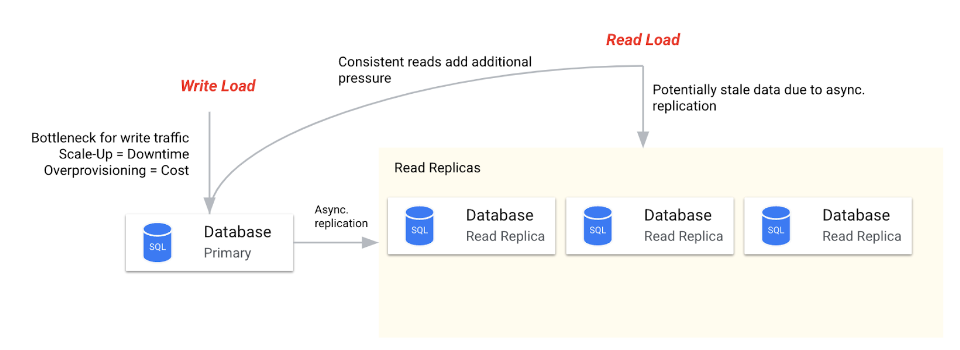
データベース リードレプリカは、読み取りオペレーションをスケールアウトして計画的ダウンタイムを軽減し、少なくともアプリケーション レイヤで読み取りを利用できるようにするための適切なツールです。
プライマリ データベース インスタンスの負荷を軽減するために、レプリカを作成して読み取り負荷を複数のマシンに分散し、より多くの読み取りリクエストを同時に処理することができます。
プライマリ レプリカとセカンダリ レプリカの間のレプリケーションは通常、非同期で行われます。このため、データがプライマリ データベースに書き込まれるときと、リードレプリカに複製されるときの間に時間差が生じる場合があります。その結果、読み取りオペレーションがレプリカに送信されると、少し古い(最新でない)データが取得される可能性があります。これはまた、整合性が保証されたクエリがプライマリ インスタンスに送信される必要があることを意味します。同期レプリケーションは複雑で、次のようにさまざまな問題を伴うため、特に地理的に分散したトポロジの場合、現実的ではありません。
-
システムのスケーラビリティが制限される: これは、すべての書き込みオペレーションがレプリカからの確認を待つ必要があるためで、パフォーマンスのボトルネックが発生し、レイテンシが増大します。
-
単一障害点が発生する: レプリカが使用できなくなったり問題が発生したりすると、プライマリ データベースの可用性にも影響を及ぼす可能性があります。
最後に、パフォーマンスの低下なしに単一のデータベースで処理できる書き込みトラフィックの量が制限されているため、書き込みスループットがボトルネックになる可能性があります。書き込みのスケーリングには、垂直方向のスケーリング(ハードウェア性能の向上)またはシャーディング(複数のデータベースへのデータ分割)が必要です。これにより、ダウンタイムや追加費用に加え、非線形に増大する運用上のトイルによる制限が発生する可能性があります。では、シャーディングの課題をもう少し詳しく見てみましょう。
シャーディングの課題
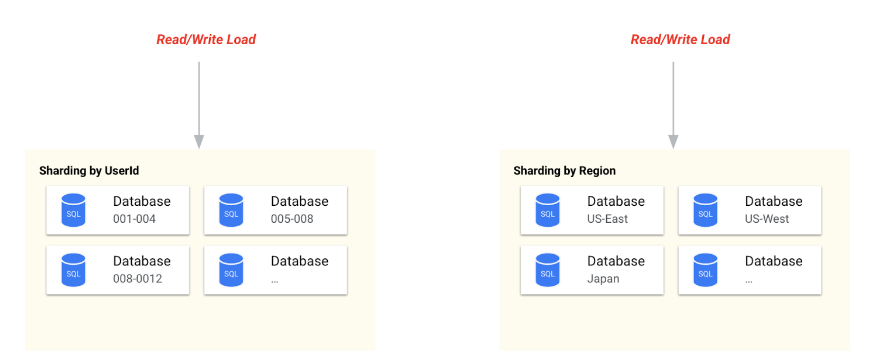
シャーディングはデータベースのスケーラビリティを実現する優れたツールです。正しく実装されると、アプリケーションが読み取りトランザクションと書き込みトランザクションを大量に処理できます。ただし、シャーディングに課題がないわけではありません。独自の複雑さが伴うため、慎重に行う必要があります。
データベースをシャーディングする方法はいくつかあります。たとえば、次の方法で分割できます。
-
ユーザー ID 範囲
-
リージョン
-
チャネル(ウェブ、モバイルなど)、その他
上術の例で示すように、ユーザー ID やリージョンによるシャーディングでは、小さなデータ範囲が個々のデータベースでホストされ、トラフィックがこれらのデータベースに分散されるため、パフォーマンスが大幅に向上します。
考慮すべきポイント:
-
「適切な」種類のシャーディングの決定: シャーディングの主な課題の一つは、初期設定です。シャーディング キー(ユーザー ID、リージョン、その他の属性)を決定するには、データアクセス パターンを深く理解する必要があります。シャーディング キーの選択が適切でないと、データの分散が不均等になり(「不均等なシャード」と呼ばれます)、シャーディングによるパフォーマンス上のメリットが大幅に損なわれかねません。
-
データの完全性: これも重要な問題です。データが複数のシャードに分散されていると、外部キー関係を維持しにくくなります。複数のシャードにまたがるトランザクションは複雑になり、レイテンシの増加や完全性の低下につながる可能性があります。
-
運用の複雑さ: シャーディングによって運用が複雑になります。複数のデータベースを管理するには、メンテナンス、バックアップ、モニタリングに対するより高度なアプローチが必要です。各シャードの個別バックアップが必要にある場合があり、シャードされたデータベースを一貫した状態に復元することは簡単にはいかない可能性があります。
-
再シャーディング: アプリケーションが大きくなるにつれて、選択したシャーディング スキームの変更が必要になる場合があります。このプロセスには、新しいシャードセット間でのデータの再分散が含まれるため、時間がかかり、リスクを伴う可能性があり、移行中に大幅なダウンタイムやパフォーマンス低下が発生することが少なくありません。
-
開発の複雑さが増大: デベロッパーはデータの分散を考慮する必要があるため、アプリケーション ロジックが複雑になることがあります。つまり、クエリを適切なシャードにルーティングし、部分的な障害に対応し、シャード間で動作する必要のあるトランザクションの整合性を維持するために、追加のロジックが必要になる可能性があります。
複雑さとオペレーションの急激な増加
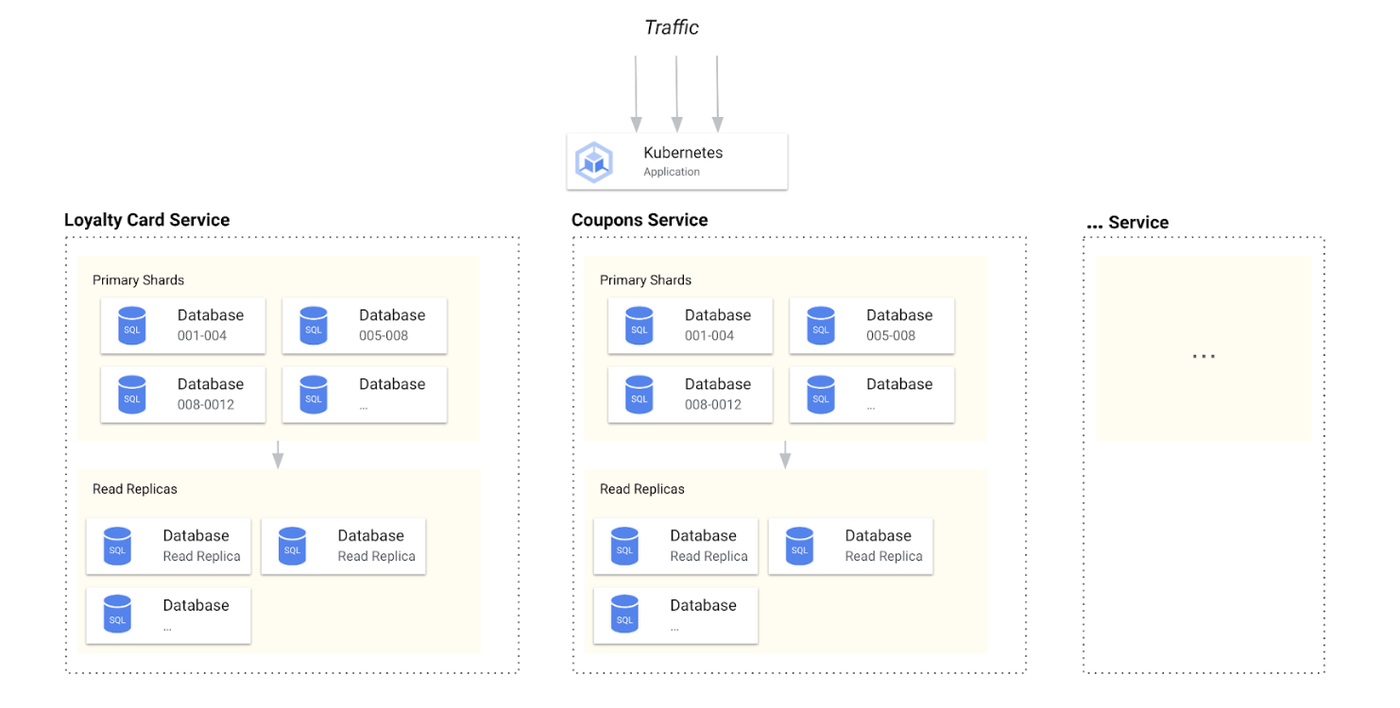
時が経つにつれて、データベースの複雑さはトラフィックの増加とともに増大し、運用のトイルがさらにかかります。大規模なシステムで費用対効果の高いスケーラビリティとパフォーマンスを確保するには、シャーディングと接続済みのスケールアウト リードレプリカの組み合わせが必要になる場合があります。
この組み合わせによるデュアル戦略アプローチは、増加するトラフィックの処理には効果的ですが、システムのアーキテクチャが大幅に複雑になります。上の図は、サービスを支えるトランザクション リレーショナル データベースにスケーラビリティと可用性の追加が必要なことを示しています。DR(バックアップなど)や地理冗長に関するすべての詳細は含まれておらず、ゼロから低の RPO / RTO 要件にも対応していません。
さらに、上述のデュアル戦略アプローチにより、次の問題が生じる可能性があります。
-
サービス メンテナンスの容易さに悪影響を与える
-
運用上の要求が増大する
-
インシデントの解決に関連するリスクが上昇する
NoSQL によって対応できないのか?
NoSQL データベースは、従来の RDBMS に伴う上述の制限に対応するため、2000 年代初めに登場し始めました。ビッグデータとウェブスケール アプリケーションの新時代において、NoSQL データベースは、半構造化データの量の増大によってもたらされたスケーラビリティ、パフォーマンス、柔軟性、可用性の課題を克服するために設計されました。
ただし、NoSQL が行った主なトレードオフは、健全なリレーショナル モデルや SQL に加え、ACID 準拠のトランザクションのサポートを廃止することでした。とはいえ、多くの著名なシステム アーキテクトは、OLTP ワークロード用のこうした実績のあるリレーショナル コンセプトを捨てるという考えに疑問を呈しています。依然としてミッション クリティカルなアプリケーションを支える重要な機能を放棄することになるからです。そのため、MongoDB の ACID トランザクションや Cassandra のクエリ言語(CQL)など、リレーショナル データベース機能を NoSQL データベースに導入または再導入する傾向が最近あります。
Spanner の出番
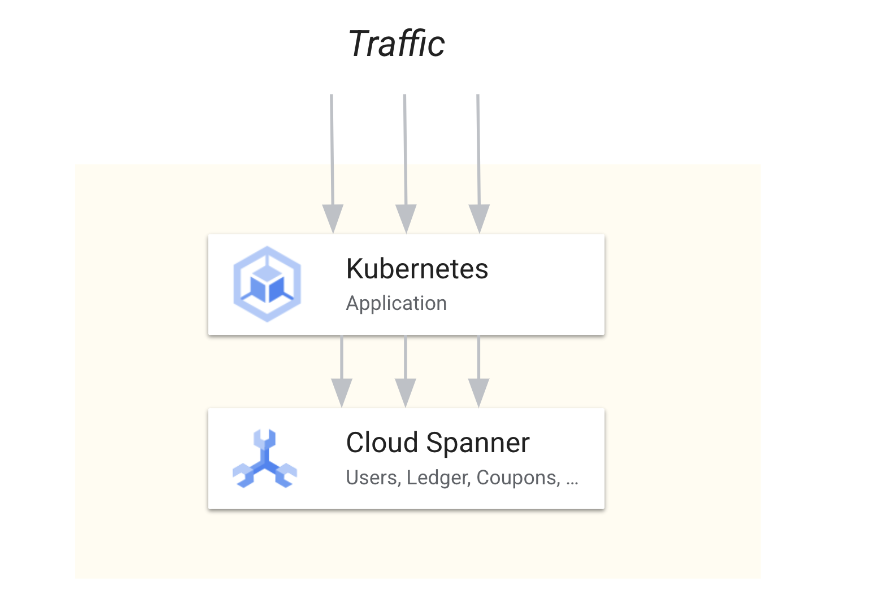
Spanner は、こうした複雑さを大幅に減らし、シンプルでメンテナンスしやすいアーキテクチャの促進に役立ち、上述のような妥協がほぼありません。リレーショナルのコンセプトと機能(SQL、ACID トランザクション)をシームレスな水平方向のスケーラビリティと組み合わせることで、マイクロサービス ベースのアプリケーションを設計する際に必要な最大 99.999% の可用性を備えた地理冗長が実現します。
Spanner がマイクロサービスのみに適していると主張しているわけではないことを強調しておきます。Spanner がマイクロサービスに適している特徴はすべて、モノリシック アプリケーションにも適しています。
まとめると、Spanner 上に構築されたマイクロサービス アーキテクチャを使用すれば、ソフトウェア アーキテクトはアプリケーションとデータベースの両方が次のような機能を提供するシステムを設計できます。
-
将来の成長シナリオに対する「スケール保証」
-
トラフィックの急増に対処する簡単な方法
-
Spanner の弾力性の高い迅速なコンピューティング プロビジョニングによる費用対効果
-
地理冗長を備えた最大 99.999% の可用性
-
ダウンタイム期間なし(メンテナンスやその他のアップグレード向け)
-
保存データと転送データの暗号化などのエンタープライズ クラスのセキュリティ
-
トランザクション ワークロードに対応する機能
-
デベロッパーの生産性向上(SQL など)
Spanner の独自性や使用例について詳しくは、こちらをご覧ください。または、90 日間無料で、あるいは月額わずか 65 米ドルで、中断を伴う再構築やダウンタイムなしでビジネスの成長に合わせて拡張できる本番環境対応のインスタンスを実際にお試しください。
ー Spanner、シニア スタッフ ソリューション アーキテクト Szabolcs Rozsnyai
ー Spanner、シニア スタッフ ソリューション アーキテクト Karthi Thyagarajan

