AlloyDB Omni で発揮される AlloyDB AI のパワー
Google Cloud Japan Team
※この投稿は米国時間 2023 年 10 月 12 日に、Google Cloud blog に投稿されたものの抄訳です。
はじめに
生成 AI は実際に仕事で使えるようになっているでしょうか?あるいはまだ、不完全なデモで、一部の機能を使って楽しむ程度のものでしょうか?
金融、小売、エンタメなど、いくつかの業界の例を見てみると、AI によって運用データを別の角度から見ることが可能になり、また特定の作業の負荷が減ることで生産性が向上するなどの効果が見られます。従来は人が行っていたルーティン ワークの多くを、この新しい技術によって簡素化し効率化できます。また、生成 AI はアプリケーションへの組み込みがさらに簡単になっています。デベロッパー ツールやデータベースのネイティブ インターフェースなど、使い慣れているツールからモデルを直接使用できるようになったためです。PostgreSQL 互換リレーショナル データベースである AlloyDB Omni と AlloyDB AI 機能を組み合わせて使用する例を見てみましょう。AlloyDB AI は、最近プレビューでお知らせしたものです。
AI はどのように役立つか
オンライン販売を行っていて、たとえば購入者により良いエクスペリエンスを提供する、製品の詳細情報を提供する、あるいは製品に関する短い説明をサマリーとして追加するなどの目的で、特別な情報をデータに加えたいとします。これはアイテムの数が少なければ難しくないでしょうが、在庫にある何千もの製品やタイトルに対して行うとなると、多大な労力が必要になります。このプロセスを改善して効率を高めるには、どうすればよいでしょうか?これは生成 AI の優れたユースケースになりそうです。
データベースから AI モデルを呼び出して、これらの目標を達成できるとしたらどうでしょうか?しかも、AlloyDB のダウンロード可能なバージョン、AlloyDB Omni を使用して、こうした目標をデータセンターやクラウドで行えるとしたらどうでしょうか?AlloyDB の生成 AI 機能セットである AlloyDB AI を使用すれば、これらの呼び出しをデータベースから直接行うことができるのです。その仕組みを説明しましょう。
今回の例では、レンタルおよびストリーミング サービス向けのバックエンドとして AlloyDB Omni データベースを使用しています。このデータベースでは、titles という名前のテーブルが、視聴可能な番組の一覧を表しています。このテーブルには、title と description という列があります。説明が短めなので、それぞれの番組の詳細を伝えるため、説明を拡張することにします。生成 AI 用の Vertex AI 基盤モデルの一つである「text-bison」大規模言語モデル(LLM)を使用して、拡張された説明を書き込みます。そしてタイトルと元の説明をプロンプトとして、AlloyDB Omni データベースからモデルを直接呼び出します。
デプロイとインストール
まず AlloyDB Omni をデプロイします。インストールとセットアップの手順は簡単であり、ドキュメントで詳しく説明されているので、ここでは繰り返しません。ただし、最終的に「database-server install」コマンドを実行する前に、Vertex AI の統合を有効にする手順を行う必要があります。
概要レベルの視点では、AlloyDB Omni インスタンスでは Vertex AI API を呼び出せる必要があり、また Google Cloud での認証と認可が要求されます。これらのステップについては、AlloyDB Omni のドキュメントで説明されています。
- Vertex AI API を有効にする Google Cloud Project ではサービス アカウントが必要です。
- 次に、Vertex AI を使用する権限をサービス アカウントに付与します。
- JSON 形式でサービス アカウント キーを作成し、AlloyDB Omni データベース サーバーに保存します。
- 次に、キーを保存した場所を alloydb cli の「database-server install」コマンドに適用して、インスタンスでの Vertex AI 統合を有効にします。
アーキテクチャの概要レベルの図を次に示します。
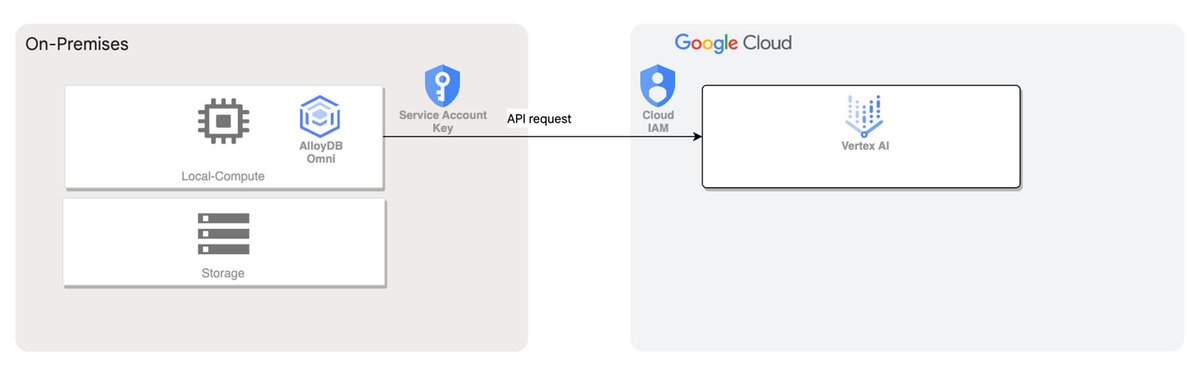
AlloyDB Omni ML の統合
Vertex AI との統合を有効にした後は、カスタムまたはビルド済みの基盤 Vertex AI モデルをアプリケーションで使用できます。
デモの実施
1 回目の試行
例に戻りましょう。デモクエリを実行するために、いくつかの映画とテレビ番組のタイトルをサンプルの AlloyDB Omni データベースに読み込んであります。「titles」テーブルには title 列があり、番組の名前が入力されています。description 列には映画または番組の短い説明が入力されています。「Pinocchio」の元の説明は次のとおりです。
自分のウェブサイトでは、それぞれの映画または番組の説明をもう少し詳しくしたいと思います。そのために、追加の列を作成し、その列に、Google の「text-bison」モデルへのプロンプトに基づいて Vertex AI が生成したデータを入力します。前述のとおりの title 列と description 列を使用しています。
改善の余地はあるか
プロンプト自体は十分にシンプルで、大筋は “Can you create a summary for the <column title value> based on the following description - <column description value>?”(「次の説明 - <description 列の値> に基づいて <title 列の値> のサマリーを作成してください。」)のようになっています。このプロンプトは、“ml_predict_row” 関数内の 2 番目の引数として使用されます。最初の引数は、Vertex AI モデルのエンドポイント、つまり Google Cloud 上のモデルの場所です。ここでは、“publishers/google/models/text-bison” です。
そして、これが「Pinocchio」での関数によって返される結果です。
情報が増えていて十分なように見えますが、ご存じのように、生成 AI ではプロンプトによってすべてが決定されます。もう少し細かく質問したらどうなるでしょうか。プロンプトを少し変更して、「elaborate」という語を追加してみます。結果は次のようになります。
この出力では「Pinocchio」のプロットのほとんど全体が示されるため、その点で注意が必要になります。モデルは、リクエストに対する応答の関連性の程度を示す、temperature などの多くのパラメータと、モデル固有のその他のパラメータを受け入れます。「text-bison」モデルとパラメータについては、ドキュメントで詳しく説明されています。
どこから始めるべきか
タスクの迅速化に AlloyDB AI がどのように役立つかをシンプルな例で示しましたが、さらに多くのことを行って、ビジネスの要件を満たし、アイデアを実装できます。Vertex AI には、さまざまなタイプのデータに応じて値を返すために使用できる、一連の基盤モデルがあります。たとえば、類似する値のベクトル検索を行うためのモデルや、画像での作業に使用できるモデルがあります。詳細については、Vertex AI のドキュメントをご覧ください。
練習として、独自のデータを用意し、Vertex AI のドキュメントに組み込まれているチュートリアルを使用して、実際の状況に合わせて基盤モデルをチューニングできます。Tune Foundation Model のチュートリアルから始めることをおすすめします。
Vertex AI foundation model tuning.
AlloyDB を使ったことがない場合は、クラウドベース バージョンの無料トライアル版が適しているかもしれません。AlloyDB Omni の無料デベロッパー版をダウンロードすることもできます。開始するには、このページに移動して、無料デベロッパー版を選択してください。
-データベース、Cloud アドボケイト Gleb Otochkin