AI を使って優れた SQL を作成する: Text-to-SQL 手法の説明
Per Jacobsson
Principal Software Engineer
Try Gemini 3.1 Pro
Our most intelligent model available yet for complex tasks on Gemini Enterprise and Vertex AI
Try now※この投稿は米国時間 2025 年 5 月 17 日に、Google Cloud blog に投稿されたものの抄訳です。
組織が意思決定を行うには、迅速かつ正確でデータドリブンな分析情報が必要です。そのデータにアクセスする方法の中心にあるのが SQL です。Google は、Gemini を使用することで自然言語から直接 SQL を生成できます(これを Text-to-SQL と呼びます)。この機能により、開発者やアナリストの生産性が向上し、技術系以外のユーザーが必要なデータを直接操作できるようになります。
現在、次のように多くの Google Cloud プロダクトで Text-to-SQL 機能が利用できます。
-
Cloud SQL Studio(Postgres、MySQL、SQLServer)、AlloyDB Studio、Cloud Spanner Studio の「コーディング サポート」機能
-
AlloyDB AI のデータベースへの直接自然言語インターフェース(現在のところ公開プレビュー版として提供中)
-
Vertex AI では、これらのプロダクトの基盤となる Gemini モデルに直接アクセス可能
最近では、推論と合成の機能を備えた Gemini のような強力な大規模言語モデル(LLM)が、Text-to-SQL の分野における目覚ましい進歩を促しています。本シリーズの初回となるこのブログ投稿では、Google Cloud の Text-to-SQL エージェントの内部技術について説明します。コンテキストの構築とテーブルの取得に対する最先端のアプローチ、LLM-as-a-Judge 手法によって Text-to-SQL の品質を効果的に評価する方法、LLM のプロンプト作成と後処理に対する最適なアプローチ、システムが事実上保証された正解を提供可能にする手法にアプローチする方法を取り上げます。
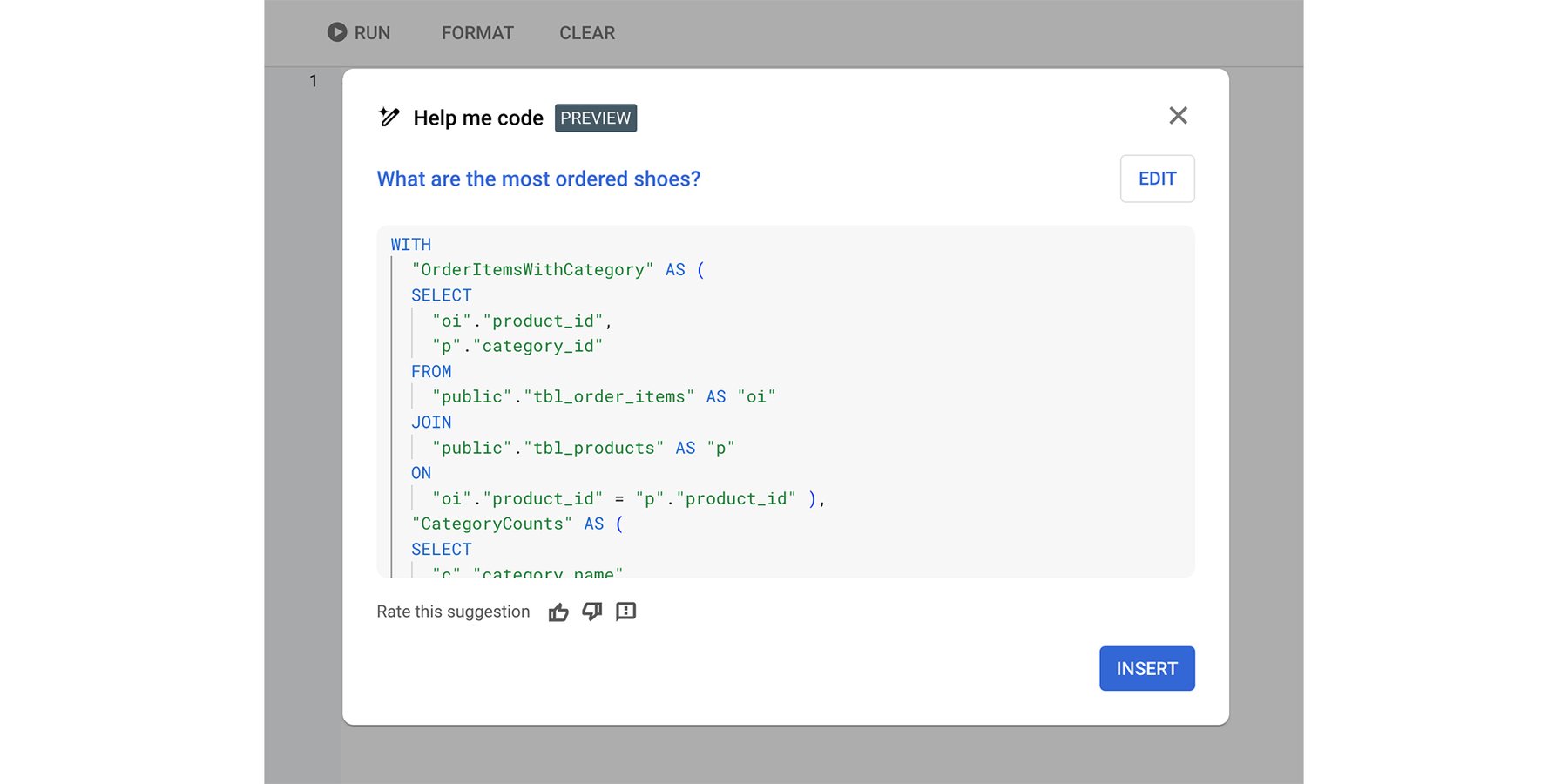
Cloud SQL Studio の「コーディング サポート」機能はテキスト プロンプトから SQL を生成する
Text-to-SQL テクノロジーの課題
Gemini 2.5 のような最新の LLM は、自然言語で提示された複雑な質問を、結合、フィルタ、集計などの難しいコンセプトを含む機能的な SQL に変換する推論機能を備えています。
これを実際に確認するには、Vertex AI Studio で簡単なテストを実行します。「商品と注文を含むデータベース スキーマがあります。靴の注文数を示す SQL クエリを作成してください」というプロンプトを入力すると、Gemini は仮定するスキーマに対して次の SQL を生成します。
適切と思われるクエリができました。しかし、このような単純な例だけでなく、実際のデータベースと実際のユーザーの質問に対して、Gemini を Text-to-SQL に使用するとどうなるでしょうか。この場合、問題はもっと難しくなります。モデルは、次の目的を果たす方法で補完する必要があります。
-
ビジネス固有のコンテキストを提供する
-
ユーザーの意図を理解する
-
SQL 言語間の違いを管理する
これらの課題をそれぞれ詳しく見ていきましょう。
問題 1: ビジネス固有のコンテキストを提供する
データ アナリストやエンジニアと同じように、LLM は正確な SQL を生成するために、かなりの量の知識、つまり「コンテキスト」を必要とします。コンテキストには明示的なもの(スキーマの構造、関連する列、データ自体の内容)と、暗黙的なもの(データの正確でセマンティックな意味、特定のビジネスケースにおける意味)があります。
特殊なモデル トレーニング(つまり、ファインチューニング)は通常、この問題に対するスケーラブルな解決策ではありません。すべてのデータベースやデータセットの形状をトレーニングし、スキーマやデータの変更に対応し続けることは、困難で費用もかかります。ビジネスに関する知識やセマンティクスは、そもそも十分に文書化されていないことが多いため、トレーニング データに変換するのが困難です。
たとえば、pcat_extension テーブルの cat_id2 = 'Footwear' が、「対象の商品は靴の一種である」を意味することを知らなければ、世界で最も優秀な DBA であっても、靴の売上をトラッキングする正確なクエリを作成することはできません。LLM についても同様です。
問題 2: ユーザーの意図を理解する
自然言語は SQL ほど厳密ではありません。エンジニアやアナリストなら、曖昧な質問に直面したときに、さらに情報が必要であることを認識し、適切なフォローアップの質問を行うことができます。一方、LLM は回答を返そうと努める傾向があり、質問が曖昧な場合はハルシネーションを起こしやすくなります。
例: 「最も売れている靴は何ですか?」という質問について考えてみましょう。ここで、ビジネスやアプリケーションのコンテキストにおいて「最も売れている」が実際に何を意味するのかという点が明らかに曖昧になっています。注文数が多い靴でしょうか?収益が最も多い靴のブランドでしょうか?また、SQL は返品数もカウントする必要があるでしょうか?レポートには何種類の靴を記載すればいいでしょうか?などです。
加えて、ユーザーによって必要な回答の種類も異なります。技術アナリストや開発者が漠然とした質問をしている場合は、100% 正しくなくても妥当な SQL クエリを提示するのが良い出発点となります。一方、技術に詳しくなく、SQL についてあまり理解していないユーザーの場合は、正確かつ正しい SQL を提示することがより重要になります。フォローアップの質問によって曖昧さを解消し、回答に至った理由を説明して、ユーザーが求めている内容へと導けることが重要です。
問題 3: LLM 生成の限界
LLM は、デフォルトの状態で、クリエイティブな文章の作成、ドキュメント内の情報の要約や抽出といったタスクに特に優れています。しかし、モデルによっては、特にわかりにくい SQL 機能の場合、正確な指示に従い、詳細を的確に処理することが困難な場合があります。LLM が正しい SQL を生成するには、多くの場合、複雑な仕様に厳密に従う必要があります。
例: SQL 言語間の違いを考えてみましょう。この違いは、Python や Java などのプログラミング言語間の違いよりも微妙です。簡単な例として、BigQuery SQL を使用している場合、タイムスタンプ列から月を抽出する正しい関数は EXTRACT(MONTH FROM timestamp_column) です。一方、MySQL を使用する場合は、MONTH(timestamp_column) となります。
Text-to-SQL 手法
Google Cloud は、常に Text-to-SQL エージェントの品質向上に努めています。上述の問題に対処するため、さまざまな手法を取り入れています。
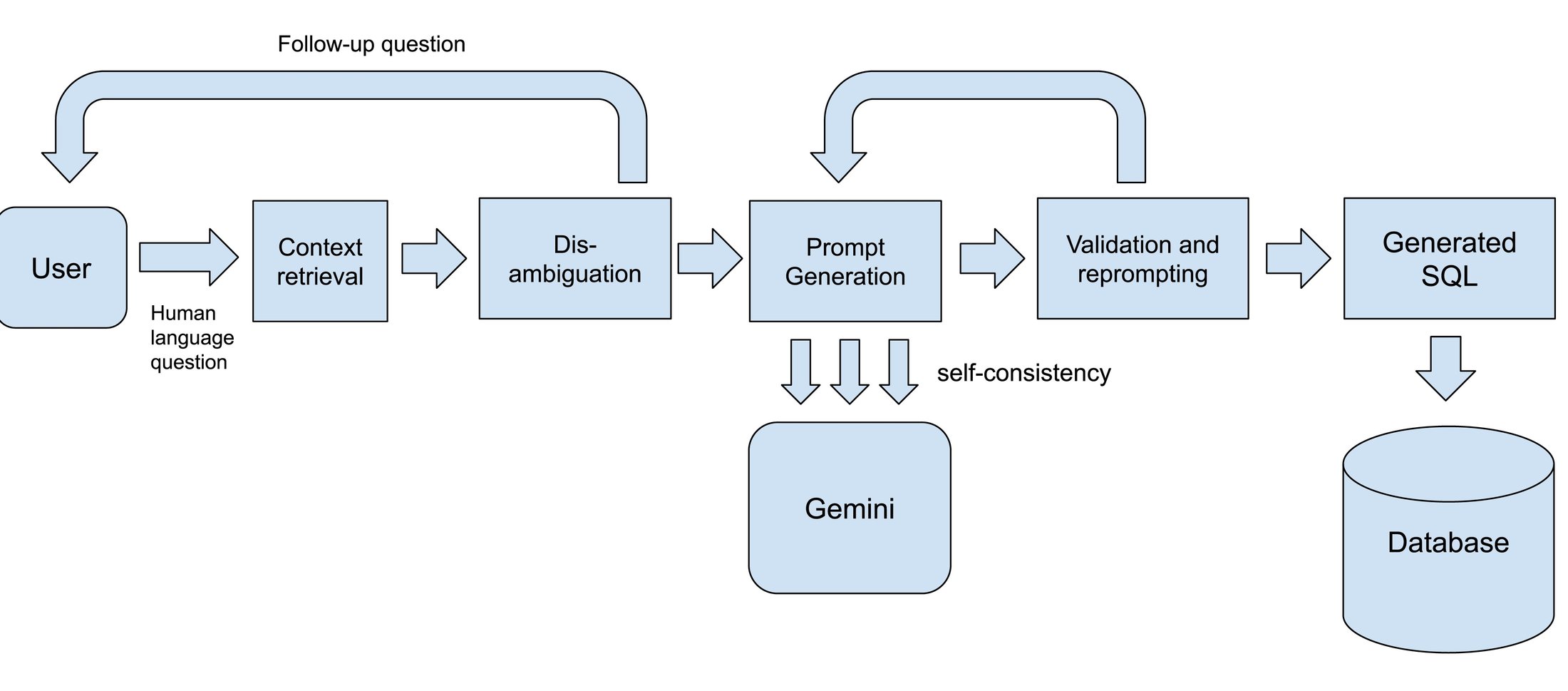
The text-to-SQL architecture
これらの手法のいくつかを詳しく見てみましょう。
SQL 対応モデル強力な LLM は Text-to-SQL ソリューションの基盤であり、Gemini ファミリーのモデルには、高品質なコードと SQL を生成してきた実績があります。Google Cloud は、実際の SQL 生成タスクに応じて、モデル バージョンを組み合わせて使用しています。カスタマイズされたファインチューニングを採用するケースもあります。たとえば、特定の SQL 言語で十分に優れた SQL をモデルが生成できるようにするためです。
LLM を使用した曖昧性除去曖昧性除去では、明確さが不十分な質問に直面したときに、システムが明確化のための質問で応答します(前述の例では、「最も売れている靴は何ですか?」という質問に対して、Text-to-SQL エージェントが「靴は注文数量と収益のどちらで並べ替えますか?」というフォローアップの質問を返すようにします)。ここでは通常、LLM 呼び出しをオーケストレートして、まず利用可能なスキーマとデータで質問に実際に答えることができるかどうかを識別し、できない場合はユーザーの意図を明確にするために必要なフォローアップの質問を生成します。
取得とコンテキスト内学習前述のように、モデルには SQL の生成に必要なコンテキストを提供することが重要です。Google Cloud は、さまざまなインデックス作成と取得の手法を使用しています。まず、関連するデータセット、テーブル、列を識別します。通常は、ベクトル検索を使用して多段階のセマンティック マッチングを行い、その後、追加の有用なコンテキストを読み込みます。プロダクトによっては、ユーザーが提供するスキーマ アノテーション、類似した SQL の例、特定のビジネスルールの適用方法、ユーザーが同じデータセットに対して実行した最近のクエリのサンプルなどが関係します。これらのデータはすべてプロンプトとして整理されてから、モデルに渡されます。Gemini では、長いコンテキスト ウィンドウがサポートされており、モデルが大きなスキーマやその他のコンテキスト情報を処理できるため、新しい機能が実現しています。
検証とプロンプトの再作成高品質のモデルであっても、LLM による SQL の生成には、非決定性や予測不可能性が多少なりとも伴います。この問題の対処においては、クエリ解析や、生成された SQL のドライランなどの AI 以外のアプローチがモデルベースのワークフローをうまく補完することがわかりました。LLM が重要なものを見逃した場合、明確で決定的なシグナルを受け取り、それをモデルに再度渡して 2 回目のパスを実行できます。誤りの例といくらかのガイダンスが提供されると、モデルは通常、誤りを修正できます。
自己整合性自己整合性の考え方は、1 回の生成ラウンドに依存するのではなく、同じユーザーの質問に対して複数のクエリを生成し、場合によっては異なるプロンプト手法やモデルのバリアントを使用して、すべての候補から最適なものを選択するというものです。ある回答が特に適切であると複数のモデルの認識が一致した場合、最終的な SQL クエリが正確で、ユーザーが求めているものに一致する可能性が高くなります。
評価と改善の測定
AI を活用した機能の改善は、堅牢な評価で決まります。学術コミュニティで開発された Text-to-SQL のベンチマーク(よく利用されている BIRD-bench など)は、モデルとエンドツーエンドのシステム パフォーマンスを理解するために非常に有用なベースラインとなっています。しかし、これらのベンチマークは多くの場合、現実の幅広いスキーマやワークロードを表すという点では不十分です。この問題に対処するために、Google はベースラインをさまざまな方法で拡張する独自の合成ベンチマークを開発しました。
カバレッジ: 幅広い SQL エンジンとプロダクト(言語とエンジン固有の機能の両方)をベンチマークでカバーしています。これには、クエリだけでなく、DDL、DML、その他の管理ニーズ、一般的な使用パターンを代表する質問(より複雑なクエリやスキーマを含む)も含まれます。
指標: ユーザー指標とオフライン評価指標を組み合わせ、人間による評価と自動評価の両方を使用しています。特に、LLM-as-a-Judge 手法は、費用を削減しながら、曖昧で不明確なタスクのパフォーマンスを把握することができます。
継続的な評価: Google のエンジニアリング チームとリサーチチームは、評価を使用して、新しいモデル、新しいプロンプト手法、その他の改善を迅速にテストできるようにしています。アプローチに見込みがあり、追求する価値があるかどうかを示すシグナルを迅速に得ることができます。
これらの手法を組み合わせることにより、Google Cloud のラボだけでなくお客様の環境でも、Text-to-SQL が大幅に改善されます。ご自身の環境に Text-to-SQL を組み込む準備を整えながら、Google Cloud の Text-to-SQL ソリューションの詳細情報もご確認ください。Gemini の Text-to-SQL は、BigQuery Studio、CloudSQL、AlloyDB、Spanner Studio と AlloyDB AI で今すぐお試しいただけます。
-プリンシパル ソフトウェア エンジニア、Per Jacobsson

