Firestore の新しい高度なクエリエンジンでアプリケーションを強化

Minh Nguyen
Group Product Manager, Google Cloud
Joseph (JD) Batchik
Staff Software Engineer, Google Cloud
※この投稿は米国時間 2026 年 1 月 21 日に、Google Cloud blog に投稿されたものの抄訳です。
価値あるデータベースの特徴は、格納されているデータを簡単にクエリできることです。これにより、デベロッパーはカスタマイズされた複雑なユーザー エクスペリエンスをアプリケーション内で構築できます。先週、Google Cloud のエンタープライズ クラスのスケーラブルなドキュメント データベースである Firestore が大きく進化しました。高度なクエリエンジンが導入され、より洗練されたアプリケーションを構築できるようになりました。
Firestore ネイティブ モードの一部として利用できるこの強力なエンジンは、パイプライン オペレーションと呼ばれる新しいクエリ機能を 100 個以上備えています。これらの機能はプレビュー版として公開されており、複雑なクエリをデータベース内で直接効率化します。これに加えて、インデックス作成の厳密な制御のリリースや、Query Explain や Query Insights などのオブザーバビリティ ツールの更新により、パフォーマンスのきめ細かい制御が可能になりました。これらの優れた機能はすべて、Firestore Enterprise エディションで利用できます。このエディションは料金モデルの透明性が高く、費用削減を図ることも可能です。これらの点すべてが、運用のオーバーヘッドを削減しながら、多くの次元にわたってデータをクエリ、変換、フィルタできる、表現豊かな高パフォーマンス アプリケーションの構築に役立ちます。同時に、Firestore 独自のサーバーレス基盤、マルチリージョン レプリケーション、事実上無制限のスケーラビリティのメリットを享受できるため、データベース管理の複雑さから解放され、イノベーションに専念できます。
Firestore は、60 万人を超える活気あるデベロッパー コミュニティを持ち、そのシンプルさが長年にわたり高く評価されてきました。2019 年には、ネイティブ モードの Firestore Standard エディションが、自動生成されたインデックスを使用して高パフォーマンスを保証するシンプルなクエリ インターフェースによってコラボレーション アプリケーションの開発を効率化しました。しかし、この簡素化されたクエリエンジンは、クエリの実行においてインデックス作成に大きく依存し、多くの場合、アプリケーションのライフサイクル全体で事前計画を必要とします。Enterprise エディションに高度なクエリエンジンが導入されたことで、デベロッパーはインデックスが明示的に存在するかどうかに関係なく、表現豊かなアプリケーションを構築できるようになりました。これは特に、e コマース、インタラクティブ ゲーム、コンテンツ管理、高度なユーザー パーソナライズなどの要求の厳しいソリューションに適しています。改良されたクエリエンジンにより、パイプライン オペレーションの作成が容易になります。複雑な集計、配列に対する直接的なクエリ、高度な文字列照合機能、詳細なフィルタリング オプションのサポートなど、洗練された新しいステージと式が用意されています。
新しいクエリエンジンとパイプライン オペレーションのエクスペリエンス
これを実現するため、Google は Firestore の既存の SDK を更新し、パイプライン オペレーションのサポートを拡大しました。現在は、集計、グループ化、フィルタリングなどの重要なタスクのために、多数のステージをスムーズに連結できるようになりました。クエリの実行にインデックスが必須とならないため、パフォーマンスを最適化するためにインデックスを作成するタイミングを自由に決められます。パイプライン オペレーションの例を見てみましょう。
注: この例は、Firestore のデータモデルと既存のクエリ方法について理解していることを前提としています。
ユーザーがレシピにハッシュタグを追加できる既存の料理レシピ アプリケーションで、人気のあるハッシュタグを特定するとします。レシピ本文のような重要なデータについては、レシピをいくつかのフィールドを持つドキュメントとして表せます。ハッシュタグは文字列のみで表せるため、レシピ ドキュメントに文字列の配列として直接追加できます。
Firestore ユーザーは、既存のコア オペレーションを使用して、レシピ内で特定のハッシュタグをクエリできます。しかし、クエリ中にドキュメント内から配列データを抽出して集計する直接的な方法は、パイプライン オペレーション以前にはありませんでした。
パイプライン オペレーションを使用すると、配列を直接「ネスト解除」できます。これにより、人気のあるハッシュタグを簡単に特定してユーザーに提案できます。JavaScript を使用してこれを実装する方法の例を以下に示します。
また、Firestore Enterprise エディションでは、より幅広いインデックス タイプ(単一フィールド、複合、スパース、非スパース、一意のインデックスなど)がサポートされており、クエリのパフォーマンスをさらに最大化できます。さらに、インデックスを作成するタイミングを制御できるため、Standard エディションの自動単一フィールド インデックスと比較して、全体的な書き込みパフォーマンスとストレージ使用率が向上します。これにより、書き込みオペレーション中のインデックス ファンアウトを軽減できます。
インデックス作成は完全にカスタマイズ可能であるため、Enterprise エディションには、Query Explain と Query Insights という高度なオブザーバビリティ ツールも用意されています。これらのツールは、デベロッパーがインデックス不足を特定して、クエリを確認、最適化できるように特別に構築されています。Query Explain を使用すると、デベロッパーはクエリをプロファイリングして、クエリ プランナーの詳細を包括的に把握するとともに、実行の統計情報を確認できます。これには、課金情報などの重要なデータや、クエリの実行パスに関するシステムレベルの詳細な可視性が含まれます。
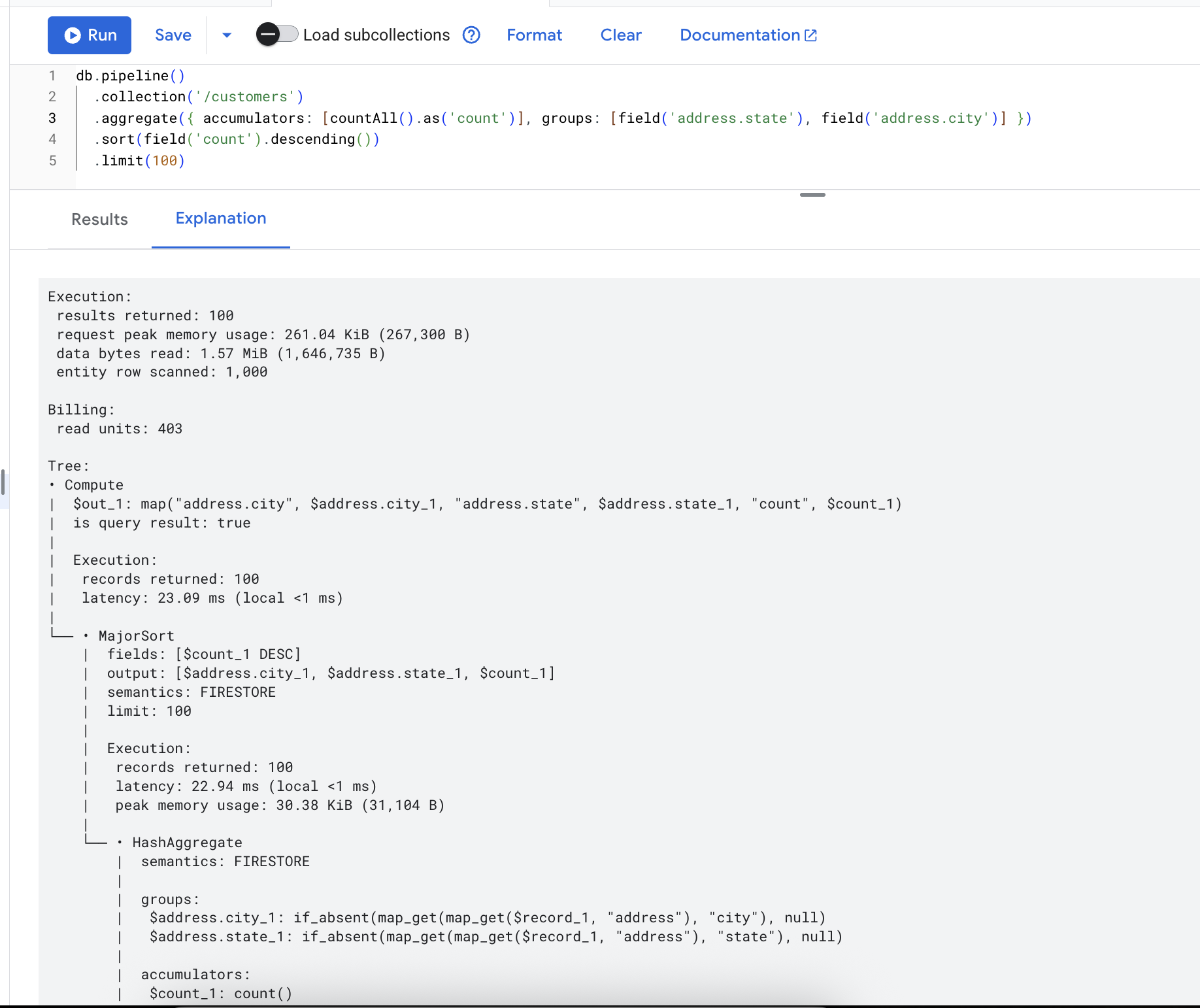
Query Explain でプロファイリングすることで、クエリでインデックスが使用されているかどうかを確認し、その合計実行指標を分析する。
これに加えて、Query Insights では、レイテンシが高いクエリや頻繁に実行されているクエリがないかどうかを継続的にモニタリングし、調整が必要かどうかを検討できます。Query Insights ダッシュボードを利用することで、インデックスを導入すればパフォーマンスの向上が可能なクエリを特定できます。
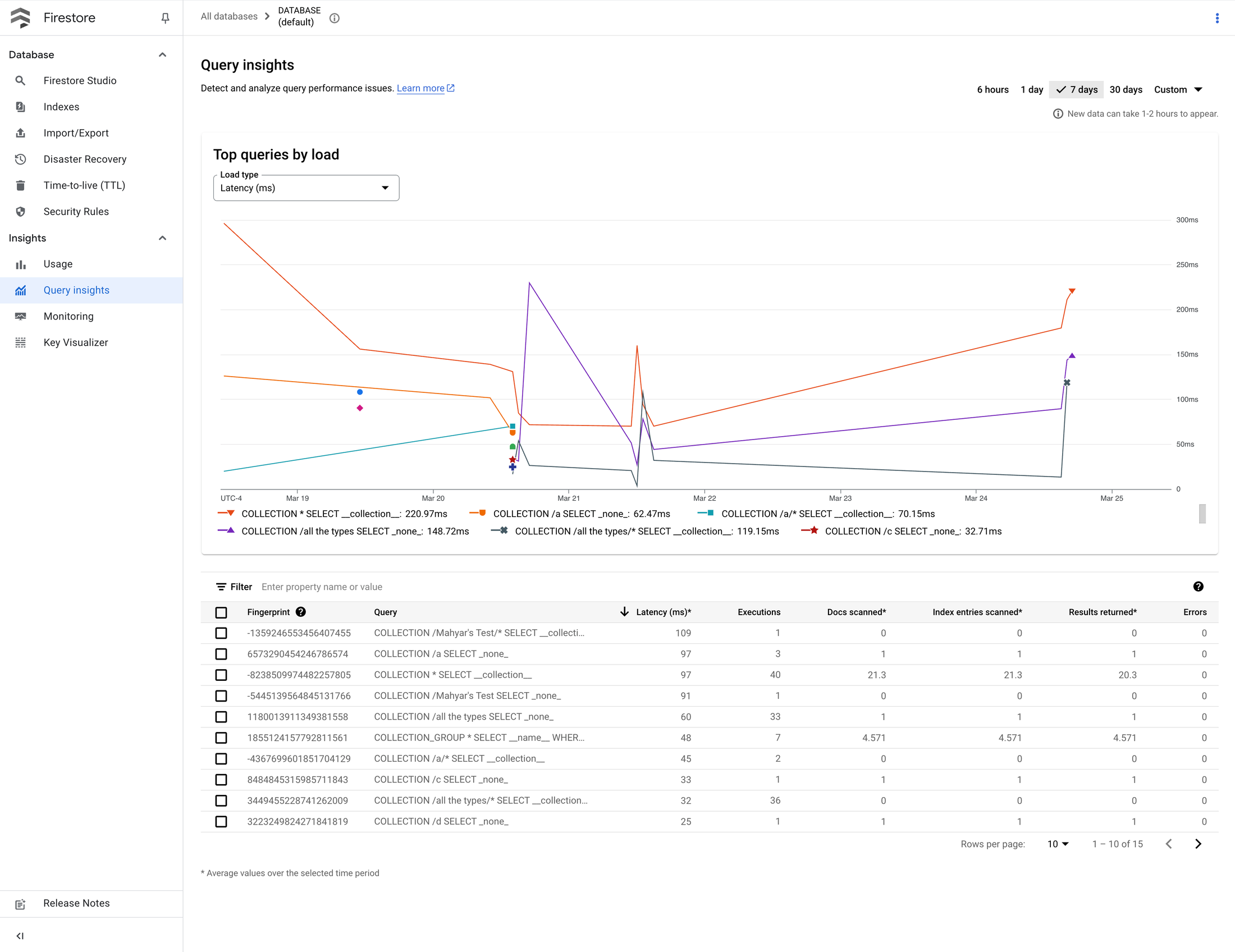
Query Insights を活用して、データベースで特にレイテンシが高いクエリや、特に頻繁に実行されているクエリを特定し、スキャンされているインデックス エントリの数に基づいてインデックスの作成が必要かどうかを評価する。
ご利用中の Firestore の移行
Firestore を初めてご利用の場合、Firestore Enterprise エディションのデータベースを作成するだけで簡単に始めることができます。Firestore をすでにご利用中のデベロッパーが Firestore パイプライン オペレーションに移行するのも簡単です。統合されたインポート / エクスポート サービスを使用して、Firestore Standard エディションのデータベースから、新たにプロビジョニングされた Enterprise エディションのデータベースにデータを移行するだけです。重要な点として、Enterprise エディションでは下位互換性が維持されているため、Firestore コア オペレーションの既存のアプリケーション コードを保持できます。高度な機能を活用する適切なタイミングが来たら、次の方法でコア オペレーションのコードをパイプライン オペレーションに変換できます。
その後、新しいパイプライン機能をすぐに使い始めることができます。
予測可能な料金と最適化された費用
Firestore Enterprise エディションでは、改善された透明性の高い料金モデルで費用を管理できます。データベースに対して実行されるすべての読み取りオペレーションと書き込みオペレーションについて、ドキュメントと関連インデックス エントリのサイズに基づいて課金されます。この新しいアプローチにより、4 キビバイト未満のドキュメントに対する読み取りオペレーションの実行時に、費用を最大 86% 削減できる可能性があります。
リアルタイム リッスン クエリの更新は、発生した時点で個別に測定、課金されます。さらに、初期費用は不要で、データベース クラスタの容量計画の誤りやデータベース シャーディングの非効率性から生じる潜在的な費用もありません。ストレージ使用量については、高可用性のための複製コピーも含め、実際に使用した容量に対してのみ課金されます。Firestore を初めてお試しになる場合は、Enterprise エディションに十分な無料枠が含まれているため、簡単に始めることができます。
Firestore パイプライン オペレーションを使ってみる
Enterprise エディションにおいて、柔軟なデベロッパー エクスペリエンスを実現する高度なクエリエンジンは、Firestore ネイティブ モードと Firestore MongoDB 互換モードのどちらからでもアクセスできます。このため、デベロッパーは Firestore と MongoDB の両方のデベロッパー コミュニティから、既存のライブラリやツールを最大限に活用できます。新しい Firestore Enterprise エディションのネイティブ モードで新規データベースを作成することで、Firestore パイプライン オペレーションのプレビュー版を今すぐご利用いただけます。パイプライン オペレーションの開始方法の詳細については、ドキュメントをご覧ください。
Enterprise エディションは、初期費用が不要で、十分な無料枠を用意しています。ぜひご利用ください。詳細については、https://cloud.google.com/products/firestore をご覧ください。
- Google Cloud、グループ プロダクト マネージャー Minh Nguyen
- Google Cloud、スタッフ ソフトウェア エンジニア Joseph (JD) Batchik


