今後のプロジェクトで Cloud Spanner の導入を検討すべき 3 つの理由
Google Cloud Japan Team
※この投稿は米国時間 2020 年 8 月 21 日に、Google Cloud blog に投稿されたものの抄訳です。
データベースは、ほぼすべてのアプリケーションの重要構成要素です。アプリケーションを設計するときは、例外なくアプリケーション データを永続的に保存する必要があります。共有データベースにデータを永続的に保存しなければ、アプリケーションのスケールも基盤ハードウェアのアップグレードも行えません。さらに悲惨なことに、インフラストラクチャに障害が発生すると、すべてのデータがただちに失われます。
信頼性の高いデータベースがあれば、アプリケーションをスケールでき、データの永続性と整合性、サービスの可用性を確保し、システムのサポートが容易になります。データベースは、ほぼすべてのアプリケーションの重要構成要素です。
Google Cloud の Spanner データベースは、Google 社内や Google Cloud を利用する多くのお客様から寄せられた、プロダクトの構造化データの保存に対する要望に応えて構築されました。Spanner は Google のコア インフラストラクチャの一部で、Google のビジネスを確実に保護しています。これは、異なる業界やユースケースでも同様です。
Spanner 導入前の Google サービスでは、トランザクションが必要なデータベースのユースケースで主に使用していたのは共有型 MySQL でした。Spanner 開発の目的は、Spanner の論文で述べられているとおり、複雑かつ変化し続けるスキーマを持つアプリケーション、または広範囲にわたるレプリケーションが行われる中で高い整合性が求められるアプリケーション向けのデータ ストレージ サービスを確立することでした。
Spanner について考えたときに最初に浮かぶコンセプトの一つは、データベースを任意の容量までスケールできる機能です。Spanner は、実際のところ、非常に多くの Google ユーザー様に機能を提供する Google アプリケーションをサポートしているため、スケーラビリティを最優先する必要があります。
この投稿では、規模の大小を問わず多様なユースケースで運用されるアプリケーションに対応できるよう、Spanner がどのように設計されているか、Spanner がデベロッパーにとっていかに扱いやすいか、総所有コスト(TCO)をどれだけ削減できるかを考察します。次の情報をぜひ参考にしてください。
小規模から始めて成長とともにスケールする
Spanner はきわめて大容量のデータを処理できるため大規模なアプリケーションに役立つのはもちろんですが、中小さまざまな規模のアプリケーションでもその威力を発揮します。また、RDBMS を必要とするすべてのワークロードを 1 つのデータベース エンジンで標準化できるというメリットもあります。Spanner は、ANSI 2011 SQL、DML、Foreign Keys などの一般的なリレーショナル データベース管理システム(RDBMS)に、TrueTime を利用した高度な外部整合性やネイティブの同期レプリケーションによる高可用性などの他に類を見ない機能を組み合わせることで、あらゆる種類のアプリケーションに適した強固な基盤を提供します。
ここで少し「小規模」という概念をどう捉えるか、つまり小規模なアプリケーションは重要ではないのか、あるいは小規模なアプリケーションの可用性は低くてもよいのか、堅牢なトランザクション機能は必要でないのか、について考えてみたいと思います。この分類は、あるアプリケーションが大規模アプリケーションに比べてビジネス上重要ではないことを意味するものではありません。また、アプリケーションの規模を最初のロールアウト時のまま永久にスケールしなくてよいというものでもありません。最初の段階でアプリケーションのユーザー数やトランザクション量が少なくても、Spanner が持つこのスケーラビリティという利点を見過ごすべきではありません。Spanner のバックエンドを使用して設計されたアプリケーションは、今後のビジネスの成功によりデータ容量やトランザクション量が増大しても、書き直したり、データベースを移行したりする必要が一切ありません。
たとえば、貴社が新たに面白くて斬新なゲームを開発しているゲーム制作会社であるとします。貴社は、そのゲームが発売初日から大いに売れてユーザーが急増するという状況にも対応できるよう備えたいと考えています。
Spanner なら、どのような規模のアプリケーションでも、トランザクション サポート、高可用性の保証、読み取り専用レプリカ、手間いらずのスケーリングなど、大きな恩恵を受けることができます。
トランザクション サポートと高度な外部整合性
Spanner では、TrueTime によって外部整合性が保証されています。原子時計を使うこの完全冗長システムにより、Spanner は、いわゆる仮想分散グローバル クロックからタイムスタンプを取得します。また、Spanner はあらゆるトランザクションに対して世界的に認められたソースから取得したタイムスタンプを commit 時に適用できるため、トランザクションの commit 順が常に明確になります。外部整合性を確保するには、すべてのトランザクションを順番に実行する必要があります。Spanner は、この強整合性保証の要件を満たしています。
強整合性は多くの種類のアプリケーション、特に商品や通貨の量を管理するアプリケーションや、結果整合性がまったく適しないアプリケーションで必要とされます。このようなアプリケーションの例として、サプライ チェーン管理、小売価格と在庫の管理、銀行業、商取引、記帳等のアプリケーションが挙げられます。
データベースの強整合性が確保されていない場合は、複数のトランザクションを別々のオペレーションに分割する必要があります。1 つのトランザクションがアトミックでない場合、そのトランザクションは部分的に失敗する可能性があることを示します。デジタル ウォレットを使用して、夕食代などをご自分の支出額と友人の支出額に分割するとします。自分のウォレットから友人のウォレットへのお金の移動が、強整合性の保証されたトランザクション内で処理されなかった場合、自分のウォレットにも友人のウォレットにもお金が存在しないなど、トランザクションの半分が失敗した状態に陥る可能性があります。
結果整合性の短所はその名前に表れています。データベース オペレーション直後にデータベース全体の整合性が失われ、変更内容がすべてのリクエスト元に返されるのはオペレーションの完了後「結果」としてです。その間に、クライアントからの異なるリクエストに対し、異なる結果が返される場合があります。たとえば、ソーシャル メディア サービスを使用している場合、写真を投稿するためにボタンを押してから画像がタイムラインに表示されるまで時間差を感じたことがあると思います。Pokemon GO の制作会社 Niantic は、特にソーシャル アプリケーションにおけるこの種の不整合を防ぐために Spanner を利用しています。
強整合性の詳細については、こちらのブログ投稿をご覧ください。基本的に、Google が学んできたことは、デベロッパーが基盤となるデータストアを利用して複雑なトランザクション処理を行い、データを順番どおりに維持できるのであれば、アプリケーションのコードはより単純になり、開発期間はより短くなるということです。元の Spanner の論文を引用すると、「Google は、トランザクション不足にまつわるコード記述ばかり行うのではなく、ボトルネック発生時にトランザクションの濫用に起因する性能上の問題をアプリケーション プログラマーに処理させる方が良いと考えています。」
高可用性の保証
Spanner は、計画的なメンテナンスやスキーマ変更のためのダウンタイムなしで最大 99.999% の可用性を保証します。フルマネージド サービスのため、お客様がメンテナンスを行う必要はありません。ソフトウェアの自動更新とインスタンスの最適化は、バックグラウンドで行われます。これはメンテナンスの時間枠を確保せずに行われます。また、ハードウェア障害発生時には、データベースがダウンタイムなく自然に復旧します。
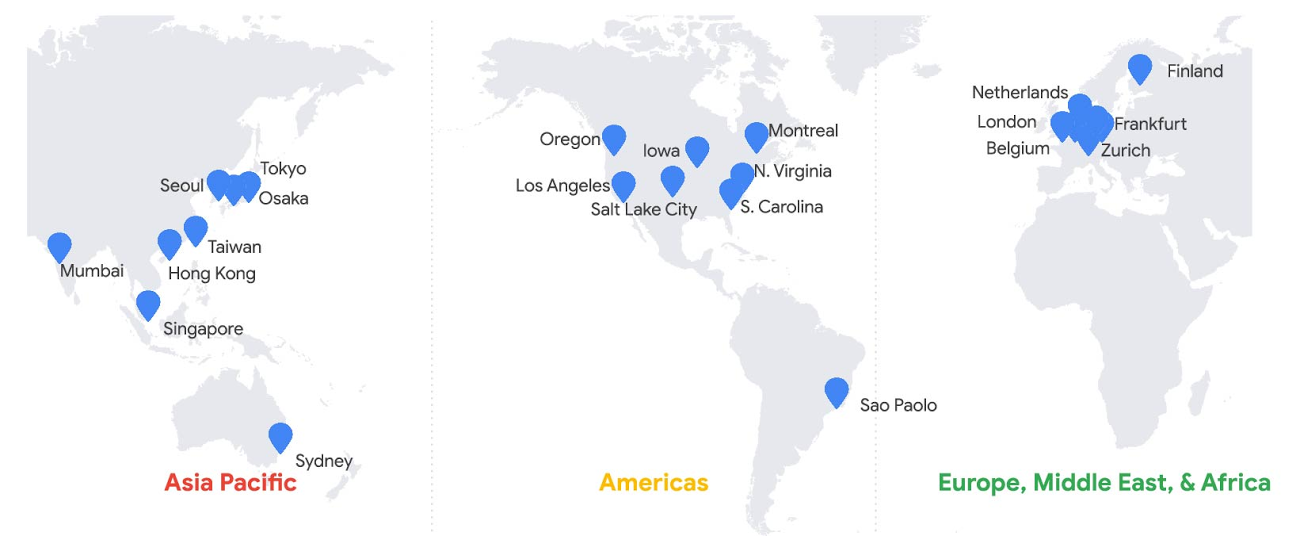
Spanner のインスタンスは、リージョン インスタンスの場合は 1 つのクラウド リージョンにある独立ゾーンの 3 つのレプリカ間の同期複製、マルチリージョン インスタンスの場合は 2 つのクラウド リージョンにまたがる独立ゾーンの 4 つ以上のレプリカ間の同期複製により、この高可用性を実現します。Spanner のリージョン インスタンスは、Google のアジア太平洋地域、米州地域、欧州地域、中東地域、およびアフリカ地域のさまざまなリージョンで使用できます。マルチリージョン インスタンスは、世界中の地域のさまざまな組み合わせで提供されます。
これにより、リージョン インスタンス構成の場合はアプリケーションがインフラストラクチャの障害とゾーンの障害の両方から保護され、マルチリージョン インスタンス構成の場合はリージョンの障害から保護されます。
読み取り専用レプリカ
一部のデータが古くても問題にならない読み取りリクエストを使用している場合、読み取り専用レプリカを使うことで生まれる計算能力をより効率的に活用でき、その結果、平均読み取りレイテンシが低くなります。アプリケーション クライアントに近い場所にレプリカを持つマルチリージョン インスタンス構成を採用している場合は、このレイテンシが大幅に低くなることもあります。
この制約を受け入れられるクエリでは、読み書きレプリカ(スプリット リーダー)を参照することなく、レプリカがステイル読み取りクエリに直接応答できます。マルチリージョン インスタンス構成の場合は、レプリカをさらにアプリケーション クライアントに近い場所に配置できるため、読み取りのパフォーマンスが大幅に向上します。
この機能は、従来の RDBMS トポロジが非同期読み取りレプリカを使用してデプロイされた場合に実現される水平方向のスケーリングに相当します。ただし Spanner は、通常のリレーショナル データベースとは異なり、運用面または管理面のオーバーヘッドの増大を招くことなくこの機能を提供します。
手間いらずの水平方向のアップスケーリングとダウンスケーリング
Spanner では、コンピューティング リソースがデータ ストレージから分離されるため、基盤となるストレージに一切変更を加えることなく処理リソースのプールを拡大、縮小、または再割り振りできます。これは、従来のオープンソースまたはクラウドベースのリレーショナル データベース エンジンでは実現できません。
つまり、1 回のクリックまたは API 呼び出しで水平方向のアップスケーリングを行えるため、データ スループットが低いままであっても、アプリケーションの要求に応じて 1 秒間あたりのオペレーション能力を高めることができます。また、より多くのコンピューティング リソースを使えるため、読み取りと書き込みの両方を処理できます。
ダウンスケーリングも同様に簡単です。Spanner のスケーリングはボタンを 1 回押すだけです。需要の変化に合わせてインスタンス ノードを簡単に追加または削除でき、ほんの数秒で有効になります。
書き込み容量の追加に対応するため、他のデータベース(リレーショナル データベースでも NoSQL でも)でクラスタを水平方向に拡大するには、多大な労力が必要です。さらに、一度追加した容量を削除するのは容易でなく、不可能な場合もあります。
汎用データベースとして優れた Spanner
リレーショナル データベースは、E.F. Codd が 1970 年に書いた論文で説明されているコンセプトを基に設計されたデータベースです。また、RDBMS は最も古くから使用され続けているデータベース技術にもかかわらず、大部分の新規プロジェクトで特に多く選ばれるデータベースの地位を維持しています。
リレーショナル データベースは信頼性の高い技術です。最初に MySQL または PostgreSQL を選択したことにまつわる体験談を、成功を収めた多くの企業が発表しています。企業は、デベロッパーが SQL を知っているから、リレーショナル モデルがプロダクト開発過程で柔軟性を発揮するからという理由でリレーショナル データベースを選択します(先に述べた点に戻ると、多くの場合、このような初期体験談では、データ容量が管理不可能なレベルを超えた後発生したリレーショナル データベース関連の管理業務がいかに厳しかったかという話が続きます)。
もちろん、Spanner については、より抽象的なコンセプトも関わっています。Spanner は分散型データベースで、その高度な外部整合性は、サーバーラックに配置されたローカル原子時計と GPS 信号を介して利用可能なリモート原子時計をともに使用する堅牢なシステムにより確保されています。ただし Spanner では、引き続き馴染み深いリレーショナル データベースの ANSI SQL に準拠したインターフェースを使用できます。そのため、アプリケーション デベロッパーは、操作方法をすぐに習得できます。
このデータベース技術は、Google の数多くのアプリケーション(社内用、社外用、大規模、小規模)に役立つことが証明されています。Spanner は、デベロッパーに使いやすい環境を用意し、新しいアイデアを自由に試すことができる基礎技術としての地位を築いています。
プロダクト アプリケーションによってはユーザー数が極めて多くなり、トランザクション量がかなり大きくなることもある一方で、より小規模なユーザー集団向けの、使用頻度の低いアプリケーションも存在します。Spanner は、両規模のアプリケーションを対象としたバックエンド データ ストレージ サービスとして機能します。
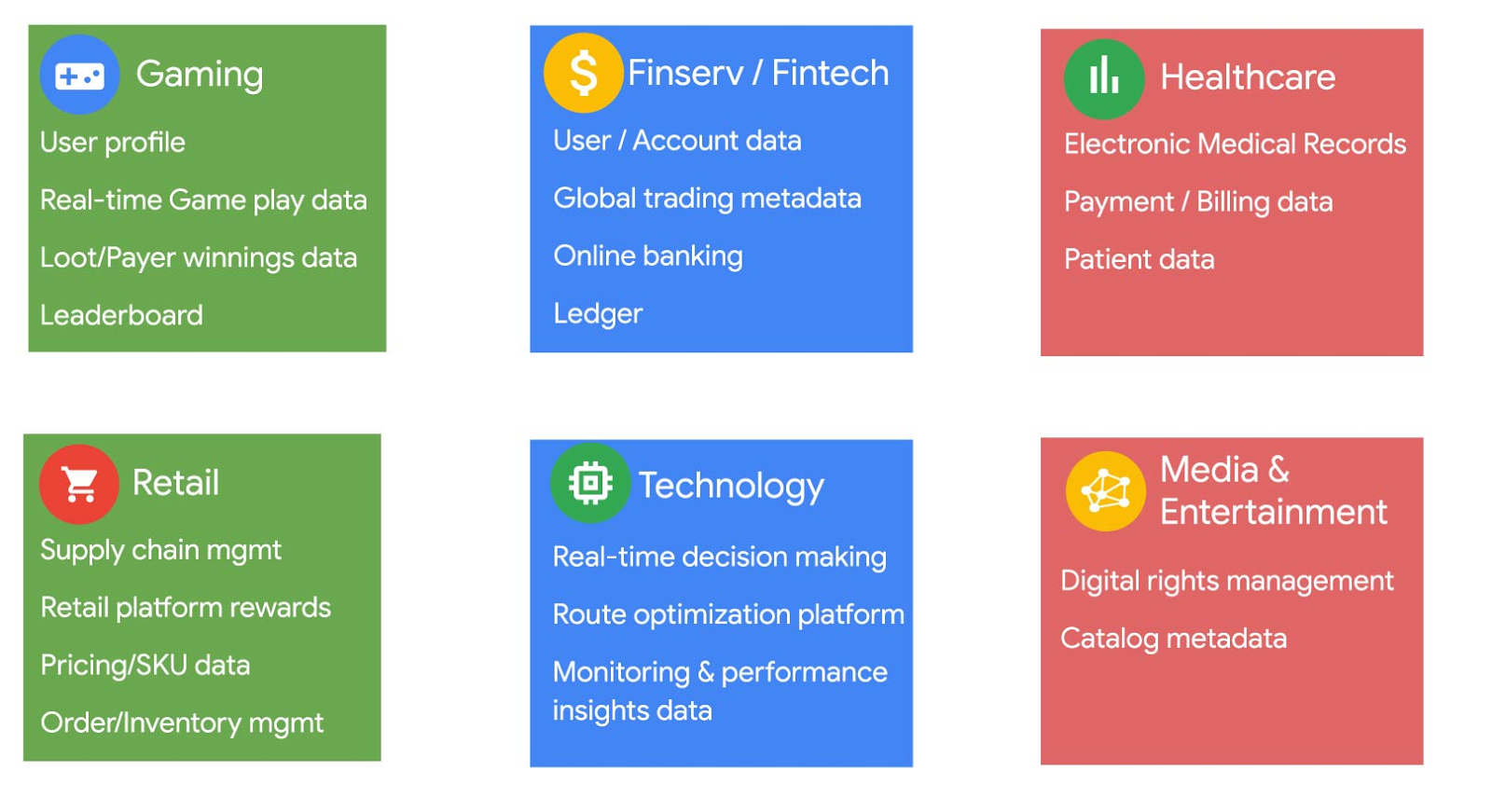
また、Google Cloud をご利用のお客様は、ゲーム(Lucille Games)、フィンテック(Vodeno)、ヘルスケア(Maxwell Plus)、小売(L.L.Bean)、テクノロジー(Optiva)、メディア、エンターテイメント(Whisper)など、さまざまな業種で多数のコアビジネス ユースケースに Spanner をうまく活用されています。さまざまな業界のお客様が Spanner をどのように使用されているかを以下に示します。
Spanner で TCO を削減し、操作をシンプルに
総所有コスト(TCO)について考えた場合、Spanner の導入により、運用費用が安くなります。また、機会費用について考えた場合、費用対効果(ROI)が向上する場合もあります。単に 1 時間あたりの料金のみに着目して近視眼的に Spanner の運用費用を評価する前に、より大きな視野で Spanner がもたらす全般的な価値と他のデータベース サービスに掛かるさまざまな費用とを対比して、両者の運用費用を比較しましょう。
まず、本番環境レベルのデータベースの運用費用について考えます。費用には、リソース費用、運用費用、機会費用の 3 つがあります。リソース費用は、公表されている正規価格を基に、比較的簡単に計算できます。運用費用は、さまざまな業務を行う必要のあるチームメンバーの人数に対応するため、計算が幾分か困難です。機会費用の計算は他の 2 つに比べて分かりにくいのですが、無視できません。1 つの活動区分に対する組織の予算を通貨単位または時間単位で増額した場合、他の機会に対し使える予算が減ります。
機会費用を計算するため、まずは Spanner の正規価格を仮想マシンで動作する自社管理型オープンソース データベースの正規価格と比較し、リソース費用について考察します。次に、同じ環境の運用面の負担と費用を比較します。最後に、Spanner が提供する機会価値について考察します。
はじめに、小規模な仮想マシンで動作する 1 つのデータベース エンジンについて考えた場合、Spanner はより多くの費用が掛かるように思えるかもしれません。しかし、1 つのコンピューティング ノードで本番環境データベースを運用することは推奨されません。実際には、十分なメモリと、短期から中期の利用拡大に備えた十分な空き容量を割り当てられた永続ディスクを実装した中規模の仮想マシンで運用することになるでしょう。
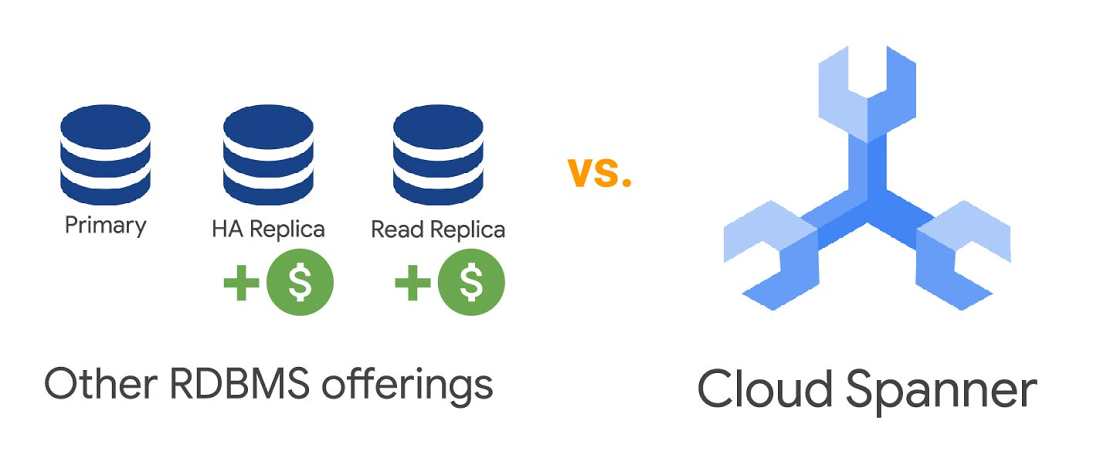
また、本番環境用仮想マシンと同じ仕様のオンライン データベース レプリカを含む高可用性データベース トポロジを準備しておくことも考えられます。さらに、読み取り専用ワークロード用の別のレプリカ データベースのメンテナンスを行うことがあるかもしれません。
この場合のトポロジは、Spanner と同等のコンピューティングとストレージのトポロジとなります。データのコピーが 3 つ作成され、3 台の仮想マシンが稼働することになります。1 台目は書き込みの管理用、2 台目は高可用性レプリカとして、3 台目は読み取り専用ワークロード用に使用されます。このことは、Spanner の背景となる中心的理念、つまり高可用性を保証するには少なくとも 3 台のレプリカを使用して運用する必要があることを反映しています。
ここで、Compute Engine で動作するデータベースの正規価格と比較した Spanner の正規価格について考えてみましょう。Spanner データベース ストレージの正規価格は、ゾーン永続ディスクの正規価格の約 2 倍です。ただし、永続ディスクにはデータのコピーが 3 つ保存されるため、合計費用はこれより高くなります。
このトポロジでは、アプリケーション データの量が同じ場合、Spanner データベース ストレージの費用は、従来型のデータベース ストレージの費用より約 3 分の 1 安くなります。また、Spanner は従量課金のため、未使用のスペースを最初に事前プロビジョニングする必要がないことから、費用を節約できます。データの容量が減少した場合も、従来型のデータベースとは異なり、ストレージ費用を削減するためにデータを移行する必要はありません。
コンピューティング リソースの料金比較は、パフォーマンスがワークロードに左右されるため、これよりやや複雑です。本番環境規模の仮想マシンで運用される 3 方向レプリケーション型の従来の RDBMS の料金を、同等数の Spanner ノードの料金と比較して、ある種の相対料金を割り出すことができます。
ただし、話はここで終わりません。ご存じのとおり、独自のデータベースの管理に掛かる運用費用は無視できません。また、運用業務ごとに、システムの稼働時間に対するリスクも増大します。Spanner は、高品質なサービスを運用オーバーヘッドを低く抑えて提供することを目的として設計されました。

たいていの場合、Spanner の運用費用はゼロに近づきます。まず、Spanner は、データベースのバックアップの取得と保管に必要な運用上の労力を削減してくれます。メンテナンスの時間枠も計画的ダウンタイムも確保する必要がありません。破損データを手動で修復することも、インデックスを再作成することも、Spanner ではまったく必要ありません。データベースで利用可能なストレージ容量を増やす場合も、手間はかかりません(インスタンス ノード数を増やすためにボタンをクリックすることを「手間」というのであれば別ですが)。最も重要な点として、Spanner は、動的データ再シャーディングとデータ レプリケーションを自動で行うため、水平方向または垂直方向の規模調整に手間はかかりません(ここでも、ボタンのクリックを手間と思う場合は別です)。
Enterprise Strategy Group は、レポート Analyzing the Economic Benefits of Google Cloud Spanner Relational Database Service で Spanner の総所有コスト(TCO)を定量化しました。Enterprise Strategy Group が顧客に意見を聞いたところ、その全員が、TCO の削減と柔軟性の向上やイノベーションによるメリットを理由に、他のデータベース サービスより Spanner の方を好んでいたということです。Spanner の総所有コストは、オンプレミス型データベースより 78% 安く、他のクラウド型データベースより 37% 安くなっています。運用上の労力が軽減されることで、ビジネスのより大きな成功につながる他の事柄に注力できます。これこそが Spanner がもたらす機会価値です。
使ってみる
Spanner は非常に高機能ですが、とても簡単に操作できます。Google で厳格にテストされているため、お客様に自信を持っておすすめできます。ワークロードの範囲や規模に関係なく、Spanner を今後のプロジェクトにおすすめしたい明確な理由があります。Google では、Cloud Storage でのオブジェクトの一覧表示を保証するため Google Cloud 社内で Spanner を使用しており、ドラゴン クエスト ウォークを配信する Colopl などのお客様も Spanner を選択されました。Spanner では一般的なリレーショナル セマンティクスとクエリ言語を使用でき、リレーショナル データベースがデータ ストレージに最適なツールとなるきっかけを作った高度な柔軟性を備えています。どのような規模のアプリケーションでも、どのようなビジネス目標をお持ちでも、Spanner は必ず皆様のお役に立つはずです。
詳細
Spanner の利用を開始するには、インスタンスを作成するか、Spanner Qwiklabs でお試しください。
-ソリューション アーキテクト Drew Stevens