Cloud Spanner イントロスペクション機能によるトラブルシューティングの改善
Google Cloud Japan Team
※この投稿は米国時間 2021 年 2 月 9 日に、Google Cloud blog に投稿されたものの抄訳です。
優れたデベロッパー エクスペリエンスは、Google のフルマネージドの水平スケーリング可能なリレーショナル データベース サービスである Cloud Spanner の最も重要な分野の 1 つです。データベースのスペシャリストでもデベロッパーでも、データベースのパフォーマンスを理解し、問題が発生した場合に検出、修正するのに役立つツールを持っていることが重要です。そのため、Spanner は、データベースのパフォーマンスを簡単にモニタリングして、潜在的な問題を診断して修正し、アプリケーションの全体的な効率を最適化できる新しいイントロスペクション機能を継続的に追加しています。
Google は先日、組み込みテーブル形式のイントロスペクション ツールを多数リリースしました。これらのツールを使い、クエリ、読み取り、トランザクションなど、Spanner のオペレーションに関する有用な分析情報を得ることができます。これらの新しいイントロスペクション テーブルは、既存のアラート機能やモニタリング機能と組み合わせると、問題の診断やトラブルシューティングに役立つ一連の強力なツールとなります。これらの新しいイントロスペクション ツールについて詳しく見ていきましょう。まずは、Spanner のイントロスペクション機能とモニタリング機能を活用してデータドリブン アプリケーションの効果を最大限に高める基本的な方法について紹介します。
リソース使用率のモニタリング方法
CPU とストレージは重要なリソースであるため、Spanner でモニタリングすることで、期待するパフォーマンスの達成に十分なノードを使用してインスタンスがプロビジョニングされていることを確認する必要があります。Spanner はすでに Google Cloud Monitoring スイートと統合され、推奨しきい値に基づいて CPU とストレージ使用率の指標のアラートを設定できます。指標の値がしきい値を超えると自動的にアラートが送信されます。Spanner コンソールの [モニタリング] タブで、指標の詳細を確認し、時間の経過に伴う変化を分析できます。
ここに例を示します。CPU 使用率に関するアラートを受け取り、モニタリング グラフを確認すると、以下のように使用率が急増していたとしましょう。
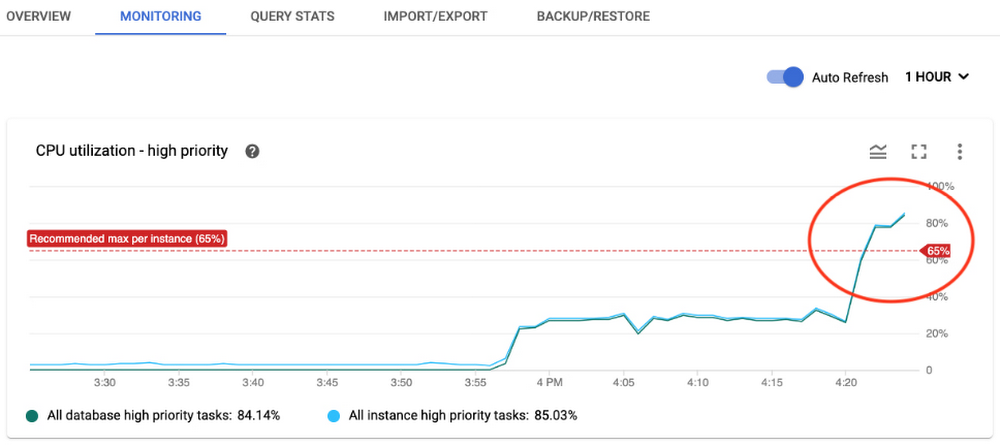
Cloud Monitoring コンソールにアクセスして期間を選択することで、データをさらに詳しく分析できます。また、インスタンス、データベース、オペレーションの優先度などのオプションで絞り込んで詳細な分析を行い、どこに注目してさらなる調査を行うべきかを判断することもできます。指標の一覧から異なる指標を相互に関連付けて急増の原因を特定し、考えられる対応策を決めることもできます。たとえば、API リクエストの増加が CPU 使用率の増加と相関関係にある場合、Spanner のワークロードが CPU 使用率の増加を引き起こしているため、CPU 使用率を推奨範囲内に戻すにはプロビジョニングするノードを増やす必要があると推測できます。
CPU 使用率の急増とリクエストの増加が連動していない場合は、非効率的な SQL クエリや読み取りが原因で CPU 消費量が増えている可能性があります。調査する必要がある SQL クエリや読み取りはどのようにわかるのでしょうか。それには、イントロスペクション テーブルが役立ちます。詳しくは、このブログで後述の「新しいイントロスペクション ツール」セクション、またはドキュメントをご覧ください。
パフォーマンスのモニタリング方法
スループットの期待値やレイテンシの期待値など、アプリケーションに特定のパフォーマンス要件がある場合があります。たとえば、書き込みオペレーションの 99 パーセンタイル レイテンシを 60 ミリ秒未満にし、レイテンシの指標がこのしきい値を超えた場合にアラートを設定したとしましょう。
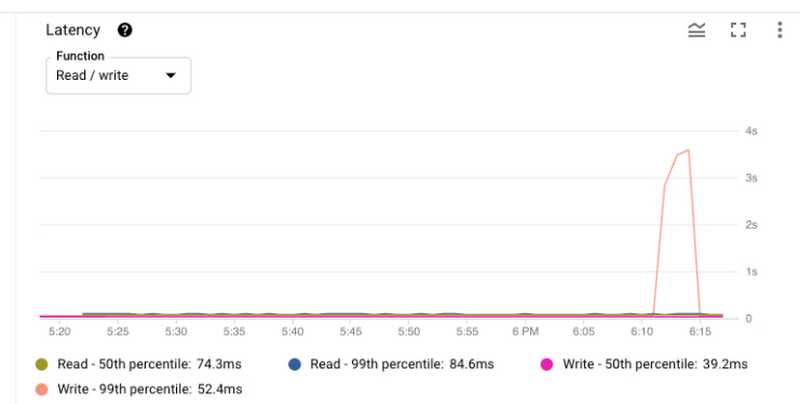
書き込みレイテンシがしきい値を超えたことでアラートを受け取ったら、Spanner コンソールでレイテンシ グラフを確認して、このインシデントを調査できます。たとえば、上の画像では、書き込みオペレーションの 99 パーセンタイル レイテンシが午前 6 時 10 分ごろに急増したことがわかります。Cloud Monitoring コンソールを使用して、どの API メソッドがレイテンシ急増の原因となっているかを判断できます。レイテンシ急増の原因が Commit API であることがわかったとします。次のステップでは、どのトランザクションに負荷の高い commit が含まれているかを確認します。commit レイテンシが増加した理由は何でしょうか。
こうしたトラブルシューティングを促進するために、よく使うクエリ、読み取り、トランザクション、トランザクションのロックに関する詳細情報と統計情報を提供する新しいイントロスペクション ツールを用意しました。これらのツールは、クエリを実行することでより多くの分析情報が得られる一連の組み込みテーブルで構成されています。各ツールをいつ使うかについては、この表をご覧ください。それでは、各ツールの機能を詳しく見ていきましょう。
新しい Spanner イントロスペクション ツールの探索
SQL クエリについて深く掘り下げる
クエリの統計情報: 負荷の高いクエリとそのパフォーマンスへの影響を特定して調査する場合は、クエリ統計テーブルを使用します。このテーブルでは次のような事項の内容を確認できます。
CPU 消費量が特に多いクエリ
1 クエリあたりの平均レイテンシ
クエリによってスキャンされた行数と返されたデータのバイト数
以下に示すテーブルの例では、CPU 消費量とレイテンシが最も高い 2 つのクエリのフィンガープリントを簡単に特定できます。
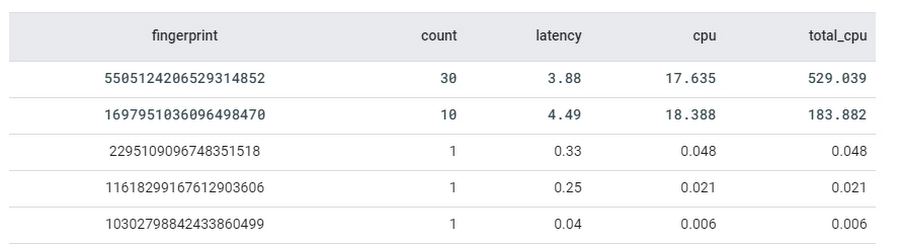
これらのフィンガープリントを使用して、テーブルから実際のクエリテキストを取得できます。次のステップで、Spanner コンソールでクエリの説明機能を使用して、クエリの実行プランを分析し、クエリを最適化できます。Spanner では最近、クエリの統計情報をさらに強化し、キャンセルされたクエリや失敗したクエリに対する分析情報を追加しました。これにより、完了したクエリだけでなく、さまざまな種類のクエリをトラブルシューティングできるようになりました。
最も古いアクティブなクエリ: クエリ統計テーブルでは過去のクエリを分析できますが、最も古いアクティブなクエリのテーブルは、レイテンシと高い CPU 使用率の問題を引き起こしているクエリをリアルタイムで特定するのに役立ちます。このテーブルでは次のような事項の内容を確認できます。
現在、実行中のクエリの数
実行時間の長いクエリ
クエリを実行しているセッション
これらの内容により、問題を引き起こしているクエリを特定し、問題を的確かつ迅速に解決できます。たとえば、アプリケーションのパフォーマンスに影響を及ぼしている実行時間が最長のクエリを特定したら、セッションを削除するなどの措置を講じることで問題をすぐに解決できます。
読み取りオペレーションについて深く掘り下げる
読み取りの統計情報: 読み取りトラフィックに起因する問題のトラブルシューティングを行う場合は、読み取り統計テーブルを使用します。このテーブルでは次のような事項の内容を確認できます。
CPU 消費量が特に多い読み取りオペレーション
1 読み取りあたりの CPU 平均消費量
これらの読み取りに関連するさまざまな待機時間の長さ
次のステップで、これらの読み取りオペレーションを最適化するか、ユースケースに適した読み取りオペレーション(強力な読み取りまたはステイル読み取り)を決定することができます。
読み取り / 書き込みトランザクションについて深く掘り下げる
トランザクションの統計情報: トランザクションに起因する問題をトラブルシューティングする場合は、トランザクション統計テーブルを使用して、読み取り / 書き込みトランザクションのパフォーマンスに影響している要因をさらに詳細に把握できます。このテーブルでは次のような事項の内容を確認できます。
実行速度の遅いトランザクション
トランザクションの commit レイテンシと全体的なレイテンシ
トランザクションが commit を試行した回数
トランザクションによって書き込みまたは読み取りが行われた列
この情報を分析することで、特定の列に対する大量の更新によるトランザクションの速度低下など、潜在的なボトルネックを検出できます。トランザクションのパフォーマンスの問題でよくある原因の 1 つは、ロックの競合です。トランザクションで commit レイテンシや全体的なレイテンシの増加が見られる場合は、ロック統計テーブルを使用して、トランザクションのロックが問題を引き起こしているかどうかを特定します。
ロックの統計情報: パフォーマンスに影響を及ぼしているトランザクションを特定したら、ロック統計テーブルを使用して、トランザクションのパフォーマンス特性とロックの競合を相互に関連付けます。このテーブルでは次のような事項の内容を確認できます。
ロック競合が特に多い行と列
発生しているロック競合の種類
ロック競合による待機時間
データベース内のロック競合の原因に関するこれらの重要な分析情報をトランザクション統計テーブルと組み合わせると、問題のトランザクションを特定できます。次のステップで、推奨されるベスト プラクティスを適用して、トランザクションを最適化し、パフォーマンスを向上させます。
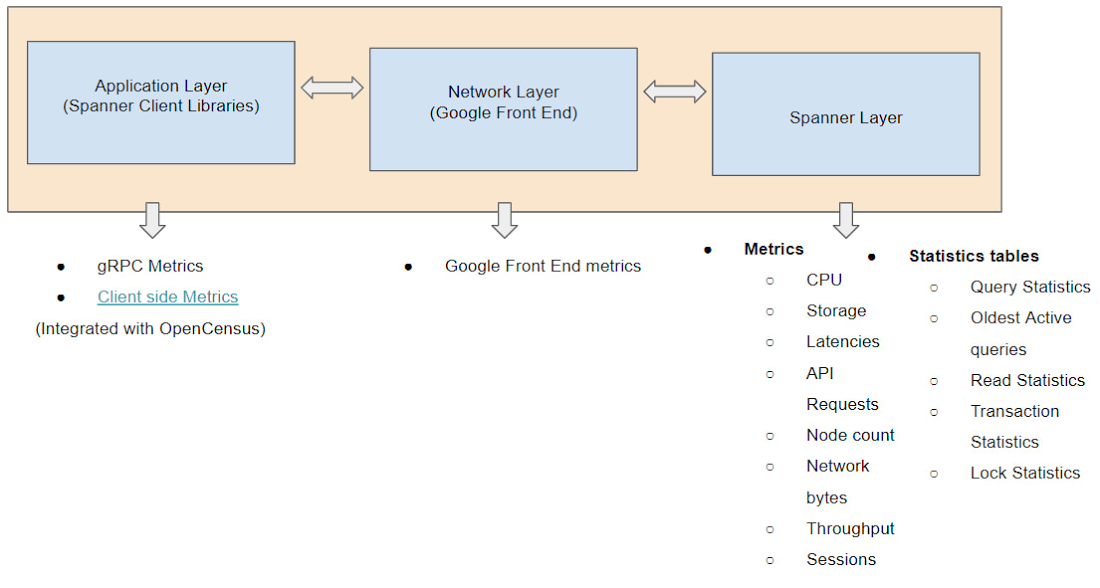
クライアント側の指標と Google Front End の指標のモニタリング
これまでは、Spanner のレイヤでイントロスペクションの指標とツールを使用する方法について説明してきました。ただし、エンドツーエンドでモニタリングするには、アプリケーション レイヤ(クライアント側)とネットワーク レイヤ(Google Front End)もモニタリングすることが重要です。これらのレイヤで問題が発生する場合があるためです。Spanner はすでに OpenCensus と統合され、クライアント側の指標や gRPC の指標をモニタリングできるようになっています。また、Google Front End 関連の指標により、レイテンシの問題がネットワーク レイヤに起因するかどうかを確認できます。クライアント側の指標と Google Front End の指標を Spanner レイヤの指標と組み合わせると、エンドツーエンドのモニタリングを行い、問題の原因を突き止め、さらにトラブルシューティングを進めることができます。
Spanner のイントロスペクション機能の更新により、Spanner での開発がさらに生産的になることを願っています。Spanner について詳しくは、Spanner の YouTube 再生リストをご覧ください。
詳細
Spanner の使用を開始するには、インスタンスを作成するか、Spanner Qwiklab でお試しください。
トラブルシューティングにイントロスペクション ツールを使用する方法について詳しくは、次のブログをお読みください。
-Google Cloud プロダクト マネージャー Shambhu Hegde


