Cloud Memorystore と Envoy で新たな高みにスケールアップ
Google Cloud Japan Team
※この投稿は米国時間 2022 年 2 月 18 日に、Google Cloud blog に投稿されたものの抄訳です。
最新のアプリケーションはミリ秒のレイテンシで大規模なデータを処理し、さまざまなエクスペリエンスを提供する必要があります。たとえば、インスタント ゲームのリーダーボード、数百万の IoT センサーから得たストリーミング データの高速分析、不正なウェブサイトのリアルタイムの脅威検出などがそうです。インメモリ データストアは、こうした最新のアプリケーションに必要なスケール、パフォーマンス、可用性を実現するために不可欠な要素です。
Memorystore を使用すると、Google Cloud でアプリケーションを構築するデベロッパーが、最も人気の高いインメモリ ストアである Redis の速度と強力な機能を簡単に活用できます。Memorystore for Redis のスタンダード ティアのインスタンスは、高可用性の Redis インスタンスを必要とするアプリケーションによく使用されます。スタンダード ティアは、ゾーン間でのフェイルオーバー レプリカによる冗長性を提供し、99.9% の SLA で迅速なフェイルオーバーを確保します。しかし、場合によっては、お客様のアプリケーションは、1 つのスタンダード ティア インスタンスの限界を超えて拡張する必要があるかもしれません。読み取りレプリカは、より高い読み取りスループットにスケールアップできますが、アプリケーションによっては、より高い書き込みスループットや、より大きなキースペース サイズが必要になる場合があります。このような場合には、キャッシュを複数の独立した Memorystore インスタンスに分割して使用する戦略を導入できます(クライアントサイド シャーディング)。この投稿では、Cloud Memorystore と Envoy で無限にスケールするために、独自のクライアントサイド シャーディング戦略を実装する方法について説明します。
アーキテクチャの概要
まず、GCP のネイティブ サービスとオープンソース ソフトウェアを組み合わせたアーキテクチャについて説明します。これにより、Cloud Memorystore を通常の限界を超えて拡張できます。そのためには、キャッシュをシャーディングして、独立した複数の Memorystore インスタンスにキースペース全体を分割することになります。シャーディングは、特定のキーを検索するための適切な場所を認識するために書き直さなければならないクライアント アプリケーションにとって課題となり、バックエンドをスケールするために更新する必要があります。しかし、クライアントサイド シャーディングは、シャーディング ロジックをプロキシでカプセル化し、アプリケーションとシャーディング ロジックを独立して更新できるようにすることで、実装と保守が容易になります。以下にアーキテクチャのサンプルを示し、各主要コンポーネントの詳細を簡単に説明します。
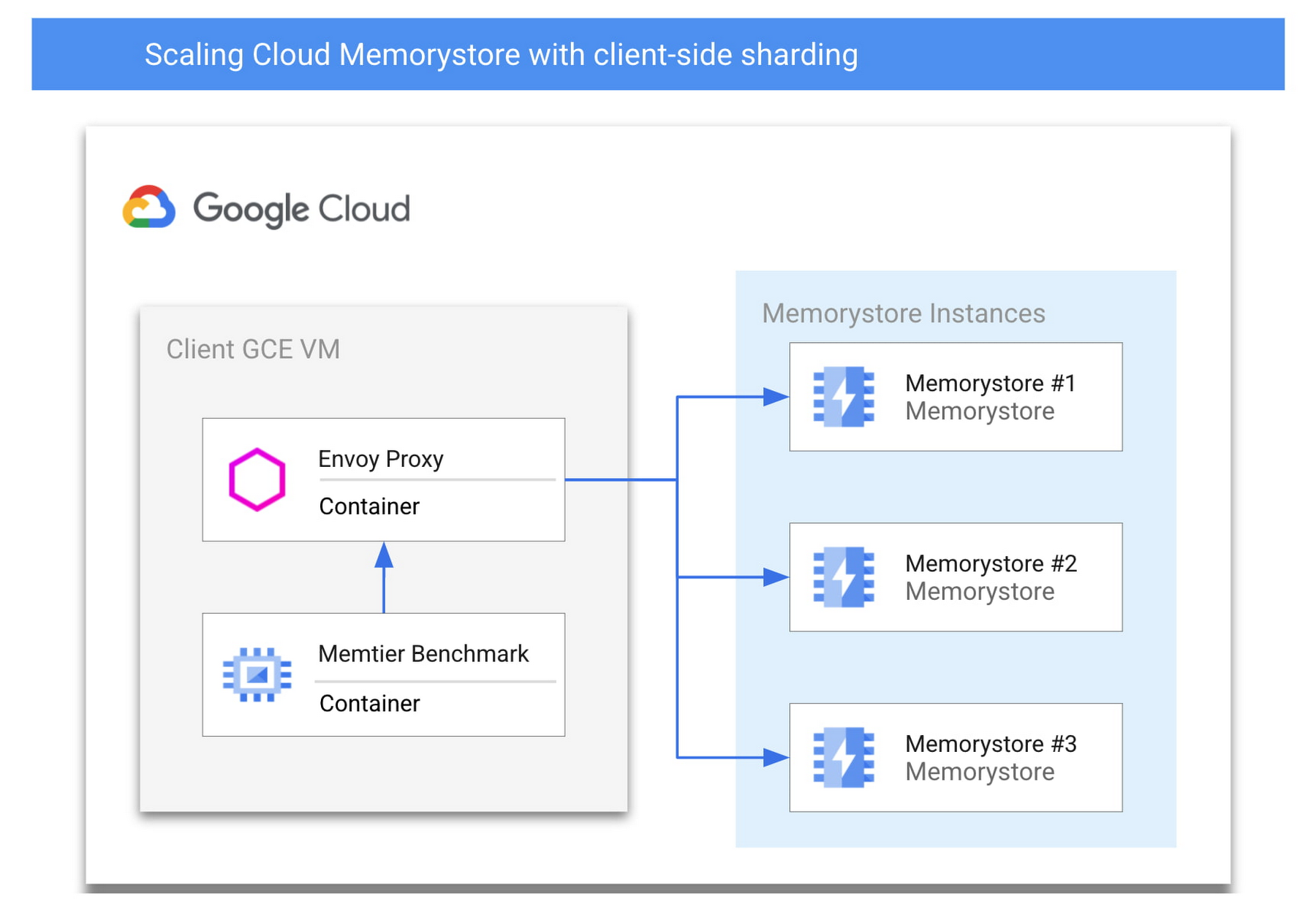
Memorystore for Redis
Cloud Memorystore for Redis は、GCP ユーザーが GCP プロジェクト内にマネージド Redis インスタンスを迅速にデプロイすることを可能にします。単一ノードの Memorystore インスタンスは、300 GB のキースペースと最大 16 gbps のネットワーク スループットをサポートします。スタンダード ティアでは、内蔵されたヘルスチェックと高速な自動フェイルオーバーを備えた高可用性の Redis インスタンスを利用できます。
今日は、複数のスタンダード ティア Cloud Memorystore インスタンスをデプロイして、スケーリングの需要が増加しているアプリケーション向けに単一インスタンスの限界を超えてスケールアップする方法をご紹介します。各 Memorystore インスタンスは、共有ホスト プロジェクト内の他のインスタンスを意識しないスタンドアロン インスタンスとしてデプロイされます。この例では、3 つのスタンダード ティア インスタンスをデプロイし、それらを 1 つの統一されたバックエンドとして扱うことにします。
GCE 上でセルフマネージド Redis インスタンスではなく、スタンダード ティア インスタンスを使用することで、以下のようなメリットが得られます。
高可用性バックエンド: スタンダード ティアでは、お客様が追加の作業をすることなく、高可用性を提供します。GCE 上でセルフマネージド Redis インスタンスの高可用性を実現するには、複雑さと障害ポイントが追加されます。
統合されたモニタリング: Memorystore は Cloud Monitoring と統合されており、セルフ マネージド インスタンスにモニタリング エージェントをデプロイし、管理する必要があるのに対し、Cloud Monitoring を使用して個々のシャードを簡単にモニタリングできます。
Memtier Benchmark
Memtier Benchmark は、key-value データベースの負荷生成とベンチマークのためによく使われるコマンドライン ユーティリティです。このユーティリティをデプロイして使用することで、大量のクエリに簡単に対応できることを実証します。Memtier Benchmark の代わりに、類似のベンチマーク ツールや独自の Redis クライアント アプリケーションを使用できます。
Envoy
Envoy は、サービス指向アーキテクチャのために設計された、オープンソースのネットワーク プロキシです。Envoy は、さまざまなソフトウェア アプリケーションやプロトコルからのネットワーク トラフィックをサポートするために、多くの異なるフィルタをサポートしています。この使用例では、Redis フィルタを構成した状態で Envoy をデプロイします。Redis クライアントは、Memorystore インスタンスに直接接続するのではなく、Envoy プロキシに接続します。Envoy を適切に構成することで、独立した Memorystore インスタンスの集合体をクラスタとして定義し、インバウンド トラフィックを各インスタンス間でロードバランスできます。Envoy を利用することで、複数の Memorystore インスタンスを利用して大規模なスケールアップを図るために、アプリケーションの大幅な書き換えが必要になる可能性が低くなります。お客様のアプリケーションとの互換性を確保するために、Envoy が現在サポートしている Redis コマンドのリストを確認することをおすすめします。
さあ始めましょう。
前提事項
このチュートリアルに沿って進めるには、以下の権限を持つ GCP プロジェクトが必要です。
Cloud Memorystore for Redis インスタンスをデプロイする (権限)
GCE インスタンスを SSH アクセスでデプロイする(権限)
Cloud Monitoring の閲覧者アクセス(権限)
Cloud Shell または他の gCloud 認証された環境へのアクセス
Memorystore バックエンドの導入
まず、アプリケーションのすべてのトラフィックを処理するバックエンド キャッシュをデプロイします。1 つのノードの限界を超えてスケールアップしたい場合は、一連のスタンダード ティア インスタンスをデプロイします。認証された Cloud Shell 環境では、次のように実行できます。
プロジェクトで Memorystore for Redis API がまだ有効になっていない場合、コマンドは先に進む前に API を有効にするように求めます。Memorystore インスタンスのデプロイには通常数分かかりますが、その間に次のステップに進むことができます。
クライアントとプロキシ VM の作成
次に、Redis クライアントと Envoy プロキシをデプロイするための VM が必要になります。1 つの GCE インスタンスを作成して、2 つのアプリケーションをコンテナとしてデプロイします。このようなデプロイは「サイドカー アーキテクチャ」と呼ばれ、Envoy の一般的なデプロイモデルとなっています。この方法でデプロイすると、物理的なネットワーク ホップが追加されないため、ネットワークのレイテンシが追加されることはほとんどありません。ここでは垂直方向にスケーリングされた単一のクライアント インスタンスをデプロイしていますが、実際には多数のクライアントやプロキシをデプロイすることが多いため、以下のセクションで説明する手順を利用して、再利用可能なインスタンス テンプレートを作成したり、GKE 用に再利用したりできます。
まずはベースとなる VM を作成します。
このインスタンスに Envoy と Memtier Benchmark をコンテナとしてデプロイするので、コンテナ用に最適化された OS インスタンスを選択しました。
Envoy プロキシの構成とデプロイ
プロキシをデプロイする前に、Memorystore のエンドポイントを適切に構成するために必要な情報を収集する必要があります。これを行うには、すでに作成した Memorystore インスタンスのホスト IP アドレスが必要です。これらをプログラムで収集できます。
これらの IP アドレスは、Envoy の構成ですぐに使用するため、アクセスしやすい場所にコピーします。
次に、Envoy プロキシをデプロイするために、新しく作成した VM インスタンスに接続する必要があります。Google Cloud Console の SSH で簡単に接続できます。詳細はこちらをご覧ください。
インスタンスへの接続に成功したら、Envoy の構成を作成します。
まず、インスタンス上に envoy.yaml という名前のファイルをテキスト エディタで新規作成します。以下の .yaml ファイルを使用し、作成したインスタンスの IP アドレスを 3 つ入力します。
IP アドレスは、ファイルの下部付近の各エンドポイントの構成のハイライト表示部分に挿入する必要があります。異なる数の Memorystore インスタンスを作成することを選択した場合、構成ファイルからエンドポイントを追加または削除するだけです。
次に進む前に、いくつかの重要な構成の詳細をご覧ください。
Cloud Memorystore に転送する Redis トラフィックをサポートするために、Redis Proxy フィルタを構成しました。
Envoy プロキシがクライアントの Redis トラフィックをポート 6379 でリッスンするように構成しました。
クライアントサイドのシャーディングされたクラスタを構成する Memorystore インスタンスのロード バランシング ポリシーとして、MAGLEV を選択しました。ロード バランシングのさまざまな種類については、こちらをご覧ください。
Memorystore バックエンドの数を増減させるには、データの再調整と構成の変更が必要ですが、このチュートリアルでは扱いません。
Memorystore インスタンスの IP アドレスを追加したら、そのファイルをコンテナ OS の VM にローカルに保存し、簡単に参照できるようにします。
Docker を使って公式 Envoy のプロキシ イメージを pull し、好みの構成で実行します。
これで Envoy がデプロイされたので、コンテナ VM から管理インターフェースにアクセスしてテストできます。
成功すれば、ターミナルに Envoy 管理者の各種統計情報が出力されるはずです。まだトラフィックがない状態では、これらは特に有用ではありません。しかし、コンテナが実行されていること、ネットワーク上で利用可能であることを確認できます。このコマンドが成功しない場合は、Envoy コンテナが実行されていることを確認することをおすすめします。一般的な問題としては、envoy.yaml の構文エラーがあります。この構文エラーは、Envoy コンテナをインタラクティブに実行して、ターミナルの出力を読むことで見つけることができます。
Memtier Benchmark のデプロイと実行
コンテナ OS の VM に SSH で接続したまま、Memtier Benchmark ユーティリティをデプロイし、人工的な Redis トラフィックを生成するために使用します。Memtier Benchmark を使用するため、独自のデータセットを用意する必要はありません。このユーティリティは、一連の set コマンドを使用して、キャッシュにデータを入力します。
一連のベンチマーク テストを実行できます。
ここでは、注目すべき構成項目を紹介します。
Envoy が他のポートをリッスンするように構成されている場合は、`-p` フラグの後に適切なポートを指定する。
デフォルトの動作であるリクエストの指定数に代わり、-test-time フラグを使用して一定時間(5 分、秒単位で指定)ベンチマークを実行。
デフォルトでは、ユーティリティはキーの取得と設定に均一なランダム パターンを使用。これを変更せず、--keypattern フラグを使用して指定することが可能です。
このユーティリティは、キー範囲の最小値と最大値、および先ほど説明した指定されたキーパターンに基づいて、取得と設定を実行することで動作可能。このキーレンジのサイズを --key-maximum パラメータを設定することによって小さくします。これにより、実際のアプリケーションに近い、より高いキャッシュ ヒット率を確保できます。
--ratio フラグを使用すると、ユーティリティによって発行されたコマンドの比率を取得するために、セットを変更可能。デフォルトでは、ユーティリティは set コマンド 1 つに対して get コマンドを 10 個発行します。この比率は、ワークロードの特性に合うように簡単に変更できます。
スレッド数を `--threads` フラグで増やしたり、スレッドあたりのクライアント数を `--clients` フラグで増やしたりすることで、ユーティリティが生成する負荷を増やすことが可能。上記のコマンドでは、デフォルトのスレッド数(4)とクライアント数(50)を使用しています。
Redis のトラフィックを観察する
負荷テストを開始したら、Cloud Monitoring によって、個々の Memorystore インスタンス間でトラフィックがバランスされていることを確認できます。Memorystore の各インスタンスについて、1 分あたりの呼び出し回数を表示するカスタム ダッシュボードを簡単に設定できます。
まず、Cloud Monitoring ダッシュボード ページに移動します。次に、[CREATE DASHBOARD] をクリックします。ページの左側にはさまざまな種類のウィジェットが表示され、ページ右側のキャンバスにドラッグできます。「Line」グラフを選択し、キャンバスにドラッグします。次に、折れ線グラフに Memorystore インスタンスからのデータを入力する必要があります。そのためには、チャート構成ペインの上部で選択できる [MQL] を使用してチャートの構成を行います。簡単にするために、コンソールに貼り付けるだけでグラフが作成できるクエリを作成しました。
Memorystore インスタンスを異なる命名規則で作成した場合、または同じプロジェクト内に他の Memorystore インスタンスがある場合は、resource.instance_id フィルタを変更する必要があるかもしれません。終了したら、チャートが適切な時間範囲を表示していることを確認し、次のように表示されることを確認します。
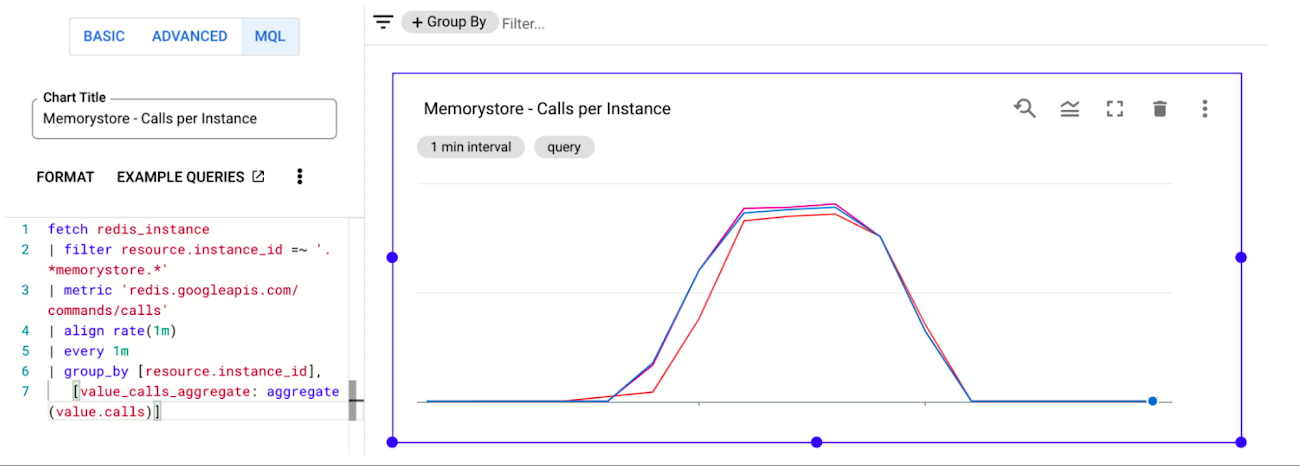
クライアントのワークロードが Memorystore インスタンスにほぼ完全に分散され、要求の高いワークロードに対して無限の水平スケーラビリティを効果的に実現できることを確認します。カスタム ダッシュボードの作成と管理の詳細については、こちらをご覧ください。
テストのパラメータを変更する際、クライアントとプロキシのパフォーマンスも考慮する必要があります。クライアントから送信されるオペレーションの数を垂直方向にスケーリングさせると、最終的には、スムーズにスケールするためにデプロイしたクライアントとサイドカー プロキシの数を水平方向にスケールさせることが必要になります。GCE インスタンスの Cloud Monitoring のグラフも見ることができます。詳細はこちらをご覧ください。
クリーンアップ
不要な課金を避けるために、数分かけてリソースをクリーンアップする必要があります。以下を消去する必要があります。
デプロイしたすべての Memorystore インスタンス
デプロイしたすべての GCE インスタンス
Memorystore インスタンスは削除できます。
チュートリアルに従えば、次のようなコマンドが使えます。
注: 各インスタンスの削除は、ターミナルから手動で承認する必要があります。
GCE コンテナ OS インスタンスは削除可能です。
インスタンスを追加で作成した場合は、スペースで区切った 1 つのコマンドで簡単にチェーンできます。
結論
クライアントサイドのシャーディングは、Cloud Memorystore で大規模なユースケースに対応するための戦略の 1 つです。Envoy と Redis フィルタにより、シンプルかつ拡張性の高い実装が可能です。上記で紹介したアウトラインは、その第一歩として最適です。これらの手順は、GKE を含む他のクライアント デプロイ モデルをサポートするために容易に拡張でき、さらに高いスケールに到達するために水平方向にスケールアウトできます。Cloud Memorystore の詳細については、ドキュメントを参照するか、ご希望の機能については、公開 Issue Trackerでリクエストしてください。
-カスタマー エンジニア、John Rabiah
-プロダクト マネージャー、Matt Geerling



