Scaling to new heights with Cloud Memorystore and Envoy
John Rabiah
Customer Engineer
Matt Geerling
Product Manager
Modern applications need to process large-scale data at millisecond latency to provide experiences like instant gaming leaderboards, fast analysis of streaming data from millions of IoT sensors, or real-time threat detection of malicious websites. In-memory datastores are a critical component to deliver the scale, performance, and availability required by these modern applications.
Memorystore makes it easy for developers building applications on Google Cloud to leverage the speed and powerful capabilities of the most loved in-memory store: Redis. Memorystore for Redis Standard Tier instances are a popular choice for applications requiring a highly available Redis instance. Standard Tier provides a failover replica across zones for redundancy and provides fast failover with a 99.9% SLA. However, in some cases, your applications may need to scale beyond the limitations of a single Standard Tier instance. Read replicas allow you to scale to a higher read throughput, but your application may require higher write throughput or a larger keyspace size as well. In these scenarios, you can implement a strategy to partition your cache usage across multiple independent Memorystore instances which is known as client-side sharding. In this post, we’ll discuss how you can implement your own client-side sharding strategy to scale infinitely with Cloud Memorystore and Envoy.
Architectural Overview
Let’s start by discussing an architecture of GCP native services alongside open-source software which can scale Cloud Memorystore beyond its usual limits. To do this, we’ll be sharding a cache such that the total keyspace is split among multiple otherwise independent Memorystore instances. Sharding can pose challenges to client applications which must then be rewritten for awareness of the appropriate place to search for a specific key and must be updated to scale the backend. However, client-side sharding can be easier to implement and maintain by encapsulating the sharding logic in a proxy, allowing your application and sharding logic to be updated independently. You’ll find a sample architecture below and we’ll briefly detail each of the major components.
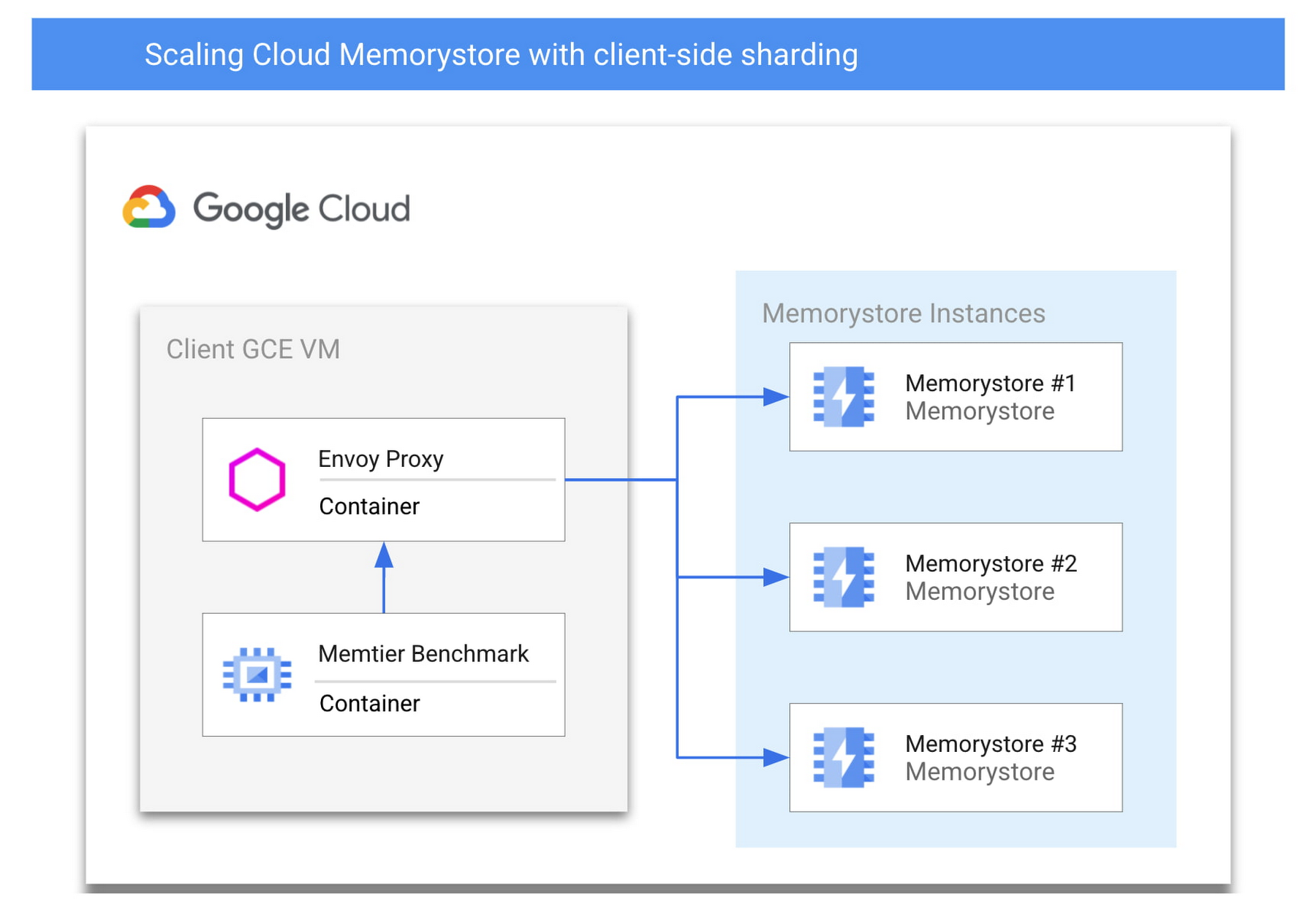
Memorystore for Redis
Cloud Memorystore for Redis enables GCP users to quickly deploy a managed Redis instance within a GCP project. A single node Memorystore instance can support a keyspace as large as 300 GB and a maximum network throughput of 16gbps. With Standard Tier you get a highly available Redis instance with built in health checks and fast automatic failover.
Today, we’ll show you how to deploy multiple Standard Tier Cloud Memorystore instances which can be used together to scale beyond the limits of a single instance for an application with increased scale demands. Each individual Memorystore instance will be deployed as a standalone instance that is unaware of the other instances within its shared host project. In this example, you’ll deploy three Standard Tier instances which will be treated as a single unified backend.
By using Standard Tier instances instead of self-managed Redis instances on GCE, you get the benefit of:
Highly available backends: Standard Tier provides high availability without requiring any additional work from you. Enabling high availability on self-managed Redis instances on GCE can add additional complexities and failure points.
Integrated monitoring: Memorystore is integrated with Cloud Monitoring and you can easily monitor the individual shards using Cloud Monitoring, compared to having to deploy and manage monitoring agents on self managed instances
Memtier Benchmark
Memtier Benchmark is a commonly used command line utility for load generation and benchmarking of key-value databases. You will deploy and use this utility to demonstrate the ability to easily scale to high query volume. Similar benchmarking tools or your own Redis client application could be used instead of Memtier Benchmark.
Envoy
Envoy is an open-source network proxy designed for service oriented architectures. Envoy supports many different filters which allow it to support network traffic from many different software applications and protocols. For this use case, you will deploy Envoy with the Redis filter configured. Rather than connecting directly to Memorystore instances, the Redis clients will connect to the Envoy proxy. By appropriately configuring Envoy, you can take a collection of independent Memorystore instances and define them as a cluster where inbound traffic will be load balanced among the individual instances. By leveraging Envoy, you decrease the likelihood of needing a significant application rewrite to leverage more than one Memorystore instance for higher scale. To ensure compatibility with your application, you’ll want to review the list of the Redis commands which Envoy currently supports.
Let’s get started.
Prerequisites
To follow along with this walkthrough, you’ll need a GCP project with permissions to do the following:
Deploy Cloud Memorystore for Redis instances (permissions)
Deploy GCE instances with SSH access (permissions)
Cloud Monitoring viewer access (permissions)
Access to Cloud Shell or another gCloud authenticated environment
Deploying the Memorystore Backend
You’ll start by deploying a backend cache which will serve all of your application traffic. As you’re looking to scale beyond the limits of a single node, you’ll deploy a series of Standard Tier instances. From an authenticated cloud shell environment, this can be done as follows:
$ for i in {1..3}; do gcloud redis instances create memorystore${i} --size=1 --region=us-central1 --tier=STANDARD --async; done
If you do not already have the Memorystore for Redis API enabled in your project, the command will ask you to enable the API before proceeding. While your Memorystore instances deploy, which typically takes a few minutes, you can move onto the next steps.
Creating a Client and Proxy VM
Next, you need a VM where you can deploy a Redis client and the Envoy proxy. You’ll be creating a single GCE instance where you deploy these two applications as containers. This type of deployment is referred to as a “sidecar architecture” which is a common Envoy deployment model. Deploying in this fashion nearly eliminates any added network latency as there is no additional physical network hop that takes place. While you are deploying a single vertically scaled client instance, in practice, you’ll likely deploy many clients and proxies, so the steps outlined in the following sections could be used to create a reusable instance template or repurposed for GKE.
You can start by creating the base VM:
$ gcloud compute instances create envoy-memtier-client --zone=us-central1-a --machine-type=e2-highcpu-32 --image-family cos-stable --image-project cos-cloud
We’ve opted for a Container-Optimized OS instance as you’ll be deploying Envoy and Memtier Benchmark as containers on this instance.
Configure and Deploy the Envoy Proxy
Before deploying the proxy, you need to gather the necessary information to properly configure the Memorystore endpoints. To do this, you need the host IP addresses for the Memorystore instances you have already created. You can gather these programmatically:
$ for i in {1..3}; do gcloud redis instances describe memorystore${i} --region us-central1 --format=json | jq -r ".host"; done
Copy these IP addresses somewhere easily accessible as you’ll use them shortly in your Envoy configuration.
Next, you’ll need to connect to your newly created VM instance, so that you can deploy the Envoy Proxy. You can do this easily via SSH in the Google Cloud Console. More details can be found here.
After you have successfully connected to the instance, you’ll create the Envoy configuration.
Start by creating a new file named envoy.yaml on the instance with your text editor of choice. Use the following .yaml file, entering the three IP addresses of the instances you created:
The IP addresses need to be inserted into the highlighted portions of each endpoint configuration near the bottom of the file. If you chose to create a different number of Memorystore instances, simply add or remove endpoints from the configuration file.
Before you move on, take a look at a few important details of the configuration:
We’ve configured the Redis Proxy filter to support the Redis traffic which you’ll be forwarding to Cloud Memorystore
We’ve configured the Envoy proxy to listen for client Redis traffic on port 6379
We’ve chosen MAGLEV as the load balancing policy for the Memorystore instances which make up the client-side sharded cluster. You can learn more about the various types of load balancing available here.
Scaling up and down the number of Memorystore backends requires rebalancing data and configuration changes which are not covered in this tutorial.
Once you’ve added your Memorystore instance IP addresses, save the file locally to your container OS VM where it can be easily referenced.
Now, you’ll use Docker to pull the official Envoy proxy image and run it with your own configuration.
$ docker run --rm -d -p 8001:8001 -p 6379:6379 -v $(pwd)/envoy.yaml:/envoy.yaml envoyproxy/envoy:v1.21.0 -c /envoy.yaml
Now that Envoy is deployed, you can test it by visiting the admin interface from the container VM:
$ curl -v localhost:8001/stats
If successful, you should see a print out of the various Envoy admin stats in your terminal. Without any traffic yet, these will not be particularly useful, but they allow you to ensure that your container is running and available on the network. If this command does not succeed, we recommend checking that the Envoy container is running. Common issues include syntax errors within your envoy.yaml and can be found by running your Envoy container interactively and reading the terminal output.
Deploy and Run Memtier Benchmark
While you’re still ssh’ed into the container OS VM, you will also deploy the Memtier Benchmark utility which you’ll use to generate artificial Redis traffic. Since you are using Memtier Benchmark, you do not need to provide your own dataset. The utility will populate the cache for you using a series of set commands.
You can run a series of benchmark tests:
$ for i in {1..15}; do docker run --network="host" --rm -d redislabs/memtier_benchmark:1.3.0 -s 127.0.0.1 -p 6379 --test-time=300 --key-maximum=10000; done
Here are some configuration options of note:
If you have configured Envoy to listen on another port, specify the appropriate port after the `-p` flag
We have chosen to run the benchmark for a set period of time (5 minutes, specified in seconds) by using the --test-time flag rather than a set number of requests which is the default behavior.
By default, the utility uses a uniform random pattern for getting and setting keys. You will not modify this, but it can be specified using the --keypattern flag.
The utility works by performing gets and sets based on the minimum and maximum values of the key range as well as the specified key pattern which we just discussed. We will decrease the size of this key range by setting the --key-maximum parameter. This allows us to ensure a higher cache hit ratio which is more representative of most real world applications.
The --ratio flag allows us to modify the set to get ratio of commands issued by the utility. By default, the utility issues 10 get commands for every set command. You can easily modify this ratio to better match your workload’s characteristics.
You can increase the load generated by the utility by increasing the number of threads with the `--threads` flag and/or by increasing the number of clients per thread with the `--clients` flag. The above command uses the default number of threads (4) and clients (50).
Observe the Redis Traffic
Once you have kicked off the load tests, you can confirm that traffic is being balanced across the individual Memorystore instances via Cloud Monitoring. You can easily set up a custom dashboard that shows the Calls per minute for each of the Memorystore instances.
Let’s start by navigating to the Cloud Monitoring Dashboards page. Next, you’ll click “Create Dashboard”. You will see many different types of widgets on the left side of the page which can be dragged onto the canvas on the right side of the page. You’ll select a “Line” chart and drag it onto the canvas. You then need to populate the line chart with data from the Memorystore instances. To do this, you’ll configure the chart via “MQL” which can be selected at the top of the chart configuration pane. For ease, we’ve created a query which you can simply paste into your console to populate your chart:
If you have created your Memorystore instances with a different naming convention or have other Memorystore instances within the same project, you may need to modify the resource.instance_id filter. Once you’re finished, ensure that your chart is viewing the appropriate time range, and you should see something like:
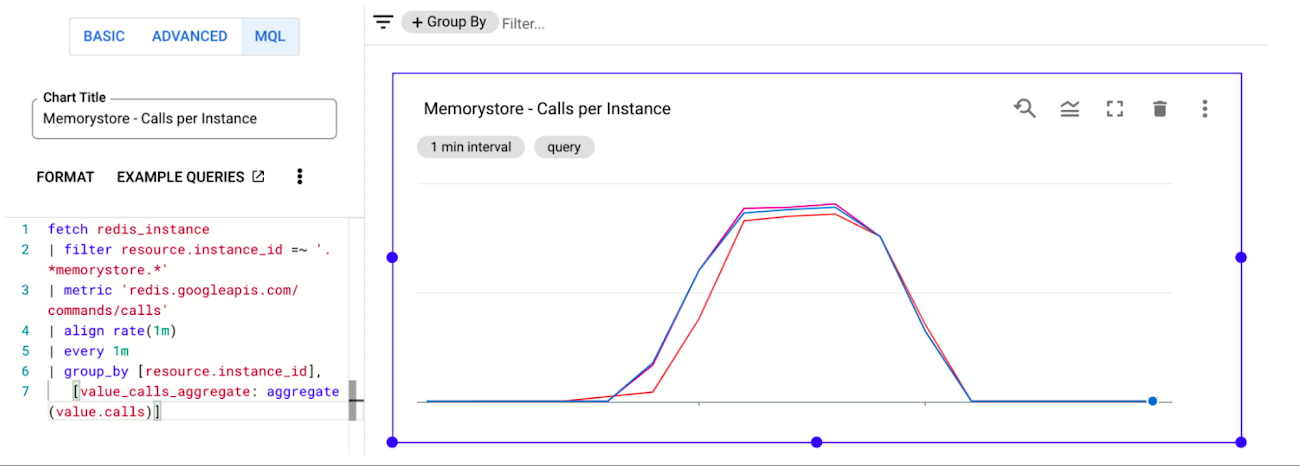
You should see nearly perfect distribution of the client workload across the Memorystore instances, effectively allowing infinite horizontal scalability for demanding workloads. More details on creating and managing custom dashboards can be found here.
As you modify the parameters of your own testing, you’ll also want to keep the performance of the client and proxy in mind. As you vertically scale the number of operations sent by a client, you’ll eventually need to horizontally scale the number of clients and sidecar proxies which you have deployed to scale smoothly. You can view the Cloud Monitoring graphs for GCE instances as well. More details can be found here.
Clean Up
If you have followed along, you’ll want to spend a few minutes cleaning up resources to avoid accruing unwanted charges. You’ll need to delete the following:
Any deployed Memorystore instances
Any deployed GCE instances
Memorystore instances can be deleted like:
$ gcloud redis instances delete <instance-name> --region=<region>
If you followed the tutorial, you can use a command like:
$ for i in {1..3}; do gcloud redis instances delete memorystore${i} --region=us-central1 --async; done
Note: You’ll need to manually acknowledge the deletion of each instance via the terminal
The GCE container OS instance can be deleted like:
$ gcloud compute instances delete <instance-name>
If you created additional instances, you can simply chain them in a single command separated by spaces.
Conclusion
Client-side sharding is one strategy to address high scale use cases with Cloud Memorystore. Envoy and its Redis filter make implementation simple and extensible. The outline provided above is a great place to get started. These instructions can easily be extended to support other client deployment models including GKE and can be scaled out horizontally to reach even higher scale. As always, you can learn more about Cloud Memorystore through our documentation or request desired features via our public issue tracker.


