Get 6X read performance with Memorystore for Redis Read Replicas

Gopal Ashok
Product Management
Modern applications need to process large-scale data at millisecond latency to provide experiences like instant gaming leaderboards, fast analysis of streaming data from millions of IoT sensors, or real-time threat detection of malicious websites. In-memory datastores are a critical component to deliver the scale, performance, and availability required by these modern applications.
Memorystore makes it easy for developers building applications on Google Cloud to leverage the speed and powerful capabilities of the most loved in-memory store: Redis. Memorystore for Redis standard tier instances are a popular choice for applications requiring a highly available Redis instance. Standard tier provides a failover replica across zones for redundancy and provides fast failover with a 99.9% SLA. However, in some cases, your applications will require more read throughput from a standard tier instance. One of the common patterns customers use to scale read queries in Redis is leveraging read replicas.
Introducing Memorystore for Redis Read Replicas
Today we are excited to announce the public preview of Memorystore for Redis Read Replicas, which allows you to seamlessly scale your application’s read requests by 6X with the click of a button.
With read replicas, you can easily add up to five replicas and leverage the read endpoint to automatically load balance read queries across all the available replicas, increasing read performance linearly with each replica added. Additionally, Memorystore’s support for Redis 6 introduced multi-thread I/O, increasing performance significantly for M3 and higher configurations. Combined, you can achieve read requests of more than a million requests per second.
You will benefit from this new functionality in several ways. You will be able to scale on demand with up to five read replicas and use read endpoint with any redis client to easily load balance read queries across multiple replicas. This new functionality will also improve availability with automatic distribution of replicas across multiple zones. With read replicas, you will also be able to minimize application downtime with fast failover to the replica with the least replication lag. In the future, Memorystore will also easily enable read replicas on existing standard tier instances to increase read throughput.
You can learn more about how to configure and use read replicas in the Read Replicas Overview.
Improving performance with Read Replicas and Redis 6
With the launch of read replicas, you can easily increase the read throughput of a Memorystore instance. You can further enhance the read performance by leveraging Redis version 6 along with read replicas.
To understand why combining read replicas and Redis 6 can significantly improve your application’s read performance, let’s look at the various Memorystore configurations that you can use with your applications today. Memorystore Basic and Standard offerings provide different capacity tiers. The capacity tier determines the single node performance of a basic and standard tier instance.
The table below outlines the configuration of the various capacity tiers:
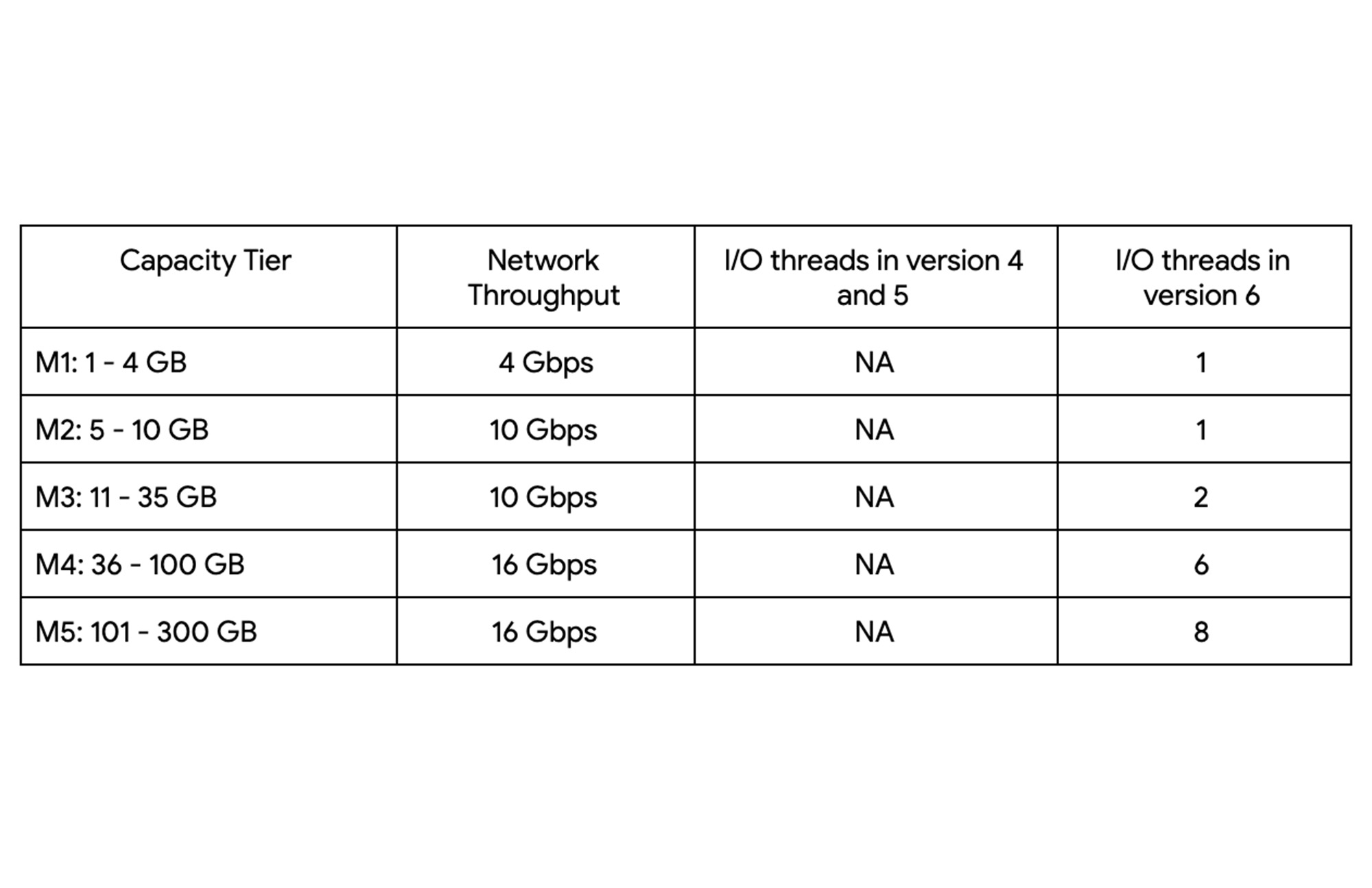
Up until version 5, Redis processed commands using a single thread. The processing involved reading the request, parsing the request, processing the request, and writing the response back to the socket. This approach means that all of the processing, which includes writing the response, was sequentially processed by a single vCPU regardless of the number of vCPUs available in the instance.
Redis 6 introduced I\O threading which allows writing the response using parallel threads. This functionality enables Redis 6 to more effectively leverage available vCPUs, thereby increasing the overall throughput compared to lower versions. Memorystore for Redis version 6 leverages I\O threading and automatically configures the optimal number of I\O threads to achieve the best possible performance for the various capacity tiers. We have also improved the overall network throughput for all redis versions by leveraging improvements in the Google Cloud infrastructure. Together these improvements deliver significant performance improvements and come at no additional cost to you.
So what can you expect from using Redis 6? As outlined in the table, Redis version 5 and lower uses a single thread to process the write requests for all tiers while Redis 6 uses a larger number of I\O threads at higher capacity tiers which provides substantially incremental throughput for higher capacity tiers.
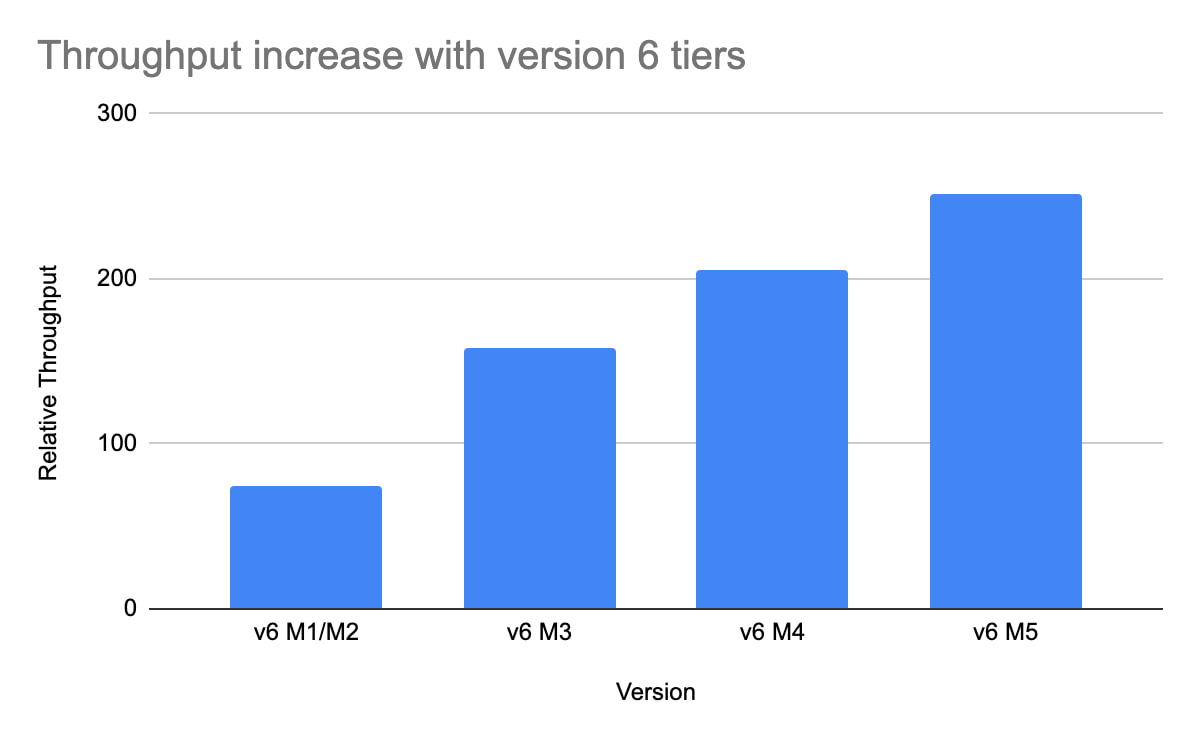
For example, using a Redis 6 standard tier instance with a capacity of 101 GB (M5), we have observed up to a 200% improvement in read/write performance compared to version 5, though the actual value you'll see is dependent on your workload. You can get the benefits of Redis 6 by upgrading an existing instance or by deploying a new instance.
By enabling read replicas on an instance using Redis 6, you can further improve the read performance. Read throughput scales linearly with the number of replicas so you can increase your read queries on an instance by up to 500% using five read replicas. By combining Redis 6 and read replicas, you can see a 10X increase in read performance compared to a version 5 standard tier instance with no read replicas.
We are excited about the launch of read replicas but this is just one step in our journey to deliver the scale you need at the best price-performance. You can learn more about read replicas pricing on our Memorystore pricing page and get started using the Read Replicas Overview.


